
往往是训练或微调 LLM,以基于特定的基础知识进行特定任务. 下图示例了不同的微调策略.
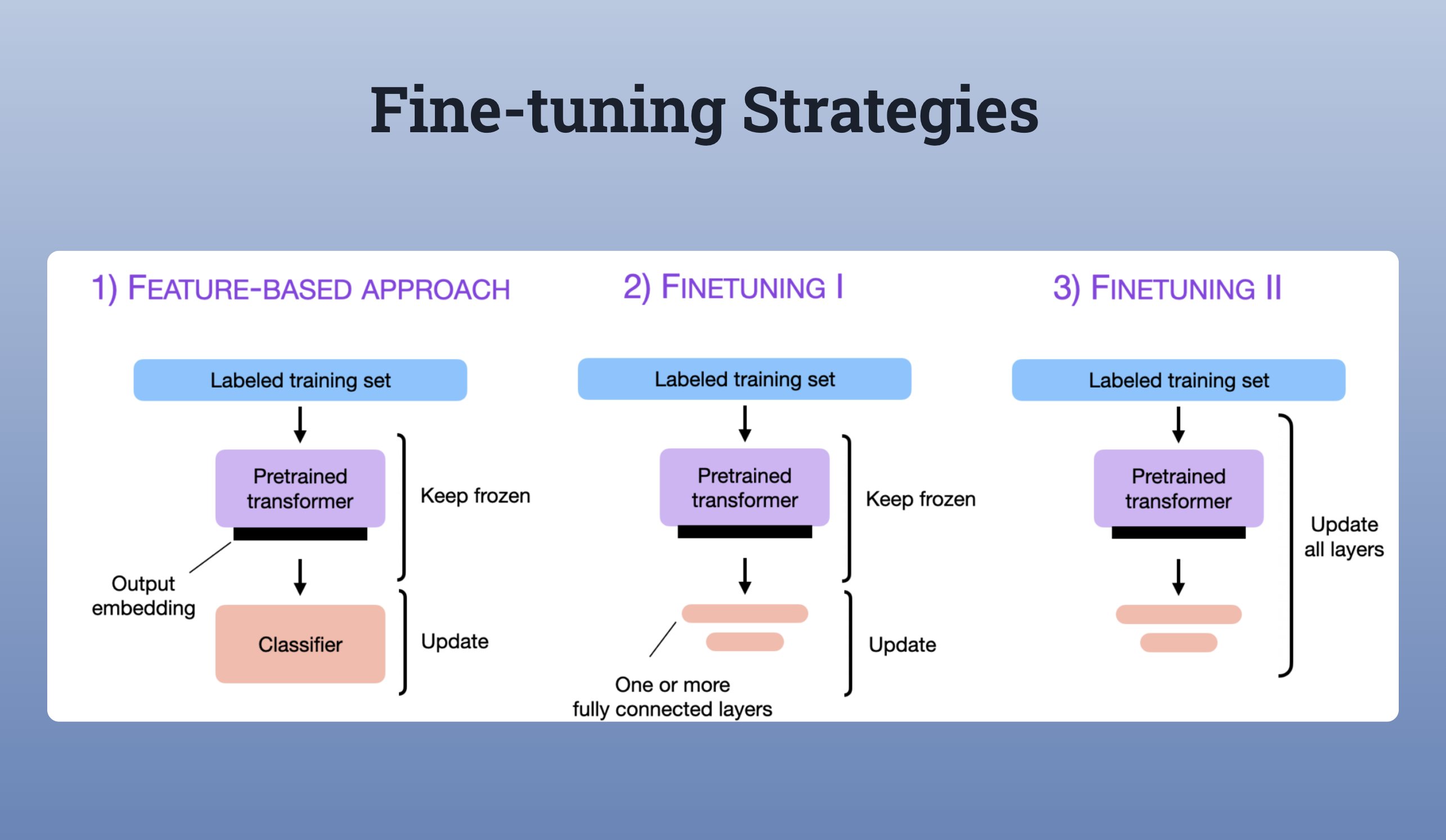
LLMs 很难完全都放进 GPU 显存里. 如果想更新全部的网络层(FineTuning II),因为其能够具有最佳的性能.
Transformer block with adapters
对此,就需要想一些 Parameter efficient 技术. 其中之一是,采用 Transformer block with adapters.
