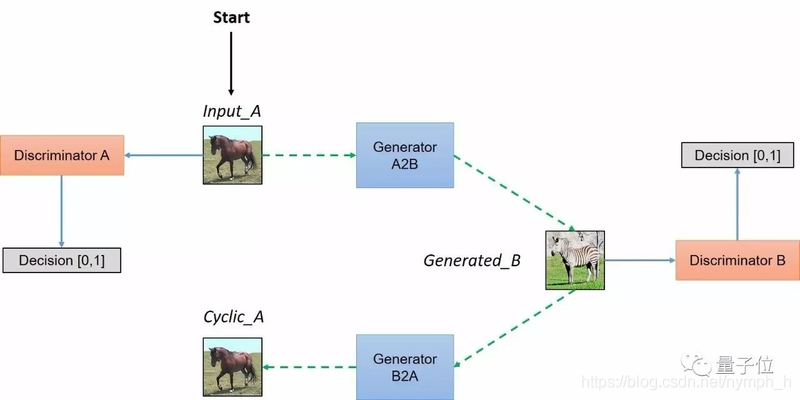
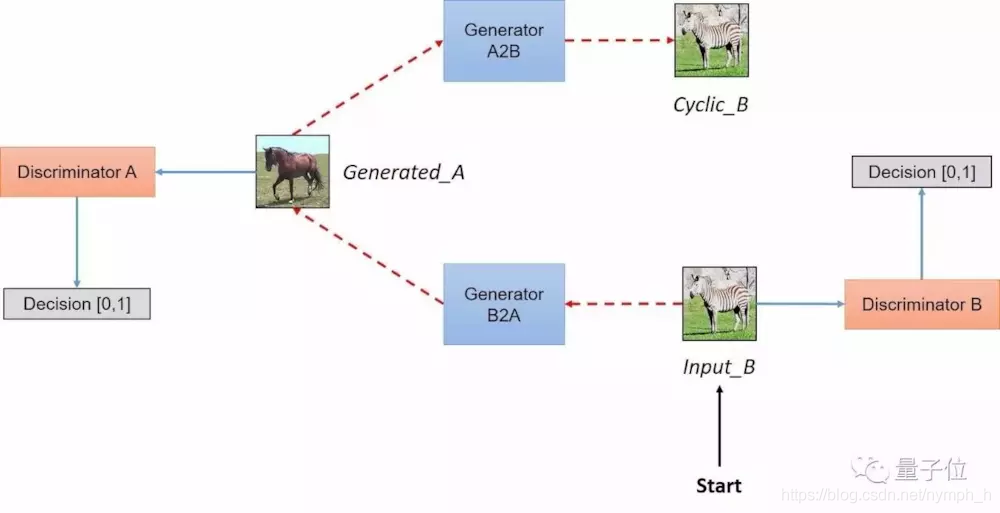
CycleGAN 流程:
[1] - 从域 A 中选择一张图片input_A,通过Generator A2B 变换为域 B 中的一张假图片Generated_B,计算分类器 Discrimination_B 的损失;
[2] - 将生成的假图片通过Generator B2A 变换回域 A,得到 Cyclic_A,计算其与 input_A 之间的损失;
[3] - 另一网络,执行相同的流程处理.
1. CycleGAN
#!/usr/bin/python3
#!--*-- coding: utf-8 --*--
"""
Pix2pix.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import time
from absl import app
from absl import flags
import tensorflow as tf
import tensorflow_datasets as tfds
FLAGS = flags.FLAGS
flags.DEFINE_integer('buffer_size', 400, 'Shuffle buffer size')
flags.DEFINE_integer('batch_size', 1, 'Batch Size')
flags.DEFINE_integer('epochs', 1, 'Number of epochs')
flags.DEFINE_string('path', None, 'Path to the data folder')
flags.DEFINE_boolean('enable_function', True, 'Enable Function?')
