StreamlitCode:Building a Semantic Search Engine
英文:The unreasonable effectiveness of Deep Learning Representations

主要介绍如何基于向量表示(vector representations) 创建搜索引擎.
主要内容:
- [1] - 如何搜索与出与输入图像相似的图像?
- [2] - 如何搜索出相似单词和同义词(synonyms)?
- [3] - 生成图像的标签(tags),并采用语言(language) 搜索图像?
采用嵌入(embeddings) 的简单方法,基于图像和文本的向量表示. 一旦创建了嵌入,则搜索问题就转变为寻找与输入向量最接近的向量的问题(finding vectors close to the input vector).
计算向量间的相似性,采用的是余弦距离(cosine distance),来度量图像嵌入向量和其它图像嵌入向量的相似性. 相似的图像间具有相似的嵌入表示,即,其嵌入表示间具有较小的余弦距离.
1. 数据集
pascal-sentences
1.1 数据集加载
这里采用的数据集共有 1000 张图像,20 个类别,每个类别包含 50 张图像.
20 个图像类别分别为:`aeroplane bicycle bird boat bottle bus car cat chair cow dining_table dog horse motorbike person potted_plant sheep sofa train tv_monitor.
另外,加载在 Wikipedia 上预训练的 GloVe 向量,用于合并文本(incorporate text).
GloVe: Global Vectors for Word Representation
word_vectors = vector_search.load_glove_vectors("models/glove.6B")
images, vectors, image_paths = load_paired_img_wrd('dataset', word_vectors)数据集加载函数:
def load_paired_img_wrd(folder, word_vectors, use_word_vectors=True):
class_names = [fold for fold in os.listdir(folder) if ".DS" not in fold]
image_list = []
labels_list = []
paths_list = []
for cl in class_names:
splits = cl.split("_")
if use_word_vectors:
vectors = np.array([word_vectors[split] if split in word_vectors
else np.zeros(shape=300) for split in splits])
class_vector = np.mean(vectors, axis=0)
subfiles = [f for f in os.listdir(folder + "/" + cl) if ".DS" not in f]
for subf in subfiles:
full_path = os.path.join(folder, cl, subf)
img = image.load_img(full_path, target_size=(224, 224))
x_raw = image.img_to_array(img)
x_expand = np.expand_dims(x_raw, axis=0)
x = preprocess_input(x_expand)
image_list.append(x)
if use_word_vectors:
labels_list.append(class_vector)
paths_list.append(full_path)
img_data = np.array(image_list)
img_data = np.rollaxis(img_data, 1, 0)
img_data = img_data[0]
return img_data, np.array(labels_list), paths_list至此,得到了图像张量 - (1000, 224, 224, 3),单词向量 - (1000, 300),以及对应的文件路径列表.
1.2 数据可视化
从每个图像类别中分别显示一张样例图像,如下:


可以看出,图像中的 labels 是存在很多噪声干扰的,很多图像中包含多个类别,但给定的 label 并不总是图像中最重要的类别标签.
2. 图像索引
现在,将要加载在大规模数据集(ImageNet) 上预训练的模型,用于生成图像的嵌入(embeddings,向量表示).3
一旦采用网络模型生成了图像特征,则可以保存到磁盘,以便于不用再次推断计算而可以直接重用. 这是嵌入方法流行的原因之一. 在实际应用中,其很有助于效率.
