Incredibly, compared with DALL-E 2 and Imagen, the Stable Diffusion model is a lot smaller. While DALL-E 2 has around 3.5 Billion parameters, and Imagen has 4.6 Billion, the first Stable Diffusion model has just 890 million parameters, which means it uses a lot less VRAM and can actually be run on consumer-grade graphics cards.
For example, using Stable Diffusion v1-5 with a ControlNet checkpoint require roughly 700 million(7亿) more parameters compared to just using the original Stable Diffusion model, which makes ControlNet a bit more memory-expensive for inference. From: https://huggingface.co/blog/controlnet
Data Fabric (数据经纬), 可以用更通俗的语言来描述,那就是,”使需要用数据的人,随时能够了解到他要的数据在哪里,数据质量如何,他可以如何方便地获取他需要的数据。“ Data Fabric (数据经纬)的主要功能就是,把正确的数据,在正确的时间,传送给正确的人。通过 Data Fabric (数据经纬), 对的人可以从对的地点,在对的时间,获取对的数据。
to have and to hold from this day forward; for better for worse, for richer for poorer, in sickness and in health, to love and to cherish, till death do us part.
hardest: features and parameters of the model; most expensive: data collection, cleaning and labeling; most time consuming: multiple iterations in order to converge to the optimal parameters, testing & evaluation. -- Lason Demiros.
Docker 镜像:https://status.1panel.top/status/docker
Incredibly, compared with DALL-E 2 and Imagen, the Stable Diffusion model is a lot smaller. While DALL-E 2 has around 3.5 Billion parameters, and Imagen has 4.6 Billion, the first Stable Diffusion model has just 890 million parameters, which means it uses a lot less VRAM and can actually be run on consumer-grade graphics cards.
From: https://medium.com/nightcafe-creator/stable-diffusion-tutorial-how-to-use-stable-diffusion-157785632eb3
Stable Diffusion model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and can run on consumer GPUs.
From: https://huggingface.co/docs/diffusers/v0.5.1/en/api/pipelines/stable_diffusion
For example, using Stable Diffusion v1-5 with a ControlNet checkpoint require roughly 700 million(7亿) more parameters compared to just using the original Stable Diffusion model, which makes ControlNet a bit more memory-expensive for inference.
From: https://huggingface.co/blog/controlnet
花开时刻
从3D到2D的转换称为投影
REST vs GraphQL vs gRPC https://blog.bitsrc.io/rest-vs-graphql-vs-grpc-684edfacf810
AI 算法工程师手册,学习总结笔记 huaxiaozhuan.com
CPU Bound => Multi Processing
I/O Bound, Fast I/O, Limited Number of Connections => Multi Threading
I/O Bound, Slow I/O, Many connections => Asyncio
三维渲染是使用计算机从数字三维场景中生成二维影像的过程。
