From: https://twitter.com/akshay_pachaar/status/1657368551471333384
Attention 是 LLMs 的核心之一.
NLP 中,将 words sequences 转换为 token,然后将 token 转换为 embeddings.
embedding 可以看做是采用一堆数字来对每个 token 的有意义的表示. 如图:

而对于语言模型来说,是对人类层次的理解,分别独立的处理 tokens 是难以做到的. 还需要理解 tokens 之间的关系.

在 Self-Attention 中,tokens 之间的关系表示为概率分数. 每个 token 分配最高的分数给其自己,基于相关性给于其他 tokens 分数.
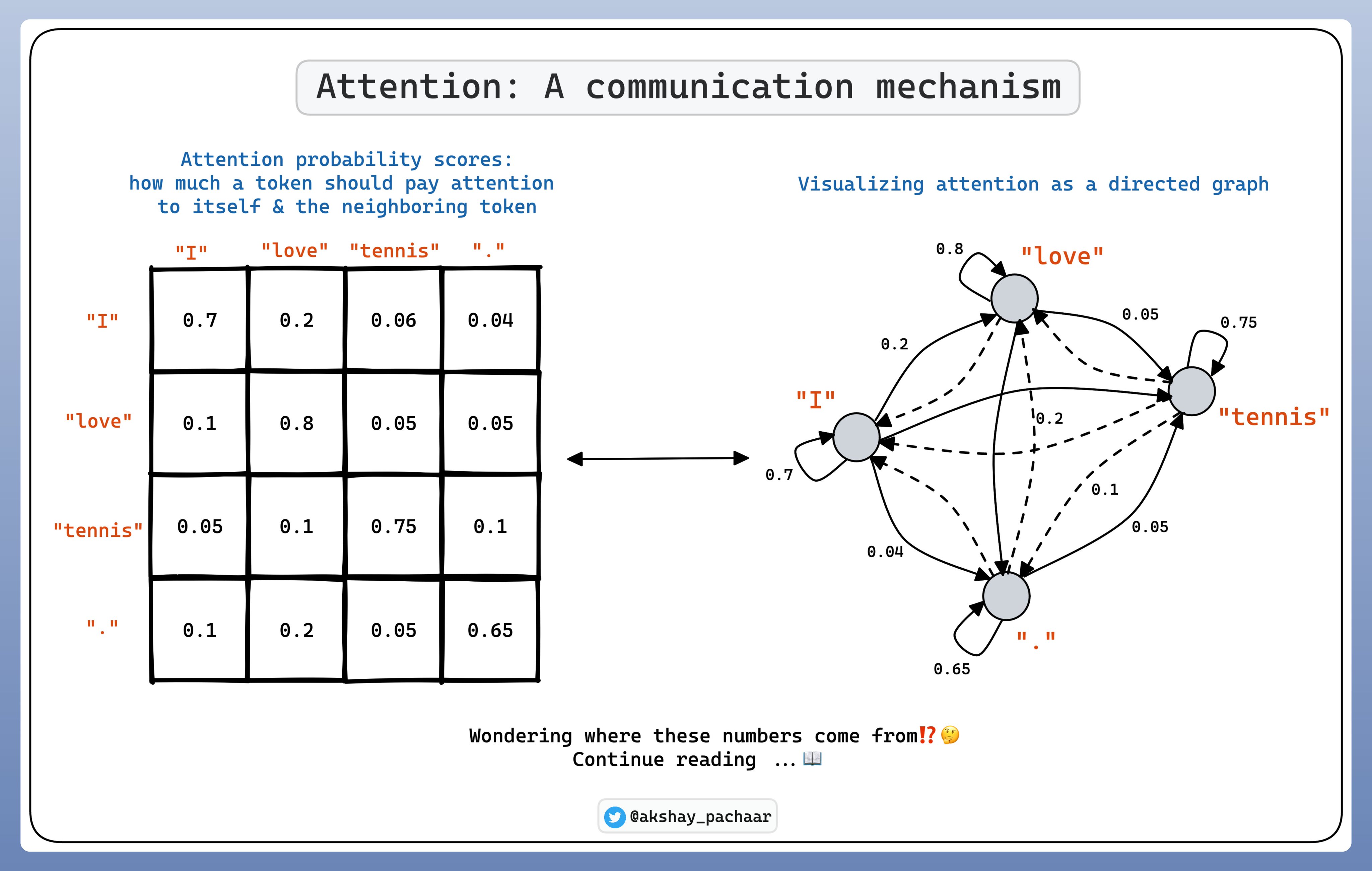
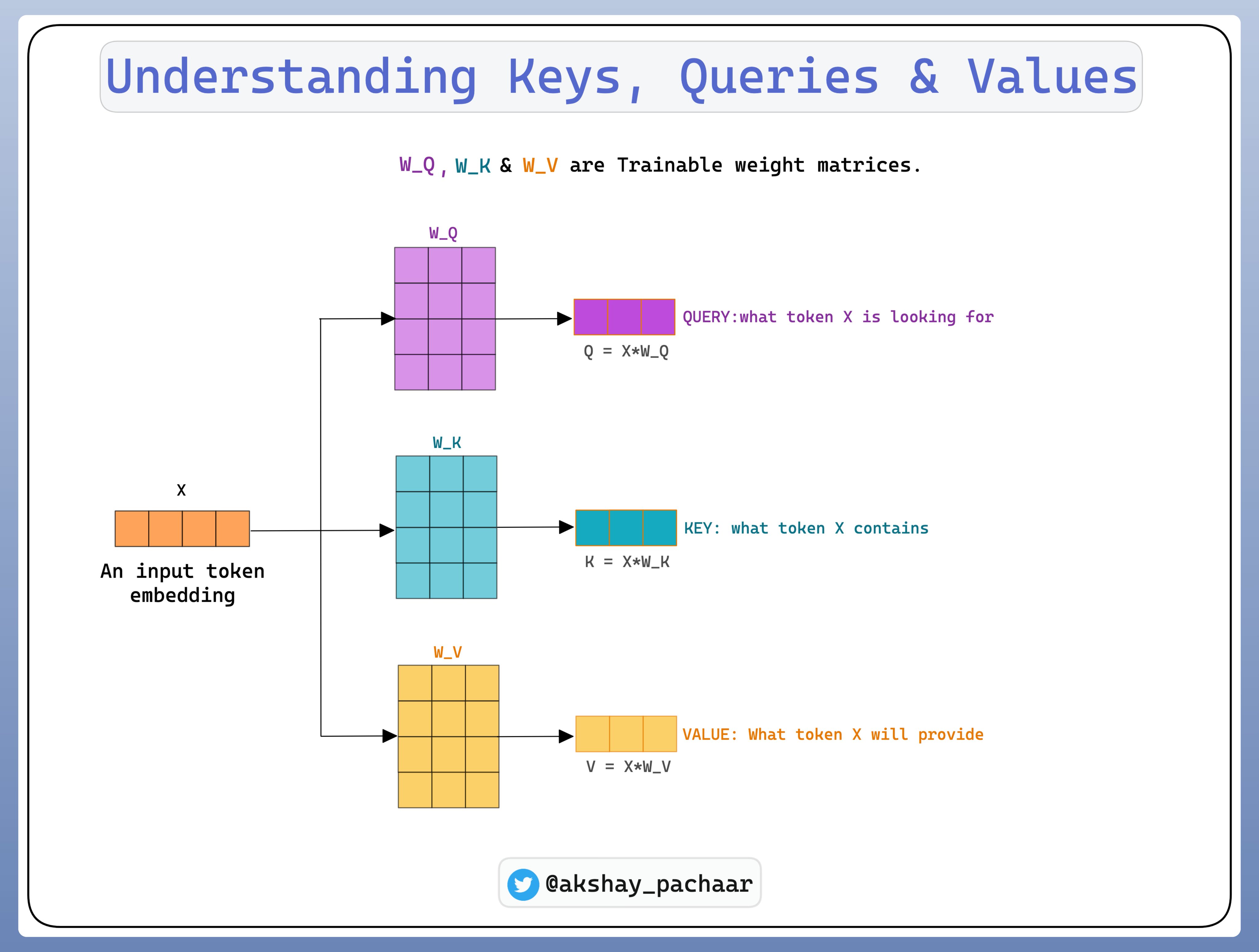
为了理解 self-attention 是如何进行的,首先需要理解三个概念:
- Query Vector
- Key Vector
- Value Vector
这些向量是通过对 input embedding 乘以三个可训练的权重矩阵来得到的.