model = vector_search.load_headless_pretrained_model()
if generate_image_features:
images_features, file_index = vector_search.generate_features(
image_paths, model)
vector_search.save_features(features_path,
images_features,
file_mapping_path,
file_index)
else:
images_features, file_index = vector_search.load_features(
features_path, file_mapping_path)这里采用的模型时采用的 VGG16,去除了其最后一层 softmax 层:

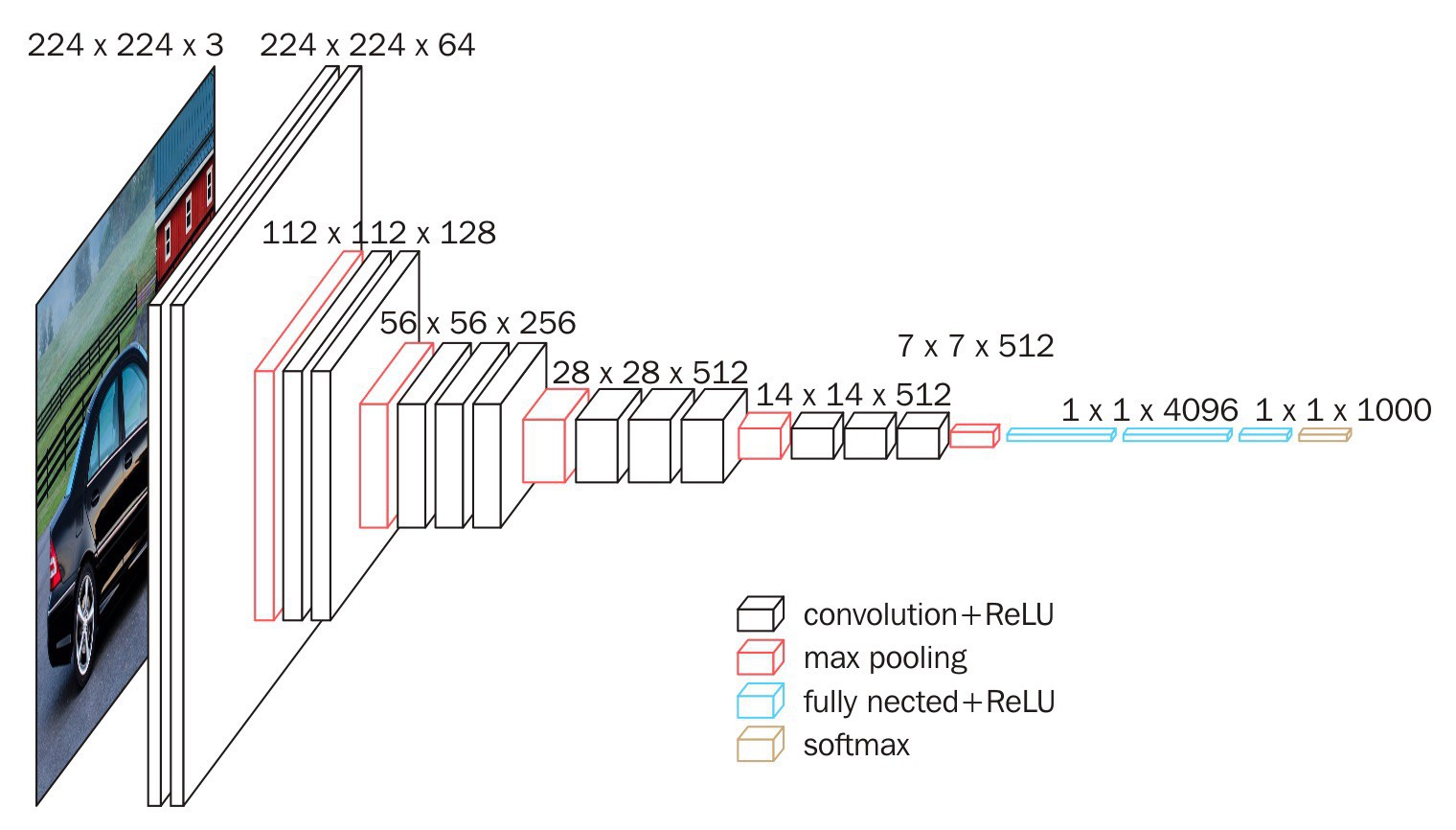
原始 VGG 网络结构
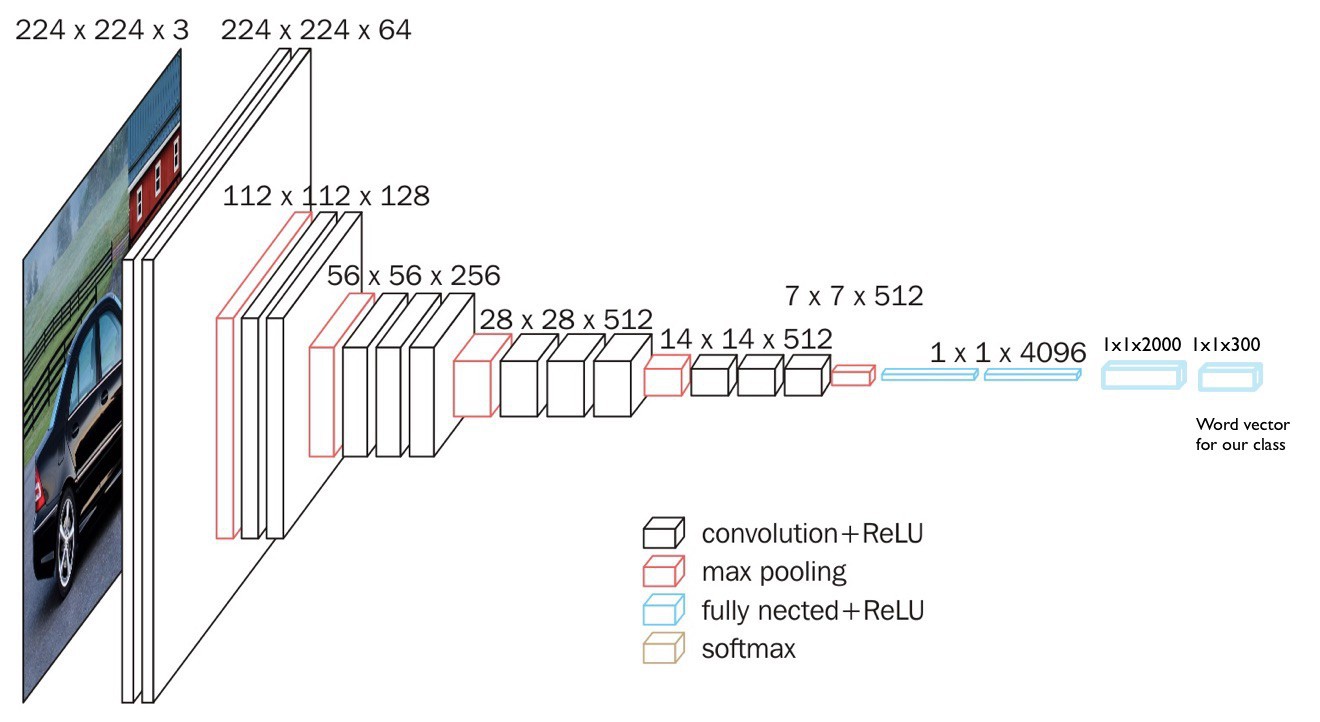
这里采用的网络模型
模型构建实现代码:
def load_headless_pretrained_model():
"""
Loads the pretrained version of VGG with the last layer cut off
:return: pre-trained headless VGG16 Keras Model
"""
pretrained_vgg16 = VGG16(weights='imagenet', include_top=True)
model = Model(inputs=pretrained_vgg16.input,
outputs=pretrained_vgg16.get_layer('fc2').output)
return model嵌入生成,是指,采用预训练的模型的第一层到倒数第二层,并保存激活值:
def generate_features(image_paths, model):
"""
Takes in an array of image paths, and a trained model.
