原文 - Splash of Color: Instance Segmentation with Mask R-CNN and TensorFlow
以构建颜色填充器(Color Splash Filter)为例.
基于 Github - matterport/Mask_RCNN 实现.
这里主要包括两部分:
[1] - Mask R-CNN 简述
[2] - 从零开始训练 Mask R-CNN 模型, 并构建智能颜色填充器. 开源实现: Color Splash
1. 实例分割
实例分割是像素级识别目标物体轮廓的任务.
相比于其它计算机视觉任务, 如目标检测, 语义分割等, 实例分割是比较有挑战性的视觉问题之一.
例如:

- 图像分类: 识别图片中有气球
- 语义分割: 识别图片中所有的气球像素点
- 目标检测: 识别图片中有 7 个气球及其对应的位置(边界框).
- 实例分割: 识别图片中有 7 个气球及其每个气球对应的像素.
2. Mask R-CNN
Mask R-CNN 可以看作是 Faster R-CNN 的扩展, 将后者的目标检测框架, 应用到了实例分割.
Mask R-CNN 主要包括两个阶段:
[1] - 卷积网络处理图片, 并生成 proposals, 获得可能包含目标的区域;
[2] - 对 proposals 分类, 并检测目标边界框和分割 mask.
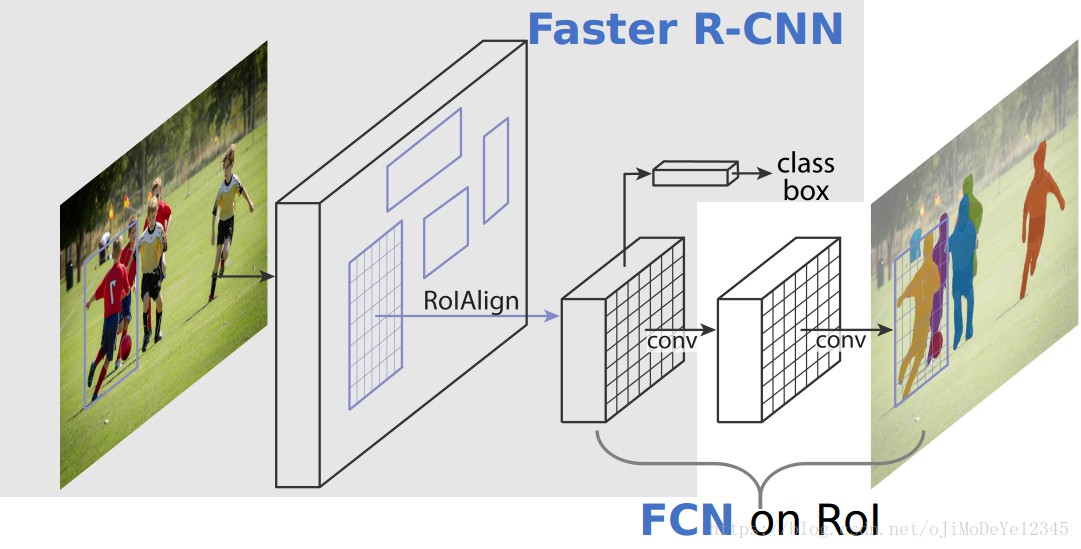
Mask R-CNN 主要包括模块有:
2.1 网络 Backbone
采用标准的 CNN 网络, 如 ResNet50, ResNet101 作为特征提取器.
浅层网络检测底层特征(边缘和角等);
深层网络检测更高层特征(car, person, sky 等).
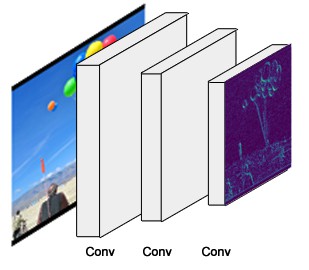
RGB图片(1024x1024x3) 经过 backbone 网络, 得到 32x32x2048 的 feature maps.
这些 feature maps 作为后续网络的输入.
backbone 网络的具体实现位于 resnet_graph() 函数.
该代码支持 ResNet50 和 ResNet101.
2.1.1 FPN - Feature Pyramid Network
虽然 Backbone 网络能够提取很好的特征, 但还可以进一步提升.
Mask R-CNN 的作者所提出的 FPN 能够更好的在不同尺度表征物体.
