这里主要记录基于 OpenCV 4.x DNN 模块和 TensorFlow MaskRCNN 开源模型的目标检测与实例分割 的实现.
MaskRCNN 不仅可以检测图片或视频帧中的物体边界框,还可以得到物体的灰度图或二值 mask 图.
在 TensorFlow Object Detection Model Zoo 中提供了基于不同 backbone 网络结构,基于 MSCOCO 数据集,得到的预训练模型,如 InceptionV2, ResNet50, ResNet101, Inception-ResNetV2. 也可以采用提供的工具自定义训练MaskRCNN 模型 - train your own models.
其中,基于 Inception 系列 的 backbone 网络速度是最快的,可以尝试在 CPU 上进行运行.
1. MaskRCNN 简介
论文阅读 - Mask R-CNN - AIUAI
语义分割:是指基于某些准则将图片分为不同的像素组,如基于颜色(color)、纹理(texture)等. 得到的像素组有时也被叫作超像素(super-pixels). 语义分割尝试将图片中的每一个像素进行分类.
实例分割:旨在检测图片中的特定物体,同时创建物体的 mask. 实例分割还可以看作是一种目标检测,其输出是物体的 mask,而不只是物体的边界框. 实例分割并不对图片中的每个像素进行标注. 如图:

图1 - 实例分割例示.
MaskRCNN 是 R-CNN 系列的改进.
R-CNN - CVPR2014 是目标检测算法,其基于 selective search 算法生成 region proposals,然后再分别逐个采用 CNN 对每个 proposed region 进行处理,输出物体的类别标签和对应的边界框.
Fast R-CNN - ICCV2015 提升了 R-CNN 算法的速度,通过采用 RoIPool 层,基于 CNN 一次处理所有的 proposed regions.
Faster R-CNN - PAMI2017进一步提升算法的速度,其主要是采用 RPN(Region Proposal Network) 网络来进行 region proposal 处理. RPN 网络和物体分类与边界框检测网络同时对共享的 feature maps 进行处理,因此具有更快的推断速度. 在单张 GPU 上, Faster R-CNN 运行速率可达到 5 fps.
Mask R-CNN - ICCV2017 对 Faster R-CNN 进行改进,其新增了一个和物体类别和物体边界框预测网络分支并行的 mask 预测网络分支,如下图2. 虽然在 Faster R-CNN 添加了一个小的输出分支,但仍能够在单张 GPU 运行速率 5 fps.

图2 - Mask-RCNN 网络结构
MaskRCNN 网络结构中的 RPN 网络对每张图片产生约 300 个 region proposals.
训练时,每个 region proposals(ROIs) 传递到目标检测网络和 mask 预测网络. 其中,对于每个给定 ROI,mask 预测分支可以与目标检测分支并行地进行,因此,网络可以预测属于所有物体类别的 masks.
推断时,region proposals 经过 NMS 处理,只对 top scoring 100 的检测边界框,才送入 mask 预测分支进行处理. 因此,对于 100 个 ROIs 和 90 个物体类别,MaskRCNN 网络的 mask 预测分支输出为 100x90x15x15 的 4D tensor,其中每个 mask 的尺寸为 15x15.
例如,对于图1 中的 sheep 物体类,MaskRCNN 检测到两个物体. 对于每个物体,目标检测分支输出包含预测的物体概率分数(即:物体属于预测类别的概率),以及检测到的物体的边界框的坐标位置 - (left, top, right, bottom). 其中 class id 用于从 mask 预测分支的输出中提取对应的物体 mask. 如下图:

图3 - MaskRCNN 预测的 sheep mask.
MaskRCNN 的 mask 预测分支得到的 masks 可以进行阈值化,以得到二值 mask.
类似于 Faster R-CNN,MaskRCNN 可以灵活的选择不同的 backbone 网络结构. 例如采用 InceptionV2 backbone 结构,其速度快,同时能够得到比 ResNeXt-101 更好的结果.
MaskRCNN 网络可以在较大的图片尺寸上进行处理,其将输入图像调整尺寸,如将图片最小边尺寸保持为 800 pixels.
