论文:YOLACT: Real-time Instance Segmentation - 2019
作者:Daniel Bolya, Chong Zhou, Fanyi Xiao, Yong Jae Lee
团队:University of California, Davis
YOLACT(You Only Look At CoefficienTs) 论文主要是提出了一种简单、快速的实时实例分割的全卷积模型,基于一块 Titan Xp 显卡,在 MS COCO 数据集上取得了 29.8 mAP 的精度,33fps 的速率. 此外,其仅是基于单张 GPU 训练得到的.
部分实例分割方法的精度与速率对比,如图:
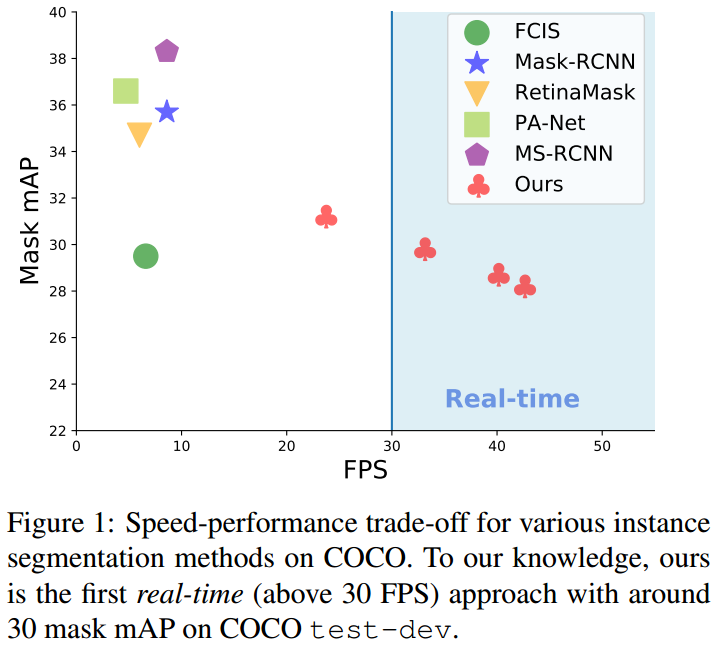
Fig 1. 基于 COCO 数据集不同实例分割方法的速度与精度情况. YOLACT 第一次在 COCO test-dev 数据集取得了实时检测(大于 30 FPS)及约 30 的 mAP.
YOLACT 主要特点与贡献点:
[1] - 将实例分割划分为两个并行任务:
- (1)生成整张图片的非局部非原型mask的字典 (generating a dictionary of non-local prototype masks over the entire image.)
- (2)预测每个实例的线性组合系数集合(predicting a set of linear combination mask coefficients per instance.)
[2] - 建立 prototype masks 和 mask coefficients 之间的线性组合,以得到实例 masks.
- 由于不依赖于 repooling 操作,故可以得到高质量的 masks 以及较高的时序稳定性(temporal stability).
- 根据 prototype mask 和 mask coefficients 得到整张图片的实例分割的处理:对于每个实例,线性组合 prototypes 及对应的预测 coefficients,然后再根据预测的边界框裁剪实例 mask.
- 这种分割方式,网络自身会学习如何定位实例 masks(the network learns how to localize instance
masks on its own),视觉上、空间上以及语义上相似的实例可能在 prototypes 是不同的. - prototype masks 的数量与物体类别无关(如,类别数量可能多于 prototypes 的数量),YOLACT 实际上是学习了一种分布表示,每一个实例被分割为被多个类别共享的 prototypes 的组合(each instance is segmented with a combination of prototypes that are shared across categories.) 在 prototype 空间,某些 prototypes 对图片空间分块,某些 prototypes 定位实例,某些 prototypes 检测实例廓形,某些 prototypes 编码位置敏感的方向图(position-sensitive directional maps),等等,这些 prototypes 的组合构成了最终的分割结果.
[3] - 提出 Fast NMS,在仅很少损失精度,对比标准 NMS 处理,有 12-ms 的速率提升.