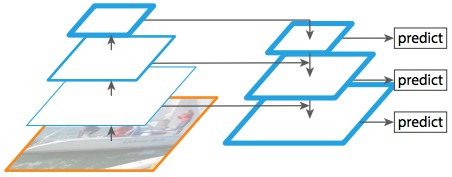
FPN 对于标准特征提取金字塔的提升, 在于, FPN 添加了第二个金字塔, 其可以从第一个金字塔选择高层特征, 并传递到底层.
这样的处理, 每一层的特征都可以学习到底层和高层的特征.
FPN 的具体实现位于 MaskRCNN.build()
FPN 位于构建 ResNet 后.
RPN 引入了新的复杂度: 与标准 backbone 网络的单个 backbone feature map (第一个金字塔的 top 层输出)不同的是, FPN 在第二个金字塔的每一层都有 feature map.
根据物体尺寸动态的选取.
后面仍采用 backbone feature map 来叙述, 但使用 FPN 时, 实际上是选取了其中一个.
2.2 RPN - Region Proposal Network
RPN 是轻量神经网络, 采用滑窗的方式扫描图片,并得到包含物体的区域.

RPN 扫描的区域叫作 Anchor. Anchor 是在图片区域上分布的 boxes. 如上图.
尽管是简化图, 但实际上是有 200K 个不同尺寸和长宽比的 boxes. 而且这些 boxes 是重叠的, 以尽可能的覆盖图片.
RPN 扫描这么多 anchors 需要多久呢? 实际上, 很快!
滑窗是由 RPN 的卷积网络来实现的, 可以并行地扫描所有区域(GPU 上).
而且, RPN 不是直接扫描图片(虽然为了例示是在图片上画出的 Anchors).
RPN 是在提取的 backbone feature map 上进行的扫描.
这样, RPN 就可以有效的重用提取的特征, 并避免重复计算.
根据 Faster R-CNN 论文所说, RPN 只需大约 10ms.
Mask R-CNN 采用更大的图片和更多的 Anchors, 可能稍微耗时多一点.
RPN 具体实现位于 rpn_graph().
Anchor 的 scales 和 aspect ratios 是由 config.py 中的 RPN_ANCHOR_SCALES 和 RPN_ANCHOR_RATIOS 参数定义的.
RPN 对于每个 anchor 生成两个输出:
[1] - Anchor Class, 两类: 前景类FG和背景类BG. FG 类表示在 box 中可能存在物体.
[2] - Bounding Box Refinement, 边界框精炼, foreground anchor, 也叫做 positive anchor, 可能不是正好位于目标物体的中心. 因此, RPN 估计 delta(x, y, width, height 的变化量) 来精炼 anchor box, 以更好的拟合物体.
根据 RPN 预测结果, 选取 top 个可能包含物体的 anchors, 并精调其位置和尺寸.
如果某些 anchors 重叠较多, 只保留最高 foreground score 的, 丢弃其余的.(即, NMS).
最终可以得到 proposals (RoI), 以用于后续阶段.
ProposalLayer 是自定义的 Keras 层, 其读取 RPN 的输出, 选取 top anchors, 并进行边界框精炼.
2.3 RoI 分类器和边界框回归器
该阶段的处理是在 RPN 生成的 RoIs 上进行的.
类似于 RPN, 对每个 RoI 生成两个输出:
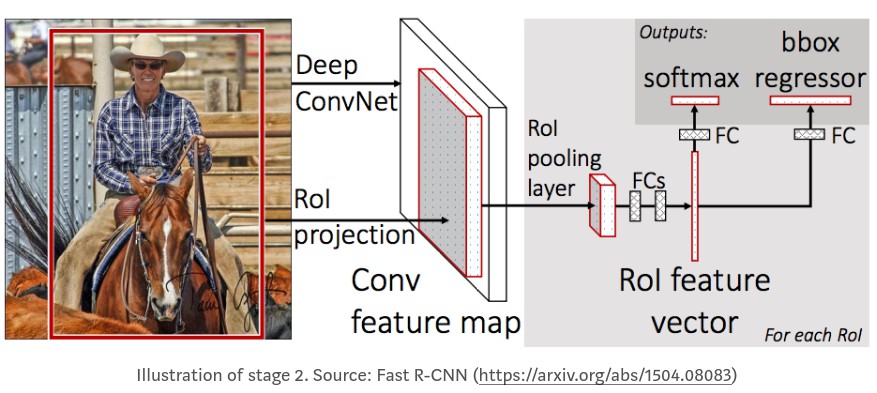
[1] - 类别Class, RoI 内的物体类别. 与 RPN只有两个类别(FG/BG) 不同的是, 该网络更深, 且能够对每个区域分类(如 person, car, chair 等). 同时也包含背景类, 表示要丢弃的 RoIs.
