在论文 Context Encoding for Semantic Segmentation - CVPR2018 看到关于Multi-GPU Batch Normalization 数据同步的一种实现. 学习记录下.
对于语义分割而言,更大的输入图片尺寸,往往能够得到更好的分割效果. 但是,这也就需要消耗更大的 GPU 显存,也就使得 Batch Normalization 的 batchsize 比较小,影响模型训练. 因此,论文作者基于 PyTorch 实现了一种采用 NVIDIA CUDA 和 NCCL 工具包的跨GPU的 BN 同步(Synchronized Cross-GPU Batch Normalization).
1. BN 原理
论文 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift - 2015 中提出的 BN 层,可以显著提升网络的训练速度(使得可以使用更大的学习率),并降低了网络对于初始化权重的敏感性.
网络训练时,BN 层的计算如图:
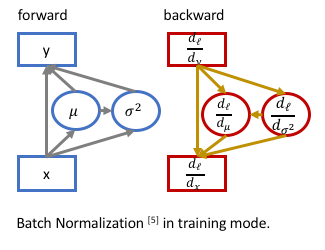
[1] - Forward 计算
对于输入数据 $X = x_1, ..., x_N$,其先被归一化为 0 均值、方差为 1(zero-mean, unit variance),然后进行缩放和平移(scale, shit):
$$ y_i = \gamma \cdot \frac{x_i - \mu}{\sigma} + \beta $$
其中,$\mu = \frac{\sum_i^N x_i}{N}$,$\sigma = \sqrt {\frac{\sum_i^N(x_i - \mu)^2}{N} + \epsilon }$.
$\gamma$ 和 $\beta$ 为 BN 的待学习参数.
[2] - Backward 计算
为了计算梯度 $\frac{d_{l}}{d_{x_i}}$,由于 $\mu$ 和 $\sigma$ 是关于输入 $x_i$ 的函数,因此,需要考虑偏微分 $\frac{d_l}{d_y}$ 和梯度 $\frac{d_l}{d_{\mu}}$ 和 $\frac{d_l}{d_{ \sigma }}$.
即:
$$ \frac{d_l}{d_{x_i}} = \frac{d_l}{d_{y_i}} \cdot \frac{\partial{y_i}}{\partial{x_i}} + \frac{d_l}{d_{\mu}} \cdot \frac{d_{\mu}}{d_{x_i}} + \frac{d_l}{d_{\sigma}} \cdot \frac{d_{\sigma}}{d_{x_i}} $$
其中,$\frac{\partial{y_i}}{\partial{x_i}} = \frac{\gamma}{ \sigma}$,$\frac{d_l}{d_\mu} = - \frac{\gamma}{\sigma} \sum_i^N \frac{d_l}{d_{y_i}}$,$\frac{d_{\sigma}}{d_{x_i}} = - \frac{1}{\sigma}(\frac{x_i - \mu}{N})$.
2. Synchronize BN
[1] - 由于在很多深度学习框架中,如 Caffe,MXNet,Torch,TF,PyTorch 等,所实现的 BN 层,都是非同步的(unsynchronized),即,只是在每个 GPU 上进行归一化. 因此,训练的时候实际的 BN 层的 batch-size 为: $\frac{BatchSize}{nGPU}$. 如图:
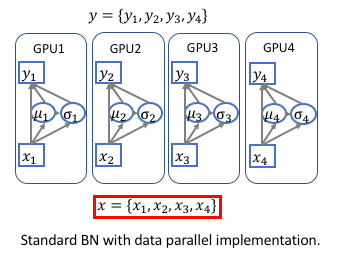
[2] - 对于很多视觉任务,如分类和检测,batch-size 是足够的,因此不需要在训练的时候使用 synchronize BN 层. synchronization 反而会导致训练速度减慢.
[3] - 但是,对于语义分割而言,很多方法往往会采用 dilated conv,其是非常消耗内存的. 在使用比较大和深的预训练网络时,如 encoding.dilated.ResNet 和 encoding.dilated.DenseNet,会导致 BN 层的 batch-size 比较小(每个 GPU 是 2 或 4.)