Returns the activations of the last layer for each image
:param image_paths: array of image paths
:param model: pre-trained model
:return: array of last-layer activations, and mapping from array_index to file_path
"""
start = time.time()
images = np.zeros(shape=(len(image_paths), 224, 224, 3))
file_mapping = {i: f for i, f in enumerate(image_paths)}
# We load all our dataset in memory because it is relatively small
for i, f in enumerate(image_paths):
img = image.load_img(f, target_size=(224, 224))
x_raw = image.img_to_array(img)
x_expand = np.expand_dims(x_raw, axis=0)
images[i, :, :, :] = x_expand
logger.info("%s images loaded" % len(images))
inputs = preprocess_input(images)
logger.info("Images preprocessed")
images_features = model.predict(inputs)
end = time.time()
logger.info("Inference done, %s Generation time" % (end - start))
return images_features, file_mapping下面是前 20 张图像的嵌入表示. 每张图像被表示为 4096-维的稀疏向量.
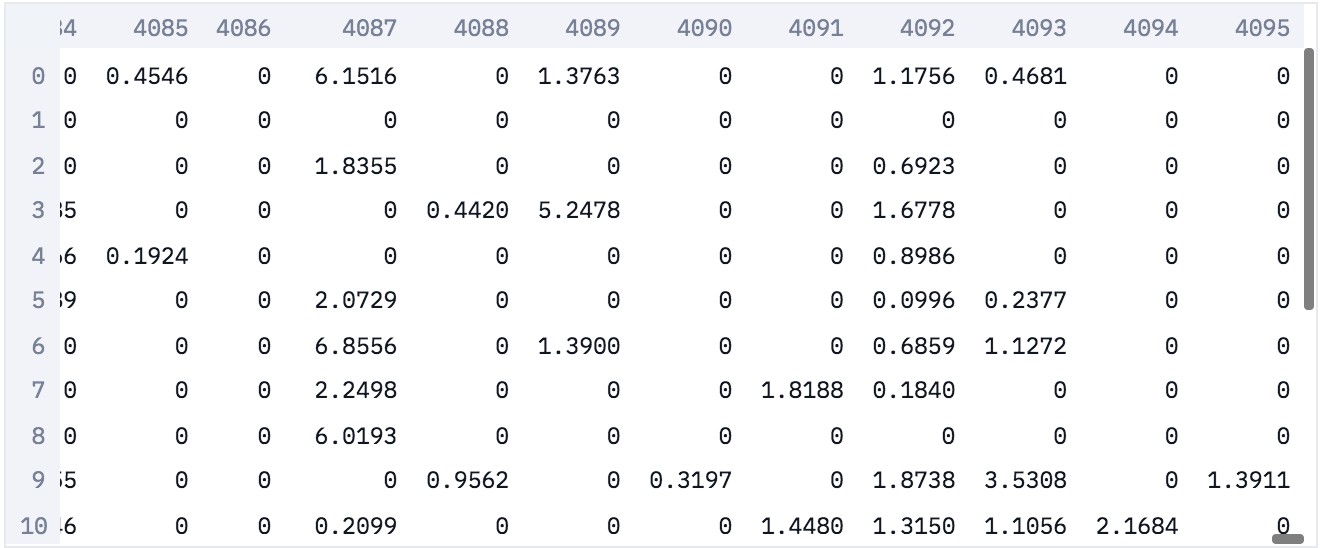
得到了特征以后,即可采用 Annoy 构建搜索的快速索引(fast index).
