Loading...
搞懂缓存机制,从Gemma4到Claude Code省80%Token大模型生成文本时,用的是 Transformer 注意力机制。核心公式:Attent...
https://poloclub.github.io/transformer-explainer/htt...
From: 如何理解attention中的Q,K,V?- 知乎From: https://www.zhihu.com/question/298810062...
往往是训练或微调 LLM,以基于特定的基础知识进行特定任务. 下图示例了不同的微调策略.LLMs 很难完...
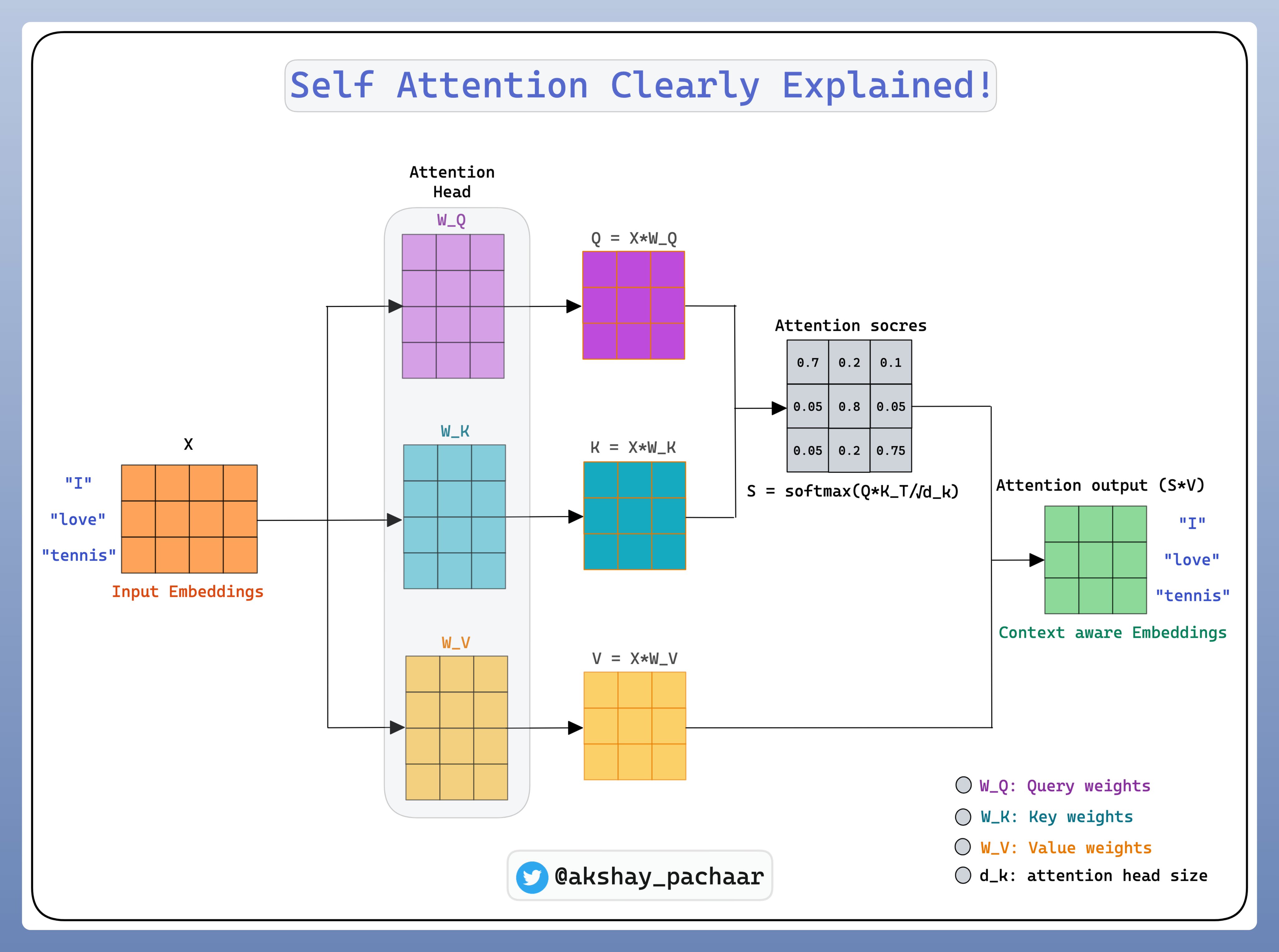
From: https://twitter.com/akshay_pachaar/status/1667147048553164800LLMs 大火,但它...
From: https://twitter.com/akshay_pachaar/status/1657...
From: https://twitter.com/akshay_pachaar/status/1638518399914643456Block可以修改 ...
https://www.youtube.com/watch?v=VtZ02rnfcCQAnalogie...
出处:Paddle文档平台 - ViT( Vision Transformer)1. ViT模型介绍在计算机视觉领域中,多数算法都是保持CNN整体结构不变...
出处:Paddle文档平台 - Transformer1. Transformer 介绍Transfor...