Synchronize BN:
假设有 $K$ 个 GPUs,$sum(x)_k$ 和 $sum(x^2)_k$ 分别表示第 k 个 GPU 的元素总和和元素平方和. 如图:
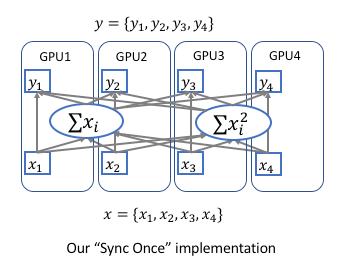
[1] - Forward 计算
首先,计算在每个 GPU 上,元素的总和 $sum(x) = \sum x_i$ 和元素平方和 $sum(x^2) = \sum x_i^2$;
然后,采用 encoding.parallel.allreduce 操作对所有 GPUs 相加;
接着,计算全局的均值和方差:$\mu = \frac{sum(x)}{N}$,$\sigma = \sqrt{\frac{sum(x^2)}{N} - \mu^2 + \epsilon}$.
[2] - Backward 计算
首先,对每个 GPU 单独计算 $\frac{d_l}{d_{x_i}} = \frac{d_l}{d_{y_i}} \cdot \frac{\gamma}{\sigma}$;
然后,计算每个 GPU 上单独计算 $sum(x)$ 和 $sum(x^2)$ 的梯度:$\frac{d_l}{d_{sum(x)_k}}$ 和 $\frac{d_l}{d_{sum(x^2)_k}}$;
接着,同步梯度(由 encoding.parallel.allreduce 自动处理),并继续 backward 计算.
具体 PyTorch 实现:Source code for encoding.nn.syncbn.
class SyncBatchNorm(_BatchNorm):
#Cross-GPU Synchronized Batch normalization (SyncBN)
def __init__(self,
num_features,
eps=1e-5,
momentum=0.1,
sync=True,
activation="none",
slope=0.01,
inplace=True):
super(SyncBatchNorm, self).__init__(num_features, eps=eps, momentum=momentum, affine=True)
self.activation = activation
self.inplace = False if activation == 'none' else inplace
#self.inplace = inplace
self.slope = slope
self.devices = list(range(torch.cuda.device_count()))
self.sync = sync if len(self.devices) > 1 else False
# Initialize queues
self.worker_ids = self.devices[1:]
self.master_queue = Queue(len(self.worker_ids))
self.worker_queues = [Queue(1) for _ in self.worker_ids]
# running_exs
#self.register_buffer('running_exs', torch.ones(num_features))
def forward(self, x):
# Resize the input to (B, C, -1).
input_shape = x.size()
x = x.view(input_shape[0], self.num_features, -1)
if x.get_device() == self.devices[0]:
# Master mode
extra = {
"is_master": True,
"master_queue": self.master_queue,
"worker_queues": self.worker_queues,
"worker_ids": self.worker_ids
}
else:
# Worker mode
extra = {
"is_master": False,
"master_queue": self.master_queue,
"worker_queue": self.worker_queues[self.worker_ids.index(x.get_device())]
}
if self.inplace:
return inp_syncbatchnorm(
x,
self.weight,
self.bias,
self.running_mean,
self.running_var,
extra,
self.sync,
self.training,
self.momentum,
self.eps,
self.activation,
self.slope).view(input_shape)
else:
return syncbatchnorm(
x,
self.weight,
self.bias,
self.running_mean,
self.running_var,
extra,
self.sync,
self.training,
self.momentum,
self.eps,
self.activation,
self.slope).view(input_shape)
def extra_repr(self):
if self.activation == 'none':
return 'sync={}'.format(self.sync)
else:
return 'sync={}, act={}, slope={}, inplace={}'.format(
self.sync, self.activation, self.slope, self.inplace
)使用示例:
m = SyncBatchNorm(100)
net = torch.nn.DataParallel(m)
output = net(input)