[2] - 边界框精炼Bounding Box Refinement, 与 RPN 非常相似, 其目的是进一步精调物体的边界框的位置和尺寸.
分类器和回归器的实现位于 fpn_classifier_graph().
2.4 RoI Pooling
在进行 RoI 分类前,需要处理的问题: 分类器不能很好的处理尺寸可变的输入.
分类器一般需要固定输入尺寸, 但是, 由于 RPN 中的 bounding box refinement 处理后, RoI boxes 具有不同的尺寸.
这就是 RoI Pooling 起作用的地方.
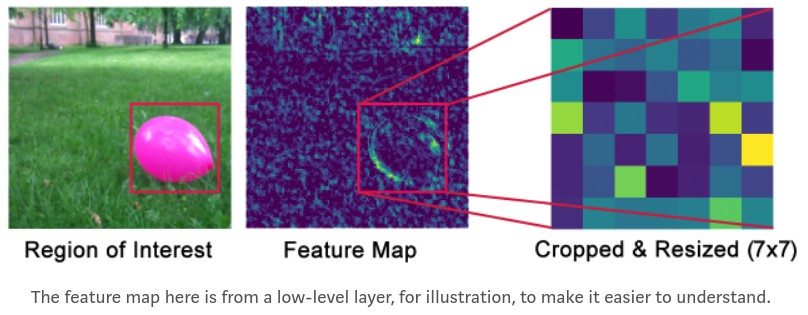
RoI Pooling 的作用是, 裁剪 feature map 的一部分, 并 resize 到固定尺寸. 类似于图片分类中, 裁剪图片的一部分, 然后 resize 到固定尺寸.(不过实现细节不同)
Mask R-CNN 提出了新的 RoIAlign 方法, 即, 从 feature map 的不同点进行采样, 并采用双线性插值.
这里的实现是, 采用 TensorFlow 中的 crop_and_resize 函数. 其已经很接近 RoIAlign 的作用.
RoI Pooling 的具体实现位于 PyramidROIAlign.
2.5 分割 Masks
到这里, 基本上介绍了 Faster R-CNN 目标检测框架.
分割 mask 网络是 Mask R-CNN 新引入部分.
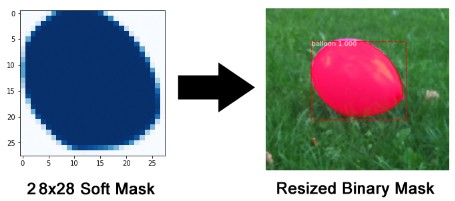
mask 网络分支是全卷积网络, 其采用 RoI 分类器选取的 positive 区域作为输入, 并生成其对应的 masks.
生成的 mask 的分辨率较低: 28x28.
但, 由于是浮点数表示的 soft masks, 相比于二值 masks, 保留了更多的细节.
小的 mask 尺寸有助于保持 mask 网络分支的轻量型.
训练时, 将 ground-truth masks 缩放到 28x28, 以进行 loss 计算.
推断时, 将预测的 masks 放大到 RoI 边界框的尺寸, 已得到每个物体最终的 masks.
mask 网络分支实现位于 build_fpn_mask_graph().
3. 构建颜色填充器
与很多图片编辑器不同的是, 这里构建的颜色填充器更智能: 自动寻找物体.
可以进一步应用到 Videos.

3.1 训练数据集
一般都是先寻找包含任务物体的公开数据集.
但,在这里要从零开始构建数据集.
从 flickr 上搜索气球图片, 从中选取了 75 张图片,并将它们划分为训练数据集和验证数据集.

寻找图片比较简单, 但标注图片比较棘手.
深度模型的训练需要百万级的图片? 也许是, 但一般来说不必这么多.