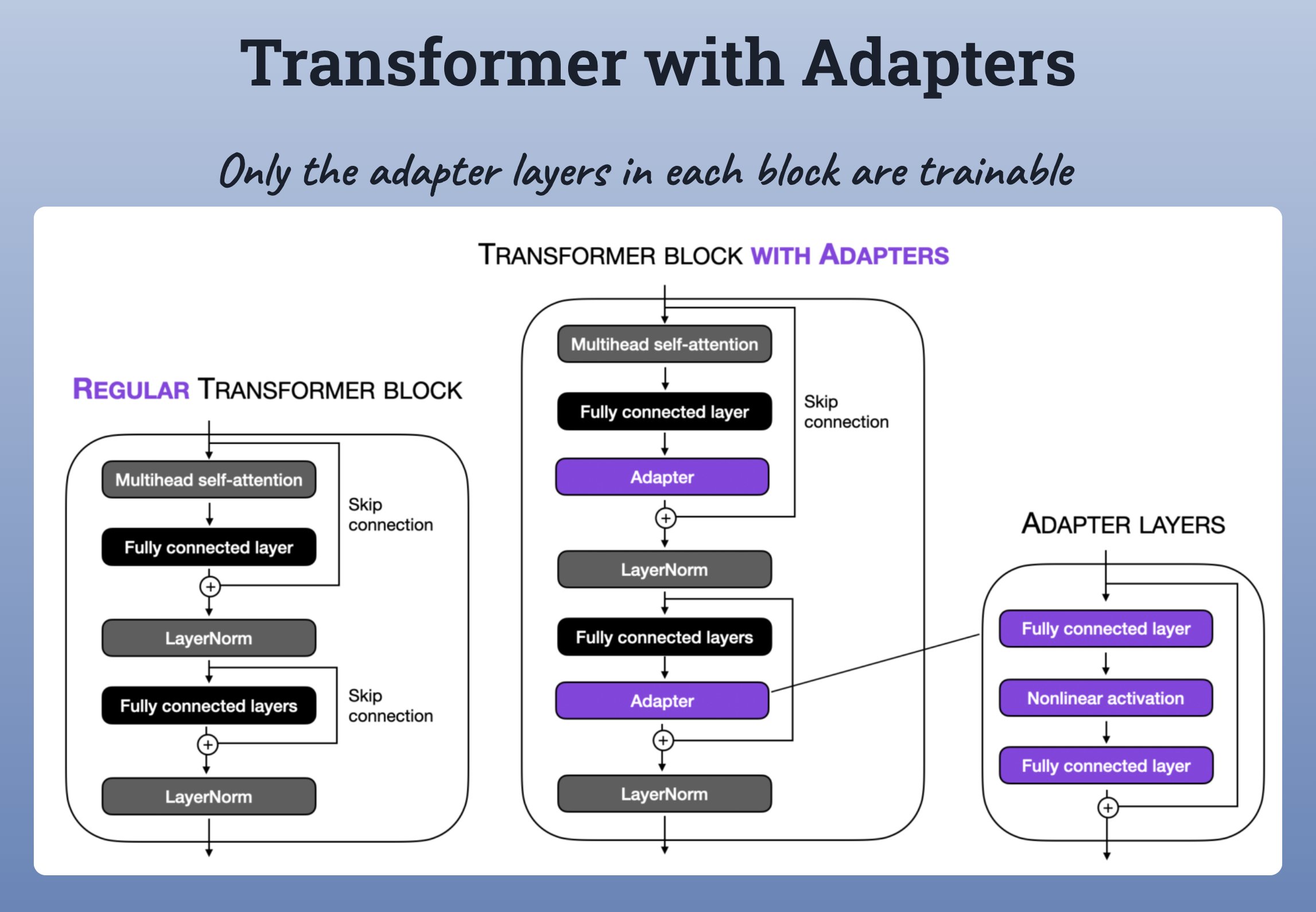
如下是,a transformer block with trainable Adapters.
