题目: Fully Convolutional Instance-aware Semantic Segmentation - CVPR2017
作者: Yi Li1, Haozhi Qi, Jifeng Dai, Xiangyang Ji, Yichen Wei
团队: Microsoft Research Asia, Tsinghua University
主要基于:
- FCNs for Semantic Segmentation 基于FCN的语义分割. 传统FCNs卷积具有平移不变性, 但实例分割需要平移可变.
- instance mask proposal 实例 mask 候选
现阶段instance semantic segmentation 方法:
1. 整张图像进行FCN处理,得到中间的共享feature maps;
2. 对于得到的feature maps,采用pooling层将各个 region of interest (ROI)变换到固定尺寸的per-ROI feature maps;
3. 在网络最后,采用一个或多个全连接层(fully-connected(fc) layer)将per-ROI feature maps转换成per-ROI masks. 这里的平移不变形是在 fc 层实现的.
现阶段instance semantic segmentation 存在的问题:
- ROI pooling 进行 feature warping 和 resizing变换,以确保fc层有固定尺寸的输入,导致feature空间特征信息损失. 对于大物体的segmentation影响较大;
- fc层参数较多,容易过拟合;
- 最后处理时,每个ROI都要过一次fc层,ROIs间不能进行参数共享,耗时多.
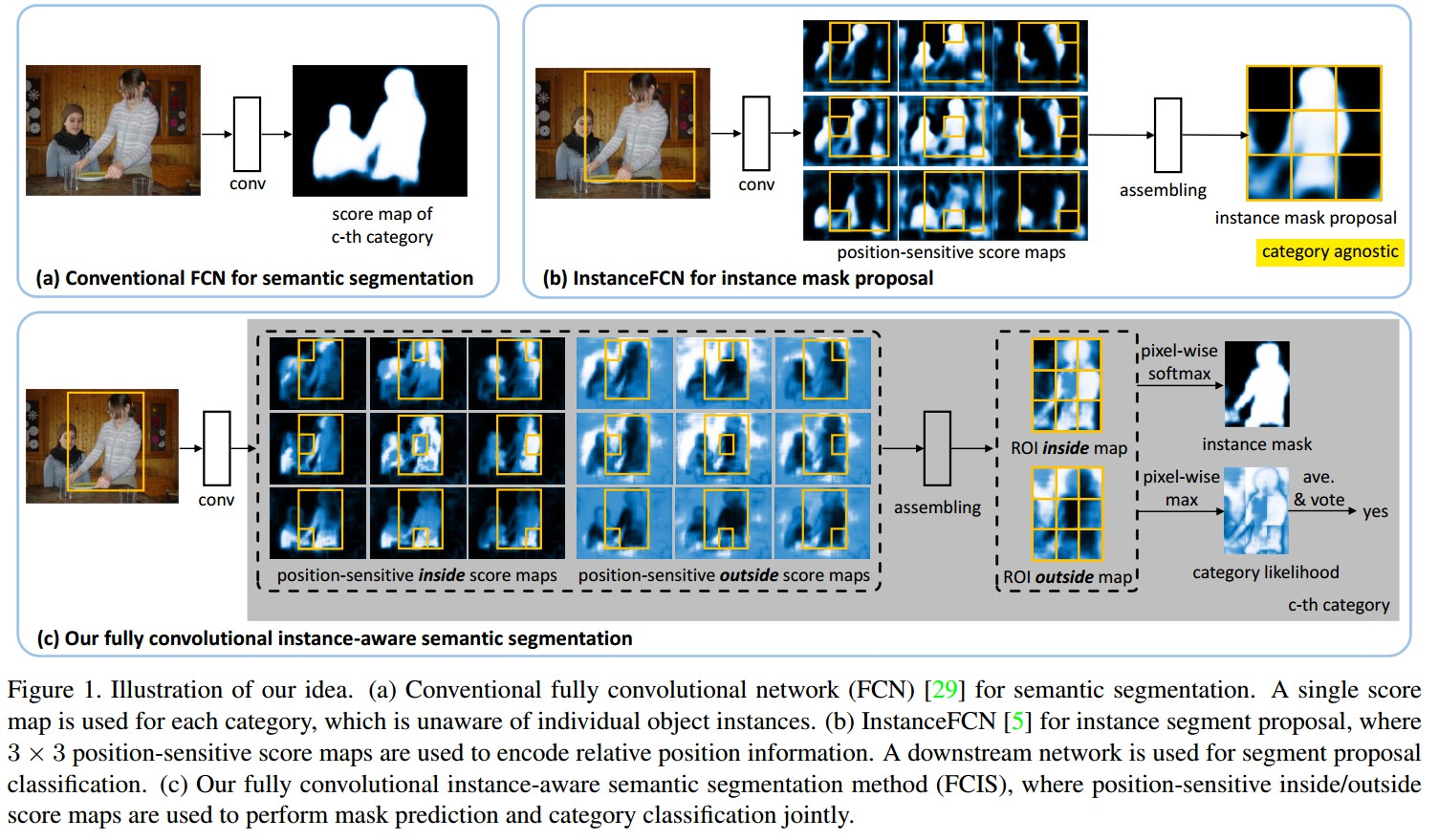
- a. 基于FCN的语义分割
- b. InstanceFCN的实例mask proposal. 该方法将传统FCNs方法的平移不变的score maps扩展成 position-sensitive score maps. 3x3 张 score map,分别取 ROI 的不同位置区域块,再汇聚成一个ROI.
其不足之处在于,不能直接得到语义类别,需要添加类别分类网络. mask预测和类别预测是分开的,也是非End-to-End的. 另外,采用方形的、固定尺寸(224×224)的平滑窗口处理,并采用十分耗时的image pyramid scanning来寻找不同尺度下的实例. 其结构如下:
- c. Fully Convolutional Instance-aware Semantic Segmentation(FCIS)。 扩展了InstanceFCN. 底层的卷积表示和score maps是全部共享参数的,以进行mask预测和类别估计. End-to-End的.
相比InstanceFCN, FCIS 引入了 inside/outside score maps,同时处理分割和分类任务,并考虑了两个任务间的相关性.
FCIS
Position-sensitive Score Map Parameterization
FCNs中,训练分类器来预测每一个像素点归属于某个物体类别的概率.
FCNs具有平移不变性,比如图片中的物体不管位于那个位置,都会被分类为该物体.
FCNs不能辨别独立的物体实例, 比如相同的像素点,对于一个物体是前景,但对于其它的物体,该像素点是后景.
每个类别的单个score map不足以进行区分.
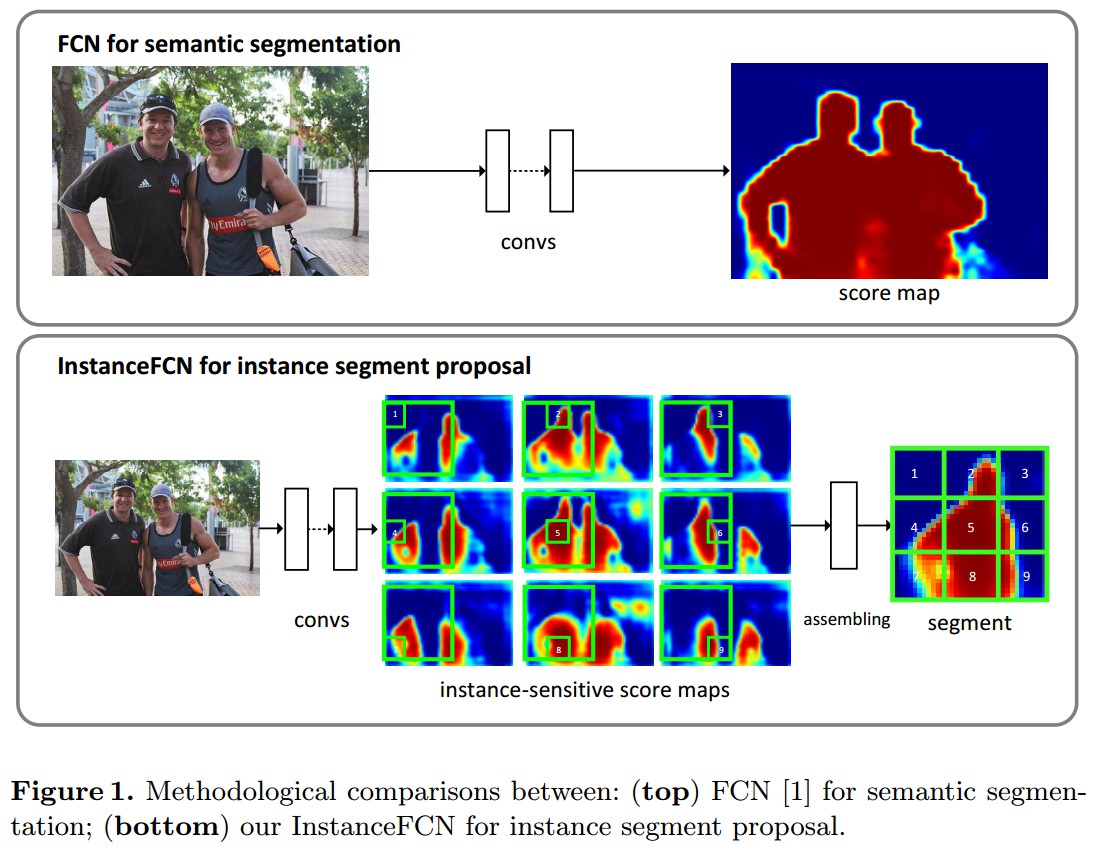
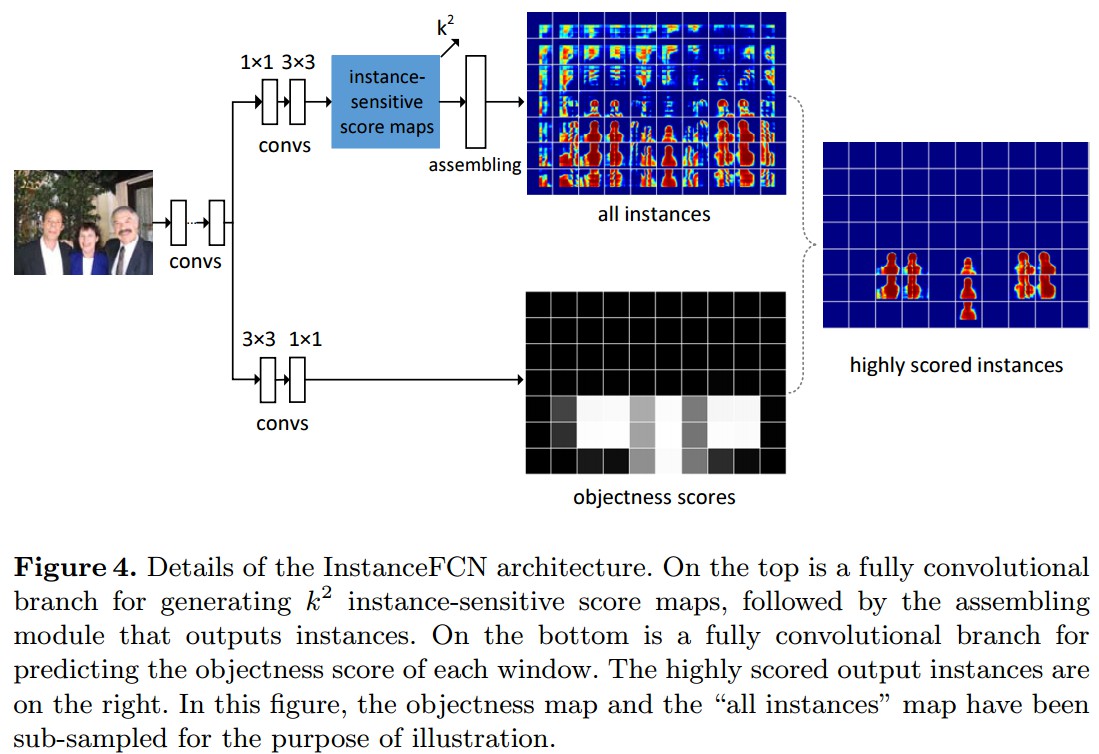
在InstanceFCN中,引入平移可变性,采用全卷积网络来获得实例mask proposal.