image_index = vector_search.index_features(images_features)def index_features(features, n_trees=1000, dims=4096, is_dict=False):
"""
Use Annoy to index our features to be able to query them rapidly
:param features: array of item features
:param n_trees: number of trees to use for Annoy. Higher is more precise but slower.
:param dims: dimension of our features
:return: an Annoy tree of indexed features
"""
feature_index = AnnoyIndex(dims, metric='angular')
for i, row in enumerate(features):
vec = row
if is_dict:
vec = features[row]
feature_index.add_item(i, vec)
feature_index.build(n_trees)
return feature_index3. 基于嵌入来搜索图像
现在,可以采用一张图像作为输入,计算得到其嵌入(embedding,保存到磁盘),然后在快速索引(fast index) 中查找相似嵌入,进而得到相似图像(similar embeddings, and thus similar images).
图像嵌入向量是信息更丰富的,因为图像标签通常很嘈杂,并且一般来说图像内包含的信息比标签的信息更多.
如,图片数据集中如下图片,有 cat 和 bottle 这两个类,你觉得图片会被标记成哪一个类?

Cat 还是 Bottle? (图像被缩放到了 224x224)
正确答案是瓶子Bottle.
这是实际数据集中经常遇到的问题. 将图像标记为唯一类别的情况是很少的,这也是希望使用更细微的表示的原因.
下面例示,基于嵌入表示的图像搜索,是否比人类标签更有效果.
寻找索引 200,dataset/bottle/2008_000112.jpg文件:
results = vector_search.search_index_by_key(search_key, image_index, file_index)def search_index_by_key(key, feature_index, item_mapping, top_n=10):
"""
Search an Annoy index by key, return n nearest items
:param key: the index of our item in our array of features
:param feature_index: an Annoy tree of indexed features
:param item_mapping: mapping from indices to paths/names
:param top_n: how many items to return
:return: an array of [index, item, distance] of size top_n
"""
distances = feature_index.get_nns_by_item(key, top_n, include_distances=True)
return [[a, item_mapping[a], distances[1][i]] for i, a in enumerate(distances[0])]输出如下:
[200, 'dataset/bottle/2008_000112.jpg', 8.953361975727603e-05][375, 'dataset/cat/2008_004635.jpg', 0.9413783550262451][399, 'dataset/cat/2008_007888.jpg', 0.9977052211761475][361, 'dataset/cat/2008_002201.jpg', 1.0260729789733887][778, 'dataset/potted_plant/2008_006068.jpg', 1.0308609008789062][370, 'dataset/cat/2008_003622.jpg', 1.0327214002609253][360, 'dataset/cat/2008_002067.jpg', 1.032860517501831][220, 'dataset/bottle/2008_004795.jpg', 1.0681318044662476][381, 'dataset/cat/2008_005386.jpg', 1.0685954093933105][445, 'dataset/chair/2008_007941.jpg', 1.074022650718689]

3.2 半监督搜索
对应于 从零开始构建图像搜索模型 - 5.2 半监督搜索(章节) - AIUAI

例如,根据 ImageNet 类别 284(Siamese cat) 对激活值进行加权,说明其工作原理:
# Index 284 is the index for the Siamese cat class in Imagenet
weighted_features = vector_search.get_weighted_features(284, images_features)
weighted_index = vector_search.index_features(weighted_features)
weighted_results = vector_search.search_index_by_key(search_key,
weighted_index,
file_index)def get_weighted_features(class_index, images_features):
"""
Use class weights to re-weigh our features
:param class_index: Which Imagenet class index to weigh our features on
:param images_features: Unweighted features
:return: Array of weighted activations
"""
class_weights = get_class_weights_from_vgg()
target_class_weights = class_weights[:, class_index]
weighted = images_features * target_class_weights
return weighted基于加权后的模型得到的输出如:
[200, 'dataset/bottle/2008_000112.jpg', 0.00011064470891142264][375, 'dataset/cat/2008_004635.jpg', 0.8694091439247131][399, 'dataset/cat/2008_007888.jpg', 0.968299150466919][370, 'dataset/cat/2008_003622.jpg', 0.9725740551948547][361, 'dataset/cat/2008_002201.jpg', 1.007677435874939][360, 'dataset/cat/2008_002067.jpg', 1.0096632242202759][445, 'dataset/chair/2008_007941.jpg', 1.013108730316162][778, 'dataset/potted_plant/2008_006068.jpg', 1.019992470741272][812, 'dataset/sheep/2008_004621.jpg', 1.021153211593628][824, 'dataset/sheep/2008_006327.jpg', 1.0285786390304565]

4. 文本嵌入
4.1 构建文本向量
NLP 领域,建立单词的嵌入.
