搞懂缓存机制,从Gemma4到Claude Code省80%Token
大模型生成文本时,用的是 Transformer 注意力机制。核心公式:
Attention(Q, K, V) = softmax(Q · Kᵀ / √d) · V
Q、K、V 三个角色:
- Q (Query) — 当前新 token 的,"我要找什么?" → 每次不同,不能缓存
- K (Key) — 历史 token 的,"我这有什么?"(索引) → 算完就固定,可以缓存
- V (Value) — 历史 token 的,"具体内容是什么?" → 算完就固定,可以缓存
KV 缓存就是把历史 token 的 Key 和 Value 存起来,新 token 只需要算自己的 Q,然后查已有的 KV。
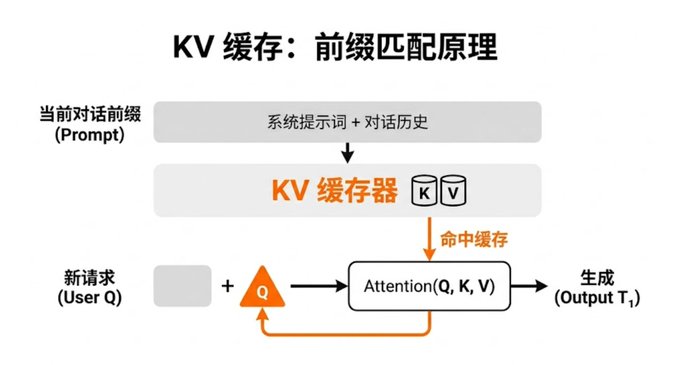
这之所以可行,是因为当前所有主流大模型(Claude、GPT、Gemini、Llama、Gemma、Qwen)都是 Decoder-only 架构——单向注意力,每个 token 只看前面的 token。前面 token 的 KV 算完就固定了,后面怎么追加都不影响。

如果是双向注意力(BERT),加一个新 token 会改变所有 token 的表示,缓存全废。这也是为什么 BERT 做不了生成式 AI。
模型越大,KV 计算越昂贵,缓存收益越大:
Transformer 的计算是确定性的,KV 从缓存加载和现场计算的结果完全一致。
在下一轮对话中,上轮的生成结果被拼回 prompt,变成了"输入"的一部分,自然被缓存覆盖。
第 1 轮:
输入: [系统提示][user: "你好"]
输出: [assistant: "你好!"] ← 不进缓存
第 2 轮:
输入: [系统提示][user: "你好"][assistant: "你好!"][user: "帮我改代码"]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~~~
整段前缀从缓存读取 只有这部分全价计算对话越长,缓存覆盖比例越高,每轮新增计算量越小。这就是为什么多轮对话是缓存的最佳场景,也是为何 Opus 现在拿 1m 当默认项。
多轮对话的上下文累计:有缓存 vs 没缓存
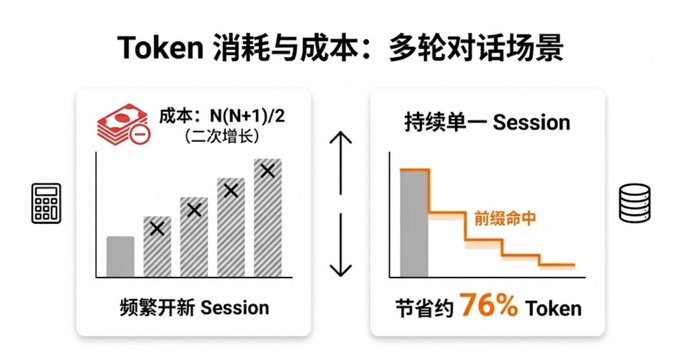
很多人以为每轮对话都要"重新读一遍"所有历史,token 消耗是 N(N+1)/2 的二次增长。如果没有缓存,确实如此。但有了缓存,情况完全不同.
假设:系统提示 20K tokens,每轮对话增加 ~1K tokens(user + assistant)
没有缓存(每轮全价):
Turn 1: 20K + 1K = 21K tokens 全价
Turn 2: 20K + 2K = 22K tokens 全价
Turn 3: 20K + 3K = 23K tokens 全价
...
Turn 10: 20K + 10K = 30K tokens 全价
────────────────────────────
10 轮总计:~255K tokens(全价) ← 二次增长,越来越贵
有缓存(前缀 1/10 价格):
Turn 1: 20K×1.25 + 1K = 26K 等价 首次写入缓存(贵 25%)
Turn 2: 20K×0.1 + 1K×0.1 + 1K = 3.1K 等价 前缀从缓存读
Turn 3: 20K×0.1 + 2K×0.1 + 1K = 3.2K 等价 更多前缀被缓存
...
Turn 10: 20K×0.1 + 9K×0.1 + 1K = 3.9K 等价 几乎全部缓存
────────────────────────────
10 轮总计:~60K 等价 tokens ← 近似线性增长!对比:255K vs 60K,缓存省了 76%。
可视化上下文累计:
没有缓存(每条都全价):
Turn 1: ████████████████████░ 21K
Turn 5: ████████████████████████░ 25K
Turn 10: ████████████████████████████░ 30K
↑ 全部全价,面积 = 总花费
有缓存(前缀只花 1/10):
Turn 1: ████████████████████░ 26K (首次写入)
Turn 5: ██░ 3.5K (几乎全缓存)
Turn 10: ███░ 3.9K (几乎全缓存)
↑ 前缀淡色 = 缓存读取 1/10这就是为什么"一个 session 持续对话"比"频繁开新 session"省钱的根本原因。 新 session 每次从 Turn 1 开始,永远在付全价写入缓存的钱。老 session 继续对话,前面的全是缓存,只有末尾新增的一点点是全价。
实验中也发现,Ollama 的缓存是概率性的——同样的 prompt 跑两次,缓存命中的轮次不同,而且连续命中几次后可能突然失效(内存压力导致 KV 被淘汰)。效果惊人,但不可靠。