导数其实反映的是函数在某一点沿某一方向的变化率,而微分反映的是函数在某一点函数增量与所有自变量增量之间的关系。当函数为一元函数时,微分反映的就是函数增量与一个自变量增量之间的关系,也就是函数在该点沿某一方向的变化率,显然此时,可导与可微是等价的。但当函数为多元函数时,区别就非常明显了。
严格来说:“贴图”特指贴在模型表面的那些图片;“纹理”泛指物体表面,比如一个浮雕,是由凹凸不平的模型和其上的贴图组成的,纹理则指这一整体效果,大多数情况贴图和纹理是一个东西;材质则是指控制物体的各类属性(贴图效果参数、物理属性等)的脚本+贴图
小波变换(WT)是一种高效的图像表示,将图像信号分解为表示纹理细节的高频小波和包含全局拓扑信息的低频小波。
Data Fabric (数据经纬), 可以用更通俗的语言来描述,那就是,”使需要用数据的人,随时能够了解到他要的数据在哪里,数据质量如何,他可以如何方便地获取他需要的数据。“ Data Fabric (数据经纬)的主要功能就是,把正确的数据,在正确的时间,传送给正确的人。通过 Data Fabric (数据经纬), 对的人可以从对的地点,在对的时间,获取对的数据。
Data Fabric (数据经纬), Forrester写到:“Data Fabric (数据经纬)是以一种智能和安全的并且是自服务的方式,动态地协调分布式的数据源,跨数据平台地提供集成和可信赖的数据,支持广泛的不同应用的分析和使用场景”。
元宇宙像是一个筐,把增强现实、云计算、数字孪生、人工智能、区块链等数字技术打包全收,其中人工智能和元宇宙有着千丝万缕的关系,深度学习、计算机视觉、自然语言处理等人工智能技术的成熟应用是元宇宙落地的关键。
MPEG-7 Texture Descriptors
深度图像 = 普通的RGB三通道彩色图像 + Depth Map
在3D计算机图形中,Depth Map(深度图)是包含与视点的场景对象的表面的距离有关的信息的图像或图像通道。其中,Depth Map 类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素点之间具有一对一的对应关系。
向量化搜索: 人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。
这些向量如同数学空间中的坐标,标识着各个实体和实体关系。一般将非结构化数据变成向量的过程称为 Embedding,而非结构化检索则是对这些生成的向量进行检索,从而找到相应实体的过程。
删除所有已存在的字节码(.pyc)文件的方法: find . -type f -name "*.py[co]" -delete -or -type d -name "__pycache__" -delete
艺术、工程、科学
使用PNG24, 如果有大面积的渐变,即使色相差异不大,文件尺寸也会很大。如果还有丰富的色彩层次会更大。PNG无损压缩是通过索引色去存储和还原图像的,在存储图像前会先判断图像上哪些地方是相同的哪些地方是不同的,然后对图像上所有出现的颜色进行索引,这些颜色就是索引色。储存的索引色数量越多,文件尺寸越大。PNG8最多只能索引256种颜色,PNG24则可以保存1600多万种颜色,文件尺寸也会大很多。
PNG采用无损压缩,通过索引色去存储和还原图像,在存储图像前会先判断图像上哪些地方是相同的哪些地方是不同的,然后对图像上所有出现的颜色进行索引,这些颜色就是索引色。储存的索引色数量越多,文件尺寸越大.
PNG8最多只能索引256种颜色,PNG24则可以保存1600多万种颜色,但相应的文件尺寸也会大很多.
CNN和Transformer目前是CV任务主要流行的两种结构,这两个结构的主要不同是感知范围不一样:CNN的感受野受卷积核大小的限制,因此CNN的建模范围只能在一个卷积核的感受野之内;Transformer的Self-Attention是做全局信息的建模,因此Self-Attention的感知范围是整张图片
Django REST framework - https://www.django-rest-framework.org/
PNG采用无损压缩,通过索引色去存储和还原图像,在存储图像前会先判断图像上哪些地方是相同的哪些地方是不同的,然后对图像上所有出现的颜色进行索引,这些颜色就是索引色。储存的索引色数量越多,文件尺寸越大.
PNG8最多只能索引256种颜色,PNG24则可以保存1600多万种颜色,但相应的文件尺寸也会大很多.
Github 项目搜索 https://pythonrepo.com/
“All models are wrong, but some models that know when they are wrong, are useful.” — Balaji Lakshminarayanan (NeurIPS 2020)
KubeSphere 容器平台 https://kubesphere.io/zh/
文档 https://kubesphere.io/zh/docs/
深度学习现状 - by ShutterStock
大规模视觉搜索的七个技巧(Seven Tips for Visual Search at Scale),https://medium.com/gsi-technology/seven-tips-for-visual-search-at-scale-c61eacbf4f0f
队列模型提供高可靠、高并发的一对一消费模型,即队列中的每一条消息都只能够被某一个消费者消费。
队列就像一家旋转寿司店。寿司店中有多个寿司师傅(生产者)在制作精美的寿司,每一份寿司都是独特的,顾客(消费者)可以从传送带上拿取中意的寿司进行食用(消费)。
局部敏感哈希(LSH)的基本思想:
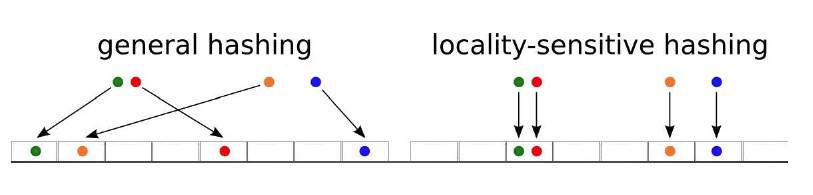
在高维数据空间中的两个相邻的数据被映射到低维数据空间中后,将会有很大的概率任然相邻;
而原本不相邻的两个数据,在低维空间中也将有很大的概率不相邻.