这里采用 GloVe 模型,加载预训练的向量集合,其通过爬取维基百科的所有内容并学习该数据集中单词之间的语义关系而获得的.
类似于图像的嵌入表示,这里将创建一个包含所有 GloVe 向量的索引. 然后,可以在嵌入层中搜索相似的单词.
st.write("word", word_vectors["word"])
st.write("vector", word_vectors["vector"])
try:
st.write("fwjwiwejiu", word_vectors["fwjwiwejiu"])
except KeyError as key:
st.write("The word %s does not exist" % key)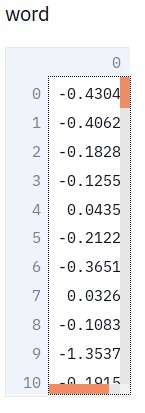
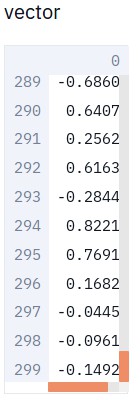
单词 fwjwiwejiu 不存在.
4.2 文本向量索引
类似于图像向量,创建索引器,对所有 GloVe 向量建立索引:
word_index, word_mapping = vector_search.build_word_index(word_vectors)def build_word_index(word_vectors):
"""
Builds a fast index out of a list of pretrained word vectors
:param word_vectors: a list of pre-trained word vectors loaded from a file
:return: an Annoy tree of indexed word vectors and
a mapping from the Annoy index to the word string
"""
logging.info("Creating mapping and list of features")
word_list = [(i, word) for i, word in enumerate(word_vectors)]
word_mapping = {k: v for k, v in word_list}
word_features = [word_vectors[lis[1]] for lis in word_list]
logging.info("Building tree")
word_index = index_features(word_features, n_trees=20, dims=300)
logging.info("Tree built")
return word_index, word_mapping4.3 单词搜索
搜索相似单词的嵌入.
如,said:
[16, 'said', 0.0][154, 'told', 0.688713550567627][391, 'spokesman', 0.7859575152397156][476, 'asked', 0.872875452041626][3852, 'noting', 0.9151610732078552][1212, 'warned', 0.915908694267273][2558, 'referring', 0.9276227951049805][859, 'reporters', 0.9325974583625793][2948, 'stressed', 0.9445104002952576][171, 'tuesday', 0.9446316957473755]
如,one:
[48, 'one', 0.0][170, 'another', 0.6205118894577026][91, 'only', 0.666000247001648][55, 'two', 0.6895312070846558][58, 'first', 0.7803555130958557][215, 'same', 0.7992483973503113][79, 'time', 0.8085516691207886][359, 'every', 0.8182190656661987][120, 'just', 0.8255878686904907][126, 'second', 0.8277111649513245]
如,(:
[23, '(', 0.0][24, ')', 0.21370187401771545][652, '8', 1.0106892585754395][422, '5', 1.0143887996673584][524, '6', 1.0183145999908447][632, '7', 1.0220754146575928][790, '9', 1.0285060405731201][314, '3', 1.0295473337173462][409, '4', 1.0337133407592773][45, ':', 1.0341565608978271]
5. 单词融合(Worlds Collide)
5.1 创建混合模型
通常情况下,图像分类器的训练是为了从多个图像类别中预测一个特定类别(如,ImageNet 1000 个类别). 即,网络最后一层是 1000-维向量,每一维表示了每个类别的概率. 这一网络层这里被移除.
这里,将模型的目标替换为类别的词向量(word vector of the category),其可以使得模型能够学习图像语义和单词语义的映射关系.
这里,添加了两个全连接层,得到输出层的大小为 300 维.