采用 k^2 个 position-sensitive score maps,对应了 k×k 对物体的均分单元格. 如(b).
每个score map具有原始图片的相同空间范围,分辨率较低,比如16×.
每个score表示在相对位置中,像素点属于某个物体实例的概率. 如(b)中,第一个map是左上角位置.
在训练和推断过程,对于一个固定尺寸的方形平滑窗,224×224,其像素级的前景概率map是通过组合(copy-paste, 复制粘贴)对应score maps的 k×k 单元格得到的. 这样,当像素点在实例的不同相对位置时,就会对不同的实例有不同的scores.
联合 Mask 预测和分类
如图(c)和下图所示:

对于每个物体类,基于网络卷积层得到两个 k^2 score maps的集合,在每个单元格,每个像素点都有两个scores,表示该像素在某个相对位置属于某个物体实例的概率和该像素在物体边界之内(或之外)的概率.
给定一个ROI区域,通过对ROI内的assembling处理,得到逐像素的inside和outside概率maps.
这两个score maps联合进行mask预测和mask分类.
对于mask预测,采用softmax,得到每个像素的前景概率([0,1]);
对于mask分类,采用max,得到每个像素属于某个物体类的概率. 整体ROI的分类score是通过对所有像素的概率求平均pooling得到.
对于 positive ROI,score对的(inside, outside) 中一个大,则另一个小,取决于对应的像素是inside物体边界,还是outside物体边界.
对于 negative ROI,所有的scores都是小的.
- 所有的 per-ROI 都没有多余的参数
- 只需要单个FCN,即可得到score maps,无需任何的feature warping、resizing或者全连接层
- 所有的特征和score maps反映了原始图片的纵横比
- 保留了FCNs的局部权重共享特点,并作为正则项
- 所有的 per-ROI计算简单快速( k^2 个单元格划分、复制score map、softmax、max、平均pooling),计算代价几乎可以忽略.
端对端
如图:
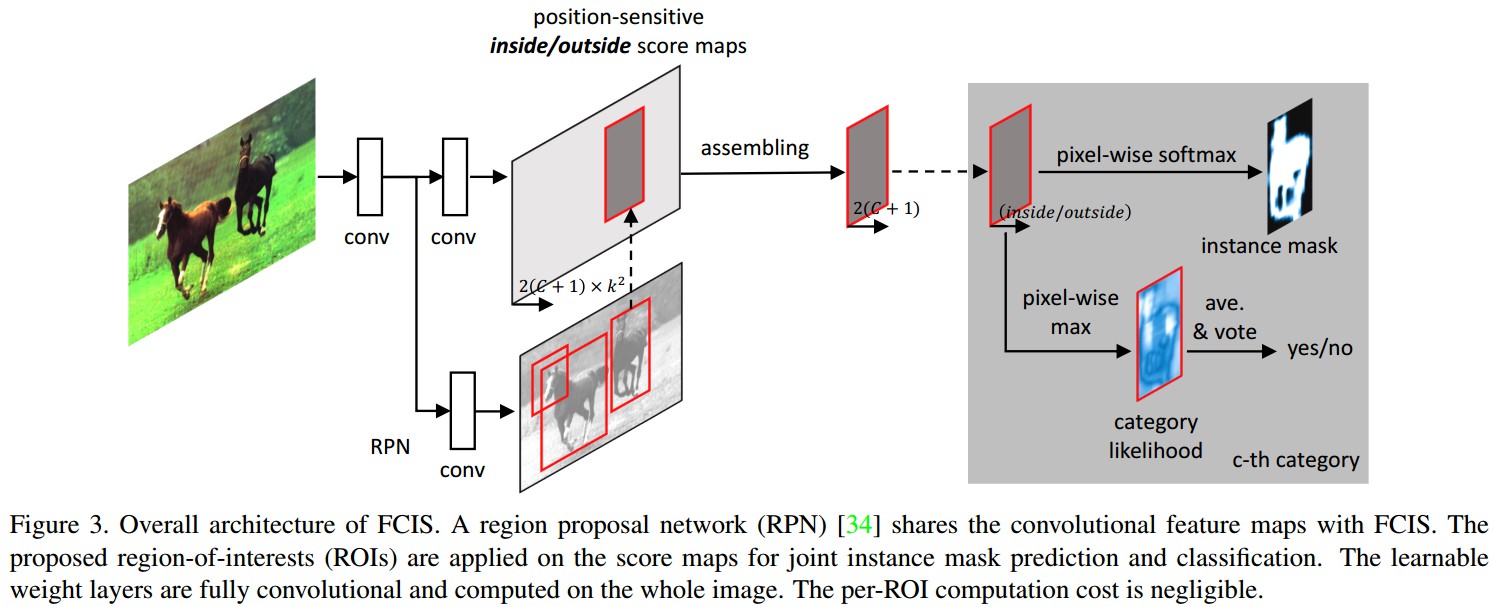
- end-to-end
- 基于ResNet,去除了最后1000-way分类的全连接层,只重新训练卷积层,得到的feature maps是 2048 channels的,采用 1×1 卷积层降维到 1024 channels
- 采用 hole algorithm 减少特征步长,保持接受野
- 原始的ResNet网络,最终的有效的特征步长(feature map的分辨率)是32,conv5 卷积层的第一个block的步长由 2 减少为 1,则有效的特征步长减少到了16
- 对conv5的所有卷积层采用 hole algorithm,设置dilation=2