通过这样一映射,可以在低维数据空间来寻找相邻的数据点,避免在高维数据空间中寻找,因为在高维空间中会很耗时. 有这样性质的哈希映射称为是局部敏感的.
Web应用处理请求的具体流程:
[1]用户操作操作浏览器发送请求;[2]请求转发至对应的web服务器;[3] web服务器将请求转交给web应用程序,web应用程序处理请求;[4]web应用将请求结果返回给web服务器,由web服务器返回用户响应结果;[5]浏览器收到响应,向用户展示.
原因:
小图在左边,大图在右边时,相当于拿较少的特征点与较多的特征点进行匹配,得到的匹配数量最多为小图的特征点的数量;但是当拿较多的特征点与较少的特征点进行匹配时,得到的匹配数量最多为大图的特征点的数量,因为大图中可能多个特征点与小图中同一个特征点匹配上,从而造成两种情况下匹配结果的不同。
问题:
OpenCV中关于SIFT特征匹配的代码有一个缺点,就是当图片大小不一致时,匹配的结果也是不同的,比如说:当小图在左边,大图在右边的时候,匹配结果正确,但是当大图在左边,小图在右边的时候,就会出现很多误匹配的点。
相同图像像素级别完全相同,相似图片则分为两级,图像哈希对应整体相似,图像特征对应局部相似。
理解任何事物都需要先对它进行定义,这样才能够在头脑中清楚地知道正在讨论的是这个东西,而不是其他东西.
-- 经济学的思维方式 by Thomas Sowell
Building a Reverse Image Search with Elasticsearch
StyleGAN v2: notes on training and latent space exploration
PyQt5 - error "could not load Qt platform plugin xcb even though it was found"
pip install opencv-python opencv-python-headless
你可能不需要BERT-flow:一个线性变换媲美BERT-flow - 科学网
BERT-whitening/demo.py
人工智能有三要素:算法,计算力,数据。
计算力归根结底由底层芯片提供。按照计算芯片的组成方式,可以分成:
同构计算:使用相同类型指令集和体系架构的计算单元组成系统的计算方式。
异构计算:使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、GPU、ASIC、FPGA等。
markdown公式中字母加粗:$pmb{字母}$
京东星链零售物联平台:http://xinglian.jd.com/web/home
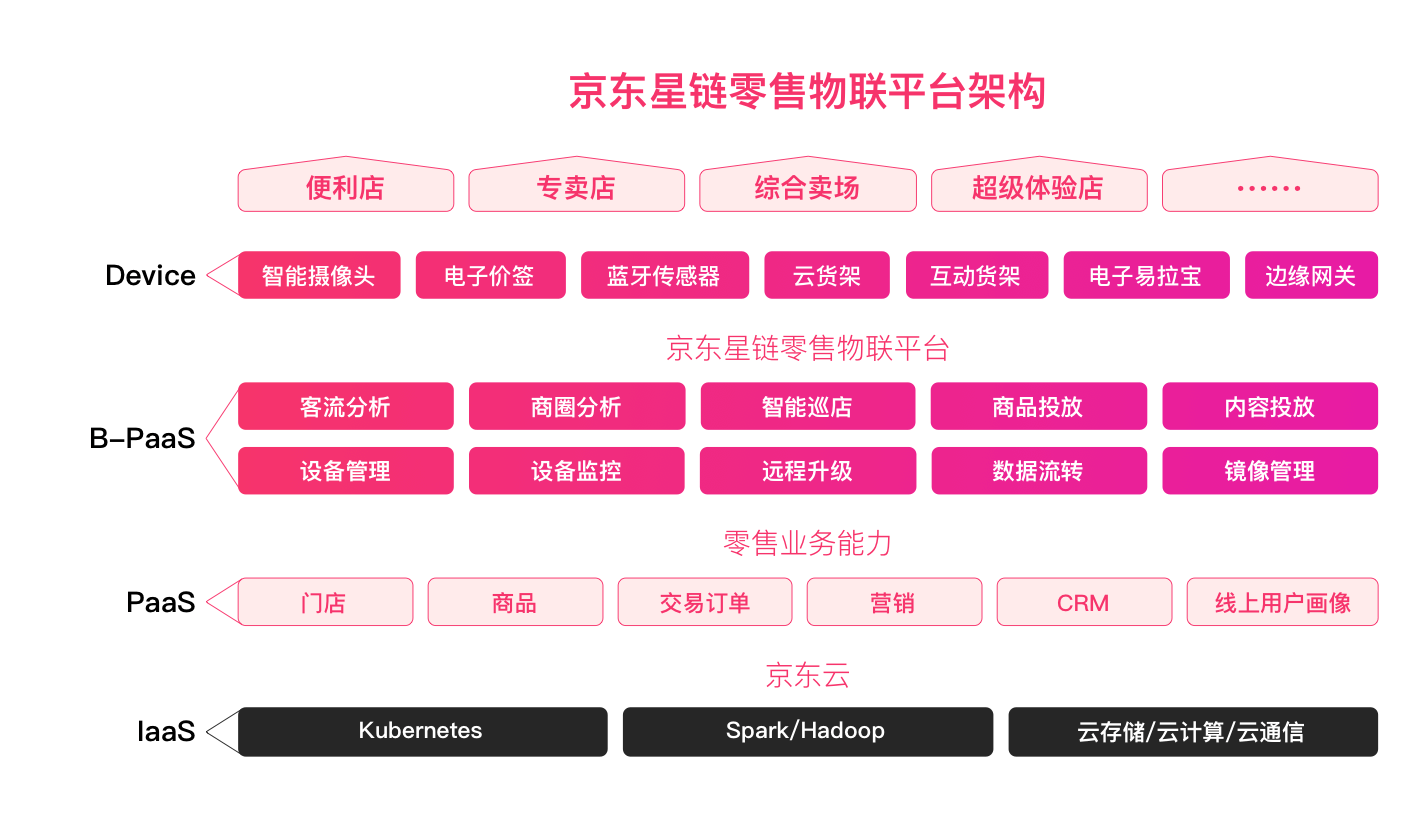
解决线下零售行业设备标准混乱、设备管理后台分散、设备数据缺失孤立等痛点,为数字化门店运营者、设备厂商、设备开发者提供的具备统一标准的、灵活的、安全可靠的设备连接通信能力,设备智能化管理、远程监控能力,以及设备数据灵活流转能力的智能平台,为线下各类零售场景赋能及行业开发者赋能。
以云货架和智能试衣镜为例,“顾客拿起了什么货、试了哪几件衣服,屏幕就能感知,并且把数据返回到后台,商家跟顾客购买数据一比对就知道哪些衣服没有被买走,经常被拿起但不被买走,说明这个东西是有需求的,但是总有哪里不对,商家就可以针对性地让营业员去做一些用户调研,或者调整产品”。
StyleGAN Pretrained 应用:

https://github.com/justinpinkney/awesome-pretrained-stylegan
Intel IoT
https://github.com/intel-iot-devkit
https://github.com/intel-iot-devkit/smart-retail-analytics
图像标注工具:https://rachelcao277.github.io/LabelImage/
2020 再见,2021 启程!
移除已存在的CUDA PPA源: sudo rm /etc/apt/sources.list.d/cuda*
信息是无边界的,但知识是有边界的.(知识图谱)
字典根据 value 排序:datas = sorted(datas_dict.items(), key=lambda d:d[1], reverse = True)
百度图说 https://tushuo.baidu.com/ , 数据可视化工具
用户或者产品经理的需求零零散散,不断变更。工程师在各处代码中寻找可以实现这些需求变更的代码,修修补补。软件只有需求分析,并没有真正的设计,系统没有一个统一的领域模型维持其内在的逻辑一致性。功能特性并不是按照领域模型内在的逻辑设计,而是按照各色人等自己的主观想象设计。项目时间一长,各种困难重重,需求不断延期,线上 bug 不断,管理者考虑是不是要推到重来,而程序员则考虑是不是要跑路。
如果对自己要开发的业务领域没有清晰的定义和边界,没有设计系统的领域模型,而仅仅跟着所谓的需求不断开发功能,一旦需求来自多个方面,就可能发生需求冲突,或者随着时间的推移,前后功能也会发生冲突,这时越是试图弥补这些冲突,就越是陷入更大的冲突之中。
elvis:
大多机器学习书和课教的: [1] - 加载干净数据; [2] - 训练MNIST-分类器,准确率达到99%
实际最需要教的:[1] - 处理、清洗、加载自己的数据; [2] - 面对频繁的实验失败,研究/发现/理解改进机器学习模型的方法.