2. MaskRCNN DNN 实现
PyTorch实现:Github 项目 - maskrcnn-benchmark 简单使用及例示 - AIUAI
#!/usr/bin/python3
#!--*-- coding: utf-8 --*--
from __future__ import division
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
import os
import random
class general_maskrcnn_dnn(object):
def __init__(self, modelpath):
self.conf_threshold = 0.5 # Confidence threshold
self.mask_threshold = 0.3 # Mask threshold
self.colors = [[ 0., 255., 0.],
[ 0., 0., 255.],
[255., 0., 0.],
[ 0., 255., 255.],
[255., 255., 0.],
[255., 0., 255.],
[ 80., 70., 180.],
[250., 80., 190.],
[245., 145., 50.],
[ 70., 150., 250.],
[ 50., 190., 190.], ]
self.maskrcnn_model = self.get_maskrcnn_net(modelpath)
self.classes = self.get_classes_name()
def get_classes_name(self):
# Load names of classes
classesFile = "mscoco_labels.names"
classes = None
with open(classesFile, 'rt') as f:
classes = f.read().rstrip('\n').split('\n')
return classes
def get_maskrcnn_net(self, modelpath):
pbtxt_file = os.path.join(modelpath, './graph.pbtxt')
pb_file = os.path.join(modelpath, './frozen_inference_graph.pb')
maskrcnn_model = cv2.dnn.readNetFromTensorflow(pb_file, pbtxt_file)
maskrcnn_model.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
maskrcnn_model.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
return maskrcnn_model
def postprocess(self, boxes, masks, img_height, img_width):
# 对于每个帧,提取每个检测到的对象的边界框和掩码
# 掩模的输出大小为NxCxHxW
# N - 检测到的框数
# C - 课程数量(不包括背景)
# HxW - 分割形状
numClasses = masks.shape[1]
numDetections = boxes.shape[2]
results = []
for i in range(numDetections):
box = boxes[0, 0, i]
mask = masks[i]
score = box[2]
if score > self.conf_threshold:
left = int(img_width * box[3])
top = int(img_height * box[4])
right = int(img_width * box[5])
bottom = int(img_height * box[6])
left = max(0, min(left, img_width - 1))
top = max(0, min(top, img_height - 1))
right = max(0, min(right, img_width - 1))
bottom = max(0, min(bottom, img_height - 1))
result = {}
result["score"] = score
result["classid"] = int(box[1])
result["box"] = (left, top, right, bottom)
result["mask"] = mask[int(box[1])]
results.append(result)
return results
def predict(self, imgfile):
img_cv2 = cv2.imread(imgfile)
img_height, img_width, _ = img_cv2.shape
# 从框架创建4D blob。
blob = cv2.dnn.blobFromImage(img_cv2, swapRB=True, crop=True)
# 设置网络的输入
self.maskrcnn_model.setInput(blob)
# 运行正向传递以从输出层获取输出
boxes, masks = self.maskrcnn_model.forward(
['detection_out_final', 'detection_masks'])
# 为每个检测到的对象提取边界框和蒙版
results = self.postprocess(boxes, masks, img_height, img_width)
return results
def vis_res(self, img_file, results):
img_cv2 = cv2.imread(img_file)
for result in results:
# box
left, top, right, bottom = result["box"]
cv2.rectangle(img_cv2,
(left, top),
(right, bottom),
(255, 178, 50), 3)
# class label
classid = result["classid"]
score = result["score"]
label = '%.2f' % score
if self.classes:
assert (classid < len(self.classes))
label = '%s:%s' % (self.classes[classid], label)
label_size, baseline = cv2.getTextSize(
label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, label_size[1])
cv2.rectangle(
img_cv2,
(left, top - round(1.5 * label_size[1])),
(left + round(1.5 * label_size[0]), top + baseline),
(255, 255, 255), cv2.FILLED)
cv2.putText(
img_cv2,
label,
(left, top),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 0), 1)
# mask
class_mask = result["mask"]
class_mask = cv2.resize(class_mask, (right - left + 1, bottom - top + 1))
mask = (class_mask > self.mask_threshold)
roi = img_cv2[top: bottom + 1, left: right + 1][mask]
# color = self.color[classId%len(colors)]
color_index = random.randint(0, len(self.colors) - 1)
color = self.colors[color_index]
img_cv2[top: bottom + 1, left: right + 1][mask] = (
[0.3 * color[0], 0.3 * color[1], 0.3 * color[2]] + 0.7 * roi).astype(np.uint8)
mask = mask.astype(np.uint8)
contours, hierachy = cv2.findContours(
mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(
img_cv2[top: bottom + 1, left: right + 1],
contours,
-1,
color,
3,
cv2.LINE_8,
hierachy,
100)
t, _ = self.maskrcnn_model.getPerfProfile()
label = 'Inference time: %.2f ms' % \
(t * 1000.0 / cv2.getTickFrequency())
cv2.putText(img_cv2, label, (0, 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255))
plt.figure(figsize=(10, 8))
plt.imshow(img_cv2[:, :,::-1])
plt.axis("off")
plt.show()
if __name__ == '__main__':
print("[INFO]MaskRCNN detection.")
