主要参考:
[1] - Illustrated Guide to Transformers- Step by Step Explanation-2020.05.01
[2] - Github - hyunwoongko/transformer
Transformer 结构如图:
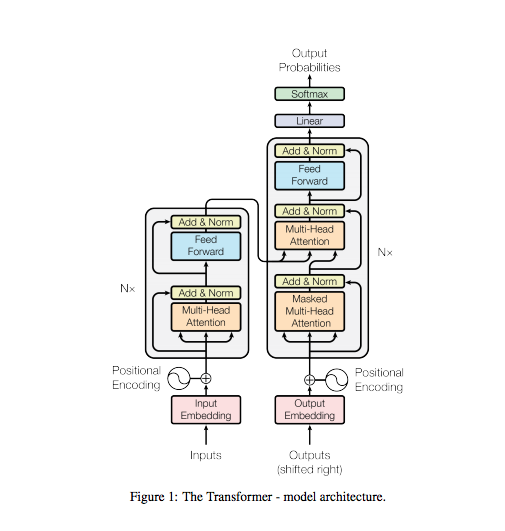
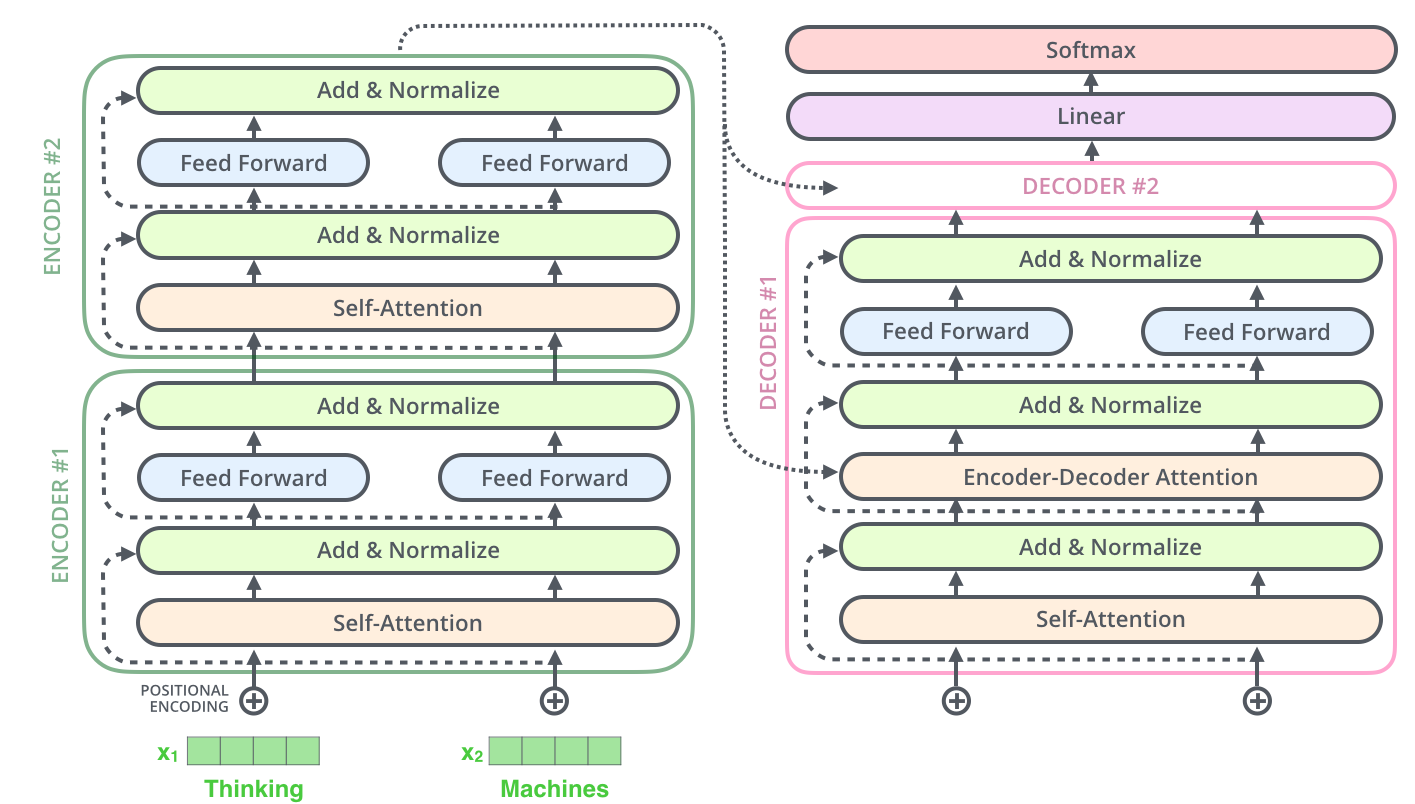
两层编码器+两层解码器组成的Transformer结构如图:
1. Attention 机制
Attention 机制使得 Transformer 能够获取非常长的记忆力(extremely long term memory).