YOLACT 的主要优势:
[1] - Fast: 并行化网络任务分支以及及其少量的线性组合处理. 相对于 one-stage backbone 检测器,仅新增了很少的计算量,甚至在采用 ResNet-101 时也取得了 30 FPS.
[2] - High-quality Masks: masks 是采用了全部的图片空间的信息,没有 repooling 的质量损失,对于大目标物体的 masks 明显高于其它方法.
[3] - General: 生成 prototypes 和 mask coefficients 的思想几乎可以用于任何深度学习目标检测器.
1. YOLACT Prototypes 与 BoFs
在阅读 YOLACT 论文的时候,发现 prototypes 和 coefficients 与计算机视觉中的 BoF(Bag of Feature) 方法有很大的相关性.
Prototypes,也可以叫作词汇(vocabulary)、编码本(codebook).
BOF 是一种图像特征提取方法,其实际上起源于文本领域的 BoW(Bag of Words) 模型. BoW 假定对于一个文本而言,忽略其词序、语法、句法等,仅看作是一个个词语的组合,每个词的出现都是相互独立的,不依赖于其它词的出现.
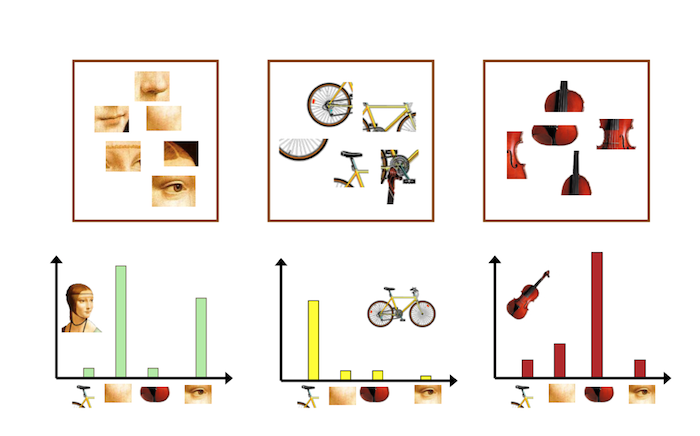
BOF 假设图像相当于一个文本,图像中的不同局部区域或特征可以看作是构成图像的词汇(codebook). 如图:

根据得到的图像的词汇,统计每个单词的频次,即可得到图片的特征向量,如图:
参考:
[1] - 浅析 Bag of Feature
YOLACT 中的 Prototypes 与 BOFs 类图像特征提取方法的区别是:
[1] - BOFs 是特征提取方法,其采用 prototypes 来表示特征;而 YOLACT 将 prototypes 用于生成实例分割的 masks.
[2] - YOLACT 是针对每张图片学习 prototypes,而 BOFs 是对整个数据集所学习的全局共享的 prototypes.
2. YOLACT 方法
YOLACT 旨在采用类似于 Mask R-CNN 对于 Faster R-CNN的方式,对已有 one-stage 目标检测模型添加一个 mask 分支. 所采用的方式即为,将复杂的实例分割任务分解为两个更简单的、并行化的任务,并可以组合为最终的 masks:
[1] - 并行化分支一:采用 FCN 生成图像大小(image-sized)的 prototype masks 集合,其不依赖于任何一个实例.
[2] - 并行化分支二:在目标检测分支添加一个额外的 head,用于预测每个 anchor 的 mask coefficients 向量,其编码了在 prototype 空间每个实例的表示.
[3] - 最后,对于 NMS 处理后得到的每个实例,线性组合两个分支所输出的 prototypes masks 和 mask coefficients,即可生成实例的 mask 分割结果.