原始 VGG 网络结构
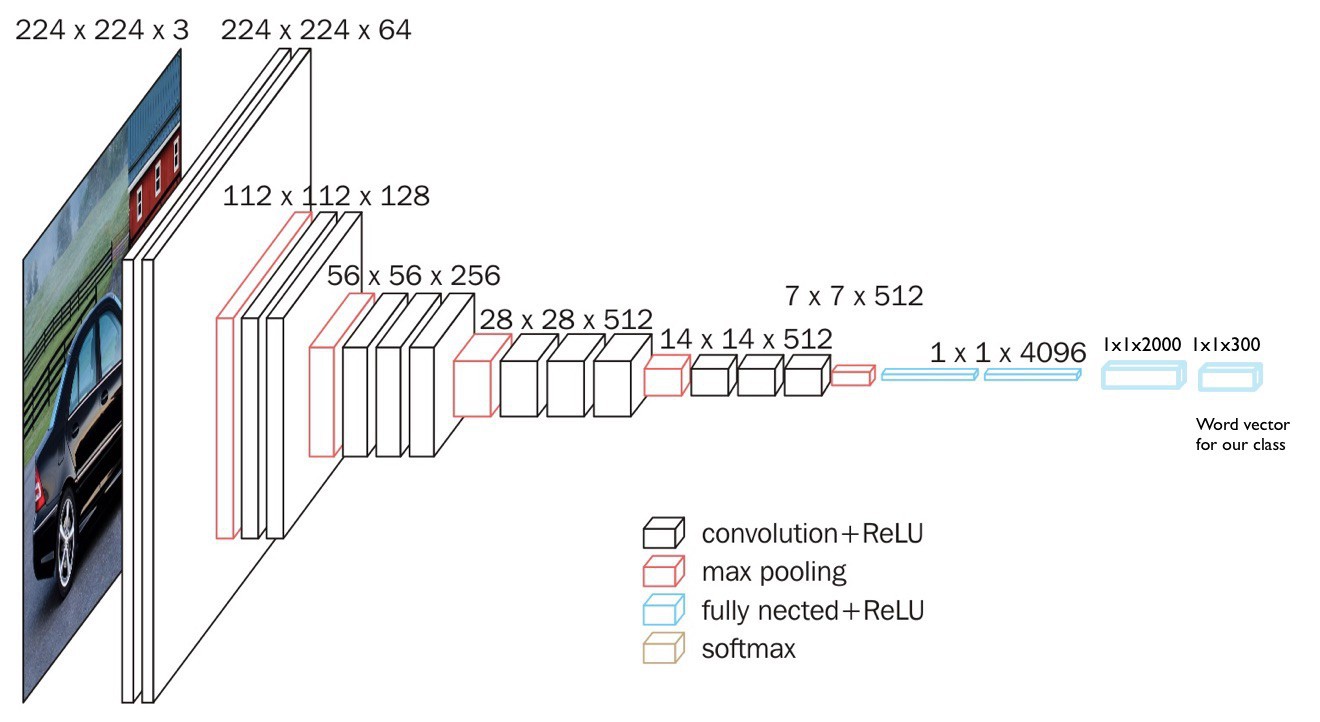
构建的网络模型
5.2 模型训练
模型构建代码:
custom_model = vector_search.setup_custon_model()def setup_custon_model(intermediate_dim=2000, word_embedding_dim=300):
"""
Builds a custom model taking the fc2 layer of VGG16 and
adding two dense layers on top
:param intermediate_dim: dimension of the intermediate dense layer
:param word_embedding_dim: dimension of the final layer,
which should match the size of our word embeddings
:return: a Keras model with the backbone frozen,
and the upper layers ready to be trained
"""
headless_pretrained_vgg16 = VGG16(weights='imagenet',
include_top=True,
input_shape=(224, 224, 3))
x = headless_pretrained_vgg16.get_layer('fc2').output
# We do not re-train VGG entirely here,
# just to get to a result quicker
# (fine-tuning the whole network would lead to better results)
for layer in headless_pretrained_vgg16.layers:
layer.trainable = False
image_dense1 = Dense(intermediate_dim, name="image_dense1")(x)
image_dense1 = BatchNormalization()(image_dense1)
image_dense1 = Activation("relu")(image_dense1)
image_dense1 = Dropout(0.5)(image_dense1)
image_dense2 = Dense(word_embedding_dim, name="image_dense2")(image_dense1)
image_output = BatchNormalization()(image_dense2)
complete_model = Model(inputs=[headless_pretrained_vgg16.input],
outputs=image_output)
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
complete_model.compile(optimizer=sgd, loss=cosine_proximity)
return complete_model在训练数据集上重新训练模型,以使得模型预测与图像标签相关的单词向量(**the word_vector
associated with the label of an image**).