油管视频下载工具 https://www.4kvideodownloader.com/
LVW水印图像数据集下载:https://pan.baidu.com/s/1c3MuJ90jVcKJm2Gp-wwzNQ
Ubuntu16.04 unity-panel-service 内存占用多的临时处理方案:restart unity-panel-service
我愿与君依守,
无惧祸福贫富,
无惧疾病健康,
只惧爱君不能足。
既为君妇,
此身可死,
此心不绝!
to have and to hold from this day forward;
for better for worse,
for richer for poorer,
in sickness and in health,
to love and to cherish,
till death do us part.
DAWNBench - An End-to-End Deep Learning Benchmark and Competition 公开数据集上GPU模型训练和推断测试.
https://dawn.cs.stanford.edu/benchmark/index.html
生命太脆弱,明天和意外,永远不知道哪个会先来.
珍惜现在,活在当下.
无论经历了什么挫折和失败,活着才有希望和未来.
恩师走好!
君闲天涯苍山幽,
人卧江暮一梦秋。
登山路遥愁更远,
遥望千峰烟云流。
溪涧草长闻啼声,
深林空谷鸟自由。
月下心事空自忆,
远怀惆怅风不休。
hello!
Python lambda 函数语法:lambda argument_list: expression
人脸生成 https://thispersondoesnotexist.com/
一个知识越贫乏的人,越是拥有一种莫名奇怪的勇气和自豪感,因为知识越贫乏,你所相信的东西就越绝对,你根本没有听过与此相对立的观点.
Ubuntu 修改 XmindZen 试用时长:
1.打开XmindZen,新建一个思维导图;
2.修改 ~/.config/XMind ZEN/Electron v3/vana/state/activation.json 文件,如{"trialStartTime":1}.
有前程可奔赴,有岁月可回首
PS复杂背景抠图
强制单核运行脚本,如:OMP_NUM_THREADS=1 python3 test.py
AI 工业自动化应用
FashionAI归纳了一整套理解时尚、理解美的方法论,通过机器学习与图像识别技术,它把复杂的时尚元素、时尚流派进行了拆解、分类、学习. 2017年,他们学习了50万套来自淘宝达人的时尚穿搭. 不停的学习、的辨别、搭配. 以袖口部位为例,FashionAI共计拆出了袖形袖口、袖肩、设计手法等4个维度、24个设计标签.
FashionAI的背后是一套完整的,用算法读懂时尚的方法论. 尽管时尚看起来庞杂且主观,但当算法不断庖丁解牛后,依然可以清晰找到服饰认知体系的框架. FashionAI就是这样,它把抽像的美学变为可重复的方法论,然后再重新建构,进而理解时尚穿搭之道,理解流行风向.
查看Linux机器显卡信息:lspci |grep VGA
最近比较忙,真是凌乱了一地
Ubuntu 网卡设置:sudo ifconfig eno2 192.168.100.98 netmask 255.255.255.0
人工智能落地的五要素:算法,算力,算据(数据),算景(场景),算者(人) —— 马少平THU
计算字符串 md5:hashlib.md5(a.encode('utf-8')).hexdigest()
不管前方的路有多苦,只要走的方向正确,不管多么崎岖不平,都比站在原地更接近幸福 - 千与千寻
七月了,年中,继续going,my love,my dear,love you so much.
CVPR2019 论文列表:https://mattdeitke.github.io/CVPR-2019/
下载 get-pip.py: https://bootstrap.pypa.io/get-pip.py;
安装 pip: sudo python get-pip.py
千亿像素看中国:http://www.bigpixel.cn/
Django 问题:OperationalError no such table
python manage.py makemigrations
python manage.py migrate
Markdown 是个好工具,图片是个大问题. 免费的确实是最贵的,403 的微博图片...
投诉运营商:www.chinatcc.gov.cn
投诉快递:sswz.spb.gov.cn
投诉电商:www.sgs.gov.cn/shaic/12315/zxtsjb.htm
表是MaxCompute的数据存储单元,它在逻辑上也是由行和列组成的二维结构,每行代表一条记录,每列表示相同数据类型的一个字段,一条记录可以包含一个或多个列,各个列的名称和类型构成这张表的Schema。
又在折腾图片图床了,只能先放到 1M 的云服务器上了,顺便研究了下图片压缩,尽量将图片压缩小一点,减少点带宽影响,后面再慢慢想办法解决 markdown 图片问题.
图片用新浪微博图床的不可靠性显现了,开始有些图莫名其妙的加载不出来了,好坑,要想办法替换掉了
被一个表情搞的 Typecho 出现了 Database Query Error 问题
新的一年,开工!