YOLACT 结构如图:
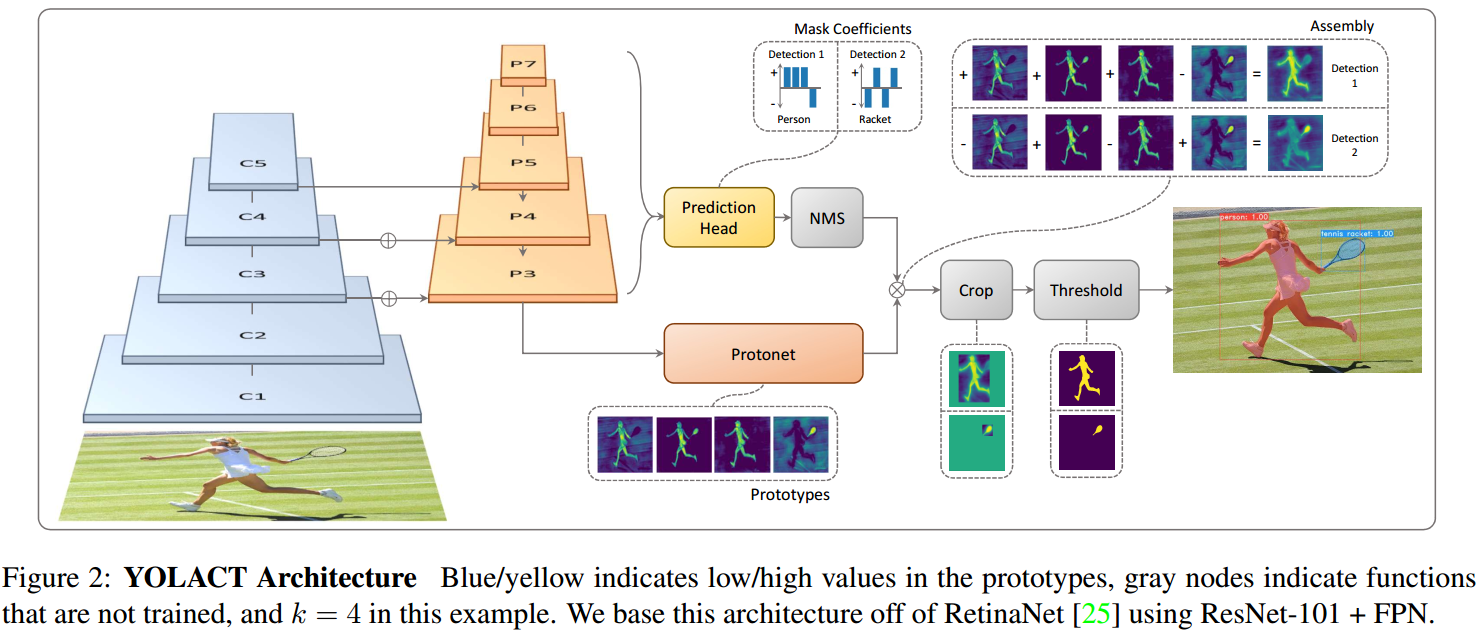
2.1. 基本原理
YOLACT 实例分割所基于的基本原理是,masks是空间语义连贯的(mask are spatially coherent),如相互接近的像素更可能是相同实例的一部分.
卷积层利用了 masks 的空间语义连贯性,但是全连接层却是无法学习该信息的. 这就遇到了一个问题:由于 one-stage 目标检测器是以全连接层的输出作为每个 anchor 的类别和边界框系数的;two-stage 的方法,如 Mask R-CNN 是通过一个定位处理,如 RoIAlign 层,以保持特征的空间连贯性,并采用卷积层输出实例 masks. 不过,这种方法需要模型里实例分割要等着 first-stage RPN 来生成候选边界框,导致速度明显受影响.
YOLACT 将问题分解为两个并行化分支,使用全连接层来生成语义向量;使用卷积层来生成空间连贯的 masks,以分别得到 mask coefficients 和 prototype masks. 由于 prototypes 和 mask coefficients 可以分别独立进行计算,因此其新增的计算大部分来自于线性组合处理,其实现可以看作是矩阵相乘(matrix multiplication). 这样就实现了同时保持了在特征空间的空间连贯性和 one-stage 的快速.
2.2. Prototype 生成
YOLACT 的 prototype 生成分支(protonet) 会输出整张图片的 k 个 prototype masks 集合.