Transformer 能够参与(attend)或关注(focus)所有先前所生成的 tokens.
token(符号): 包括单词和标点
tokenization(分词):词语是什么->['词语', '是', '什么']
基于示例,假如想要采用生成式 Transformer 写一部科幻小说,采用 Hugging Face 实现的 Write With Transformer 即可. 给定模型输入,模型会自动生成其余部分.
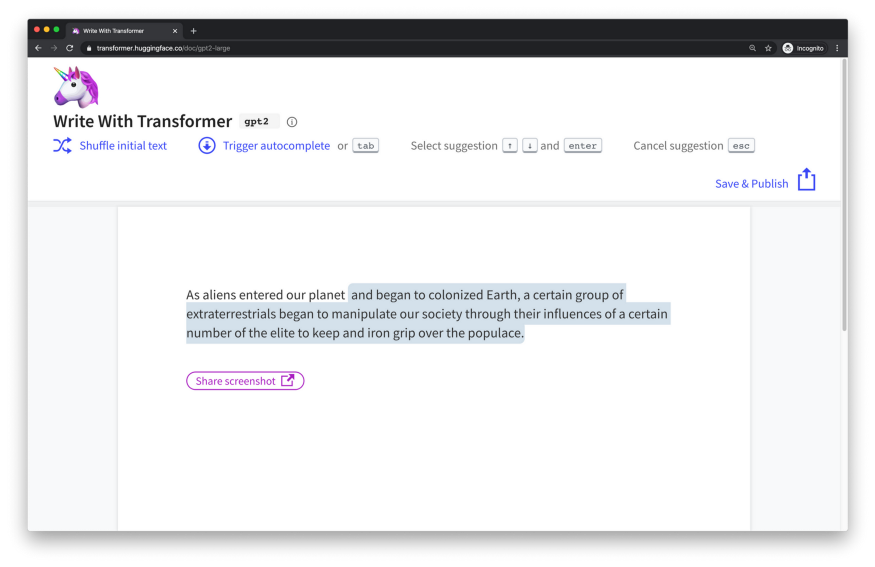
输入:“As Aliens entered our planet”.
Transformer输出: “and began to colonized Earth, a certain group of extraterrestrials began to manipulate our society through their influences of a certain number of the elite to keep and iron grip over the populace.”
虽然生成的故事有点黑暗,但有意思的是模型如何生成的故事. 当模型逐个单词生成文本时,其可以参与或关注与生成的单词相关的单词. 这种能够知道哪些单词被参与的能力是通过反向传播的训练过程中学会的.

图:在逐个生成单词的过程中,Attention 机制关注于不同的 tokens.
RNN(Recurrent neural networks) 也具有捕捉先前输入的能力. 但是,Attention 机制的能力在于,其不在受限于短时记忆.