例如,对于一张 cat类别的图像,模型要预测与 cat 相关的 300-维向量.
if train_model:
with st.echo():
num_epochs = 50
batch_size = 32
st.write(
"Training for %s epochs, this might take a while, "
"change train_model to False to load pre-trained model" % num_epochs)
x, y = shuffle(images, vectors, random_state=2)
X_train, X_test, y_train, y_test = train_test_split(x, y,
test_size=0.2,
random_state=2)
checkpointer = ModelCheckpoint(filepath='checkpoint.hdf5',
verbose=1,
save_best_only=True)
custom_model.fit(X_train,
y_train,
validation_data=(X_test, y_test),
epochs=num_epochs,
batch_size=batch_size,
callbacks=[checkpointer])
custom_model.save(model_save_path)
else:
st.write("Loading model from `%s`" % model_load_path)
custom_model = load_model(model_load_path)从 cpu_5_hours.hdf5 中加载模型.
5.3 构建单词和图像的两个 索引
模型训练完后,对于单词索引,采用的是 4.2-文本向量索引.
为了构建快速图像索引,需要采用新模型对每张图像运行一次前向计算:
if generate_custom_features:
hybrid_images_features, file_mapping =
vector_search.generate_features(image_paths, custom_model)
vector_search.save_features(custom_features_path,
hybrid_images_features,
custom_features_file_mapping_path,
file_mapping)
else:
hybrid_images_features, file_mapping =
vector_search.load_features(custom_features_path,
custom_features_file_mapping_path)
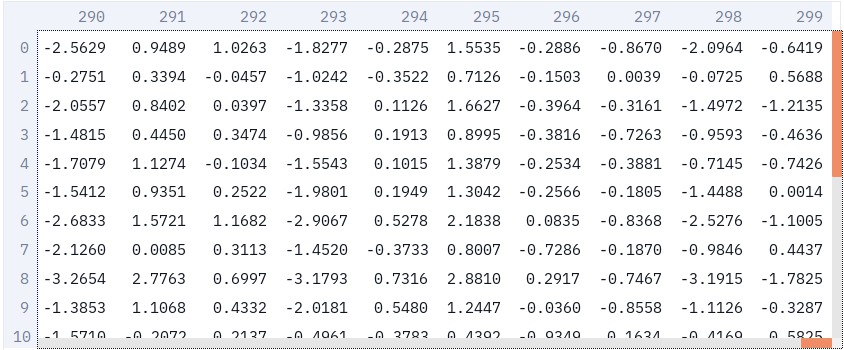
image_index = vector_search.index_features(hybrid_images_features, dims=300)下面是前 20 张图像的嵌入表示,其长度为300,类似于单词向量:
5.4 生成语义标签(tags)
基于构建的混合模型,可以提取任何图像的标签.
例如,cat/bottle 图像:

生成图像 dataset/bottle/2008_000112.jpg 的标签:
results = vector_search.search_index_by_value(hybrid_images_features[200],
word_index,
word_mapping)def search_index_by_value(vector, feature_index, item_mapping, top_n=10):
"""
Search an Annoy index by value, return n nearest items
:param vector: the index of our item in our array of features
:param feature_index: an Annoy tree of indexed features
:param item_mapping: mapping from indices to paths/names
:param top_n: how many items to return
:return: an array of [index, item, distance] of size top_n
"""
distances = feature_index.get_nns_by_vector(vector, top_n, include_distances=True)
return [[a, item_mapping[a], distances[1][i]] for i, a in enumerate(distances[0])]输出结果如下:
[5450, 'cat', 0.8766047954559326][18990, 'litter', 1.173615574836731][39138, 'raccoon', 1.1843332052230835][11408, 'monkey', 1.1853549480438232][18389, 'leopard', 1.1956979036331177][22454, 'puppy', 1.2021284103393555][18548, 'sunglasses', 1.2086421251296997][13748, 'goat', 1.2140742540359497][22718, 'squirrel', 1.217861294746399][8891, 'mask', 1.2214369773864746]
生成图像 dataset/bottle/2008_005023.jpg 的标签:
results = vector_search.search_index_by_value(hybrid_images_features[223],
word_index,
word_mapping)输出如下:
[6676, 'bottle', 0.3879561722278595][7494, 'bottles', 0.7513495683670044][12780, 'cans', 0.9817070364952087][16883, 'vodka', 0.9828150272369385][16720, 'jar', 1.0084964036941528][12714, 'soda', 1.0182772874832153][23279, 'jars', 1.0454961061477661][3754, 'plastic', 1.0530102252960205][19045, 'whiskey', 1.061428427696228][4769, 'bag', 1.0815287828445435]
模型可以学习提取许多相关标签,即使其并没有被训练过的类别.
5.5 采用文本搜索图像
最重要的是,可以使用网络的联合嵌入层来使用任何单词搜索图像数据库.
只需从 GloVe 获取预先训练好的单词嵌入层,并找到具有最相似嵌入层的图像.