- 采用 region proposal network (RPN) 得到ROIs. RPN 也是全卷积网络. RPN 与 FCIS 共享卷积层.
RPN 产生的兴趣区域 (RoI) 作用于 score maps,同时产生分类和分割预测. 在整张图像上进行计算.
- 根据 conv5 的feature maps,可以得到 2k^2×(C+1) 个score maps,[C个物体类别,一个背景类,每个类有两组 k^2 score maps集合,这里默认 k=7]. 针对score maps,每一个ROI被投影成 16× 的小区域,以计算分割概率图和类别概率.
- 基于目标检测方法, 边界框(bbox)回归以进一步精炼初始化输入ROIs. 一组 1×1 的卷积层( 4k^2 channels) 添加到 conv5 的feature maps上,以估计边界框的位置平移和大小.
推断
对于输入图像,采用 RPN 方法得到最高score的300个ROIs;
并经过 bbox回归分支,得到新的 300个ROIs.
对于每个ROI,得到其对所有类别的分类score和前景mask(概率形式). 如Figure 2所示.
采用IoU阈值0.3的Non-maximum suppression (NMS)方法来去除重合度较高的ROIs. 将剩余的ROIs根据最高的分类scores来进行分类.
前景masks是根据mask voting得到的. 对于一个ROI, 所有的ROIs(共600个)的IoU scores大于0.5.
类别的前景masks进行逐像素的平均,并根据像素的对应分类scores进行加权. 平均后的mask进行二值化作为输出.
训练
- 如果ROI的box与最近的ground truth(GT)物体的IoU大于0.5,则该ROI是positive的;否则,该ROI是negative.
- 每个ROI有三个权重一样的loss项(后两个loss仅对positive ROIs有效):
- softmax分类loss, C+1类
- softmax分割loss, GT类别的前景mask
- bbox回归loss
- 从ImageNet分类的预训练模型进行初始化,其它的权重进行随机初始化
- 训练图像尺寸调整到一个短边为600像素
- SGD 优化
- 8 GPUs, 每个GPU的 mini-batch 为 1,最终的 batch-size 为 8
- PASCAL VOC, 共30K次迭代, 前20K次迭代的学习率为 10^{-3},后10K次迭代的学习率为 10^{-4}.
- COCO, 迭代次数是 VOC 的8倍
- online hard example mining(OHEM). 在每个mini-batch, 对一张图片的全部300个ROIs进行前向传播计算,选取其中的128个具有最大loss的ROIs进行后向传播计算其误差梯度
- 对于 RPN proposals, 默认9个anchors(3尺度 × 3纵横比). COCO多三个anchors
- FCIS和RPN联合训练,以实现特征共享
Result
On COCO: