作者:Yuying Ge, Ruimao Zhang, Xiaogang Wang, Xiaoou Tang, Ping Luo
团队:The Chinese University of Hong Kong
DeepFashion2 数据集是一个更加综合的服装数据集,其包含了适用于服装检测、服装姿态估计、服装分割以及服装检索等场景的图片与标注数据.

1. DeepFashion2 数据集
1.1. DeepFashion2 数据集概况
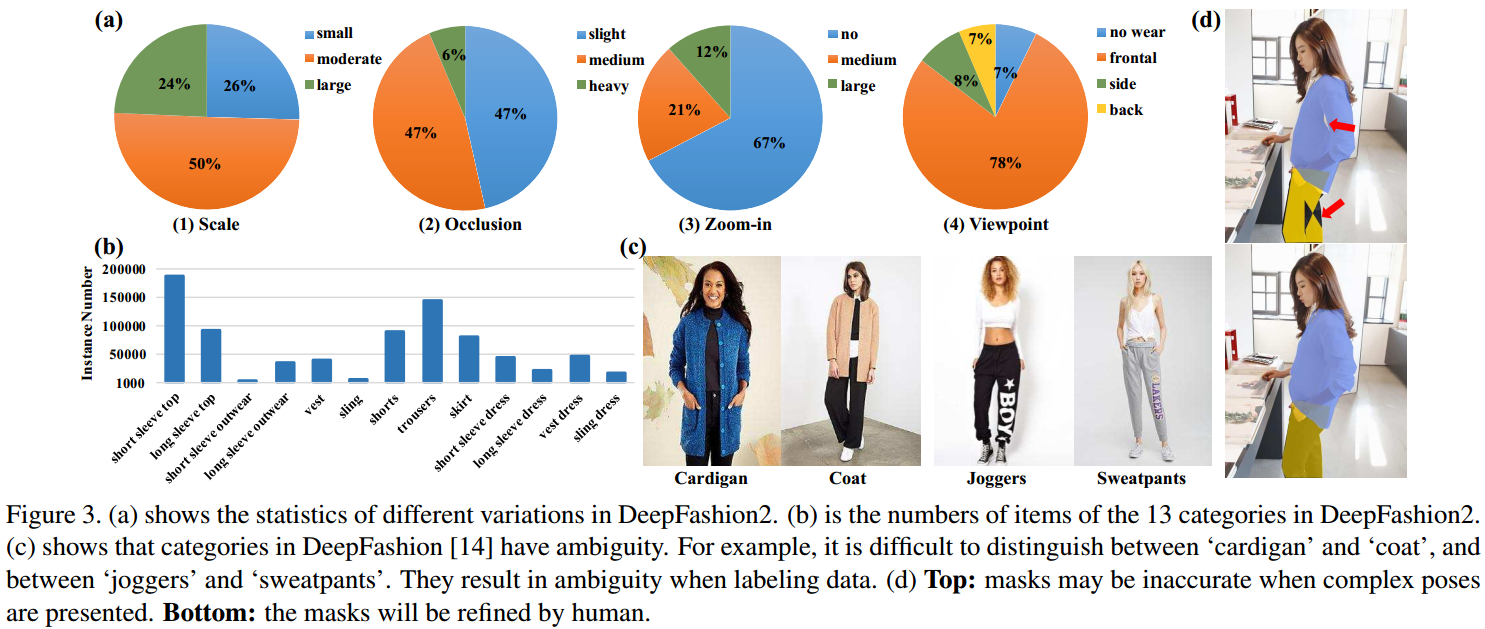
DeepFashion2 共包含 491K 张图片,13 个常见服装类目,收集自电商和用户.
DeepFashion2 共包含 801K 个服装主体,图片中每个服装主体的标注信息包括:
[1] - scale 尺度:
根据服装主体相对于图像尺寸的比例,包含三种尺度:small(< 10%), moderate(10% ∼ 40%), large(> 40%) .
[2] - occlusion 遮挡
遮挡表示的是,如果服装主体的区域被头发、肢体、配饰或者其它物体所遮挡,导致的服装主体有一定的不完整.
每个服装主体根据其关键点缺失的数量进行归类为:partial occlusion(< 20% occluded keypoints), heavy
occlusion(> 50% occluded keypoints), medium occlusion(otherwise).
注:服装主体超出图片不适于 occlusion.
[3] - zoom-in 放大
服装主体被标注为 zoom-in,表示其区域超出了图片. 根据超出图片的关键点数量进行归类为:no, large(> 30%, medium.
