From: https://twitter.com/akshay_pachaar/status/1667147048553164800
LLMs 大火,但它是怎么生成文本的呢?
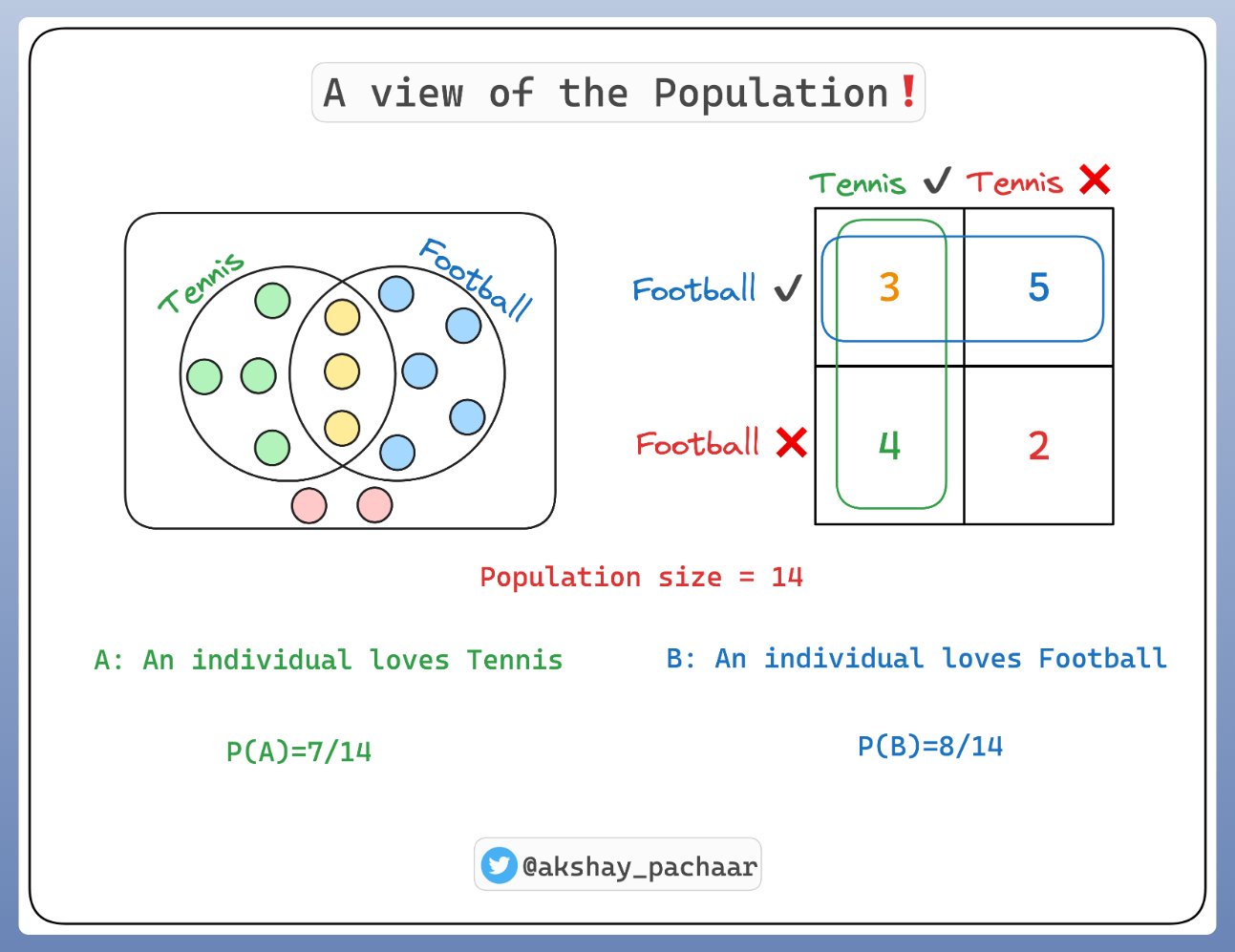
在开始深入 LLMs 之前,首先理解一下条件概率.
假设有 14 个样本,其中,
- 某些像 Tennis
- 某些像 Football
- 一些既像 Tennis 又像 Football
- 还有一些都不像
那么什么是条件概率(Conditional Probability)呢?