RNN 的参考窗口更短,当故事变长时,RNN 将无法访问序列中较早生成的单词. 且,对于GRU(Gated Recurrent Units) 和 LSTM(Long-short Term Memory),虽然能够具有更大的容量来实现长期记忆,并因此具有更长的参考窗口,但其存在和 RNN 类似的问题.
而,Attention 机制,从理论上将,如果具有足够的计算资源,其具有无限的参考窗口,因此能够在生成文本的同时,使用故事的全部上下文信息.

图: Attention, RNN’s, GRU’s 和 LSTM 的假设参考窗口
2. Attention Is All You Need 逐步说明
Attention Is All You Need
Transformers 基于 Attention 的 encoder-decoder 结构,如图:
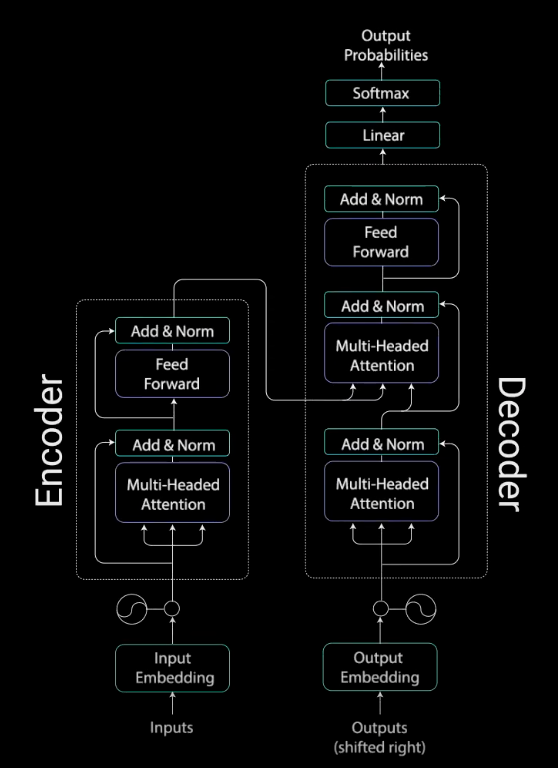
图:Transformer模型
概括来说,编码器将输入序列映射为抽象的连续表示形式,这种表示形式能够保留所有已经学习到的输入信息. 然后,解码器采用这种连续表示,并逐步生成单个输出,同时还接收先前的输出.
这里逐步说明,并给出参考实现,示例:
输入:“Hi how are you”
Transformer输出:“I am fine”
2.1. Input Embeddings
Transformer的第一步是,将输入送人 word embdding 层.
word embedding 层可以看作是一个查询表(lookup table),以获取每个单词的学习向量表示形式. 神经网络的学习是通过数字进行的,因此每个单词都被映射到具有连续值的向量来表示该单词.
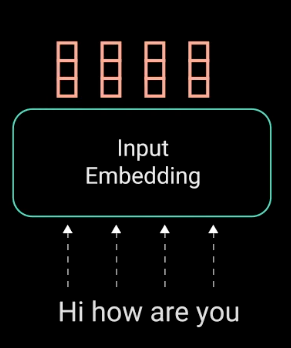
图:将 Words 转化为 Input Embeddings
实现如:
models/embedding/token_embeddings.py
from torch import nn
class TokenEmbedding(nn.Embedding):
"""
Token Embedding using torch.nn
they will dense representation of word using weighted matrix
"""
def __init__(self, vocab_size, d_model):
"""
class for token embedding that included positional information
:param vocab_size: size of vocabulary
:param d_model: dimensions of model
"""
super(TokenEmbedding, self).__init__(vocab_size, d_model, padding_idx=1)2.2. Positional Encoding
Transformer 下一步是对输入 embeddings 注入位置信息.
因为 Transformer 编码器没有类似于RNNs 的递归,因此必须将一些关于位置的信息添加到单词的 input embedding 中.