[4] - viewpoint 视角
数据集中的服装主体被归类为 4 中视角:7% clothes that are not on people, 78% clothes on people from frontal viewpoint, 15% clothes on people from side, back viewpoint.
[5] - category 类目
根据对 DeepFashion 的 50 个类目进行归组,得到 13 个类目:short sleeve top, long sleeve top, short sleeve outwear, long sleeve outwear, vest, sling(吊带), shorts, trousers, skirt, short sleeve dress, long sleeve dress, vest dress, sling dress.
[6] - bounding box 边界框
[7] - dense landmarks 关键点
[8] - per-pixel mask 像素级 mask
[9] - style 风格
DeepFashion2 还包含了 873K 组 Commercial-Consumer 服装搭配组.
DeepFashion2 中,training 数据集 391K 张图片,validation 数据集 34K 张图片,test 数据集 67K 张图片.
例图,如:

1.2. DeepFashion2 数据集下载
谷歌Drive:https://drive.google.com/drive/folders/125F48fsMBz2EF0Cpqk6aaHet5VH399Ok?usp=sharing
解压密码:需要填写表格申请,链接 - https://docs.google.com/forms/d/e/1FAIpQLSeIoGaFfCQILrtIZPykkr8q_h9qQ5BoTYbjvf95aXbid0v2Bw/viewform?usp=sf_link
Second Workshop on Computer Vision for Fashion, Art and Design
1.3. DeepFashion2 数据集统计
| Train | Validation | Test | Overall | |
|---|---|---|---|---|
| images | 390,884 | 33,669 | 67,342 | 491,895 |
| bboxes | 636,624 | 54,910 | 109,198 | 800,732 |
| landmarks | 636,624 | 54,910 | 109,198 | 800,732 |
| masks | 636,624 | 54,910 | 109,198 | 800,732 |
| pairs | 685,584 | query: 12,550 gallery: 37183 | query: 24,402 gallery: 75,347 | 873,234 |
2. DeepFashion2 数据组织形式
每张图片的图片名是由六位数字组成,如 000001.jpg. 其对应的 json 标注文件为 000001.json.
每个 json 标注数据的组织形式为:
|---- source,string,表示图片是来自于电商(shop)还是用户(user).
|---- pair_id,number. 同一家 shop 的图片和对应的用户所购买的图片,具有相同的 pair id.
|-------- item 1
|------------ category_name,string,服装类目名
|------------ category_id,number,对应与服装类目名.
|------------ style,number,用于区分具有相同 pair id 的图片的服装主体.具有相同 pair id 的图片的服装主体 的 style numbers 不同时,其 style 是不同的,如 color, printing, logo 等.
|------------ bounding_box,[x1, y1, x2, y2],依次为边界框的左下(lower left) 和右上(upper right) 点的坐标值.
|------------ landmarks,[x1, y1, v1, ..., xn, yn, vn],其中 v 表示可见性:v=2 visible; v=1 occlusion; v=0 not labeled.
|------------ segmentation,[[x1, y1, ..., xn, yn], []],其中,[x1, y1, xn, yn] 表示多边形标注,单一服装主体可能包含多个多边形(polygon)标注.
|------------ scale,number,1-small; 2-modest; 3-large.
|------------ occlusion,number,1-slight occlusion(no occlusion); 2-medium occlusion; 3-heavy occlusion.
|------------ zoom_in,number,1-no zoom-in; 2-medium zoom-in; 3-large zoom-in.
|------------ viewpoint,number,1-no wear; 2-front viewpoint; 3-side of back viewpoint.
|-------- item 2
|-------- item n
注:pair_id 和 source 是图片级的标注. 同一张图片的所有服装主体具有相同的 pair_id 和 source.
2.1. 服装类目名与对应id
category_name 和 category_id 的对应关系如下:
1 - short sleeve top
2 - long sleeve top
3 - short sleeve outwear
4 - long sleeve outwear
5 - vest
6 - sling
7 - shorts
8 - trousers
9 - skirt
10 - short sleeve dress
11 - long sleeve dress
12 - vest dress
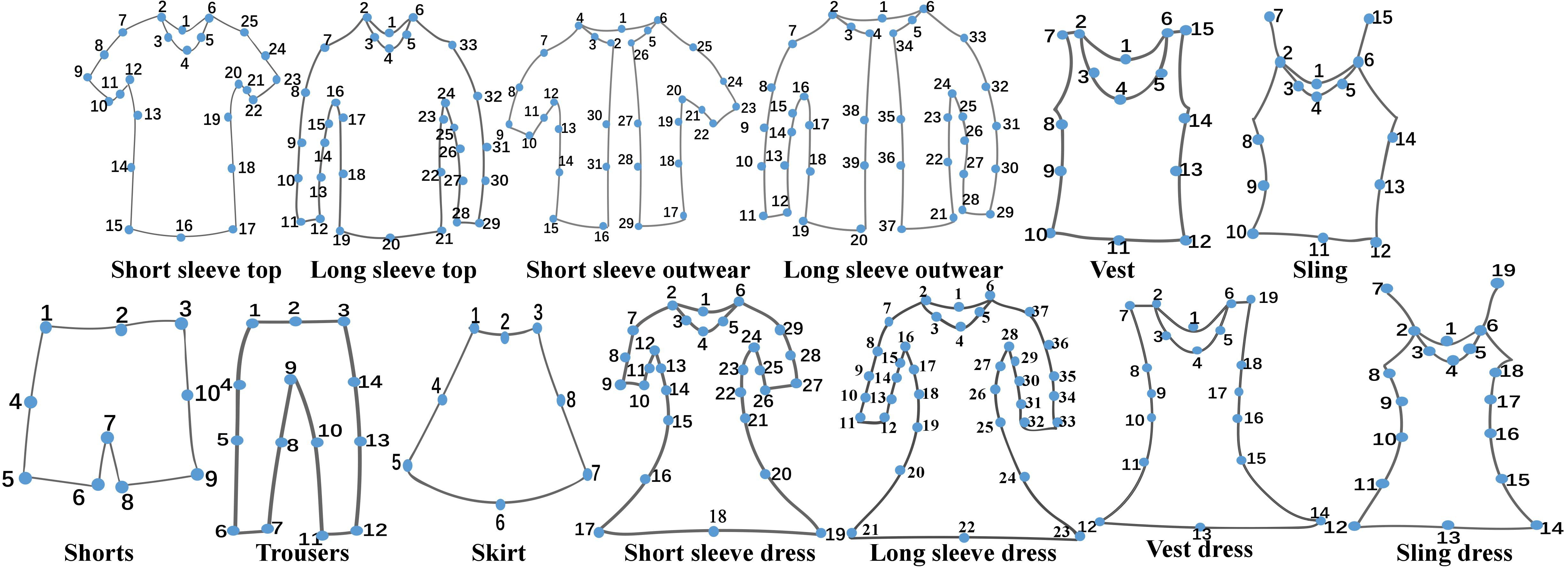
13 -sling dress2.2. 服装 landmarks 次序
13 种服装类目的 landmarks 和 skeletons 的表示如图.
图中的数字表示在标注文件中,每个服装类目的 landmarks 标注的词序.
13 种服装类目共定义了 294 个 landmarks.
2.3. 服装 pairs 说明
DeepFashion2 数据集中,图片是以连续的 paird_id 进行组织的,其同时包括用户和商店来源的图片. 例如:
000001.jpg(pair_id:1; from consumer),
000002.jpg(pair_id:1; from shop),
000003.jpg(pair_id:2; from consumer),
000004.jpg(pair_id:2; from consumer),
000005.jpg(pair_id:2; from consumer),
000006.jpg(pair_id:2; from consumer),
000007.jpg(pair_id:2; from shop),
000008.jpg(pair_id:2; from shop)
...对于 shop 图片和 consumer 图片的两个服装主体,如果其具有相同的 style number(大于0),且其来自具有相同 pair_id 的图片,则这两个服装主体是 positive commerical-consumer pair;否则,这两个服装主体shi negative commerical-consumer pairs. 据此,可以构建实例级的 positive pairs 和 negative pairs,以用于训练.
例如下图中:前三张图片来自 consumers,最后两张来自于 shops. 这五张图片具有相同的 pair_id. 橙色框的服装主体具有相同的 style: 1;绿色框的服装主体具有相同的 style: 2. 其它未画出边界框的服装主体的 style 是 0,其不能用于构建 positive commerical-consumer pairs. 一组 positive commerical-consumer pair 是在第一张图片中标注的 short sleeve top 和最后一张图片中标注的 short sleeve top.
因此,DeepFashion2 数据集可以很灵活的用于构建实例级(instance-level)的pairs.