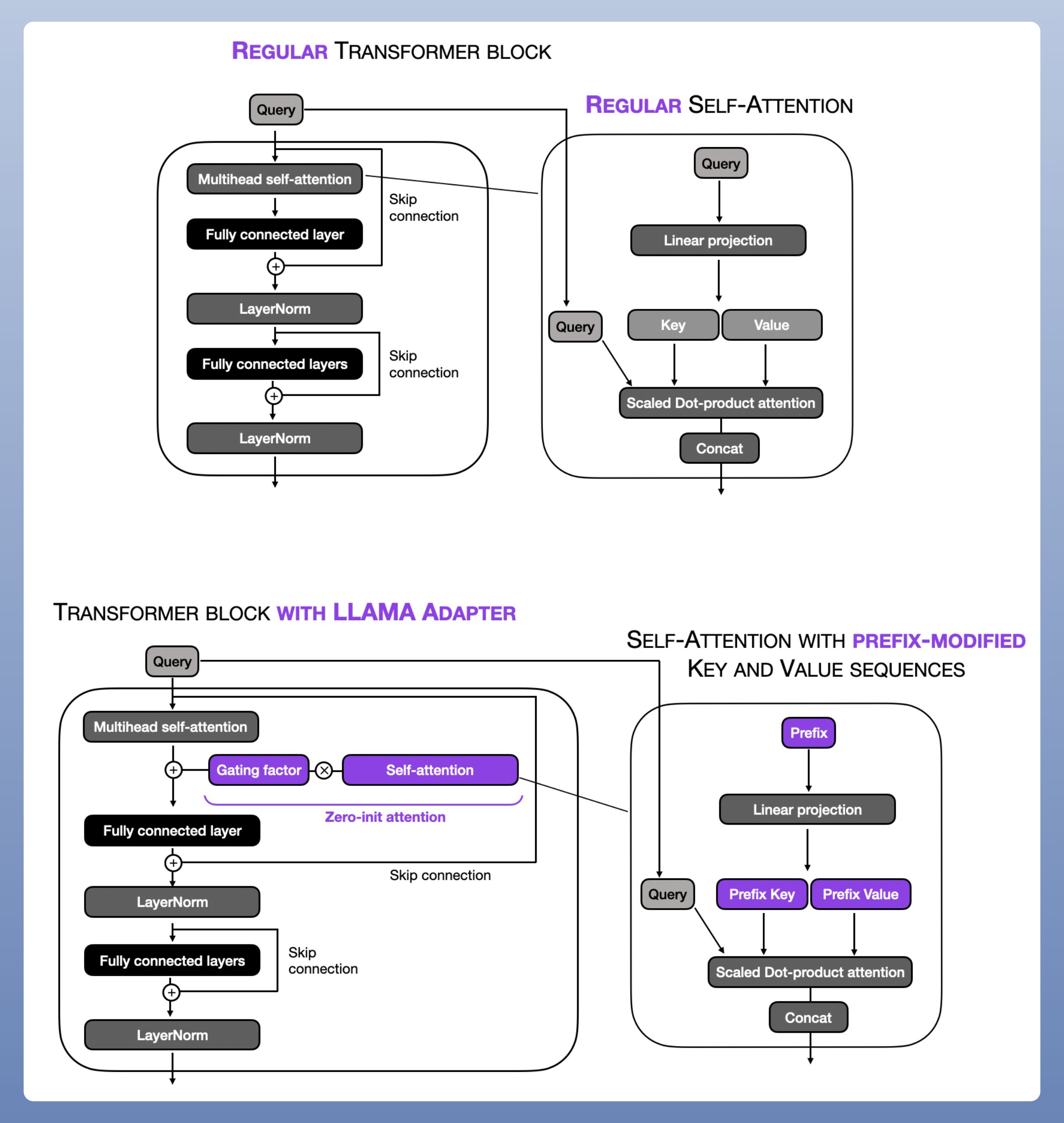
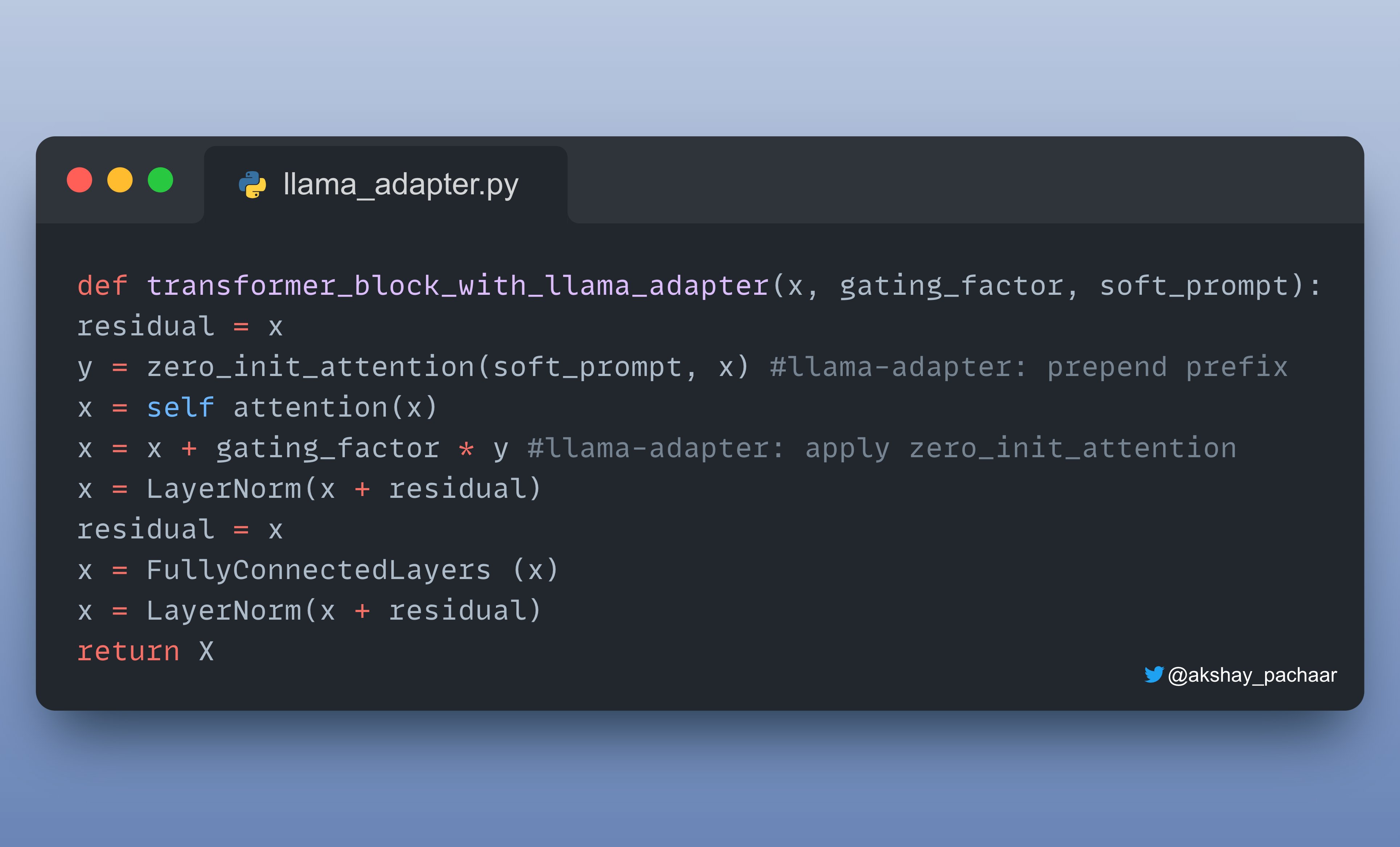
LLaMA-Adapter: Prefix tuning + Adapter
LLaMA-Adapter: Prefix tuning + Adapter,是另一种有效、流行的 Parameter efficient 技术.