如,数据集中存在的 dog:
results = vector_search.search_index_by_value(word_vectors["dog"],
image_index,
file_mapping)输出如下:
[578, 'dataset/dog/2008_004931.jpg', 0.3864878714084625][589, 'dataset/dog/2008_005890.jpg', 0.3922061026096344][567, 'dataset/dog/2008_002859.jpg', 0.4144909679889679][568, 'dataset/dog/2008_003133.jpg', 0.4158168137073517][555, 'dataset/dog/2008_000706.jpg', 0.4299579858779907][590, 'dataset/dog/2008_006130.jpg', 0.43139806389808655][576, 'dataset/dog/2008_004760.jpg', 0.4334023892879486][556, 'dataset/dog/2008_000808.jpg', 0.43694719672203064][561, 'dataset/dog/2008_001479.jpg', 0.43990498781204224][574, 'dataset/dog/2008_004653.jpg', 0.44838857650756836]

如, 数据集中未被训练的单词ocean:
results = vector_search.search_index_by_value(word_vectors["ocean"],
image_index,
file_mapping)输出如下:
[191, 'dataset/boat/2008_006720.jpg', 1.0978461503982544][168, 'dataset/boat/2008_003951.jpg', 1.107574462890625][156, 'dataset/boat/2008_001202.jpg', 1.1096670627593994][192, 'dataset/boat/2008_006730.jpg', 1.1217926740646362][198, 'dataset/boat/2008_007841.jpg', 1.1251723766326904][158, 'dataset/boat/2008_001858.jpg', 1.1262227296829224][184, 'dataset/boat/2008_005959.jpg', 1.1270556449890137][173, 'dataset/boat/2008_004969.jpg', 1.1288203001022339][170, 'dataset/boat/2008_004014.jpg', 1.1291345357894897][180, 'dataset/boat/2008_005695.jpg', 1.129249930381775]

如,tree:
results = vector_search.search_index_by_value(word_vectors["tree"],
image_index,
file_mapping)[772, 'dataset/potted_plant/2008_005111.jpg', 1.085968017578125][788, 'dataset/potted_plant/2008_007525.jpg', 1.090157389640808][776, 'dataset/potted_plant/2008_005914.jpg', 1.0998691320419312][775, 'dataset/potted_plant/2008_005874.jpg', 1.1043848991394043][755, 'dataset/potted_plant/2008_001078.jpg', 1.104411005973816][779, 'dataset/potted_plant/2008_006112.jpg', 1.1125234365463257][774, 'dataset/potted_plant/2008_005680.jpg', 1.1161415576934814][789, 'dataset/potted_plant/2008_007621.jpg', 1.1222350597381592][405, 'dataset/chair/2008_001467.jpg', 1.1241838932037354][502, 'dataset/dining_table/2008_000817.jpg', 1.126217246055603]

如,street:
results = vector_search.search_index_by_value(word_vectors["street"],
image_index,
file_mapping)[303, 'dataset/car/2008_000252.jpg', 1.1869385242462158][579, 'dataset/dog/2008_004950.jpg', 1.2010694742202759][72, 'dataset/bicycle/2008_005175.jpg', 1.201261281967163][324, 'dataset/car/2008_004080.jpg', 1.2037224769592285][284, 'dataset/bus/2008_007254.jpg', 1.2040880918502808][741, 'dataset/person/2008_006554.jpg', 1.205135464668274][273, 'dataset/bus/2008_005277.jpg', 1.2077884674072266][274, 'dataset/bus/2008_005360.jpg', 1.211493730545044][349, 'dataset/car/2008_008338.jpg', 1.2118890285491943][260, 'dataset/bus/2008_003321.jpg', 1.214812159538269]

也可以组合多个单词进行搜索,通过平均单词向量:
results = vector_search.search_index_by_value(
np.mean([word_vectors["cat"], word_vectors["sofa"]], axis=0),
image_index, file_mapping)[354, 'dataset/cat/2008_000670.jpg', 0.584483802318573][395, 'dataset/cat/2008_007363.jpg', 0.6164626479148865][352, 'dataset/cat/2008_000227.jpg', 0.6314529180526733][891, 'dataset/sofa/2008_008313.jpg', 0.6323047876358032][880, 'dataset/sofa/2008_006436.jpg', 0.6585681438446045][369, 'dataset/cat/2008_003607.jpg', 0.7039458751678467][386, 'dataset/cat/2008_006081.jpg', 0.7254294157028198][885, 'dataset/sofa/2008_007169.jpg', 0.7283080816268921][350, 'dataset/cat/2008_000116.jpg', 0.7311896085739136][872, 'dataset/sofa/2008_004497.jpg', 0.7487371563911438]