img_file = "test.jpg"
#
start = time.time()
modelpath = "/path/to/mask_rcnn_inception_v2_coco_2018_01_28"
maskrcnn_model = general_maskrcnn_dnn(modelpath)
print("[INFO]Model loads time: ", time.time() - start)
start = time.time()
res = maskrcnn_model.predict(img_file)
print("[INFO]Model predicts time: ", time.time() - start)
maskrcnn_model.vis_res(img_file, res)
print("[INFO]Done.")输出结果如:

3. MaskRCNN TensorFlow 实现
#!/usr/bin/python3
#!--*-- coding: utf-8 --*--
import numpy as np
from PIL import Image, ImageColor, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import os
# 指定 GPUID
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import tensorflow as tf
# masks 颜色
COLORS = np.array([
np.array([128,0,0]),
np.array([0,128,0]),
np.array([128,128,0]),
np.array([0,0,128]),
np.array([128,0,128]),
np.array([0,128,128]),
np.array([192,192,192]),
np.array([128,128,128]),
np.array([255,0,0]),
np.array([0,255,0]),
np.array([255,255,0]),
np.array([0,0,255]),
np.array([255,0,255]),
np.array([0,255,255]),
np.array([255,255,255]),
np.array([0,0,0]),
np.array([0,0,95]),
np.array([0,0,135]),
np.array([0,0,175]),
np.array([0,0,215]),
np.array([0,0,255]),
np.array([0,95,0]),
np.array([0,95,95]),
np.array([0,95,135]),
np.array([0,95,175]),
np.array([0,95,215]),
np.array([0,95,255]),
np.array([0,135,0]),
np.array([0,135,95]),
np.array([0,135,135]),
np.array([0,135,175]),
np.array([0,135,215]),
np.array([0,135,255]),
np.array([0,175,0]),
np.array([0,175,95]),
np.array([0,175,135]),
np.array([0,175,175]),
np.array([0,175,215]),
np.array([0,175,255]),
np.array([0,215,0]),
np.array([0,215,95]),
np.array([0,215,135]),
np.array([0,215,175]),
np.array([0,215,215]),
np.array([0,215,255]),
np.array([0,255,0]),
np.array([0,255,95]),
np.array([0,255,135]),
np.array([0,255,175]),
np.array([0,255,215]),
np.array([0,255,255]),
np.array([95,0,0]),
np.array([95,0,95]),
np.array([95,0,135]),
np.array([95,0,175]),
np.array([95,0,215]),
np.array([95,0,255]),
np.array([95,95,0]),
np.array([95,95,95]),
np.array([95,95,135]),
np.array([95,95,175]),
np.array([95,95,215]),
np.array([95,95,255]),
np.array([95,135,0]),
np.array([95,135,95]),
np.array([95,135,135]),
np.array([95,135,175]),
np.array([95,135,215]),
np.array([95,135,255]),
np.array([95,175,0]),
np.array([95,175,95]),
np.array([95,175,135]),
np.array([95,175,175]),
np.array([95,175,215]),
np.array([95,175,255]),
np.array([95,215,0]),
np.array([95,215,95]),
np.array([95,215,135]),
np.array([95,215,175]),
np.array([95,215,215]),
np.array([95,215,255]),
np.array([95,255,0]),
np.array([95,255,95]),
np.array([95,255,135]),
np.array([95,255,175]),
np.array([95,255,215]),
np.array([95,255,255]),
np.array([135,0,0]),
np.array([135,0,95]),
np.array([135,0,135]),
np.array([135,0,175]),
np.array([135,0,215]),
np.array([135,0,255]),
np.array([135,95,0]),
np.array([135,95,95]),
np.array([135,95,135]),
np.array([135,95,175]),
np.array([135,95,215]),
np.array([135,95,255]),
np.array([135,135,0]),
np.array([135,135,95]),
np.array([135,135,135]),
np.array([135,135,175]),
np.array([135,135,215])
])
# 类别名
classes_names = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle',
'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket','bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut',
'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table',
'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink',
'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush']
model_path = "/path/to/mask_rcnn_inception_v2_coco_2018_01_28"
frozen_pb_file = os.path.join(model_path, 'frozen_inference_graph.pb')
# 加载 Graph
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(frozen_pb_file, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# sess 配置
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.log_device_placement = True
# memory_fraction = 0.4
# config.gpu_options.per_process_gpu_memory_fraction = memory_fraction
def reframe_box_masks_to_image_masks(
box_masks, boxes, image_height, image_width):
"""
Transforms the box masks back to full image masks.