这里从两方面, 大幅降低训练条件:
[1] - 迁移学习. 相比于从零开始训练模型, 可以基于 COCO 数据集得到的模型权重开始训练. 尽管 COCO 数据集里没有气球balloon 类别, 但包含了大量的其它图片(约 120K). 因此, 模型已经学习了自然图片中通用的大量特征.
[2] - 该任务场景比较简单, 不需要太高的模型精度. 因此, 该小数据集应该够用.
图片标注现在有很多工具, 这里简洁起见, 采用 VIA(VGG Image Annotator) 标注图片.
标注结果是单个 HTML 文件, 可以下载,在浏览器中打开.
刚开始标注这些图片比较慢, 但很快适应工具后,就可以一分钟左右标注一个物体.
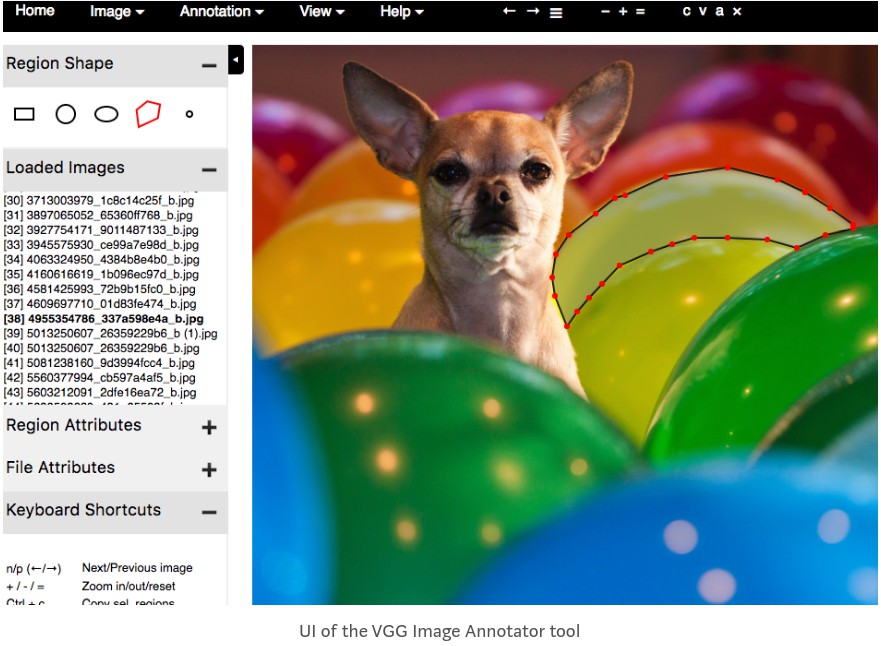
除了 VIA(VGG Image Annotator), 还有以下标注工具可用:
- LabelMe - 最有名的图片标注工具之一. 其 UI 有点慢, 尤其是在大图片的缩放时.
- RectLabel - 简单易用的工具, 只支持 Mac.
- LabelBox - 对于较大规模的项目比较好, 具有对不同标注任务的选项.
- VIA(VGG Image Annotator) - 快速,轻量, 设计好. 这里所采用的.
- COCO UI - COCO 数据集采用的标注工具.
3.2 加载数据集
语义分割 masks 还没有通用的存储格式, 比如 PNG 图片, 多边形点(polygon points) 等等.
为了便于处理, 这里给出 Dataset 类来便于数据加载. 可以重写几个函数来读取各种格式.
VIA 标注工具把图片标注结果保存为 JSON 文件, 每个 mask 是多边形点的集合.
一种重写适用新数据集读取的方法是, 复制 coco.py, 根据需要进行修改.
这里即采用该方式, 得到新文件 ballons.py.
如:
class BalloonDataset(utils.Dataset):
def load_balloons(self, dataset_dir, subset):
...
def load_mask(self, image_id):
...
def image_reference(self, image_id):
...
load_balloons- 读取 JSON 文件, 提取标注, 通过迭代地调用add_class和add_image函数来构建数据集.load_mask- 生成图片中有多边形标注的物体的位图 mask(bitmap mask).image_reference- 简单地返回一个字符串, 用于调试. 这里返回图片文件的路径.
可以看到, 该 BalloonDataset 不包括加载图片和返回边界框的函数.
默认的 load_image 函数可以加载图片.
边界框是由 masks 动态地生成的.
3.2.1 验证数据集
这里添加 inspect_balloon_data.ipynb 来验证数据集.
