Loading...
https://poloclub.github.io/transformer-explainer/https://github.com/poloclub/...
From: 如何理解attention中的Q,K,V?- 知乎From: https://www.zhi...
往往是训练或微调 LLM,以基于特定的基础知识进行特定任务. 下图示例了不同的微调策略.LLMs 很难完全都放进 GPU 显存里. 如果想更新全部的网络层...
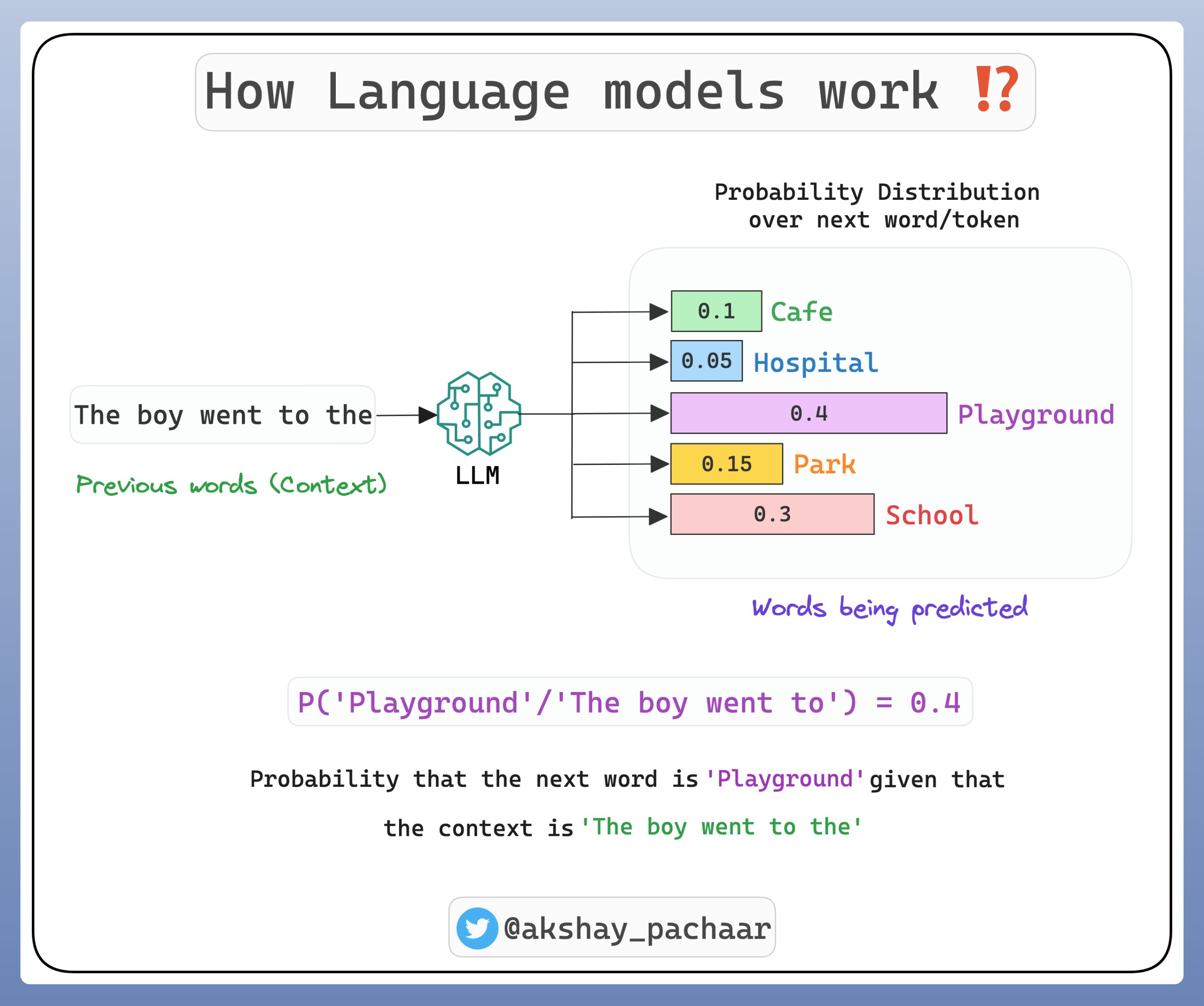
From: https://twitter.com/akshay_pachaar/status/1667...
From: https://twitter.com/akshay_pachaar/status/1657368551471333384Attention ...
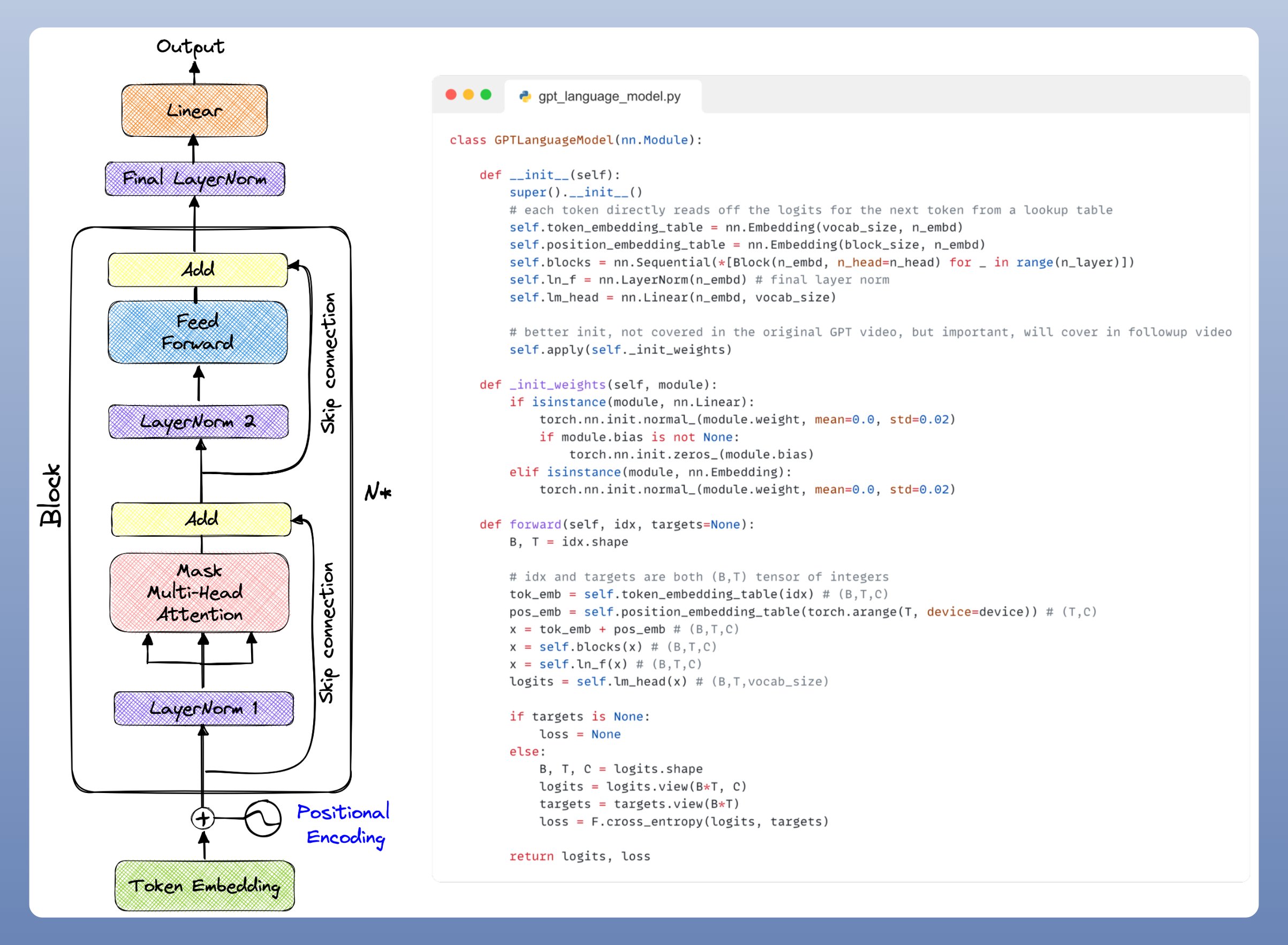
From: https://twitter.com/akshay_pachaar/status/1638...
https://www.youtube.com/watch?v=VtZ02rnfcCQAnalogies that explain Transforme...
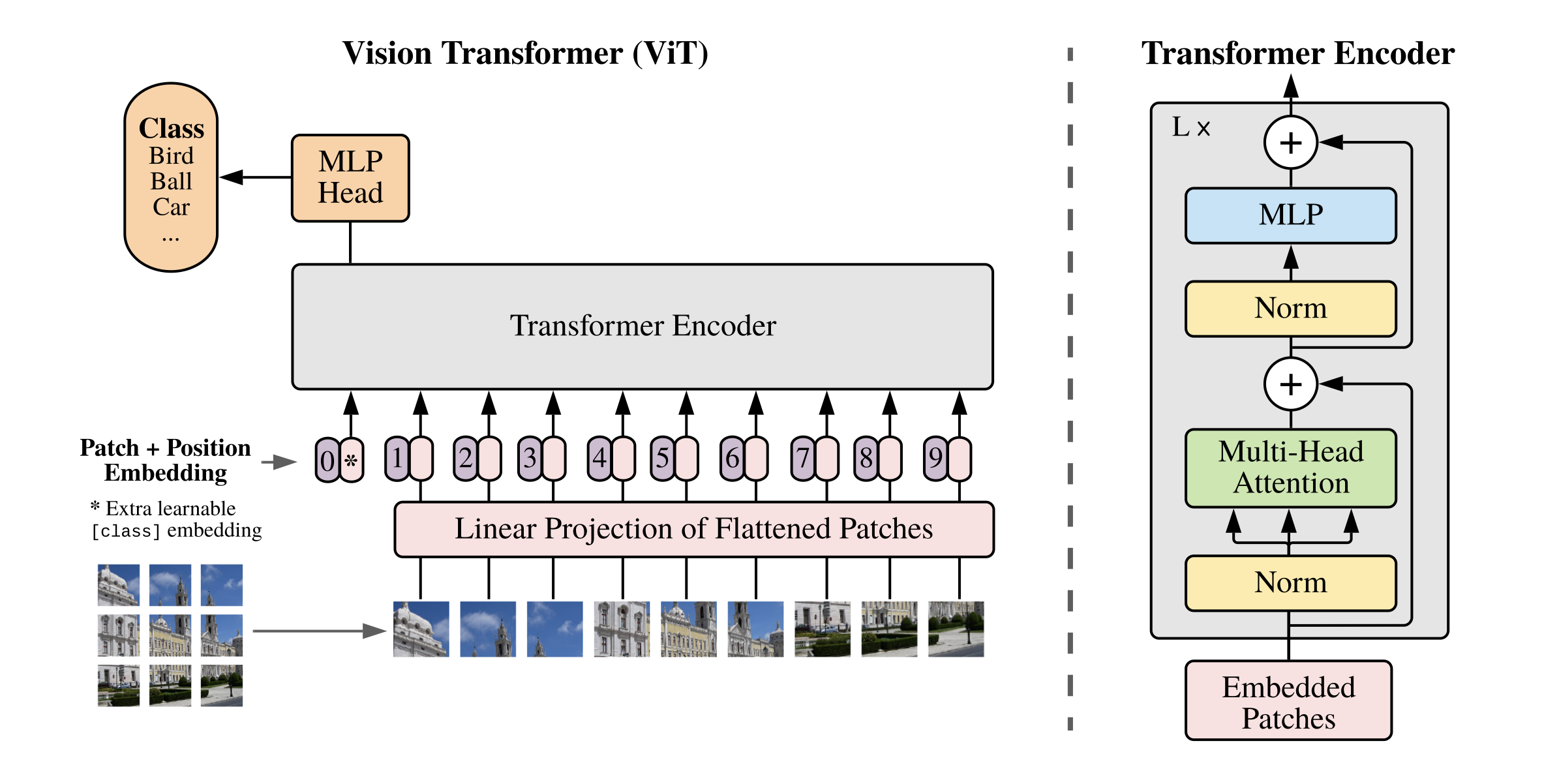
出处:Paddle文档平台 - ViT( Vision Transformer)1. ViT模型介绍在计...
出处:Paddle文档平台 - Transformer1. Transformer 介绍Transformer 网络架构架构由 Ashish Vaswan...
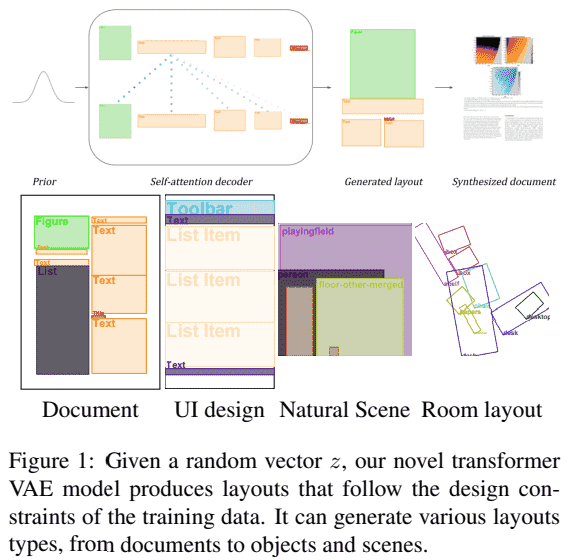
论文:Variational Transformer Networks for Layout Gener...