原文 - ConvNets Series. Actual Project Prototyping with Mask R-CNN
很有意思,根据图片来识别煎蛋质量,口味.
1. 介绍
以前关注过基于德国交通信号(German traffic signs)数据集的应用,这里着手一个更加实际的现实生活问题:
是否可以利用深度学习,根据只采用图片作为输入,来判断图片中食物质量的好坏?
简单来说,商业问题可能是:
如下图,商人看待机器学习问题时,可能觉得 omelette 是 OK 的.

注:欧姆蛋(Omelette,又称西式煎蛋卷、杏力蛋(新加坡和马来西亚的叫法)或奄列(粤语地区的叫法)是煎熟的鸡蛋,中间或可放些馅料卷著。其发源地为法国。做法是先在平底锅内加进蛋汁煎到凝固,再将煎好的圆形蛋饼对折成半圆形即可.
来自百度百科.
这是一个不适定问题(ill-imposed problem): 不确定是否存在解决方案,也不确定解决方式是否唯一和稳定,因为完成(Done) 的定义十分模糊(更别说具体实现了.)
这篇文章不是关于高效沟通和项目管理的,但必要的一点是,不要提交范围不明确的项目.
模棱两可问题解决的最好方式是,首先构造具有明确定义的原型,然后再继续深入任务(问题抽象).
这里即是如此.
2. 问题定义
原型关注于单一物品:欧姆蛋(omelette),并构建可扩展的数据管道(data pipline), 其输出欧姆蛋的 "感知质量 perceived quality".
概括如下:
- 问题类型:多类别分类问题,multiclass classification
六个不同的质量类别:[good, broken_yolk, overroasted, two_eggs, four_eggs, misplaced_pieces] - 数据集:351 张不同的欧姆蛋图片,采用 DSLR 相机手工采集. 数据集随机划分:Train/val/test: 139/32/180.
- 标签:每张欧姆蛋图片均有一个对应的质量列表标签.
- 度量方法:分类交叉熵 categorical cross-entropy.
- 必要知识:"good" 欧姆蛋的定义是,三个蛋黄完整的鸡蛋,一些培根肉,没有烧焦碎片,中间有少量的西芹. 另外,组成应该是视觉正确的,没有散乱的片.
- "完成 Done" 的定义:经过两周的原型设计,能够在测试集上取得最好的交叉熵.
- 可视化结果:测试数据集低维表示的 t-SNE.

相机拍摄的输入图片
目标:采用神经网络分类器提取特征,然后计算在测试集上,分类器关于类别概率的 softmax 预测结果.
这样的目标可以使原型可行,且便于后续应用.
以下是提取的有用信息:
- 关键成分mask (Mask R-CNN), Singal #1
- 根据关键成分分组进行计数(基本是不同成分计数的矩阵),Singal #2
- 移除欧姆蛋盛放盘子的 RGB 和背景. 不添加到模型. 即最明显的 Singal - 只对这些图片根据设定的损失函数训练 ConvNet 分类器,并计算选定的典型图片的低维表示和当前图片的 L2 距离. 由于训练数据集只有 139 张图片,无法来验证这个假设.
3. 通用 50K 管道 General 50K Pipeline Overview
忽略了几个重要的阶段,如数据发现,数据探索分析,baseline方案,和 Mask R-CNN 的主动标记(active labeling, 根据半监督实例标注新自定义的命名,启发于 Polygon-RNN demo video)管道. 这里主要关注于 Mask R-CNN.
50K 管道如图:

主要关注于 Mask R-CNN 和分类阶段.
[1] - Mask R-CNN, 成分 mask 分割;
[2] - 基于 Keras 实现 ConvNet 分类器;
[3] - t-SNE 可视化结果
3.1 Stage1 - Mask R-CNN 和 Masks 推断
Mask R-CNN 最近比较热门. 从最初的 Mask R-CNN 论文,到 Kaggle 中的 Data Science Bowl 2018, Mask R-CNN 已经被证明是实例分割中很有效的结构.
matterport/Mask_RCNN 的基于 Keras 的版本,代码结构良好,文档完整,实现快速,但与期望的相比仍较慢.
Github项目 - Mask R-CNN 的 Keras 实现之Demo
Mask R-CNN 简述:
Mask R-CNN 主要包括两个部分: backbone 网络和类似于 Faster R-CNN 结构的 head 网络.
卷积 backbone 网络,基于 FPN 或 ResNet101,作为整张图片的特征提取器.
其后是 RPN 网络,来为 head 网络采样多尺度的 RoIs.
head 网络计算每个 RoI 的边界框识别和mask 预测.
此过程中,RoIAlign 精细地将 RoI 提取的多尺度特征和输入内容进行对齐.