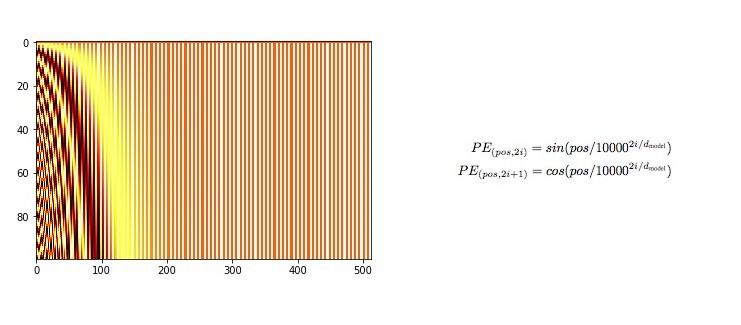
这里不深入位置编码的数学细节,但其基本原理是,对于输入向量的每个奇数索引,采用 cos 函数创建一个向量;对于每个偶数索引索引,采用 sin 函数创建一个向量;然后,将这些向量添加到对应的 input embedding 中,即可成功实现在每个向量的位置上给定网络信息. sin 函数和 cos 函数的一并选择,因为他们具有线性属性,模型可以很容易的学习.
实现如:
models/embedding/positional_encoding.py
import torch
from torch import nn
class PostionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(self, d_model, max_len, device):
"""
constructor of sinusoid encoding class
:param d_model: dimension of model
:param max_len: max sequence length
:param device: hardware device setting
"""
super(PostionalEncoding, self).__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
pos = torch.arange(0, max_len, device=device)
pos = pos.float().unsqueeze(dim=1)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, d_model, step=2, device=device).float()
# 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# it will add with tok_emb : [128, 30, 512]2.3. TransformerEmbedding
Input Embeddings 和 Postional Encoding 即为 Transformer 的 Embedding 层,实现如:
models/embedding/transformer_embedding.py
from torch import nn
from models.embedding.positional_encoding import PostionalEncoding
from models.embedding.token_embeddings import TokenEmbedding
class TransformerEmbedding(nn.Module):
"""
token embedding + positional encoding (sinusoid)
positional encoding can give positional information to network
"""
def __init__(self, vocab_size, d_model, max_len, drop_prob, device):
"""
class for word embedding that included positional information
:param vocab_size: size of vocabulary
:param d_model: dimensions of model
"""
super(TransformerEmbedding, self).__init__()
self.tok_emb = TokenEmbedding(vocab_size, d_model)
self.pos_emb = PostionalEncoding(d_model, max_len, device)
self.drop_out = nn.Dropout(p=drop_prob)
def forward(self, x):
tok_emb = self.tok_emb(x)
pos_emb = self.pos_emb(x)
return self.drop_out(tok_emb + pos_emb)2.3. Encoder Layer
接着是 Transformer 的编码器层.
编码器层的工作是,将所有输入序列映射为抽象的连续表示形式,这种连续表示形式能够保留整个序列的所有学习到的信息. 其包含 2 个子模块,multi-headed attention 以及其后接的 fully connected network. 此外,对于每个子模块还有残差连接,然后接 layer normalization 层.