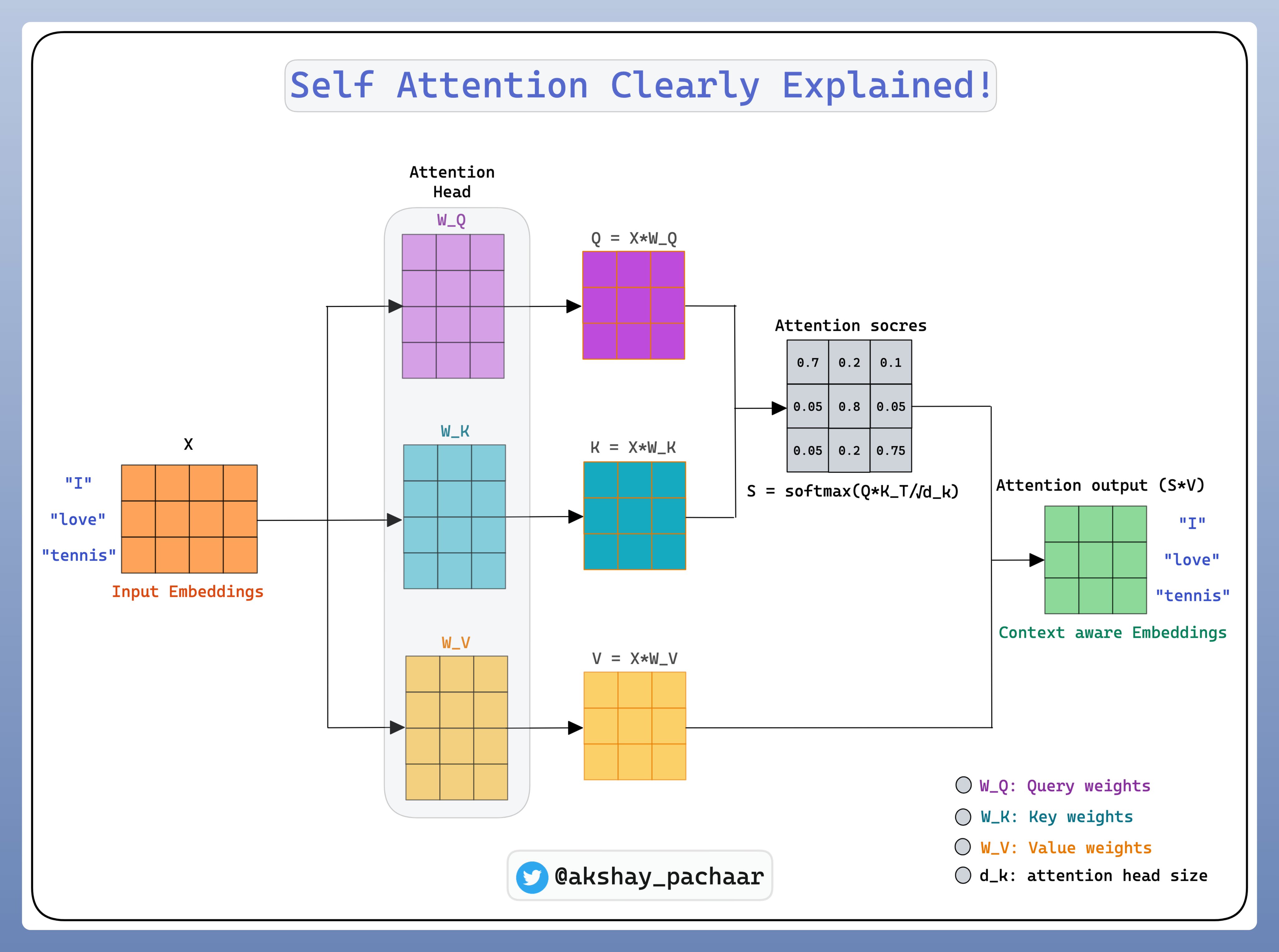
Self-attention 可以让模型学习到序列中不同部分之间长范围的依赖(long-range dependencies).