包括数据集加载, masks 和边界框的可视化, 以及 anchors 的可视化, 以确认 anchor 尺寸能够更好的拟合物体尺寸.
例如:

Sample from inspect_balloon_data notebook
复制用于 COCO 数据集的 inspect_data.ipynb, 修改以适用于 Balloons 数据集.
3.3. 配置
这里的配置类似于 COCO 数据集的基本设置. 仅修改了 3 个值, 继承了 Config 类:
class BalloonConfig(Config):
# Give the configuration a recognizable name
NAME = "balloons"
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # Background + balloon
# Number of training steps per epoch
STEPS_PER_EPOCH = 100
COCO 数据集的基本配置中, 为了获得较好精度, 输入图片的尺寸是 1024x1024. 这里仍采用相同的尺寸.
虽然 Balloon 数据集中的图片小一点, 但模型会自动的调整尺寸.
基本的 Config 类位于 config.py
新增的 BalloonConfig 类位于 balloons.py.
3.4 训练
Mask R-CNN 是相对较大的模型. 尤其是, 这里的实现采用 ResNet101 和 FPN.
因此, 需要显存 12 GB 的 GPU.
这里采用 Amazon’s P2 instances 来训练模型.
基于该小型数据集, 训练耗时不到 1 个小时.
从 balloon 路径运行下面命令,开始模型训练:
python3 balloon.py train --dataset=/path/to/dataset --model=coco
这里指定模型训练从 COCO 数据集预训练的模型开始. 代码自动从下载对应的权重文件.
如果中间停止了, 可以恢复训练:
python3 balloon.py train --dataset=/path/to/dataset --model=last
除了 balloons.py, 项目里还包括两个例子:
[1] - train_shapes.ipynb - 训练检测几何形状的模型.
[2] - coco.py - COCO数据集上的训练.
3.5 检查结果
inspect_balloon_model.ipynb 给出了训练模型生成的结果.
里面还有更多可视化以及逐步可视化检测流程的细节.
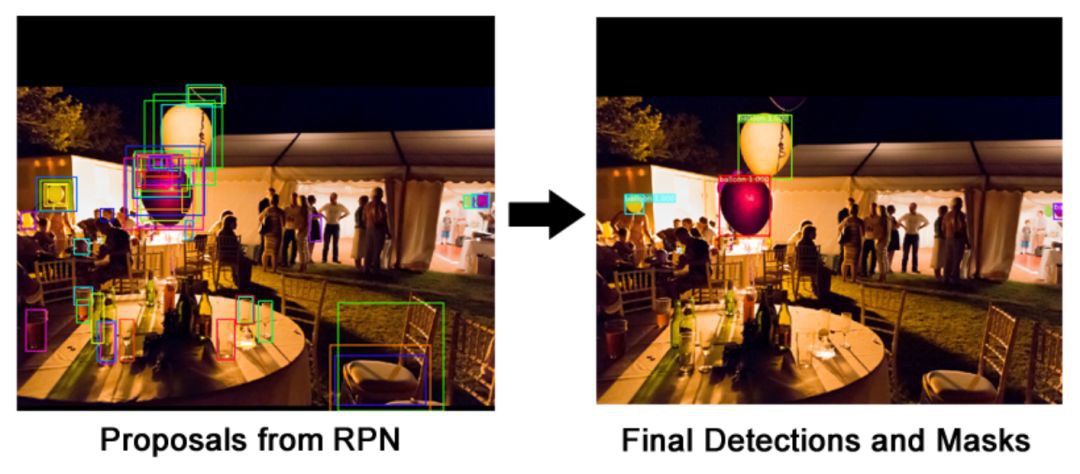
inspect_mode.ipynb 的简化版本, 其包括对 COCO 数据集的可视化和调试代码.
3.6 颜色填充 Color Splash
模型训练完成后, 即可用于颜色填充.
该方法比较简单: 创建图片的灰度图, 然后对物体 mask 标注的区域, 从原始图片复制颜色像素. 例如:

具体实现位于 color_splash() 函数.
detect_and_color_splash() 包含了加载图片, 运行实例分割, 颜色填充过滤.
相关论文
[1] - RCNN
[2] - Fast RCNN
[3] - Faster RCNN
[4] - FPN
[5] - Mask RCNN