如图:
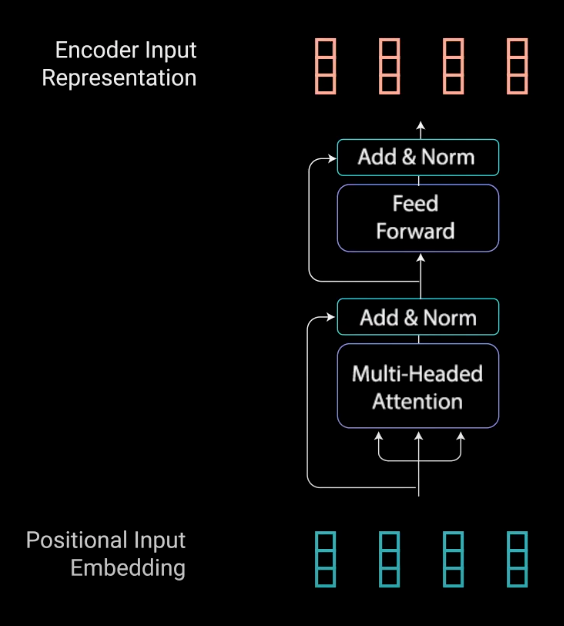
图:编码器层的子模块
其实现如:
models/blocks/encoder_layer.py
from torch import nn
from models.layers.layer_norm import LayerNorm
from models.layers.multi_head_attention import MultiHeadAttention
from models.layers.position_wise_feed_forward import PositionwiseFeedForward
class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x, s_mask):
# 1. compute self attention
_x = x
x = self.attention(q=x, k=x, v=x, mask=s_mask) # x->q,k,v
# 2. add and norm
x = self.norm1(x + _x)
x = self.dropout1(x)
# 3. positionwise feed forward network
_x = x
x = self.ffn(x)
# 4. add and norm
x = self.norm2(x + _x)
x = self.dropout2(x)
return x2.3.1. Multi-Headed Attention
编码器中的 Multi-headed attention 模块采用了一种特殊的 Attention 机制,即:Self-Attention(自注意力机制).
Self-Attention 使得模型能够关联输入中的每个单词和其他单词. 因此,对于示例,模型可以学习到单词 “you” 和 “how” 及 “are” 之间的关联性. 模型还可能会学习到,在这种模式里的单词往往是一个问题,并做出适当的回答.
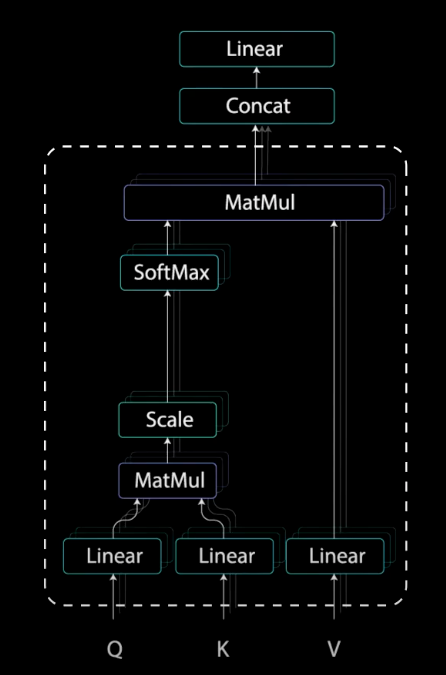
图:Encoder Self-Attention Operations.
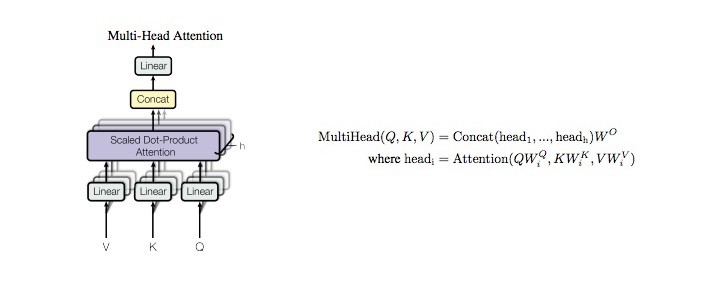
其实现如:
models/layers/multi_head_attention.py
from torch import nn
from models.layers.scale_dot_product_attention import ScaleDotProductAttention
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention() #
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_concat = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2. split tensor by number of heads
q, k, v = self.split(q), self.split(k), self.split(v)
# 3. do scale dot product to compute similarity
out, attention = self.attention(q, k, v, mask=mask)