Embeds masks in bounding boxes of larger masks whose shapes correspond to
image shape.
Args:
box_masks: A tf.float32 tensor of size [num_masks, mask_height, mask_width].
boxes: A tf.float32 tensor of size [num_masks, 4] containing the box
corners. Row i contains [ymin, xmin, ymax, xmax] of the box
corresponding to mask i. Note that the box corners are in
normalized coordinates.
image_height: Image height. The output mask will have the same height as
the image height.
image_width: Image width. The output mask will have the same width as the
image width.
Returns:
A tf.float32 tensor of size [num_masks, image_height, image_width].
"""
def reframe_box_masks_to_image_masks_default():
"""
The default function when there are more than 0 box masks.
"""
def transform_boxes_relative_to_boxes(boxes, reference_boxes):
boxes = tf.reshape(boxes, [-1, 2, 2])
min_corner = tf.expand_dims(reference_boxes[:, 0:2], 1)
max_corner = tf.expand_dims(reference_boxes[:, 2:4], 1)
transformed_boxes = (boxes - min_corner) / (max_corner - min_corner)
return tf.reshape(transformed_boxes, [-1, 4])
box_masks_expanded = tf.expand_dims(box_masks, axis=3)
num_boxes = tf.shape(box_masks_expanded)[0]
unit_boxes = tf.concat(
[tf.zeros([num_boxes, 2]), tf.ones([num_boxes, 2])], axis=1)
reverse_boxes = transform_boxes_relative_to_boxes(unit_boxes, boxes)
return tf.image.crop_and_resize(
image=box_masks_expanded,
boxes=reverse_boxes,
box_ind=tf.range(num_boxes),
crop_size=[image_height, image_width],
extrapolation_value=0.0)
image_masks = tf.cond(
tf.shape(box_masks)[0] > 0,
reframe_box_masks_to_image_masks_default,
lambda: tf.zeros([0, image_height, image_width, 1], dtype=tf.float32))
return tf.squeeze(image_masks, axis=3)
def detect(img_array):
# model expects images shape: [1, None, None, 3]
img_array_expanded = np.expand_dims(img_array, axis=0)
results = {}
with detection_graph.as_default():
with tf.Session(config=config) as sess:
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in ['num_detections',
'detection_boxes',
'detection_scores',
'detection_classes',
'detection_masks']:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] =
tf.get_default_graph().get_tensor_by_name(tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates
# to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes,
[0, 0],
[real_num_detection, -1])
detection_masks = tf.slice(detection_masks,
[0, 0, 0],
[real_num_detection, -1, -1])
detection_masks_reframed = reframe_box_masks_to_image_masks(
detection_masks,
detection_boxes,
img_array.shape[0],
img_array.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(
tensor_dict,
feed_dict={image_tensor: img_array_expanded})
# all outputs are float32 numpy arrays, so convert types as appropriate
results['num_detections'] = int(output_dict['num_detections'][0])
results['classes'] = output_dict['detection_classes'][0].astype(np.uint8)
results['boxes'] = output_dict['detection_boxes'][0]
results['scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
results['masks'] = output_dict['detection_masks'][0]
return results
def vis_res(img_array, result, score_threshold=0.3,alpha = 0.5):
