
腾讯开源的多标签数据集,主要包括两部分:
[1] - ML-Images - 最大的开源多标签图s片数据集,包括 17,609,752 张训练图片URLs,88, 739 张验证图片URLs,共标注了多达 11,166 个类别标签.
[2] - Resnet-101 模型 - 基于 ML-Images 的预训练模型,通过迁移学习,其在 ImageNet上的 top-1 准确率为 80.73% .
依赖环境:
- Linux
- Python2.7
- Tensorflow >= 1.6.0
1. 数据集
图片 URLs 和对应的标注标签,数据集下载:
- train_urls.txt - 下载地址1 - GoogleDrive, 下载地址2 - 百度网盘
- var_urls.txt - 下载地址1 - GoogleDrive,下载地址2 - 百度网盘
train_urls.txt 的内容格式:
...
https://c4.staticflickr.com/8/7239/6997334729_e5fb3938b1_o.jpg 3:1 5193:0.9 5851:0.9 9413:1 9416:1
https://farm8.staticflickr.com/3796/19447434033_7820f80b7b_o.jpg 9290:0.8 1043:0.8
https://c7.staticflickr.com/1/42/74229536_063452179d_o.jpg 9416:1.0 9413:1.0 3:1.0
https://farm7.staticflickr.com/2378/2572916531_38735defe1_o.jpg 4063:0.9 1837:0.9 4132:1 4097:1 4089:1 1054:1 1041:1 865:1 2:1
...每一行对应一张图片及其标注. 第一项为图片 URL,其后是由空格分割的标注标签. 例如,5193:0.9 表示类别索引5193及其置信度0.9.
类别索引由 0 开始计数,具体类别名可见:data/dictionary_and_semantic_hierarchy.txt.
1.1 图片源
ML-Images 中的图片 URLs 是根据 ImageNet 和 Open Images 收集而来的.
具体地,
[1] - Part 1 - 基于 ImageNet 整个数据库,采用了 10,706,941 张训练图片URLs 和 50,000 张验证图片 URLs,覆盖了 10, 032 个类别.
[2] - Part 2 - 基于 OpenImages 数据集,采用了额 6,902,811 张训练图片 URLs 和 38,739 张验证图片 URLs,覆盖了 1,134 个独立的类别(有些类别与 ImageNet 相似类进行了合并).
1.2 语义层次
根据 WordNet 对数据集的 11,166 个类别建立了语义层次.
每个类别的直接父类可以参见 data/dictionary_and_semantic_hierarchy.txt.
整个语义层次包含 4 个独立的树,其根节点分别为 thing, matter, object, physical objectand 和 atmospheric phenomenon. 从根节点到叶节点的最长语义路径的长度为 16,平均长度为 7.47.
1.3 标注
由于 ML-Images 中的图片 URLs 是根据 ImageNet 和 Open Images 收集而来的,因此,标注也是基于 ImageNet 和 OpenImages 的原始标注的.
具体地,
[1] - 对于 OpenImages 的 6,902,811 张训练图片URLs,移除不在保留的 1,134 个类别中的其它标注标签tags.
[2] - 根据构建的 11,166 个类别的语义层次,对 ML-Images 所有图片 URLs 进行了增强标注,即,如果一个 URL 被标注为类别 i,则其父类(ancestor categories) 也都被标注到该 URL.
[3] - 基于 OpenImages 的 6,902,811 张训练图片URLs 训练 ResNet-101 模型,输出为 1,134 个类别. 基于该 ResNet-101 模型,对 ImageNet 的10,756,941 个单标注的图片进行预测,得到其在 1,134 个类别的标签. 然后,得到 ImageNet 的 10,032 个类别和 OpenImages 的 1,134 个类别之间的归一化共存矩阵(normalized co-occurrence matrix). 例如,如果类别 i 和类别 j 是强共存的,则,如果一张图片被标注为类别 i,则类别 j 也应该被标注.
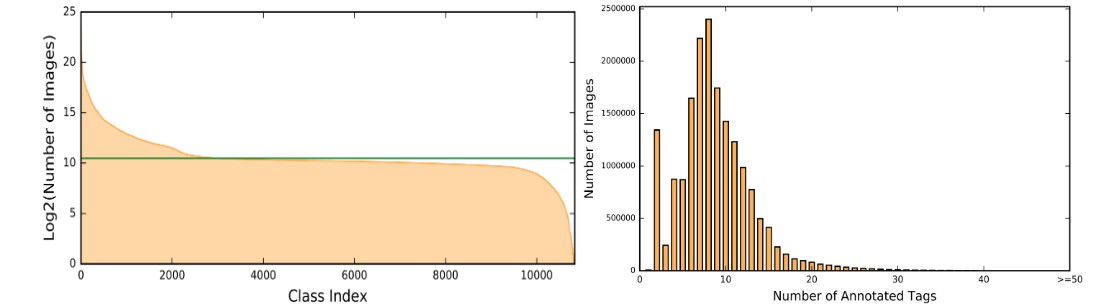
1.4 统计
| # 训练图片 | # 验证图片 | # 类别 | # 训练类别 | # 平均每张图片的标签数 | # 平均每个类别的图片数 |
|---|---|---|---|---|---|
| 17,609,752 | 88,739 | 11,166 | 10,505 | 8 | 1447.2 |
每个类别的图片数和训练集中标注数的直方图,如图:
2. 数据集多线程下载
下载测试的 tiny 数据集:train_urls_tiny.txt
cd data
./download_urls_multithreading.shdownload_urls_multithreading.sh:
python2.7 ./download_urls_multithreading.py
--url_list=train_urls_tiny.txt
--im_list=train_im_list_tiny.txt
--num_threads=20 --save_dir='./images'download_urls_multithreading.py :
#!/usr/bin/env python
import os
import urllib
import argparse
import threading,signal
import time
import socket
socket.setdefaulttimeout(10.0)
def downloadImg(start, end, url_list, save_dir):
global record,count,count_invalid,is_exit
im_names = []
with open(url_list, 'r') as url_f:
for line in url_f.readlines()[start:end]:
sp = line.rstrip('\n').split('\t')
url = sp[0]
im_name = url.split('/')[-1]
try:
urllib.urlretrieve(url, os.path.join(save_dir, im_name))
record += 1
im_file_Record.write(im_name + '\t' + '\t'.join(sp[1:]) + '\n')
print('url = {} is finished and {} imgs have been '
'downloaded of all {} imgs'.format(url, record, count))
except IOError as e:
print ("The url:{} is ***INVALID***".format(url))
invalid_file.write(url + '\n')
count_invalid += 1
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--url_list', type=str, help='the url list file')
parser.add_argument('--im_list', type=str,
default='img.txt',help='the image list file')
parser.add_argument('--num_threads', type=int,
default=8, help='the num of processing')
parser.add_argument('--save_dir', type=str,
default='./images', help='the directory to save images')
args = parser.parse_args()
url_list = args.url_list
im_list = args.im_list
num_threads = args.num_threads
save_dir = args.save_dir
# create savedir
if not os.path.isdir(save_dir):
os.mkdir(save_dir)
count = 0 # 图片 urls 数量
count_invalid = 0 # 无效的图片 urls 数量
record = 0
with open(url_list,'r') as f:
for line in f:
count += 1
part = int(count/num_threads)
with open(im_list, 'w') as im_file_Record,open('invalid_url.txt','w') as invalid_file:
# 记录下载的 imgs
thread_list = []
for i in range(num_threads):
if(i == num_threads-1):
t = threading.Thread(target = downloadImg,
kwargs={'start':i*part,
'end':count,
'url_list':url_list,
'save_dir':save_dir})
else:
t = threading.Thread(target = downloadImg,
kwargs={'start':i*part,
'end':(i+1)*part,
'url_list':url_list,
'save_dir':save_dir})
t.setDaemon(True)
# Thread.setDaemon(true)设置为守护线程
# Thread.setDaemon(false)设置为用户线程
thread_list.append(t)
t.start()
for i in range(num_threads):
try:
while thread_list[i].isAlive():
pass
except KeyboardInterrupt:
break
if count_invalid==0:
print ("all {} imgs have been downloaded!".format(count))
else:
print("{}/{} imgs have been downloaded, {} URLs are invalid".
format(count-count_invalid, count, count_invalid))
3. 数据集转换为 TFRecord 文件
采用多线程模块生成 tfrecords. 需要首先将 train_im_list_tiny.txt 分为多个小文件,然后保存到子目录 data/images_lists/, 如 data/images_list/train_im_list_tiny_1.txt 和 data/images_list/train_im_list_tiny_2.txt.
生成的多个 tfrecords 保存在 data/tfrecords/x.tfrecords.
cd data
./tfrecord.shtfrecord.sh:
echo "Generating tfrecords ..."
./tfrecord.py -idx image_lists/
-tfs tfrecords/
-im images/
-cls 11166
-one Truetfrecord.py:
#!/usr/bin/python
import sys
import os
import tensorflow as tf
import numpy as np
import imghdr
import threading
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-idx","--indexs", type=str, default="",
help="dirs contains train index files")
parser.add_argument("-tfs", "--tfrecords", type=str, default="",
help="dirs contains train tfrecords")
parser.add_argument("-im", "--images", type=str, default="",
help="the path contains the raw images")
parser.add_argument("-cls", "--num_class", type=int, default=0,
help="class label number")
parser.add_argument("-one", "--one_hot", type=bool, default=True,
help="indicates the format of label fields in tfrecords")
parser.add_argument("-sidx", "--start_index", type=int, default=0,
help="the start number of train tfrecord files")
args = parser.parse_args()
def _int64_feature(value):
"""
Wrapper,用于插入 int64 特征到 Example proto.
"""
if not isinstance(value, list):
value = [value]
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def _float_feature(value):
"""
Wrapper,用于插入 float 特征到 Example proto.
"""
if not isinstance(value, list):
value = [value]
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def _bytes_feature(value):
"""
Wrapper,用于插入 bytes 特征到 Example proto.
"""
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
class ImageCoder(object):
"""
TF 图像编码的辅助函数类.
"""
def __init__(self):
# 创建单个会话(Session),以运行所有的图片编码调用.
self._sess = tf.Session()
# 初始化函数,用于转换 PNG 到 JPEG 数据.
self._png_data = tf.placeholder(dtype=tf.string)
image = tf.image.decode_png(self._png_data, channels=3)
self._png_to_jpeg = tf.image.encode_jpeg(image, format='rgb', quality=100)
# 初始化函数,用于解码 RGB JPEG 数据.
self._decode_jpeg_data = tf.placeholder(dtype=tf.string)
self._decode_jpeg = tf.image.decode_jpeg(self._decode_jpeg_data, channels=3)
def png_to_jpeg(self, image_data):
return self._sess.run(self._png_to_jpeg,
feed_dict={self._png_data: image_data})
def decode_jpeg(self, image_data):
image = self._sess.run(self._decode_jpeg,
feed_dict={self._decode_jpeg_data: image_data})
assert len(image.shape) == 3
assert image.shape[2] == 3
return image
def _is_png(filename):
return (imghdr.what(filename)=='png')
def _is_jpeg(filename):
return (imghdr.what(filename)=='jpeg')
def _process_image(filename, coder):
"""
单个图像文件处理.
"""
with tf.gfile.FastGFile(filename, 'rb') as f:
image_data = f.read()
if not _is_jpeg(filename):
if _is_png(filename):
print('Converting PNG to JPEG for %s' % filename)
image_data = coder.png_to_jpeg(image_data)
else:
try:
image = coder.decode_jpeg(image_data)
assert len(image.shape) == 3
height = image.shape[0]
width = image.shape[1]
assert image.shape[2] == 3
return image_data, height, width
except:
print('Cannot converted type %s' % imghdr.what(filename))
return [], 0, 0
image = coder.decode_jpeg(image_data)
assert len(image.shape) == 3
height = image.shape[0]
width = image.shape[1]
assert image.shape[2] == 3
return image_data, height, width
def _save_one(train_txt, tfrecord_name, label_num, one_hot):
writer = tf.python_io.TFRecordWriter(tfrecord_name)
with tf.Session() as sess:
coder = ImageCoder()
with open(train_txt, 'r') as lines:
for line in lines:
sp = line.rstrip("\n").split()
imgf = os.path.join(args.images, sp[0])
print(imgf)
img, height, width = _process_image(imgf, coder)
if height*width==0:
continue
if one_hot:
label = np.zeros([label_num,], dtype=np.float32)
for i in range(1, len(sp)):
if len(sp[i].split(":"))==2:
label[int(sp[i].split(":")[0])] = float(sp[i].split(":")[1])
else:
label[int(sp[i].split(":")[0])] = 1.0
example = tf.train.Example(features=tf.train.Features(feature={
'width': _int64_feature(width),
'height': _int64_feature(height),
'image': _bytes_feature(tf.compat.as_bytes(img)),
'label': _bytes_feature(tf.compat.as_bytes(label.tostring())),
'name': _bytes_feature(sp[0])
}))
writer.write(example.SerializeToString())
else:
label = int(sp[1])
example = tf.train.Example(features=tf.train.Features(feature={
'width': _int64_feature(width),
'height': _int64_feature(height),
'image': _bytes_feature(tf.compat.as_bytes(img)),
'label': _int64_feature(label),
'name': _bytes_feature(sp[0])
}))
writer.write(example.SerializeToString())
writer.close()
def _save():
files = os.listdir(args.indexs)
coord = tf.train.Coordinator()
threads = []
i = args.start_index
for idxf in files:
threads.append(
threading.Thread(target=_save_one,
args=(os.path.join(args.indexs, idxf),
os.path.join(args.tfrecords, str(i) + ".tfrecords"),
args.num_class, args.one_hot)
)
)
i = i+1
i=0
thread = []
for t in threads:
if i==32:
for ct in thread:
ct.start()
coord.join(thread)
i = 0
thread = [t]
else:
thread.append(t)
i += 1
for ct in thread:
ct.start()
coord.join(thread)
if __name__=='__main__':
_save()
4. 训练/Finetune/分类/特征提取
TFRecords 文件处理完以后即可进行训练,源码中给出了基于 ResNet101 的模型训练与 Finetune,训练好的 ResNet101 模型,单标签图像分类,特征提取.
4.1 ResNet101 训练/Finetune
./example/train.sh注:这里提供的训练代码是单节点单 GPU 的.
[ImageNet PreTrained ResNet101 模型]()
./example/finetune.sh4.2 ResNet101 模型断点
[1] - ckpt-resnet101-mlimages - 下载地址1:GoogleDrive 下载地址2:百度网盘 - 在 ML-Images 数据训练的模型
[2] - ckpt-resnet101-mlimages-imagenet - 下载地址1:GoogleDrive 下载地址2:百度网盘 - 在 ML-Images 数据集预训练,并在 ImageNet(ILSVRC2012) 数据集 Finetune 的模型.
4.3 单标签图像分类
基于 ckpt-resnet101-mlimages-imagenet 模型,
./example/image_classification.sh./example/image_classification.sh:
python2.7 image_classification.py \
--images=data/im_list_for_classification.txt \
--top_k_pred=5 \
--model_dir=checkpoints/resnet.ckpt \
--dictionary=data/imagenet2012_dictionary.txtimage_classification.py:
#!/usr/bin/python
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import sys
import numpy as np
import cv2 as cv
import tensorflow as tf
from models import resnet as resnet
from flags import FLAGS
"""
采用保存的断点模型,进行单标签(single-label)图像分类.
"""
tf.app.flags.DEFINE_string("result", "label_pred.txt",
"file name to save predictions")
tf.app.flags.DEFINE_string("images", "",
"contains image path per line per image")
tf.app.flags.DEFINE_integer("top_k_pred", 5,
"the top-k predictions")
tf.app.flags.DEFINE_string("dictionary", "",
"the class dictionary of imagenet-2012")
def _load_dictionary(dict_file):
dictionary = dict()
with open(dict_file, 'r') as lines:
for line in lines:
sp = line.rstrip('\n').split('\t')
idx, name = sp[0], sp[1]
dictionary[idx] = name
return dictionary
def preprocess(img):
rawH = float(img.shape[0])
rawW = float(img.shape[1])
newH = 256.0
newW = 256.0
test_crop = 224.0
if rawH <= rawW:
newW = (rawW/rawH) * newH
else:
newH = (rawH/rawW) * newW
img = cv.resize(img, (int(newW), int(newH)))
img = img[int((newH-test_crop)/2):int((newH-test_crop)/2)+int(test_crop),
int((newW-test_crop)/2):int((newW-test_crop)/2)+int(test_crop)]
img = ((img/255.0) - 0.5) * 2.0
img = img[...,::-1]
return img
# build model
images = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3])
net = resnet.ResNet(images, is_training=False)
net.build_model()
logit = net.logit
prob = tf.nn.softmax(logit)
prob_topk, pred_topk = tf.nn.top_k(prob, k=FLAGS.top_k_pred)
# restore model
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(FLAGS.visiable_gpu)
config.log_device_placement=False
sess = tf.Session(config=config)
saver = tf.train.Saver(tf.global_variables())
saver.restore(sess, FLAGS.model_dir)
dictionary = _load_dictionary(FLAGS.dictionary)
# inference
types= 'center'#'10crop'
orig_stdout = sys.stdout
f = open(FLAGS.result, 'w')
sys.stdout = f
with open(FLAGS.images, 'r') as lines:
for line in lines:
sp = line.rstrip('\n').split('\t')
raw_img = cv.imread(sp[0])
if type(raw_img)==None or raw_img.data==None :
print("open pic " + sp[0] + " failed")
continue
#imgs = preprocess(raw_img, types)
img = preprocess(raw_img)
logits, probs_topk, preds_topk = sess.run([logit, prob_topk, pred_topk],
{images:np.expand_dims(img, axis=0)}
)
probs_topk = np.squeeze(probs_topk)
preds_topk = np.squeeze(preds_topk)
names_topk = [dictionary[str(i)] for i in preds_topk]
print('+++ the predictions of {} is:'.format(sp[0]))
for i, pred in enumerate(preds_topk):
print('%d %s: %.3f' % (pred, names_topk[i], probs_topk[i]))
sys.stdout = orig_stdout
f.close()
4.4 特征提取
./example/extract_feature.sh./example/extract_feature.sh:
#!/usr/bin/bash
set -x
PYTHON=/path/to/you/python
RESNET=101
DATA_FORMAT='NCHW'
GPUID=0
CKPT="./ckpts"
$PYTHON extract_feature.py --resnet_size=$RESNET \
--data_format=$DATA_FORMAT \
--visiable_gpu=${GPUID} \
--pretrain_ckpt=$CKPT \
--result=test.txt \
--images=imglist.txt extract_feature.sh.py:
#!/usr/bin/python
"""
采用预训练的模型提取图像特征
Use pre-trained model extract image feature
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import sys
import numpy as np
import cv2 as cv
import tensorflow as tf
from models import resnet as resnet
from flags import FLAGS
tf.app.flags.DEFINE_string("result", "",
"file name to save features")
tf.app.flags.DEFINE_string("images", "",
"contains image path per line per image")
"""Crop Image To 224*224
Args:
img: an 3-D numpy array (H,W,C)