IMG_WIDTH = 256
IMG_HEIGHT = 256
AUTOTUNE = tf.data.experimental.AUTOTUNE # 根据可用的CPU动态设置并行调用的数量
def random_crop(image):
cropped_image = tf.image.random_crop(image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
@tf.function
def random_jitter(image):
# 调整大小为 286 x 286 x 3
image = tf.image.resize(image, [286, 286], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# 随机裁剪到 256 x 256 x 3
image = random_crop(image)
# 随机镜像
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
def create_horse2zebra_dataset(buffer_size, batch_size):
"""
Creates a tf.data Dataset.
Args:
path_to_train_images: Path to train images folder.
path_to_test_images: Path to test images folder.
buffer_size: Shuffle buffer size.
batch_size: Batch size
Returns:
train dataset, test dataset
"""
dataset, metadata = tfds.load('cycle_gan/horse2zebra', with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
#
train_horses = train_horses.map(preprocess_image_train, num_parallel_calls=AUTOTUNE).cache()
train_horses = train_horses.shuffle(buffer_size)
train_horses = train_horses.batch(batch_size)
train_zebras = train_zebras.map(preprocess_image_train, num_parallel_calls=AUTOTUNE).cache()
train_zebras = train_zebras.shuffle(buffer_size)
train_zebras = train_zebras.batch(batch_size)
test_horses = test_horses.map(preprocess_image_test, num_parallel_calls=AUTOTUNE).cache()
test_horses = test_horses.shuffle(buffer_size)
test_horses = test_horses.batch(batch_size)
test_zebras = test_zebras.map(preprocess_image_test, num_parallel_calls=AUTOTUNE).cache()
test_zebras = test_zebras.shuffle(buffer_size)
test_zebras = test_zebras.batch(batch_size)
#
dataset_dict = {}
dataset_dict['train_horses'] = train_horses
dataset_dict['train_zebras'] = train_zebras
dataset_dict['test_horses'] = test_horses
dataset_dict['test_zebras'] = test_zebras
return dataset_dict
class InstanceNormalization(tf.keras.layers.Layer):
"""
Instance Normalization Layer (https://arxiv.org/abs/1607.08022).
"""
def __init__(self, epsilon=1e-5):
super(InstanceNormalization, self).__init__()
self.epsilon = epsilon
def build(self, input_shape):
self.scale = self.add_weight(
name='scale',
shape=input_shape[-1:],
initializer=tf.random_normal_initializer(1., 0.02),
trainable=True)
self.offset = self.add_weight(
name='offset',
shape=input_shape[-1:],
initializer='zeros',
trainable=True)
def call(self, x):
mean, variance = tf.nn.moments(x, axes=[1, 2], keepdims=True)
inv = tf.math.rsqrt(variance + self.epsilon)
normalized = (x - mean) * inv
return self.scale * normalized + self.offset
def downsample(filters, size, norm_type='batchnorm', apply_norm=True):
"""
Downsamples an input.
Conv2D => Batchnorm => LeakyRelu
Args:
filters: number of filters
size: filter size
norm_type: Normalization type; either 'batchnorm' or 'instancenorm'.
apply_norm: If True, adds the batchnorm layer
Returns:
Downsample Sequential Model
"""
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_norm:
if norm_type.lower() == 'batchnorm':
result.add(tf.keras.layers.BatchNormalization())
elif norm_type.lower() == 'instancenorm':
result.add(InstanceNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
def upsample(filters, size, norm_type='batchnorm', apply_dropout=False):
"""
Upsamples an input.
Conv2DTranspose => Batchnorm => Dropout => Relu
Args:
filters: number of filters
size: filter size
norm_type: Normalization type; either 'batchnorm' or 'instancenorm'.
apply_dropout: If True, adds the dropout layer
Returns:
Upsample Sequential Model
"""
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
if norm_type.lower() == 'batchnorm':
result.add(tf.keras.layers.BatchNormalization())
elif norm_type.lower() == 'instancenorm':
result.add(InstanceNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
def unet_generator(output_channels, norm_type='batchnorm'):
"""
Modified u-net generator model (https://arxiv.org/abs/1611.07004).
Args:
output_channels: Output channels
norm_type: Type of normalization. Either 'batchnorm' or 'instancenorm'.
