原文:Going beyond the bounding box with semantic segmentation

我们怎么去描述一个场景呢? 比如,在窗户下有一张桌子,或者,在睡椅的右边有一盏台灯.
将场景分解为不同实体元素,是场景理解的关键,其有助于我们理解物体的行为.
目标检测虽然可以画出某些物体元素的边界框,但人们对于真实场景的理解,还需要能够以像素级、高精度地检测和标注每个实体的边界.
这对于自动驾驶和智能机器人的应用日益重要,因为它们需要更好的感知和理解周围的环境.
1. 语义分割是什么?
语义分割是一种计算机视觉任务,其需要将视觉输入内的不同部分分类为语义可解释(semantically interpretable)的类别.
语义可解释(semantically interpretable), 意味着,物体类别具有某种真实意义.
例如,对于某个实例,我们可能想要找出图片中所有属于 cars 类别的像素点,并用蓝色来标注.

From ICNet, Zhao et al. 2017, demo videp
虽然无监督方法,如聚类,可以用于分割,但其分割结果不一定都是具有语义性的. 无监督方法不能根据训练数据分割出物体类别,而是寻找广义的区域边界. A Survey of Semantic Segmentation - 2016.
语义分割,相比于图片分类和目标检测,能够对图片有更详细的理解,这对于很多应用场景都十分重要,如自动驾驶,机器人,图片搜索引擎等.
这里,介绍基于深度学习方法的监督语义分割方法.
2. 数据集和评价方法
常用的语义分割数据集有:
- Pascal VOC 2012 - 20 个物体类别,比如,Person, Vehicle 等等. 用于分割出物体类别和背景.
- Cityscapes - 城市场景的语义数据集,50 个城市.
- Pascal Context - 室内和室外场景,400+ 类别.
- Stanford Background Dataset - 室外场景数据集,每张图片至少一个前景物体. 如:

语义分割算法的一种标准评价度量方式是 Mean IoU. 其中,IoU 定义如下:

采用 mean IoU 既可以捕捉到目标物体(使预测标签与 groundtruth 重叠),也可以尽可能的精确(使并集与重叠越接近越好.)
3. 管道 Pipeline
一般来说,语义分割模型的 Pipeline 如:
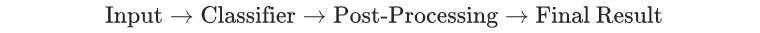
下面继续讨论 Classifier 和 Post-Processing 阶段.
4. 网络结构和方法
4.1 CNN 语义分类
最近语义分割结构通常采用 CNNs 对每个像素分类一个初始化类别标签.
卷积层能够有效的学习图片的局部信息,通过多个卷积层按层堆积,CNNs 尝试提取更广泛的结构.
虽然,连续卷积层能够逐渐捕捉图片的复杂特征,CNN 可以将图片编码为其内容的紧凑表示.
但是,为了对每个像素分类,需要将标准的 CNN 编码器encoder 结构扩展为编码-解码结构encoder-decoder.
编码器采用卷积层和 Pooling 层将图片进行低维表示.
解码器将图片低维表示采用上采用技术(如转置卷积,transpose convs),恢复图片的空间维度. 每步解码器处理,都扩展了低维表示的尺寸.
某些情况,编码器处理中的中间步骤,也应用于各解码器处理.
最终,解码器生成表示了原始图片的标注情况的数组.