type: crop method support [ center | 10crop ]
"""
def preprocess(img, type="center"):
# resize image with smallest side to be 256
rawH = float(img.shape[0])
rawW = float(img.shape[1])
newH = 256.0
newW = 256.0
if rawH <= rawW:
newW = (rawW/rawH) * newH
else:
newH = (rawH/rawW) * newW
img = cv.resize(img, (int(newW), int(newH)))
imgs = None
if type=='center':
imgs = np.zeros((1, 224, 224, 3))
imgs[0,...] = img[int((newH-224)/2):int((newH-224)/2)+224,
int((newW-224)/2):int((newW-224)/2)+224]
elif type=='10crop':
imgs = np.zeros((10, 224, 224, 3))
offset = [(0, 0),
(0, int(newW-224)),
(int(newH-224), 0),
(int(newH-224), int(newW-224)),
(int((newH-224)/2), int((newW-224)/2))]
for i in range(0, 5):
imgs[i,...] = img[offset[i][0]:offset[i][0]+224,
offset[i][1]:offset[i][1]+224]
img = cv.flip(img, 1)
for i in range(0, 5):
imgs[i+5,...] = img[offset[i][0]:offset[i][0]+224,
offset[i][1]:offset[i][1]+224]
else:
raise ValueError("Type not support")
imgs = ((imgs/255.0) - 0.5) * 2.0
imgs = imgs[...,::-1]
return imgs
# build model
images = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3])
net = resnet.ResNet(images, is_training=False)
net.build_model()
logits = net.logit
feat = net.feat
# restore model
saver = tf.train.Saver(tf.global_variables())
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(FLAGS.visiable_gpu)
config.log_device_placement=False
sess = tf.Session(config=config)
# load trained model
saver.restore(sess, FLAGS.pretrain_ckpt)
# inference on net
types='center'
ffeat = open(FLAGS.result, 'w')
with open(FLAGS.images, 'r') as lines:
for line in lines:
sp = line.rstrip('\n').split(' ')
raw_img = cv.imread(sp[0])
if type(raw_img)==None or raw_img.data==None :
print("open pic " + sp[0] + " failed")
continue
imgs = preprocess(raw_img, types)
feats = sess.run(feat, {images:imgs})
feats = np.squeeze(feats[0])
if types=='10crop':
feats = np.mean(feats, axis=0)
print('feature-length:{}, feature={}'.format(len(feats), feats))
ffeat.write(sp[0] + "\t" + sp[1] + "\t" + " ".
join([str(x) for x in list(feats)]) + '\n')
ffeat.close()5. Results
不同的 ResNet101 模型在 ImageNet(ILSVRC2012) 验证数据集上的结果如下:
| Checkpoints | Train and finetune setting | Top-1 acc on Val 224 | Top-5 acc on Val 224 | Top-1 acc on Val 299 | Top-5 accuracy on Val 299 |
|---|---|---|---|---|---|
| MSRA ResNet-101 | train on ImageNet | 76.4 | 92.9 | -- | -- |
| Google ResNet-101 ckpt1 | train on ImageNet, 299 x 299 | -- | -- | 77.5 | 93.9 |
| Our ResNet-101 ckpt1 | train on ImageNet | 77.8 | 93.9 | 79.0 | 94.5 |
| Google ResNet-101 ckpt2 | Pretrain on JFT-300M, finetune on ImageNet, 299 x 299 | -- | -- | 79.2 | 94.7 |
| Our ResNet-101 ckpt2 | Pretrain on ML-Images, finetune on ImageNet | 78.8 | 94.5 | 79.5 | 94.9 |
| Our ResNet-101 ckpt3 | Pretrain on ML-Images, finetune on ImageNet 224 to 299 | 78.3 | 94.2 | 80.73 | 95.5 |
| Our ResNet-101 ckpt4 | Pretrain on ML-Images, finetune on ImageNet 299 x 299 | 75.8 | 92.7 | 79.6 | 94.6 |
注:
[1] - 如果没有说明,则默认训练时图像尺寸为 224x224.
[2] - 在 ImageNet 由 224 到 299 进行 finetune,表示在靠前的 epochs 的 finetune 采用 224x224,然后在后面的 epochs 采用 299x299.
[3] - Top-1 acc on Val 224 表示是 224x2224 验证图片数据集的 top-1 准确率.