摘自:策略算法工程师之路-基于内容的图像检索
BoW - Bag of Words
SIFT - Scale Invariant Feature Transform,
基于SIFT和CNN特征的通用检索流程 - AIUAI
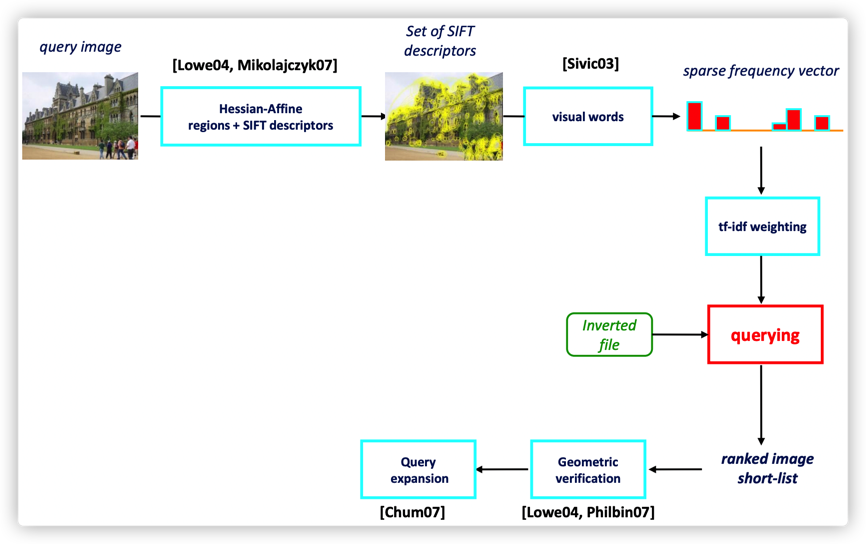
From: https://www.robots.ox.ac.uk/~vgg/publications/2012/Arandjelovic12/presentation.pdf
1. BoW 模型
BoW 模型最初被用在文本分类中,将文档表示成特征矢量.
BoW 模型基本思想是,假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的.
如:
文档1:John likes to watch movies. Mary likes too
文档2:John also likes to watch football games.
对于给定词典:
Vocabulary ={
"John": 1,
"likes":2,
"to": 3,
"watch":4,
"movies":5,
"also":6,
"football":7,
"games":8,
"Mary": 9,
"too": 10 } 上述文档可以表示成:
文档1: [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
文档2: [1, 1,1, 1, 0, 1, 1, 1, 0, 0]

在计算机图像处理中也借鉴了BOW的思想,假设一张图像是有若干视觉词汇组成.

什么样的视觉词典是期望的?
- 光照不敏感
- 尺度不敏感
- 视角变化不敏感
- 旋转不变
- ...
2. SIFT
SIFT特征之杂七杂八解析 - AIUAI
SIFT 算法简单来讲,可分为以下几步:
2.1. 多分辨率图像金字塔
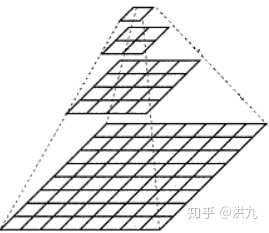
想象人从不同距离看同一个事物,不同尺度的同一个事物从不同视角反映了事物的本质. 距离越远尺度越小更反映事物的全局特性,相反更反映事物的局部特性.
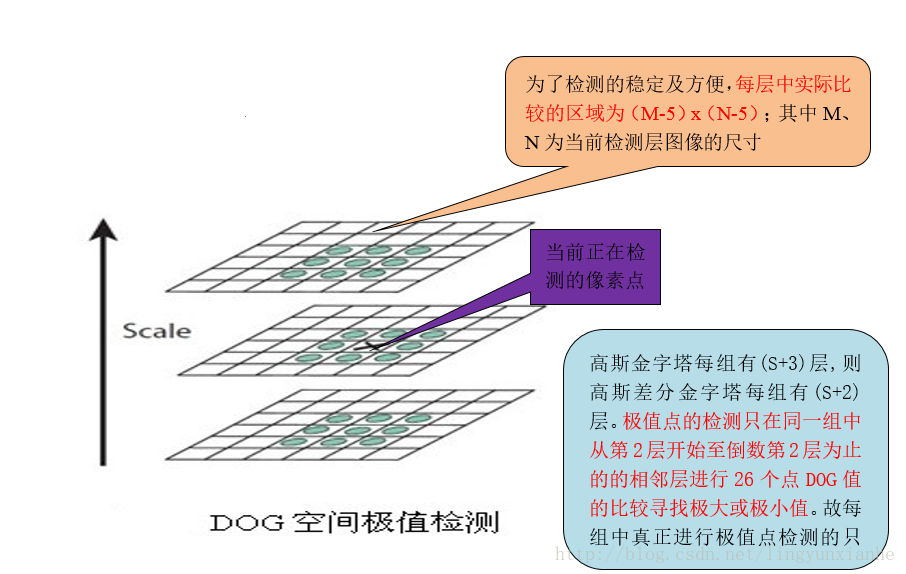
2.2. 极值点检测
为了寻找尺度空间的极值点,每个像素点要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,改点就是极值点.
如图所示,中间的检测点要和其所在图像的3×3邻域8个像素点,以及其相邻的上下两层的3×3领域18个像素点,共26个像素点进行比较.
2.3. 特征点梯度直方图生成
通过对特征点周围的像素进行分块,计算块内梯度直方图,生成具有独特性的向量,这个向量是该区域图像信息的一种抽象,具有唯一性.
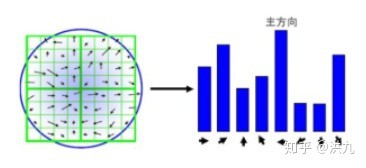
得到的梯度直方图就是最后SIFT特征向量.
SIFT特征点的检测实例如图:

3. SIFT 特征构建 BoW
对提取的SIFT特征点K-means聚类:

如下三个Cluster:
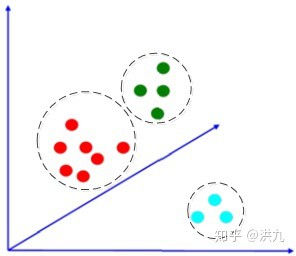
如此,每个Cluster的中心即是需要的视觉词典(Visual Vocabulary),如下:
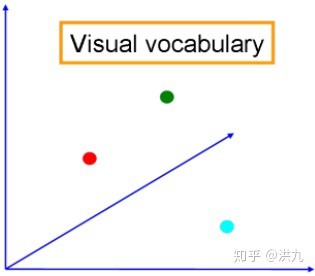
对图像检测出的SIFT特征点,指派给离它最近的中心点(将这一步称为hard-assignment),如此得到图像的视觉词汇分布.
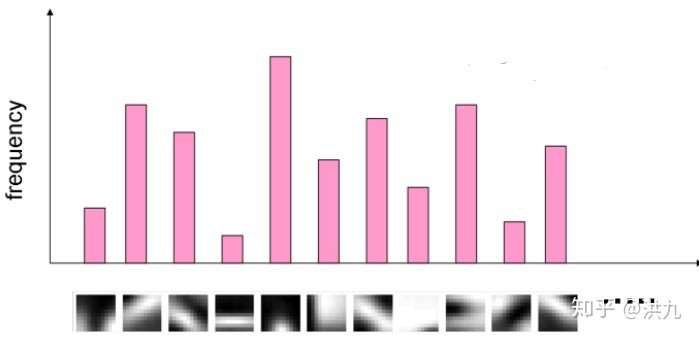
基于BOW的图像检索算法可以描述如下:
[1] - 提取图像库中所有图像的局部特征(如SIFT、SURF、ORB等),得到特征集合 $F$.
[2] - 对特征集合 $F$ 进行聚类,得到 $k$ 个聚类中心 $\lbrace C_i | i = 1,...,k \rbrace$,每个聚类中心 $C_i$ 表示一个视觉词汇. 聚类中心的集合就是视觉词典.
[3] - 计算特征 $f_i$ 属于哪个词汇 $C_i$(距离该聚类中心的距离最近.)
[4] - 统计每个词汇 $C_i$ 在各图像中出现的频次,得到一维的特征向量,即 BoW 表示.
基于BOW的方法仅仅关注图像的局部特征而忽略了图像的全局语义,导致会召回不少语义差异较大的图像.
4. Python 实现
import cv2
import numpy as np
from sklearn.cluster import KMeans
from scipy.cluster.vq import *
from sklearn import preprocessing
from PIL import Image
#加载数据集
imgFiles = ['1.jpg', '2.jpg', '3.jpg', '4.jpg', '5.jpg']
#聚类中心数/视觉词典数
numWords = 64
#提取图像SIFT特征
sift = cv2.xfeatures2d.SIFT_create()
des_list=[]
for i in range(0, len(imgFiles)):
img=cv2.imread(imgFiles[i])
#转换成灰度图像
gray=cv2.cvtColor(img,cv2.COLOR_RGB2GRAY)
#sift
kp, des = sift.detectAndCompute(gray,None)
#kp, des = sift.detectAndCompute(img1, None)
des_list.append((image_path, des))
#视觉词典生成
#生成向量数组(堆叠所有sift特征,以进行 K-means聚类)
descriptors = des_list[0][1]
for image_path, descriptor in des_list[1:]:
descriptors = np.vstack((descriptors, descriptor))
#K-means聚类生成视觉词典
print("开始K-means聚类: %d words, %d key points" %(numWords, descriptors.shape[0]))
voc, variance = kmeans(descriptors, numWords, 1)
#图像视觉单词抽取
im_features = np.zeros((len(image_paths), numWords), "float32")
for i in range(0,len(imgFiles)):
#将图像的SIFT特征转换成视觉单词分布
words, distance = vq(des_list[i][1],voc)
for w in words:
#单张图像单词出现频次统计
im_features[i][w] += 1
#Tf-Idf计算
#统计idf
nbr_occurences = np.sum((im_features > 0) * 1, axis = 0)
idf = np.array(np.log((1.0*len(imgFiles)+1) / (1.0*nbr_occurences + 1)), 'float32')
# tf*idf
im_features = im_features*idf
# L2 归一化
im_features = preprocessing.normalize(im_features, norm='l2')
#查询
#读取图像
query = imgFiles[idx]
im = cv2.imread(query)
# 提取图像sift特征
des_list = []
gray = cv2.cvtColor(im, cv2.COLOR_RGB2GRAY)
kp, des = sift_det.detectAndCompute(gray, None)
des_list.append((image_path, des))
descriptors = des_list[0][1]
# 抽取图像Tf-Idf特征
test_features = np.zeros((1, numWords), "float32")
words, distance = vq(descriptors,voc)
for w in words:
test_features[0][w] += 1
test_features = test_features*idf
# 归一化
test_features = preprocessing.normalize(test_features, norm='l2')
# 计算所有图像的相似度
scores = np.dot(test_features, im_features.T)
rank_ID = np.argsort(-scores)
# 输出Top最相似的图像
for i, ID in enumerate(rank_ID[0][0:20]):
img = Image.open(imgFiles[ID])
plt.imshow(img)
plt.show()
1 条评论
image_path是啥