Mask R-CNN 结构
在实际应用中,尤其是对于原型,预训练的 ConvNet 模型是很重要的.
很多现实生活场景中,数据科学家对于标注数据集知之甚少的,甚至都没有标注数据.
但是,ConvNets 需要大量标注的数据集来进行训练收敛,如 ImageNet 数据集包含 1.2M 标注图片.
这时,迁移学习 - transfer learning 的重要性显现出来了:
冻结预训练模型的卷积层权重,只重新训练分类器. 对于小规模数据集而言,冻结卷积层权重很重要,以保证模型不出现过拟合.
一个训练 epoch 后的示例:

实例分割的结果:所有的关键成分都被检测到.
下一个阶段是,裁剪包含盘子的图片部分,并提取每个成分的 2D 二值 Masks.

裁剪的图片和关键成分的二值 mask.
然后,将所有的二值 masks 组合为 8-通道图片(这里定义了 8 个 mask 类别),即 Singal #1.
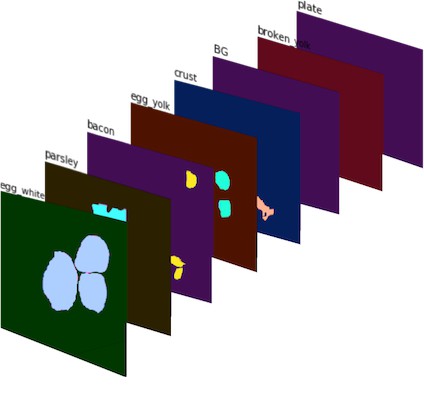
Singal #1 由二值 masks 组成的 8-通道图片
对于 Singal #2,根据 Mask R-CNN 结果计算每个成分的数量,然后组成每个裁剪图片的一个特征向量.
3.2 Stage2 - 基于 Keras 的 ConvNet 分类器
采用 Singal #1 和 Singal #2,(未来添加更多数据) 作为输入,训练网络来分类关于口味质量类别的预测结果.
初步结构如:
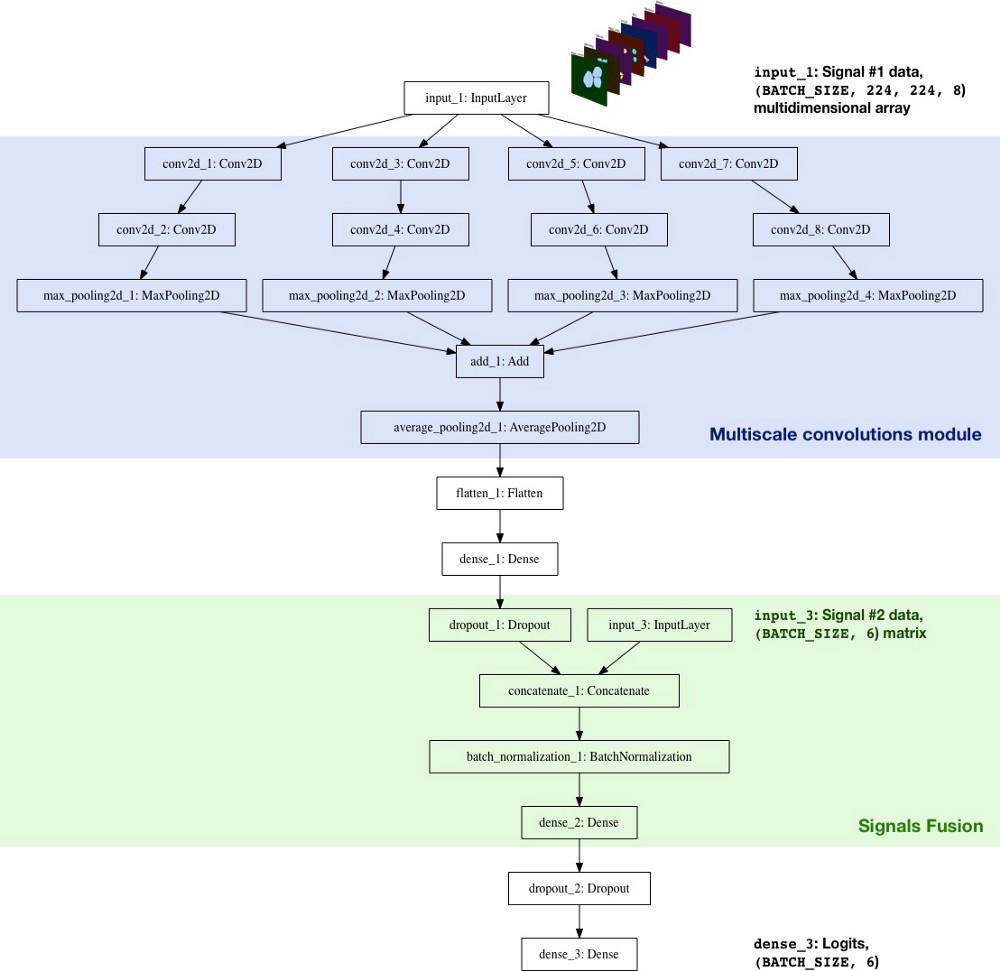
分类器结构的主要特点:
- 多尺度卷积模块 - 开始时采用的 5x5 kernels 的卷积层,但结果不如人意. 采用 3x3, 5x5, 7x7, 11x11 多种 kernels 卷积层的
AveragePooling2D取得了更好的结果. 每一层后都添加一个 1x1 卷积层进行降维. 类似于 Inception 模块. - 大 kernels - 采用较大的 kernel,是因为能够从输入图片中提取更大尺度的特征(其本身也可以看作是 8 fliters 的激活层,每个成分的二值 mask 是一个基本 filter).