Protonet 是 FCN 网络,其输出层包含 k 个通道(channels),每个通道分别表示一个 prototype. 如图Fig3. Protonet 类似于语义分割任务,但其不同之处在于,其没有具体的关于 prototypes 的 loss;所有的监督都来自于线性组合后最终的 mask loss.
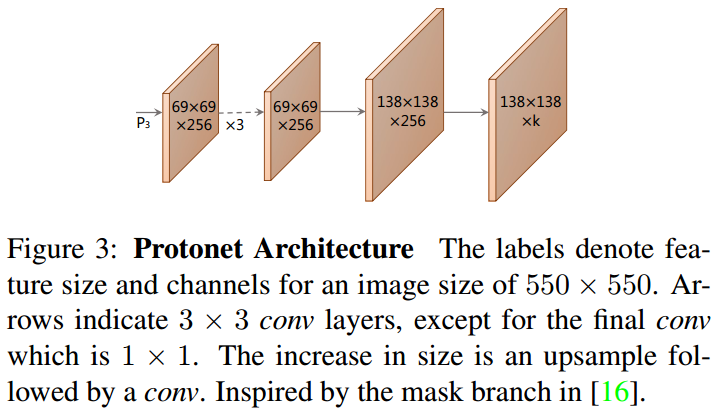
这里包含两个重要的网络设计选择:
[1] - 采用 deeper backbone 特征的 Protonet 能够生成更鲁棒的 masks;
[2] - 更高分辨率的 prototypes 能够得到更高质量的 masks 以及对于小目标物体具有更好的性能.
因此,YOLACT 采用 FPN 网络,因为 FPN 的最大特征层(如 Fig2 中的 $P_3$) 是最深的网络层. 因此,将 $P_3$ 上采样到输入图片尺寸的四分之一大小,以增强对于小目标物体的效果.
最后,Protonet 网络输出的无界性(unbounded) 也是非常重要的,因为其使得网络能够对于 prototypes 非常置信的地方,生成更大的、更强的激活值(如,明显是背景的区域). 因此,YOLACT 采用 ReLU 激活函数以得到解释性更好的 prototypes.
2.3. Mask Coefficients
一般来说,anchor-based 目标检测器包含两个预测输出分支:(1)分支一预测 c 个类别置信度;(2)分支二预测 4 个边界框回归值.
对于 mask coefficients 预测,YOLACT 只需添加一个并行化分支,用于预测 k 个 mask coefficients,每个 coefficient 分别对应一个 prototype. 因此,对于每个 anchor 而言,其不是生成 $4+c$ 个 coefficients,而是 $4+c+k$ 个.
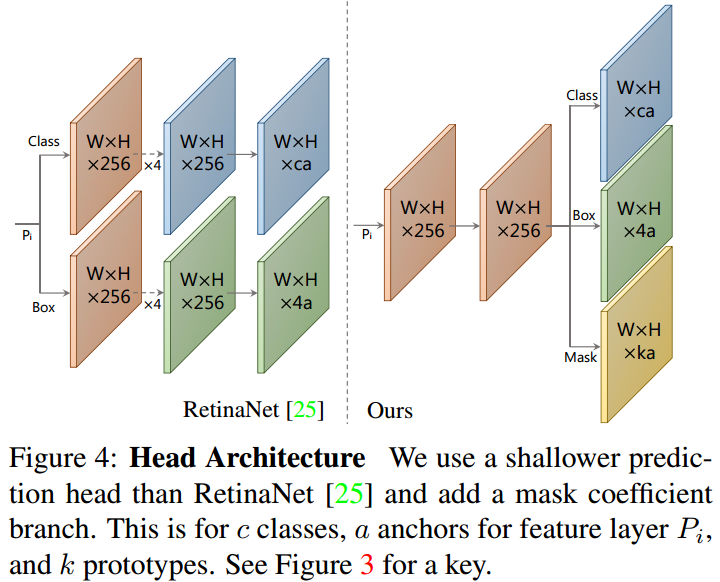
另外,非线性(nonlinerity)对于最终 mask 的 prototypes 提取也是很重要的. 因此,YOLACT 对 k 个 mask coefficients 采用 tanh 激活函数处理,以生成更加稳定的非线性输出.