Returns:
Generator model
"""
down_stack = [
downsample(64, 4, norm_type, apply_norm=False), # (bs, 128, 128, 64)
downsample(128, 4, norm_type), # (bs, 64, 64, 128)
downsample(256, 4, norm_type), # (bs, 32, 32, 256)
downsample(512, 4, norm_type), # (bs, 16, 16, 512)
downsample(512, 4, norm_type), # (bs, 8, 8, 512)
downsample(512, 4, norm_type), # (bs, 4, 4, 512)
downsample(512, 4, norm_type), # (bs, 2, 2, 512)
downsample(512, 4, norm_type), # (bs, 1, 1, 512)
]
up_stack = [
upsample(512, 4, norm_type, apply_dropout=True), # (bs, 2, 2, 1024)
upsample(512, 4, norm_type, apply_dropout=True), # (bs, 4, 4, 1024)
upsample(512, 4, norm_type, apply_dropout=True), # (bs, 8, 8, 1024)
upsample(512, 4, norm_type), # (bs, 16, 16, 1024)
upsample(256, 4, norm_type), # (bs, 32, 32, 512)
upsample(128, 4, norm_type), # (bs, 64, 64, 256)
upsample(64, 4, norm_type), # (bs, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(
output_channels, 4, strides=2,
padding='same', kernel_initializer=initializer,
activation='tanh') # (bs, 256, 256, 3)
concat = tf.keras.layers.Concatenate()
inputs = tf.keras.layers.Input(shape=[None, None, 3])
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = concat([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
def discriminator(norm_type='batchnorm', target=True):
"""
PatchGan discriminator model (https://arxiv.org/abs/1611.07004).
Args:
norm_type: Type of normalization. Either 'batchnorm' or 'instancenorm'.
target: Bool, indicating whether target image is an input or not.
Returns:
Discriminator model
"""
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[None, None, 3], name='input_image')
x = inp
if target:
tar = tf.keras.layers.Input(shape=[None, None, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (bs, 256, 256, channels*2)
down1 = downsample(64, 4, norm_type, False)(x) # (bs, 128, 128, 64)
down2 = downsample(128, 4, norm_type)(down1) # (bs, 64, 64, 128)
down3 = downsample(256, 4, norm_type)(down2) # (bs, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)
conv = tf.keras.layers.Conv2D(
512, 4, strides=1, kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (bs, 31, 31, 512)
if norm_type.lower() == 'batchnorm':
norm1 = tf.keras.layers.BatchNormalization()(conv)
elif norm_type.lower() == 'instancenorm':
norm1 = InstanceNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(norm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)
last = tf.keras.layers.Conv2D(
1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1)
if target:
return tf.keras.Model(inputs=[inp, tar], outputs=last)
else:
return tf.keras.Model(inputs=inp, outputs=last)
def get_checkpoint_prefix():
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, 'ckpt')
return checkpoint_prefix
#
class CycleGAN(object):
def __init__(self, epochs, enable_function):
self.epochs = epochs
self.enable_function = enable_function
self.lambda_value = 10
self.loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
self.generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
self.generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
self.discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
self.discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
self.generator_g = unet_generator(output_channels=3, norm_type='instancenorm')
self.generator_f = unet_generator(output_channels=3, norm_type='instancenorm')
self.discriminator_x = discriminator(norm_type='instancenorm', target=False)
self.discriminator_y = discriminator(norm_type='instancenorm', target=False)
self.checkpoint = tf.train.Checkpoint(
generator_g=self.generator_g,
generator_f=self.generator_f,
discriminator_x=self.discriminator_x,
discriminator_y=self.discriminator_y,
generator_g_optimizer=self.generator_g_optimizer,
generator_f_optimizer=self.generator_f_optimizer,
discriminator_x_optimizer=self.discriminator_x_optimizer,
discriminator_y_optimizer=self.discriminator_y_optimizer)
def discriminator_loss(self, disc_real_output, disc_generated_output):
real_loss = self.loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = self.loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