2.4. DeepFashion2 数据集划分
下载后的数据集组织形式为:
|---- train
|-------- image 训练图片数据
|-------- annos 训练标注数据
|---- validation
|-------- image 验证图片数据
|-------- annos 验证标注数据
|---- test
|-------- image 测试图片数据
[1] - DeepFashion2 数据集中,每张图片的图片名是由六位数字组成,如 000001.jpg;其对应的 json 标注文件为 000001.json.
[2] - DeepFashion2 数据集提供了将数据组织为 COCO 格式的脚本 - deepfashion2_to_coco.py.
[3] - DeepFashion2 的 validation 数据集提供了图片级的数据信息 - keypoints_val_information.json,retrieval_val_consumer_information.json 和 retrieval_val_shop_information.json(前 10844 张图片来自 consumers ,后 20681 张图片来自 shops). 对于服装检测任务和语义分割任务,也可以采用 keypoints_val_information.json.
[4] - DeepFashion2 数据集还提供了 keypoints_val_vis.json, keypoints_val_vis_and_occ.json, val_query.json 和 val_gallery.json,以用于 validation 数据集的评测.
DeepFashion2 - Evaluation
[5] - DeepFashion2 的 test 数据集提供了图片集的数据信息 - keypoints_test_information.json, retrieval_test_consumer_information.json 和 retrieval_test_shop_information.json(前 20681 张图片来自 consumers,后 41984 张图片来自于 shops).
2.5. deepfashion2_to_coco.py
deepfashion2_to_coco.py
import json
from PIL import Image
import numpy as np
dataset = {
"info": {},
"licenses": [],
"images": [],
"annotations": [],
"categories": []
}
dataset['categories'].append({
'id': 1,
'name': "short_sleeved_shirt",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 2,
'name': "long_sleeved_shirt",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 3,
'name': "short_sleeved_outwear",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 4,
'name': "long_sleeved_outwear",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 5,
'name': "vest",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 6,
'name': "sling",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 7,
'name': "shorts",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 8,
'name': "trousers",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 9,
'name': "skirt",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 10,
'name': "short_sleeved_dress",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 11,
'name': "long_sleeved_dress",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 12,
'name': "vest_dress",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
dataset['categories'].append({
'id': 13,
'name': "sling_dress",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186', '187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200', '201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214', '215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228', '229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242', '243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256', '257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270', '271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284', '285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
})
sub_index = 0 # the index of ground truth instance
for num in range(1,num_images+1):
json_name = '/path/to/val_annos/' + str(num).zfill(6)+'.json'
image_name = '/path/to/val/' + str(num).zfill(6)+'.jpg'
if (num>=0):
imag = Image.open(image_name)
width, height = imag.size
with open(json_name, 'r') as f:
temp = json.loads(f.read())
pair_id = temp['pair_id']
dataset['images'].append({
'coco_url': '',
'date_captured': '',
'file_name': str(num).zfill(6) + '.jpg',
'flickr_url': '',
'id': num,
'license': 0,
'width': width,
'height': height
})
for i in temp:
if i == 'source' or i=='pair_id':