2.4. Mask 组合
在得到 mask prototypes 和 mask coefficients 后,采用线性组合处理,并再接 sigmoid 非线性函数,以生成最终的 masks. 该过程可以记为矩阵相乘与 sigmoid 的实现如下:
$$ M = \sigma(PC^T) $$
其中,$P$ 为 $h \times w \times k$ 的 prototype masks 矩阵;
$C$ 为 $n \times k$ 的 mask coefficients 矩阵;$n$ 为 NMS 和阈值处理后得到的 $n$ 个实例数.
2.5. Losses
YOLACT 模型训练时,采用了三个 losses 函数:
[1] - 分类loss $L_{cls}$
[2] - 边界框回归 loss $L_{box}$
[3] - mask loss $L_{mask}$,计算的是组合的 masks $M$ 与 GT masks $M_{gt}$ 之间的逐像素的二值交叉熵:$L_{mask} = BCE(M, M_{gt})$.
2.6. Masks 裁剪
为了能在 prototypes 中保留小目标物体,YOLACT 在预测阶段,会根据预测边界框对最终的 masks 进行裁剪.
在训练时,YOLACT 是根据 GT 边界框对预测 masks 进行裁剪,并根据 GT 边界框区域划分 $L_{mask}$.
2.7. Emergent Behavior
实例分割任务中,通常需要考虑平移变化(translation variance)问题.
YOLACT 在处理实例分割时,出现平移变化(translation variance) 之处仅有采用预测的边界框对最终的 mask 进行裁剪的操作. 然而,实际上,对于中型及大型目标物体,不需要裁剪操作,YOLACT 也是有效的. YOLACT 通过对其 prototypes 的不同激活值,能够在网络自身学习到如何定位实例的能力. 对此,这里如图 Fig 5 例示.

Fig 5. 不同图片的相同的六种 prototypes 的激活情况例示. Prototype 1,4和5 是在图片 a 中具有清晰便捷定义的分割图;prototype 2 是 bottom-left 方向图;prototype 3 分割出背景,并给出了实例的轮廓;prototype 6 分割出了地面 (ground).
在上图 Fig5 中,红色方块图像(图像 a)的 prototype 激活值实际上是不能以 FCN without padding 操作来得到. 因为卷积输出单个像素,如果卷积的输入中图像中的各区域都是相同的,则,卷积的输出结果也应该是相同的. 另一方面,FCNs 网络中,如 ResNet,padding 操作使得网络能够知道某个像素距离图像边缘的距离. 从概念上来讲,其可以通过序列化的多个网络层,从边缘向中心逐步 padding 0 操作(如 kernel 为[1, 0]). 以ResNet 为例,其具有平移变化(inherently translation variant),YOLACT 充分利用了该特点(如Fig 5 的图像 b 和图像 c 表现处理很明显的平移变化.)
另外,对于待学习的目标物体,prototypes 是可压缩的. YOLACT 即使在有 32 个 prototypes 的情况下,模型表现并没有退化.
3. Backbone 检测器
对于 backbone 检测器,YOLACT 同时关注速度与特征的信息丰富度,因为 prototypes 和 coefficients 的预测是比较困难的任务,需要利用较好特征. 因此,采用了类似于 RetinaNet 的网络.
3.1. YOLACT 检测器
采用 ResNet-101 with FPN 作为默认的特征 backbone 网络,输入图像尺寸为 550x550. 但没有保持长宽比(aspect ratio).
类似于 RetinaNet,YOLACT 对 FPN 进行修改,不采用 $P_2$、 $P_6$ 和 $P_7$ 的输出,从 $P_5$ 开始采用连续的 $3 \times 3$、步长为 2 的卷积层,并分别放置长宽比为 [1, 1/2, 2] 的 3 个 anchors. $P_3$ 的 anchors 的面积为 24 pixels 方形,且其后的 $P_4, P_5, P_6, P_7$ 的尺寸依次翻倍,即:[24, 48, 96, 192, 384]. 对于接每个 $P_i$ 的预测 head 网络,采用被所有 3 个分支共享的 $3 \times 3$ 卷积操作,然后每个分支并行地分别采用对应的 $3 \times 3$ 卷积操作.