当得到 keys, queries 和 values 之后,将其合并,以创建新的 context-aware embeddings 集合.
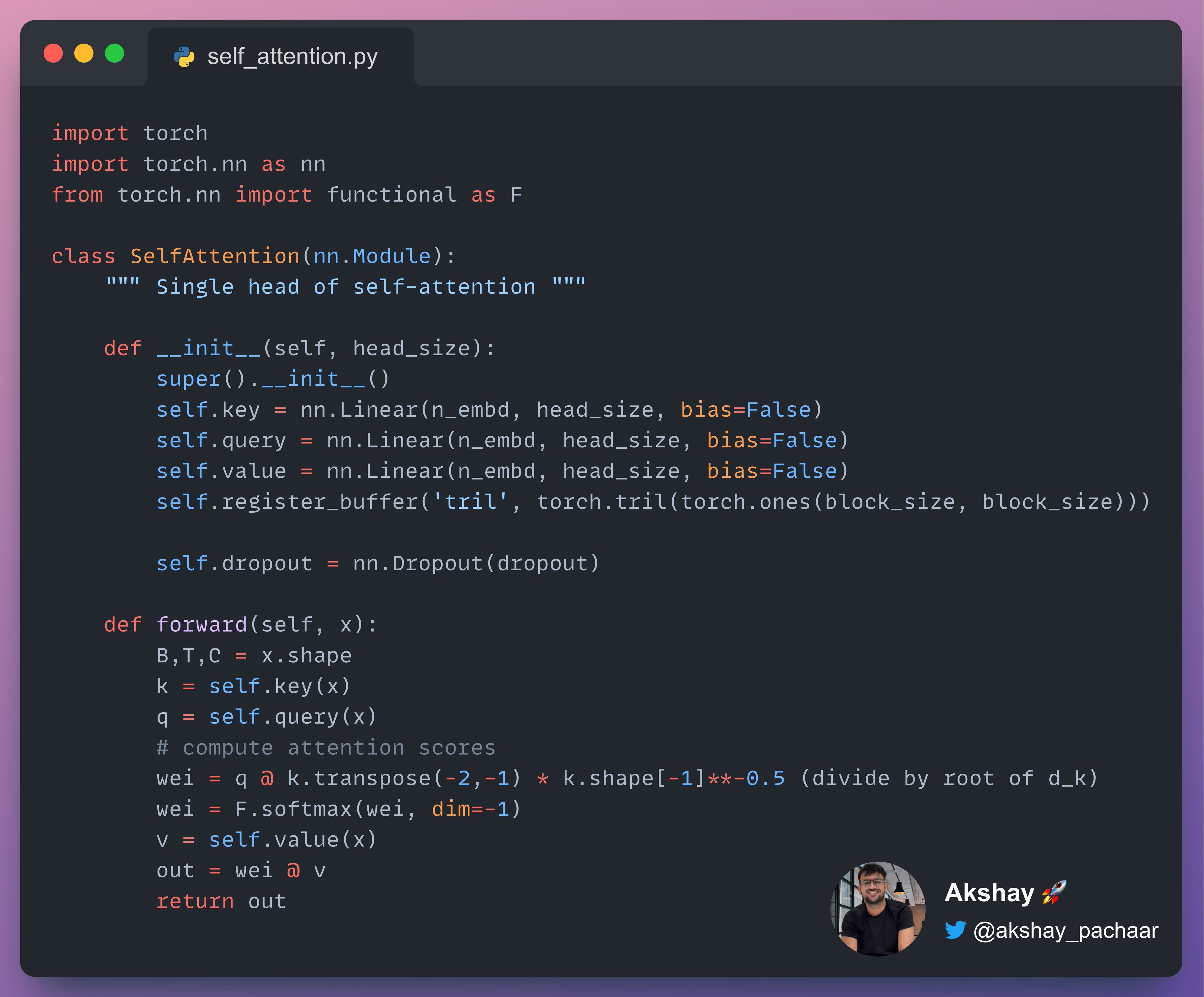
PyTorch 中 Self-Attention 的实现示例如,