From SCNet 的编码-解码结构
许多语义分割网络结构中,CNNs 的损失函数采用最小化交叉熵损失 cross-entropy loss.
该目标函数计算的是每个像素的预测概率分布和其真实概率分布间的距离.
但是,交叉熵损失函数不是语义分割最理想的损失函数.
因为图片的最终 loss 只是每个像素 losses 的相加和,交叉熵 loss 不能保证临近像素的连续性.
鉴于交叉熵损失函数不能充分利用像素间的高层结构信息,采用最小化交叉熵损失的标注,往往会导致分割结构不够协调和出现模糊,因此需要进一步后处理.
4.2 CRFs 改良
CRFs,Conditional Random Fields
CNN 分割结果往往是不够协调,某些小区域可能出现不正确的标注,与其周围像素标注不一致.
为了解决这种不连续性,采用平滑技术进行处理.
需要确保物体在图片中位于连接区域,而且,给定一个像素点,其应该与其周围大部分邻近像素点具有相同的类别标签.
对此,类似于 CRFs 的结构被用于改良 CNN 的语义分割结果,CRFs 利用了原始图片中像素间的相似性.
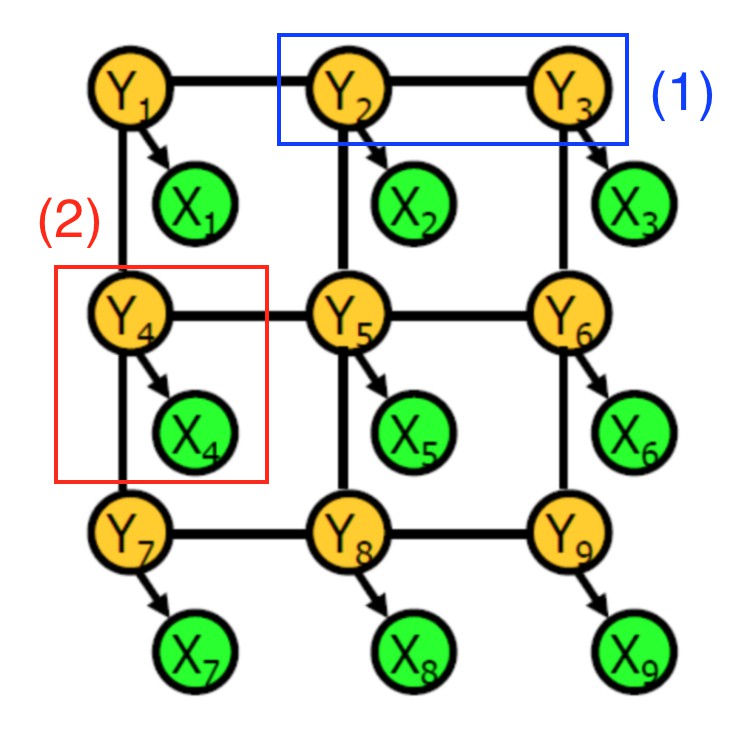
条件随机场CRF 示例.
一个 CRF 是由随机变量构成的图. 图的每一个顶点表示了下面两种意义之一:
- 特定像素点的 CNN 预测标签 (绿色顶点 X_i)
- 特定像素点的真实物体标签 (黄色顶点 Y_i)
两种类型的信息由边来连接:
- 蓝色(1) - 两个像素点的真实物体标签之间的依赖关系,彼此接近;
- 红色(2) - 给定像素点的真实物体标签和CNN预测标签之间的依赖关系.
每个依赖关系是由势能potential 来关联的,势能是两个关联的随机变量值的函数.
例如,当邻近像素点的真实物体类别标签相同时,第一种类型的依赖关系的势能可能比较高.
直观上,物体类别标签作为隐变量,能够根据某种概率分布而生成更好的 CNN 像素类别标签.
为了采用 CRFs 来改良 CNN 预测类别标签,首先采用交叉验证,来学习训练数据的图模型参数. 然后,修改学习的参数,以最大化概率 P(Y1, Y2,...Yn | X1, X2,...Xn).
CRFs 推断的输出即是最终的原始图片像素点的物体标注结果.
实际上,CRF 图是全连接的,也就是说,即使是很远离的两个节点也能够有边edge 连接.
图模型有数以亿计的边,其精确推断的计算量很大.
CRF 结构往往采用有效的逼近技术来进行推断.
5. 分类器结构
CNN 分类 + CRF 改良的方法,仅仅是语义分割的一种技术方案. 其变形有:
- U-Net (2015) - 通过对训练数据集进行变形处理,增强训练数据集. 使得 CNN 编码-解码器可以对图片形变更加鲁棒,从比较少的训练图片中进行模型学习. 当仅对少于 40 张图片的医学图片数据集训练时,仍能够达到 92% 的 IoU.
DeepLab (2016) - 结合了 CNN 编码-解码结构和 CRF 改良技术,生成物体分割结果.(在解码处理中采用了上采样操作). Atrous 卷积, 也叫做 dilated 卷积, 在每一层卷积层采用不同尺寸的 filters,来捕捉不同尺度的特征. 在 Pascal VOC2012 test set 上达到了 70.3% 的IoU.
Dilation10 (2016) - 采用 dilated 卷积的交替方法. 其整体流程是将 dilated 卷积"前端模块(front-end module)" 应用到上下文模块,再采用 CRF-RNN 进一步处理. 在 Pascal VOC2012 test set 上达到了 75.3% 的IoU.
6. 其它训练方案
这里介绍除了分类器和 CRF 模型外的其它训练方案.
除了分部分处理和分开优化,还有 end-to-end 模型.
6.1 完全可微条件随机场 Fully Differentiable Conditional Random Fields
CRF-RNN model 提出了一种将分类和后处理整合为单个 end-to-end 模型的方法. 因此,CRF Gaussian kernels 权重等参数可以自动学习.
他们通过将推断逼近算法操作重新阐述为卷积操作,并采用 RNN 来对推断算法的全迭代特点进行建模.