对比于 RetinaNet,YOLACT 的 head 网络设计(Fig4所示) 更加轻量和快速.
YOLACT 采用 smooth-L1 loss 来训练 box 回归器,并采用与 SSD 相同的方式编码 box 回归坐标值.
YOLACT 采用 softmax 交叉熵 loss 来对 c 个类别标签(positive labels)和 1 个背景类别(background label)进行处理. 采用 OHEM 选择训练样本,$neg:pos=3:1$.
与 RetinaNet 不同的是,YOLACT 未采用 focal loss.
4. Fast NMS
在得到每个 anchor 的边界框回归系数和类别置信度后,类似于目标检测,YOLACT 也采用 NMS 去除重复的检测结果.
通常情况下,NMS 是序列的处理的,即:对于数据集中的 c 个类别中的每一个类别,首先根据置信度,对检测到的边界框降序排列;然后,对于每个检测结果,移除所有比其置信度小的以及与其 IoU 的重叠程度大于设定阈值的检测结果.
目标检测 - NMS非极大值抑制计算 - AIUAI
YOLACT 中 Fast NMS 可以并行地对每个实例进行判读是保留还是丢弃,其实现如下:
[1] - 首先根据数据集中 $c$ 个类别中每一类的置信度排名,计算 top n 个检测结果成对间的 IoU,得到 $c \times n \times n$ 的矩阵$X$(对角矩阵).
[2] - 然后,通过判断是否有置信度较高(higher-scoring)的检测结果,其对应的矩阵 $X$ 中的 IoU 元素值大于设定阈值 $t$,以得到待删除的检测结果. 具体地,
首先设置对角矩阵 $X$ 的下三角和对角元素的值为0:
$$ X_{kij} = 0, \forall k, j, i \geq j $$
然后,逐列求 max,以计算得到由每个检测结果的最大 IoU 值组成的矩阵 $K$:
$$ K_{kj} = max _{i} (X_{kij}), \forall k, j $$
- 最后,对矩阵 $K$ 求阈值 $t$,$K < t$,即可得到对于每个类别所保留的检测结果.
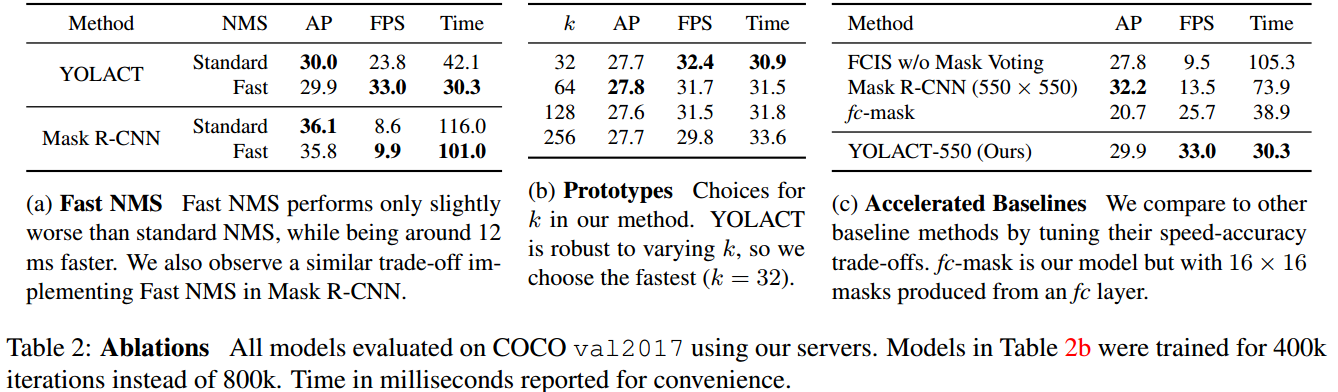
5. Results
5.1. 实例分割
在 COCO test-dev 数据集,基于单张 Titan Xp 显卡,不同方法的对比结果吐下:
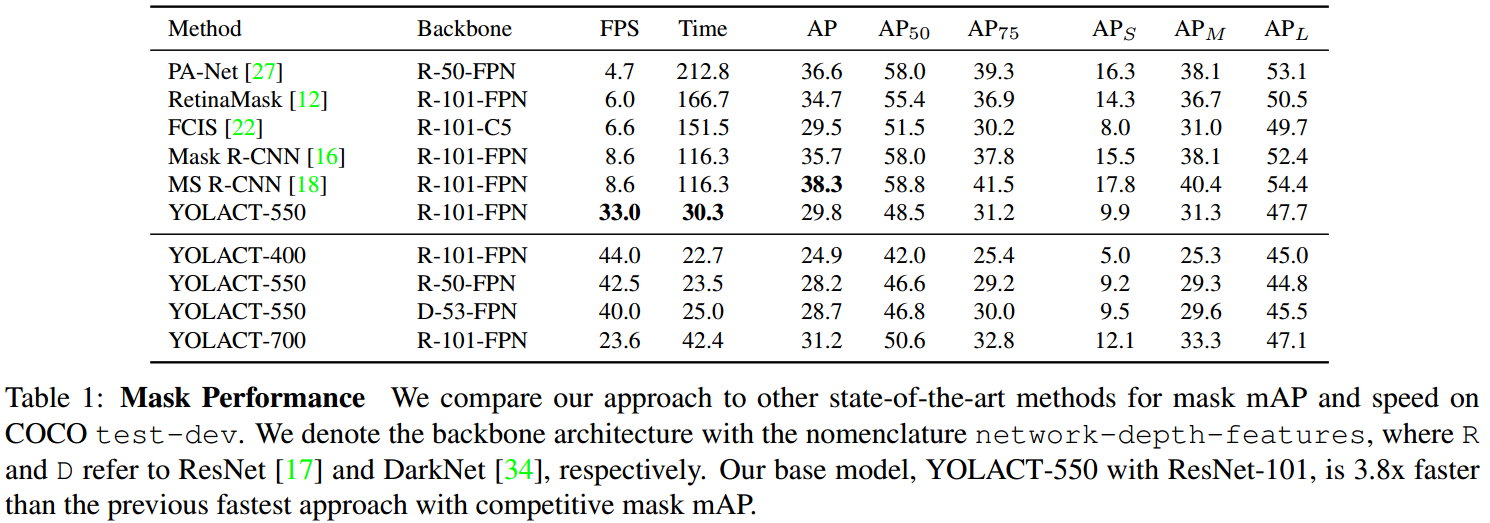
除了采用的 550x550 分辨率的输入,即 YOLACT-550 模型,还采用了 400x400 和 700x700 的输入图片尺寸分别训练了 YOLACT-400 和 YOLACT-700 模型,其中,anchor scales 采用等比例的调整($s_x = s_{550} / 550 * x$).
降低输入图片的尺寸会导致模型精度出现较大的衰退,说明实例分割需要较大尺寸的图片. 增大图片尺寸会导致速度明显降低,但可以增加模型精度.
除了 ResNet-101 backbone 网络,还测试 ResNet-50 和 DarkNet-53,可以得到更快的速率. 如果需要更快的检测速度,建议采用 ResNet-50 或 DarkNet-50,而不是降低输入图片尺寸.


5.2. Mask Quality
由于 YOLACT 最终输出的 mask 尺寸为 $138 \times 138$,且直接根据原始特征来生成的 masks(无需 repooling 变换以及没有特征 mis-align 问题),因此,YOLACT 对于大目标的检测结果的 mask 质量是高于 Mask R-NN 和 FCIS 的(虽然mAP 略低). 如图 Fig 7.

5.3. Ablations