# Visualize detected bounding boxes and masks.
num_detections = int(result['num_detections'])
classes = result['classes']
boxes = result['boxes']
scores = result['scores']
if 'masks' in result:
masks = result['masks']
img_pil = Image.fromarray(np.uint8(img_array)).convert('RGB')
img_height, img_width = img_array.shape[:2]
for idx in range(num_detections):
draw = ImageDraw.Draw(img_pil)
class_id = int(classes[idx])
score = float(scores[idx])
if score > score_threshold:
# box
box = boxes[idx] * np.array(
[img_height, img_width, img_height, img_width])
top, left, bottom, right = box.astype("int")
draw.rectangle((left, top, right, bottom), None, "red", 4)
text = "{}: {:.4f}".format(classes_names[class_id], score)
font = ImageFont.truetype('NotoSansCJK-Black.ttc', 10)
draw.text((left, top), text, font=font, fill='blue')
# mask
mask = masks[idx]
rgb = COLORS[class_id]
# color = "red"
# rgb = ImageColor.getrgb(color)
solid_color = np.expand_dims(
np.ones_like(mask), axis=2) * np.reshape(list(rgb),
[1, 1, 3])
pil_solid_color = Image.fromarray(np.uint8(solid_color)).convert('RGBA')
mask_pil = Image.fromarray(np.uint8(255.0 * alpha * mask)).convert('L')
img_pil = Image.composite(pil_solid_color, img_pil, mask_pil)
plt.figure(figsize=(10, 8))
plt.imshow(img_pil)
plt.title("TensorFlow Mask RCNN-Inception_v2_coco")
plt.axis("off")
plt.show()
if __name__ == '__main__':
img_file = "test.jpg"
img_pil = Image.open(img_file)
img_width, img_height = img_pil.size
img_array = np.array(img_pil.getdata()).reshape((img_height, img_width, 3)).astype(np.uint8)
results = detect(img_array)
vis_res(img_array, results)
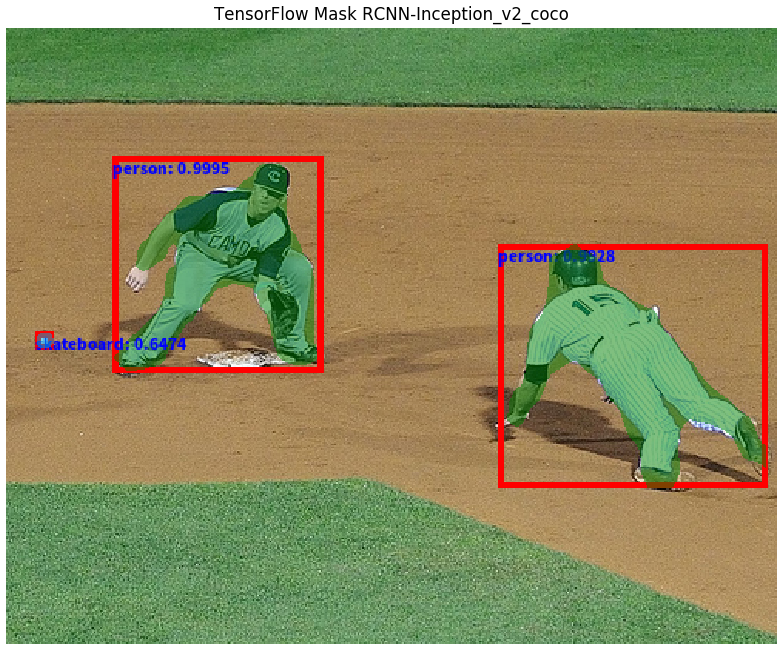
print("[INFO]Done.")输出结果如:
3 条评论
训练自己的模型进行测试会出现此种错误,请问怎么解决,求助,谢谢
cv2.error: OpenCV(4.1.0) error: (-2:Unspecified error) Input layer not found: CropAndResize/Reshape/shape in function 'connect
果然大佬的站就是优秀 想要的资料一搜就有 向大佬学习