https://lightning.ai/pages/community/article/understanding-llama-adapters/
LLaMA-Adapter 方法预先将可调的 prompt tensors 转换成 embedded inputs.
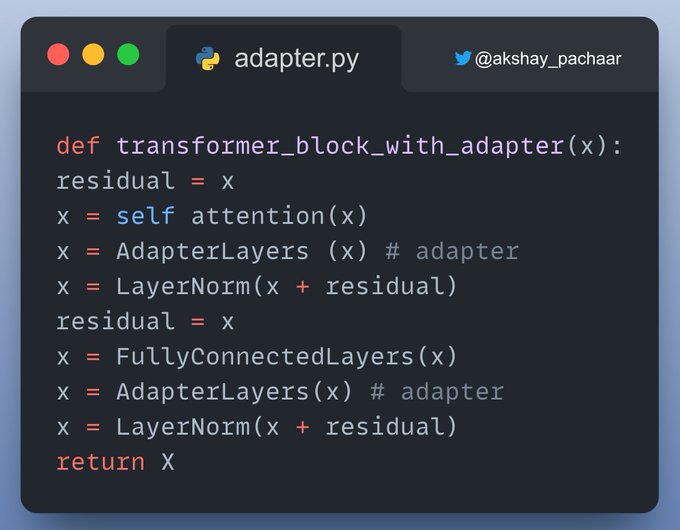
如下是,a LLaMa Adapter 的代码实现.
简而言之, Parameter efficient 技术,相比于全部微调,只需要训练少量参数,即可达到相当的性能表现.