#
def generator_loss(self, generated):
gan_loss = self.loss_object(tf.ones_like(generated), generated)
return gan_loss
def calc_cycle_loss(self, real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return self.lambda_value * loss1
def identity_loss(self, real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return self.lambda_value * 0.5 * loss
@tf.function
def train_step(self, real_x, real_y):
# persistent 设置为 Ture,因为 GradientTape 被多次应用于计算梯度
with tf.GradientTape(persistent=True) as tape:
# 生成器 G 转换 X -> Y
# 生成器 F 转换 Y -> X
fake_y = self.generator_g(real_x, training=True)
cycled_x = self.generator_f(fake_y, training=True)
fake_x = self.generator_f(real_y, training=True)
cycled_y = self.generator_g(fake_x, training=True)
# same_x 和 same_y 用于一致性损失。
same_x = self.generator_f(real_x, training=True)
same_y = self.generator_g(real_y, training=True)
disc_real_x = self.discriminator_x(real_x, training=True)
disc_real_y = self.discriminator_y(real_y, training=True)
disc_fake_x = self.discriminator_x(fake_x, training=True)
disc_fake_y = self.discriminator_y(fake_y, training=True)
# 计算损失
gen_g_loss = self.generator_loss(disc_fake_y)
gen_f_loss = self.generator_loss(disc_fake_x)
total_cycle_loss = self.calc_cycle_loss(real_x, cycled_x) + self.calc_cycle_loss(real_y, cycled_y)
# 总生成器损失 = 对抗性损失 + 循环损失。
total_gen_g_loss = gen_g_loss + total_cycle_loss + self.identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + self.identity_loss(real_x, same_x)
disc_x_loss = self.discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = self.discriminator_loss(disc_real_y, disc_fake_y)
# 计算生成器和判别器损失。
generator_g_gradients = tape.gradient(total_gen_g_loss, self.generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss, self.generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss, self.discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss, self.discriminator_y.trainable_variables)
# 将梯度应用于优化器。
self.generator_g_optimizer.apply_gradients(zip(generator_g_gradients, self.generator_g.trainable_variables))
self.generator_f_optimizer.apply_gradients(zip(generator_f_gradients, self.generator_f.trainable_variables))
self.discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients, self.discriminator_x.trainable_variables))
self.discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients, self.discriminator_y.trainable_variables))
return total_gen_g_loss, total_gen_f_loss, disc_x_loss, disc_y_loss
def train(self, dataset, checkpoint_pr):
"""
Train the GAN for x number of epochs.
Args:
dataset: train dataset.
checkpoint_pr: prefix in which the checkpoints are stored.
Returns:
Time for each epoch.
"""
time_list = []
if self.enable_function:
self.train_step = tf.function(self.train_step)
#
train_horses, train_zebras = dataset['train_horses'], dataset['train_zebras']
for epoch in range(self.epochs):
start_time = time.time()
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
total_gen_g_loss, total_gen_f_loss, disc_x_loss, disc_y_loss = self.train_step(image_x, image_y)
wall_time_sec = time.time() - start_time
time_list.append(wall_time_sec)
# saving (checkpoint) the model every 20 epochs
if (epoch + 1) % 10 == 0:
self.checkpoint.save(file_prefix=checkpoint_pr)
template = 'Epoch {}, Generator G loss {}, Generator F loss {}, Discriminator X Loss {}, Discriminator Y Loss {}'
print(template.format(epoch, total_gen_g_loss, total_gen_f_loss, disc_x_loss, disc_y_loss))
return time_list
def run_main(argv):
del argv
kwargs = {'epochs': FLAGS.epochs,
'enable_function': FLAGS.enable_function,
'path': FLAGS.path,
'buffer_size': FLAGS.buffer_size,
'batch_size': FLAGS.batch_size}
main(**kwargs)
def main(epochs, enable_function, path, buffer_size, batch_size):
path_to_folder = path
cyclegan_object = CycleGAN(epochs, enable_function)
dataset_dict = create_horse2zebra_dataset(buffer_size, batch_size)
checkpoint_pr = get_checkpoint_prefix()
print ('Training ...')
return cyclegan_object.train(dataset_dict, checkpoint_pr)
if __name__ == '__main__':
app.run(run_main)