条件概率是当另一件事件发生时,事件发生的概率. 如果事件分别记为A和B,条件概率表示为 P(A|B). 其意义是,给定B时,A的概率.
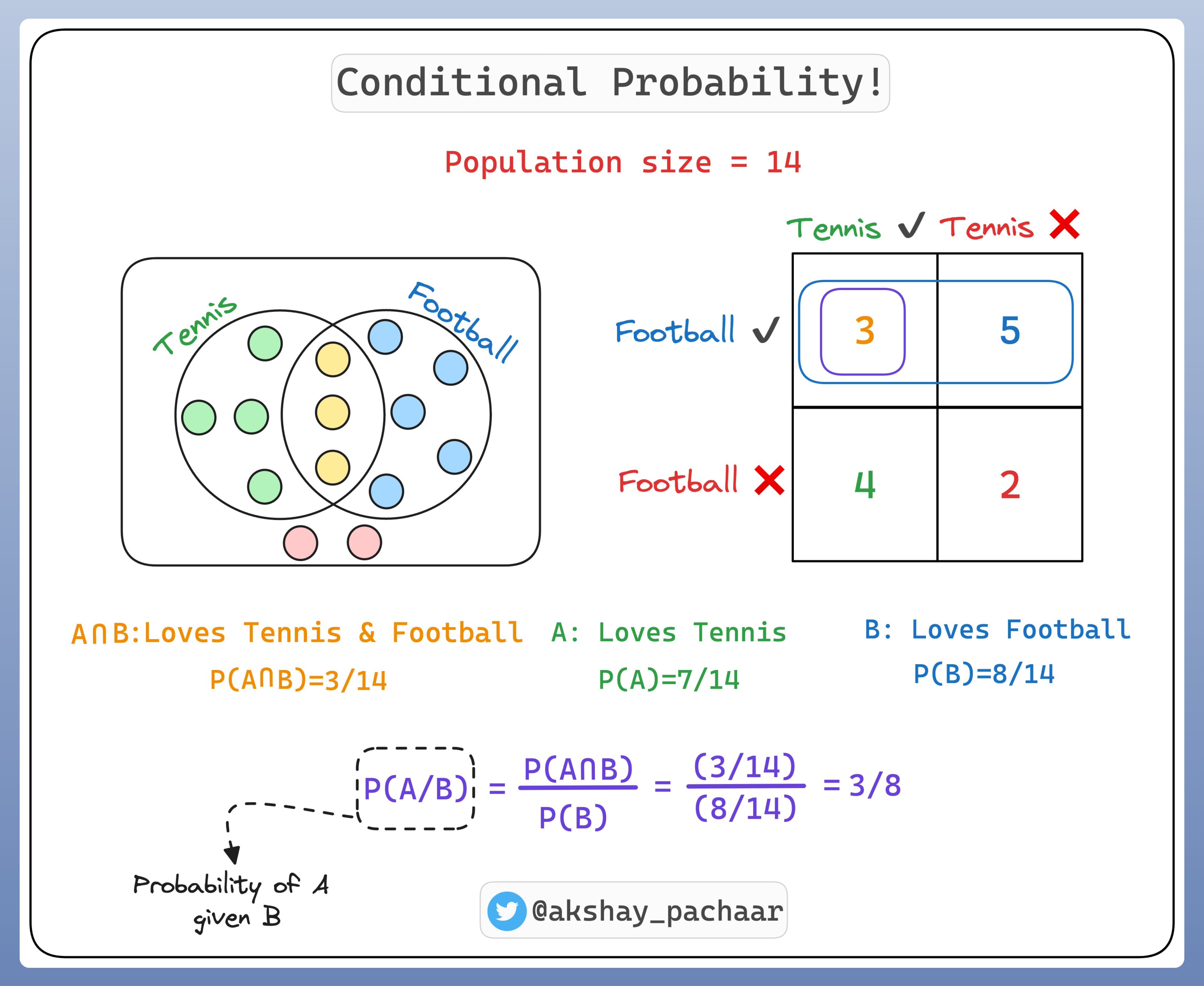
例如,如果想预测今天是否下雨(事件A),已知是多云(事件B)有可能影响预测.
当是多云时,就更可能下雨,也就是说条件概率 P(A|B) 比较大.
那么,条件概率是如何应用到 LLMs,如GPT-4 呢?
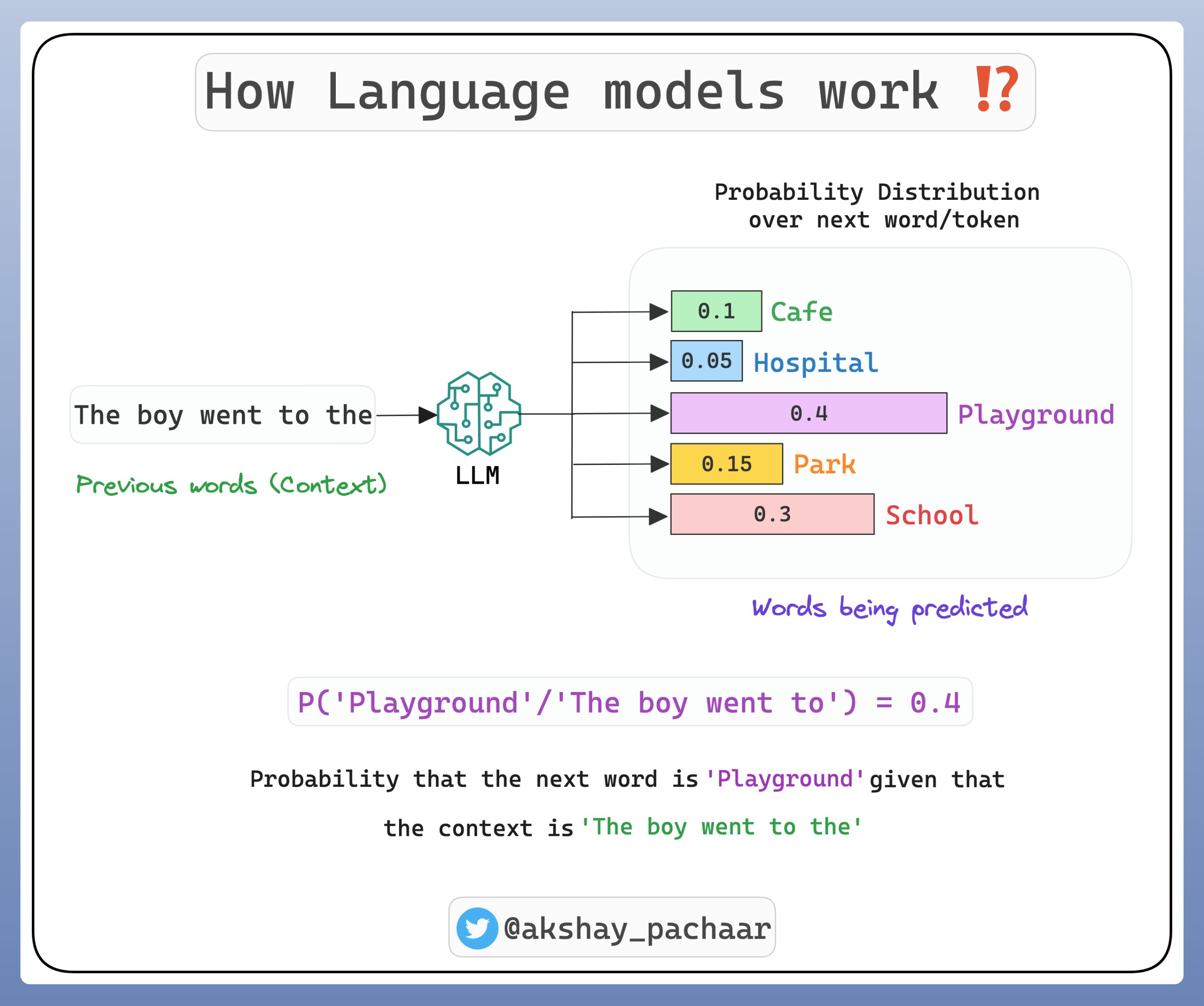
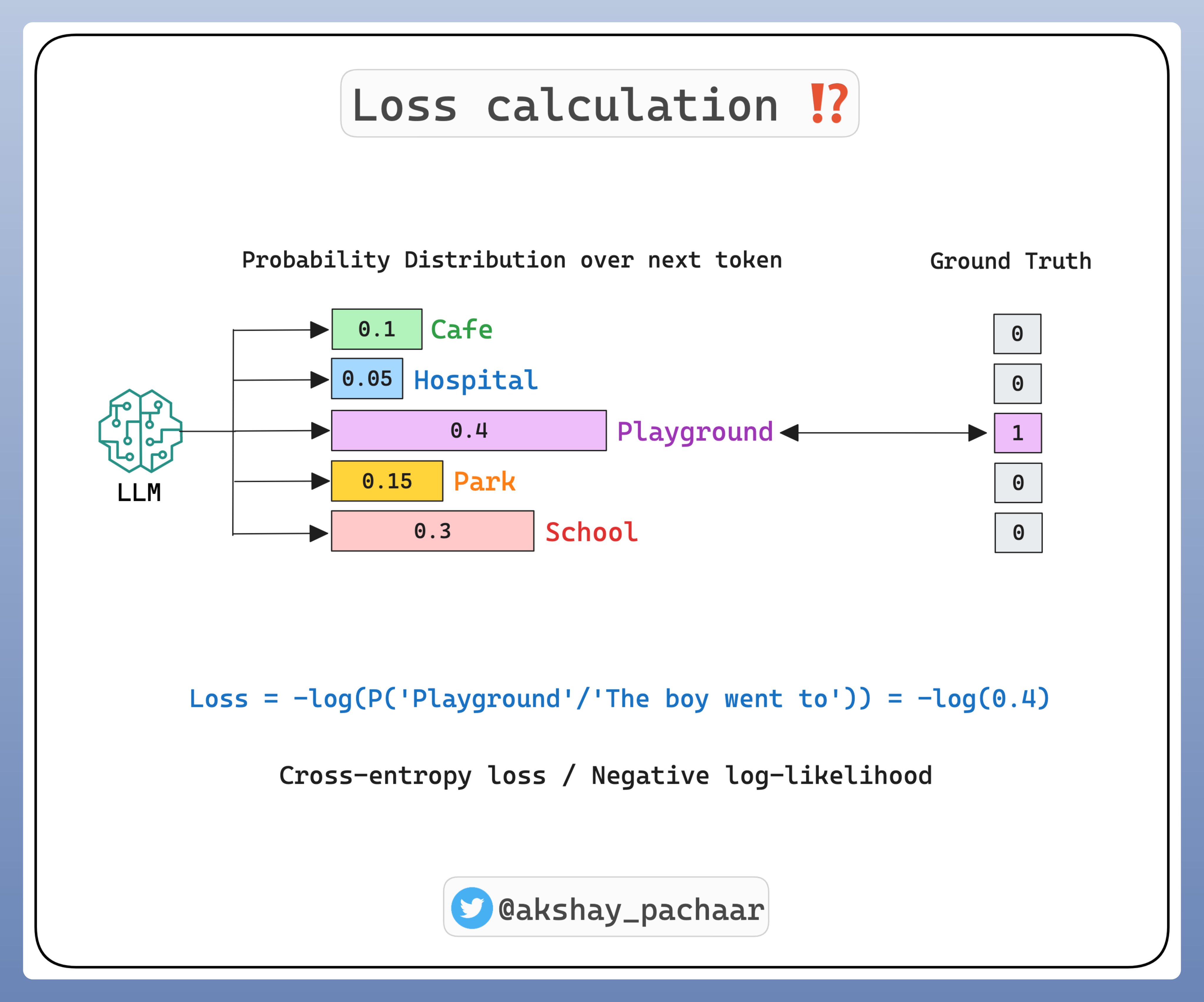
LLMs 是用于预测序列中的下一个单词.
这是一个条件概率问题: 给定前面的单词,下一个单词更可能是什么.

为了预测下一个单词,给定先前的单词(context,上下文),LLMs 模型计算每个下一个可能出现的单词的条件概率.
最高条件概率的单词被作为预测结果.

LLMs 学习单词序列的高维概率分布(high-dimensional probability distribution)。
高维分布的参数就是训练的权重.
1 条评论
你好,可以方向一下deepfasion数据集的img_highres的解压密码吗?非常感谢,1191426436@qq.com