Singals 融合 - 初步实现仅采用了单个非线性层来融合两个特征集: 二值 masks(Singal #1) 和成分计数(Singal #2). 虽然比较初步,但 添加 Singal #2 还是取得了提升,将交叉熵由 0.8 提升到了 [0.7, 0.72].
Logits - 对于 TensorFlow, 该层是
tf.nn.softmax_cross_entropy_with_logits计算 batch loss 的.
3.3 Stage3 - t-SNE 可视化结果
t-SNE,流形学习技术,用于数据可视化. 其最小化低维表示的数据点和原始高维数据的联合概率分布的 KL 散度, 基于 非凸损失函数. 具体可见论文 - Visualizing Data using t-SNE- JMLR2008
对于测试集分类结果的可视化,提取了对于测试集图片,分类器的 logits 层,然后采用 t-SNE. 效果还不错,如图:
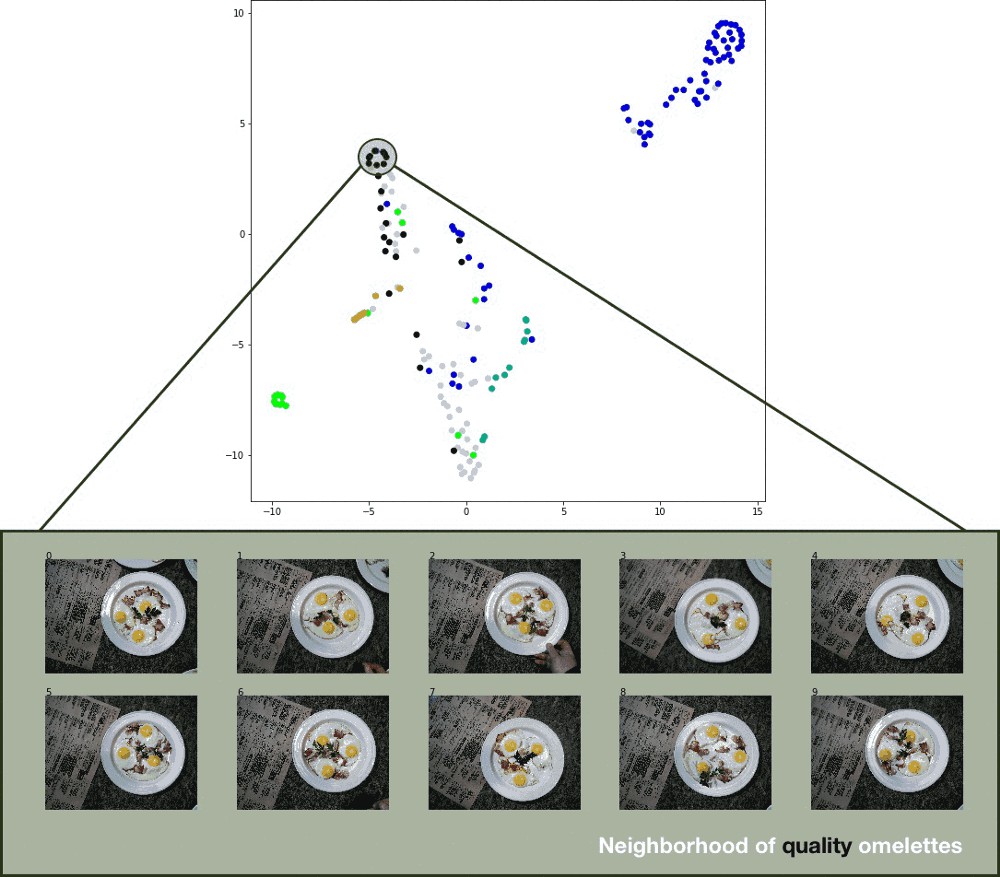
分类器预测的测试集结果的 t-SNE.
虽然仍不完美,但该方法的确有效. 需要改进的地方有很多:
合适的损失函数 - 这里为了简单,采用了分类交叉熵损失函数,但会有更合适的损失函数,以更好的利用类内方差(intra-class variance). 如 Face 论文 里的 triplet loss.
更好的分类器结构 - 当前分类器只是基础原型,其目的是为了解释输入二值 masks,并将多种特征集组合为单个推断.
更好的标签 - 这里只是手工选了图片标签,六种食物质量标签,分类器的表现已经在十几个测试集图片上超过了预料.
4. 思考
在实际中更普遍的情况是,商业问题没有数据,没有标注,没有需要完成的清晰和结构良好的技术任务.
这是好事:我们要做的就是,利用工具,足够的 GPU 硬件,商业和技术的结合,预训练模型,以及其它所需要的东西,发掘商业价值.
小事开始做起 - 根据 LEGO 代码块构建的原型有助于进一步的提高交流的生产力. 作为数据科学家,应该为商业提供相应的解决方案.