GluonCV: a Deep Learning Toolkit for Computer Vision - https://gluon-cv.mxnet.io/
移动宽带好扯,已经一段时间都不能上 Github,速度特烂,挂 VPN 也打不开,但是可以 git clone,真是坑.
突然发现收藏了很多博文,需要整理下清除部分了,记录备忘到这里. 年前结束.
你好,2019.
谢谢,2018.
作为开发人员,工作不是关于写了多少代码,而是关于如何有效地解决了问题. 最好的代码是不用亲自编写和维护的代码——因为用的是现成的解决方案,或者因为选择了涉及较少子问题的解决方案.
hardest: features and parameters of the model;
most expensive: data collection, cleaning and labeling;
most time consuming: multiple iterations in order to converge to the optimal parameters, testing & evaluation.
-- Lason Demiros.
机器学习什么环节最难、最费钱、最费时?
最难:模型特性和参数;
最费钱:数据收集、清洗和标注(往往也是决定项目成功的最重要因素);
最费时:多轮迭代参数调优、测试与评价.
UGC(User Generated Content)指用户原创内容,是伴随着以提倡个性化为主要特点的Web2.0概念而兴起的. 它并不是某一种具体的业务,而是一种用户使用互联网的新方式,即由原来的以下载为主变成下载和上传并重.
随着互联网运用的发展,网络用户的交互作用得以体现,用户既是网络内容的浏览者,也是网络内容的创造者. - From 百度百科
PGC(Professional Generated Content)指专业生产内容(视频网站)、专家生产内容(微博). 用来泛指内容个性化、视角多元化、传播民主化、社会关系虚拟化. 也称为PPC(Professionally-produced Content). - From 百度百科
联发科P90 - AI 实时多人姿态识别
极简图床,上传到微博图床是好用,但最近遇到的崩溃情况好几次了,上传不了. 自建的基于 ImgURL 的图床,因为 1M 带宽,速度不给力. 靠谱图床在哪里......
Ubuntu 系统查看 opencv 的版本 - pkg-config --modversion opencv
FLOPS,Floating Point Operations Per Second,每秒所能够进行的浮点运算数,用来描述 GPU 性能的标准.
今天才发现,11.22日应该有人在某个文章打赏了 2.0 元耶,感谢感谢. 也才知道原来 handsome 这个 typecho 主题集成的好多功能,厉害!访问到博文的各位,博文多是记录备忘和学习,欢迎互相交流学习,如有错误,请一定指出哈。感谢.
森系,最早来自于森林系女孩,是一种时尚潮流,也是一直比较拥抱大自然的态度,即清新、自然、超凡脱俗,背着有如走出森林般的感觉.
森系所代表的生活态度便是,崇尚自然、舒适、返璞归真;生活态度随遇而安;热爱流浪;排斥消费主义;追求简单、直接的处世态度.
森系,一种服饰风格,多带有碎花,田园等花朵为元素,百褶裙,淡色系便是其小清新的代表.
bug bug 满天飞
浏览器收藏栏的很多博文都已 404,看来还是要随时记录备份了. 一定明确标识原文出处,以免侵犯了别人版权.
安装 PyTorch Preview 一定要先确认下 echo $LD_LIBRARY_PATH 啊,输出 /usr/local/cuda-9.0/lib64: 才行,要不然 import torch 的时候出错 libtorch.so.1: undefined symbol,坑了好几天.
飞 —《飞狐外传》清乾隆
雪 —《雪山飞狐》清乾隆
连 —《连城诀》晚清
天 —《天龙八部》北宋后期
射 —《射雕英雄传》南宋
白 —《白马啸西风》清朝
鹿 —《鹿鼎记》清康熙
笑 —《笑傲江湖》明中
书 —《书剑恩仇录》清乾隆
神 —《神雕侠侣》南宋末
侠 —《侠客行》明中
倚 —《倚天屠龙记》元末
碧 —《碧血剑》明末
鸳 —《鸳鸯刀》清朝
论脑子如何更好使
两个 Git 可视化管理工具:Git GUI for Windows, Mac & Linux | GitKraken 和 Sourcetree | Free Git GUI for Mac and Windows
第一次被 CSDN 删除了一篇博文记录.
十来天,就会手生.
博客由 WordPress 迁移到了 Typecho,WordPress 后台有点驾驭不了,囧