FCN-8s, DeepLab 和 CRF-RNN 的两组测试图片.
其中,CRF-RNN 模型采用 end-to-end 的方式优化 CRF,分割结果的不协调性更少,分割更准确.
6.2 对抗训练 Adversarial Training
对抗训练有助于高阶连续性.
受到 GANs 启发,generative adversarial networks, Luc et al. Semantic Segmentation using Adversarial Networks 除了训练一个语义分割的标准 CNN 网络,还训练了对抗网络,以尝试学习 groundtruth 分割和 CNN 分割网络分割结果之间的差异性.
CNN 分割网络用于生成对抗网络不能所不能从真实分割标准区分的分割结果.
核心思想是,将分割结果尽可能的与真实分割相同.
如果其它网络能够从 groundtruth 中分类预测结果,那么预测的分割结果不够好.
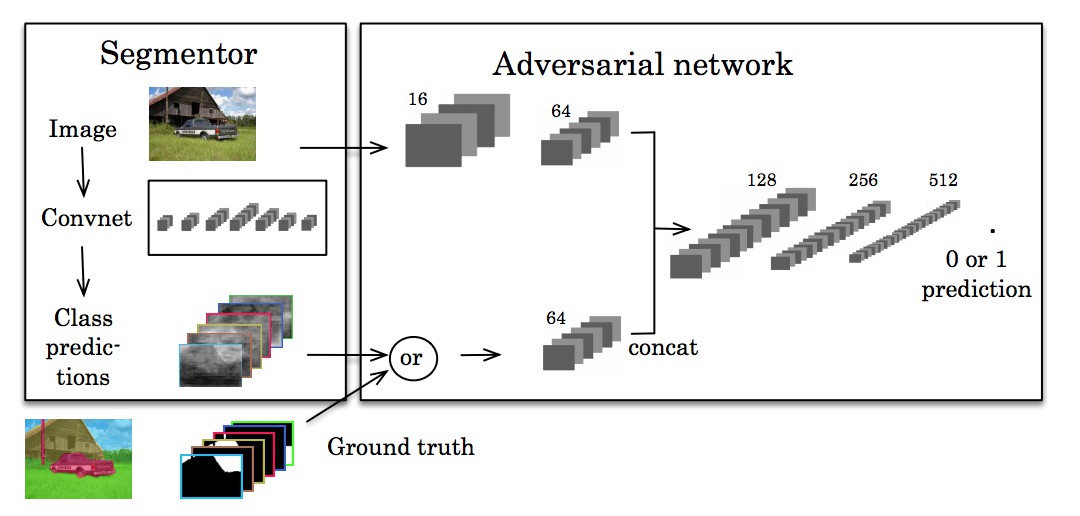
From Semantic Segmentation using Adversarial Networks
6.3 时序分割 Segmentation over time
预测物体在未来可能在的位置呢?
可以采用对场景中分割的连续性进行建模.
在机器人和自动驾驶应用场景中比较普遍,对物体运动的建模有助于路径规划.
论文 进行了首次探索,说明了直接预测未来语义分割,比先预测未来的帧图片,再进行分割,能够得到更好的分割结果.
他们采用自回归模型 autoregressive model,采用过去的分割结果来预测下一个分割 S(t+1).
预测帧 S(t+2) 及以后的分割时,采用过去的帧 S(i) 和预测的帧 S(t+1),依次类似.
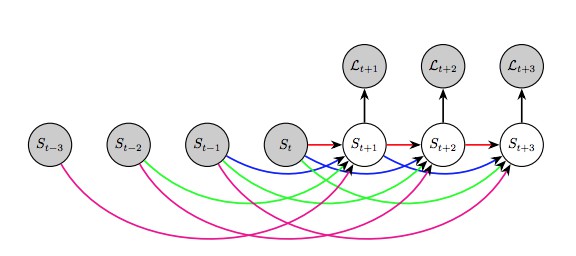
训练方案是从过去分割结果来预测未来分割.
其中, L(t) 是计算预测的和真实分割间差异的损失函数.
From Predicting Deeper into the Future of Semantic Segmentation
论文在 Cityscapes 数据集,采用不同时间尺度来对比模型表现:
- 预测下一帧(short-term timescale)
- 预测下 0.5 秒 (medium-term timescale)
- 预测下 10 秒 ((long-term timescale)
结果发现,对于 long-term 时间尺度,分割结果比较差,但是在 short-term 和 medium-term 的分割结果比较好.
而且,论文方法的结果比基于光流方法 的经典方法的 baseline 结果要更好.
7. 思考
很多语义分割方法,如U-Net,基于基础结构:CNNs 操作 + 经典概率方法的后处理.
单纯的 CNN 输出不够完美,后处理操作更好的与人类直觉上好的标注来对齐分割结果.
其它方法,如对抗学习,作为有效的 end-to-end 分割方案, 其不需要单独建模来改良分割结果,不需要先前描述的 CRF 后处理操作.
由于 end-to-end 的方案比 multistage 方案更加有效,未来的研究可能越来越关注 end-to-end 的方案.