# 4. concat and pass to linear layer
out = self.concat(out)
out = self.w_concat(out)
# 5. visualize attention map
# TODO : we should implement visualization
return out
def split(self, tensor):
"""
split tensor by number of head
:param tensor: [batch_size, length, d_model]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, d_model = tensor.size()
d_tensor = d_model // self.n_head
tensor = tensor.view(batch_size, self.n_head, length, d_tensor)
# it is similar with group convolution (split by number of heads)
return tensor
def concat(self, tensor):
"""
inverse function of self.split(tensor : torch.Tensor)
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, d_model]
"""
batch_size, head, length, d_tensor = tensor.size()
d_model = head * d_tensor
tensor = tensor.view(batch_size, length, d_model)
return tensor2.3.1.1. ScaleDotProductAttention
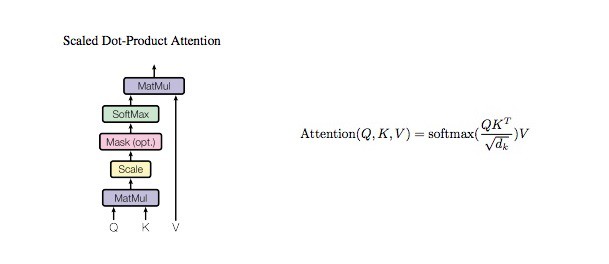
其实现如:
scale_dot_product_attention.py
import math
from torch import nn
class ScaleDotProductAttention(nn.Module):
"""
compute scale dot product attention
Query : given sentence that we focused on (decoder)
Key : every sentence to check relationship with Qeury(encoder)
Value : every sentence same with Key (encoder)
"""
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax()
def forward(self, q, k, v, mask=None, e=1e-12):
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot product Query with Key^T to compute similarity