continue
else:
points = np.zeros(294 * 3)
sub_index = sub_index + 1
box = temp[i]['bounding_box']
w = box[2]-box[0]
h = box[3]-box[1]
x_1 = box[0]
y_1 = box[1]
bbox=[x_1,y_1,w,h]
cat = temp[i]['category_id']
style = temp[i]['style']
seg = temp[i]['segmentation']
landmarks = temp[i]['landmarks']
points_x = landmarks[0::3]
points_y = landmarks[1::3]
points_v = landmarks[2::3]
points_x = np.array(points_x)
points_y = np.array(points_y)
points_v = np.array(points_v)
if cat == 1:
for n in range(0, 25):
points[3 * n] = points_x[n]
points[3 * n + 1] = points_y[n]
points[3 * n + 2] = points_v[n]
elif cat ==2:
for n in range(25, 58):
points[3 * n] = points_x[n - 25]
points[3 * n + 1] = points_y[n - 25]
points[3 * n + 2] = points_v[n - 25]
elif cat ==3:
for n in range(58, 89):
points[3 * n] = points_x[n - 58]
points[3 * n + 1] = points_y[n - 58]
points[3 * n + 2] = points_v[n - 58]
elif cat == 4:
for n in range(89, 128):
points[3 * n] = points_x[n - 89]
points[3 * n + 1] = points_y[n - 89]
points[3 * n + 2] = points_v[n - 89]
elif cat == 5:
for n in range(128, 143):
points[3 * n] = points_x[n - 128]
points[3 * n + 1] = points_y[n - 128]
points[3 * n + 2] = points_v[n - 128]
elif cat == 6:
for n in range(143, 158):
points[3 * n] = points_x[n - 143]
points[3 * n + 1] = points_y[n - 143]
points[3 * n + 2] = points_v[n - 143]
elif cat == 7:
for n in range(158, 168):
points[3 * n] = points_x[n - 158]
points[3 * n + 1] = points_y[n - 158]
points[3 * n + 2] = points_v[n - 158]
elif cat == 8:
for n in range(168, 182):
points[3 * n] = points_x[n - 168]
points[3 * n + 1] = points_y[n - 168]
points[3 * n + 2] = points_v[n - 168]
elif cat == 9:
for n in range(182, 190):
points[3 * n] = points_x[n - 182]
points[3 * n + 1] = points_y[n - 182]
points[3 * n + 2] = points_v[n - 182]
elif cat == 10:
for n in range(190, 219):
points[3 * n] = points_x[n - 190]
points[3 * n + 1] = points_y[n - 190]
points[3 * n + 2] = points_v[n - 190]
elif cat == 11:
for n in range(219, 256):
points[3 * n] = points_x[n - 219]
points[3 * n + 1] = points_y[n - 219]
points[3 * n + 2] = points_v[n - 219]
elif cat == 12:
for n in range(256, 275):
points[3 * n] = points_x[n - 256]
points[3 * n + 1] = points_y[n - 256]
points[3 * n + 2] = points_v[n - 256]
elif cat == 13:
for n in range(275, 294):
points[3 * n] = points_x[n - 275]
points[3 * n + 1] = points_y[n - 275]
points[3 * n + 2] = points_v[n - 275]
num_points = len(np.where(points_v > 0)[0])
dataset['annotations'].append({
'area': w*h,
'bbox': bbox,
'category_id': cat,
'id': sub_index,
'pair_id': pair_id,
'image_id': num,
'iscrowd': 0,
'style': style,
'num_keypoints':num_points,
'keypoints':points.tolist(),
'segmentation': seg,
})
json_name = '/path/to/deepfashion2.json'
with open(json_name, 'w') as f:
json.dump(dataset, f)3. DeepFashion2 数据集对比
[1] - 对比 DeepFashion 数据集:

图:(a) DeepFashion 数据集,每张图片只标注了单个服装主体,一般是 4-8 个关键点. 边界框是根据标注的关键点估计得到,噪声比较多. (b) DeepFashion2 数据集,每张图片最少标注一个服装主体,最多 7 个主体. 每个服装主体手工标注了边界框、mask、关键点(每个主体平均 20 个关键点) 以及 commercial-customer 图片对.
[2] - 对比多个服装相关数据集
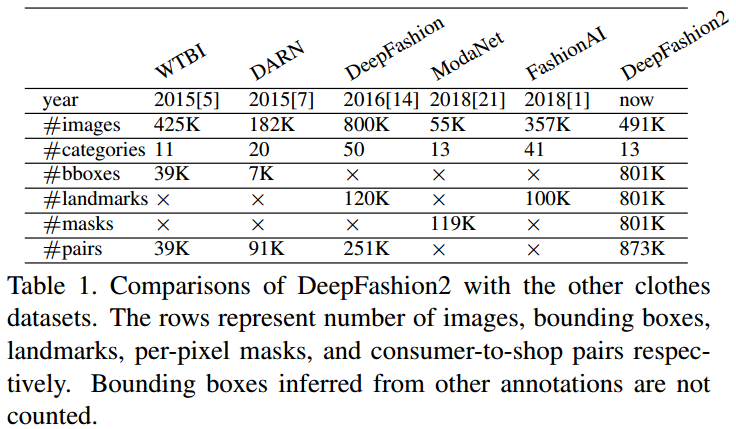
DeepFashion2 数据集的标注至少是 DeepFashion 的 3.5X 倍,是ModaNet 的 6.7X 倍,是FashionAI 的 8X 倍.
116 条评论
求数据集密码,感谢
670667626@qq.com解压密码谢谢
求解压密码,非常谢谢
求解压密码,871826082@qq.com, 感谢。
train数据只有191961,好像没有39w,请问大家也是这样么?另外valid数据是32153,test数据是62629
我的也是这样
收不到官方密码,求解压密码~感谢~
jxgu1016 AT gmail.com
楼主,求数据集的解压密码>﹏<,感谢!!!
大佬,求解压密码,583515094@qq.com
869293@qq.com 大哥,请告知解压密码!!!!
求密码,表格老是填不上
研究生搞人体姿态生成,求发送到邮箱解压密码。~多谢
求大佬给份解压密码
跪求数据集密码,27626305@qq.com,谢谢
跪求求数据集密码,非常感谢
同需求数据集密码,非常感谢
已发送到邮箱.
求数据集密码。谢谢
您好,可以把解压密码发到邮箱里面吗?谢谢啦
已发送到邮箱.
求密码,博主
已发送到邮箱
求数据集密码 感谢
已发送到邮箱.
博主您好 可以分享下数据集解压密码吗 万分感谢!
已发送到邮箱.
谢谢博主!
求解压密码,感谢!
已发送到邮箱.
楼主求解压密码
邮箱patrick.phzhou@gmail.com, 谢谢楼主!!
已发送到邮箱.
求解压密码谢谢,582720969@qq.com
已发送到邮箱.
非常谢谢您
感谢(☆ω☆)
您好,可以提供下解压密码给我吗,谢谢啦
已发送到邮箱.
学习,解压密码是否分享一下?
已发送到邮箱.
求解压密码,谢谢
已发送到邮箱.
求DeepFashion2数据集密码,万分感谢!
已发送到邮箱.
博主您好,能够给一下解压密码么~~谢谢
已发送到邮箱.
已收到,谢谢
楼主可以分享一下解压密码么?用于本科课程学习 蟹蟹~
已发送到邮箱.
求数据解压密码:
yfhall@163.com
已发送到邮箱.
求数据集解压密码 感谢!
已发送到邮箱.
求数据集的解压密码>﹏<
已发送到邮箱.
楼主 能给个解压密码吗
已发送到邮箱.
求一个密码博主!感谢! chengmeng0115@gmail.com
已发送到邮箱.
求数据集的解压密码,1500560975@qq.com
已发送到邮箱.
求解压密码:qq: 994329541@qq.com
已发送到邮箱.
求解压密码,谢谢 497316113@qq.com
已发送到邮箱.
求解压密码,感谢大佬
已发送到邮箱.
博主大佬,求解压密码
已发送到邮箱.
已收到,谢谢
博主您好,能够给一下解压密码么~~谢谢chenhehong@126.com
已发送到邮箱.
收到了,十分感谢!!!
求解压密码,万分感谢!!!OωO
已发送到邮箱.
求数据的解压密码,谢谢!
已发送到邮箱.
求密码 谢谢
已发送到邮箱.
@AIHGF
同求数据集密码,非常感谢!
已发送到邮箱.
你好,可以发一下数据集密码吗?谢谢。
已发送到邮箱.
已经收到,谢谢。
同求数据集密码,十分感谢!
已发送到邮箱.
多谢多谢!!!
谁复现了训练的代码,能分享一下么?
博主,求数据集密码
已发送到邮箱
您好,可以把解压密码发到邮箱里面吗?谢谢啦
收不到官方密码,求解压密码~感谢~
已发送到邮箱.
一个星期还没有发密码,请问能发一下数据集密码吗?
已发送到邮箱.
您好 请问可以发下数据集的密码吗???万分感谢
已发送到邮箱.
求deep fashion2数据集,可以分享一下吗?
链接: https://pan.baidu.com/s/10gITxlDA1tQQStiwAXtYwA 提取码: arja
博主你好,非常感谢你的分享精神,我是深入学习刚刚入门,接到了一个衣物分割分类的任务,能够发送一下deepfashion的数据以及您作训练的推理的代码,帮助我入门.万分感谢
同求训练模块的复现代码
deepfashion 数据集已发送到邮箱.
你在deepfashion2上做过训练么?可以加个微信不?
训练过.
多谢分享~博主有ICCV2019deepfashion2workshop的论文吗?找不到,求分享~
噗,应该是博主~
求数据集密码,非常感谢!
已发送到邮箱.
获取密码的网址打不开⌇●﹏●⌇,求数据集密码,非常感谢
已发送到邮箱.
同需求数据集密码,非常感谢
已发送到邮箱.
博士也请帮忙给我发一下数据集密码,表格网站打不开.....非常感谢(・ω・)ノ
train数据只有191962,剩下的呢OωO
刚要转DL的初学者,求数据集密码,感谢