k_t = k.view(batch_size, head, d_tensor, length) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2. apply masking (opt)
if mask is not None:
score = score.masked_fill(mask == 0, -e)
# 3. pass them softmax to make [0, 1] range
score = self.softmax(score)
# 4. multiply with Value
v = score @ v
return v, score逐步分析如下:
[1] - Query, Key, Value Vectors
为了实现 Self-Attention,首先将输入送到 3 个不同的 fully connected layers,以得到 query, key, 和 value vectors.
而,query, key, value vectors 这三个向量表示什么呢,可以参考:what-exactly-are-keys-queries-and-values-in-attention-mechanisms.
query,key,value的概念来自于检索系统. 例如:
当在 Youtube 输入 query 来搜索某些视频时,搜索引擎会将 query 映射到一组 keys 集合(包含,视频标题、描述等),其关联了数据库中的候选视频,然后返回最佳的匹配视频结果(values).
[2] - Dot Product of Query and Key
将 query, key 和 value 向量经过 linear 层处理后,queries 和 keys 经过点积矩阵相乘,得到得分(score)矩阵.
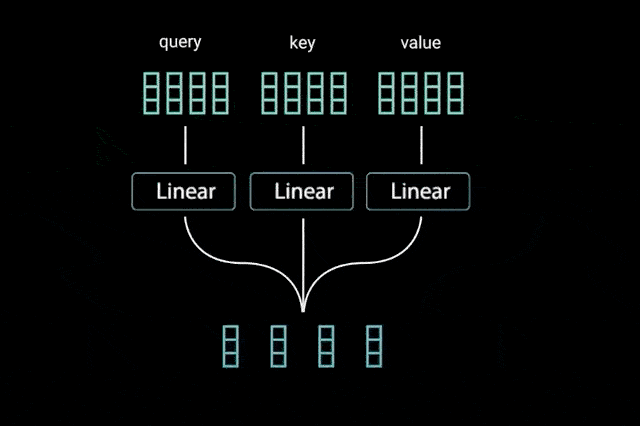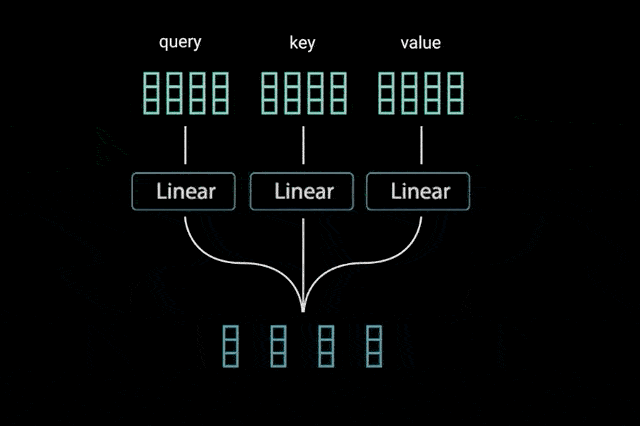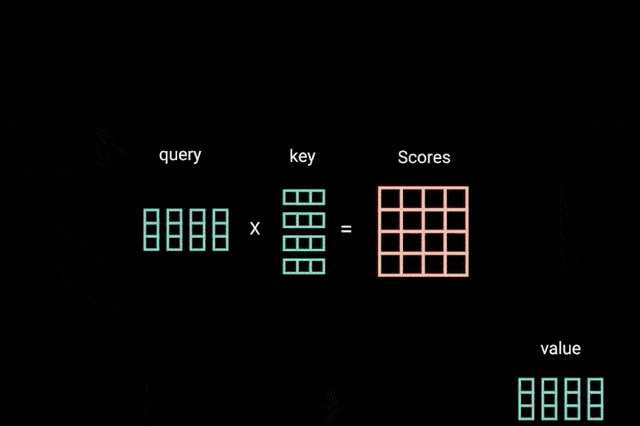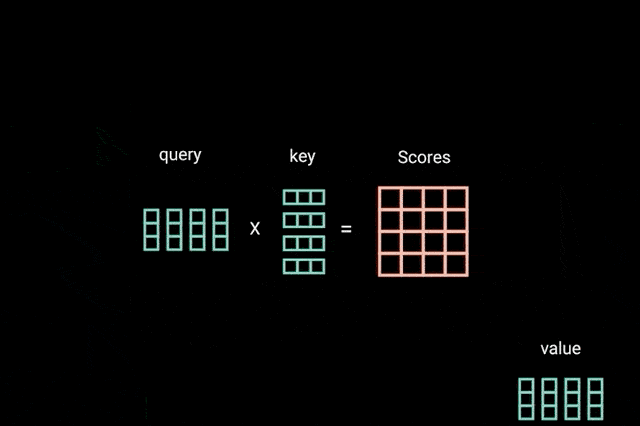
图:query 和 key 的点积矩阵乘法
score 矩阵确定了一个单词应该放到其他单词上的重要成都. 因此,每个单词和其他单词都有一个对应的分数. 分数越高,关联性越高. 这就是 queries 如何被映射到 keys 上的原理.

图:点积得到的 Attention scores 矩阵.
[3] - Scaling Down the Attention Scores
接着,attentions scores 通过除以 query 和 key 的维度的平方根进行缩放. 以得到更稳定的梯度,因为相乘的值可能会导致梯度爆炸.(使得 scores 的方差变小.)
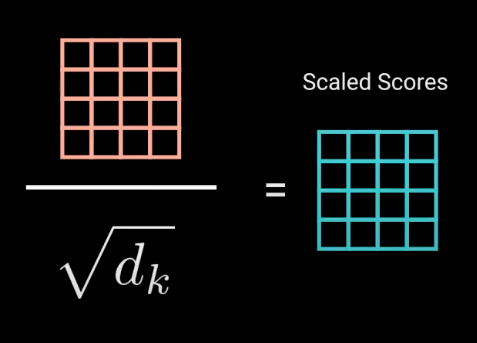
图:Attention scores 缩放
[4] - Softmax of the Scaled Scores
接着,可以对缩放后的 scores 采用 softmax 处理,以得到 attention 权重,其是 0-1之间的概率值. Softmax 处理后,较高的分数会提高,而较低的分数会抑制,使得模型更加自信地关注要参与的单词.

图:scaled scores 的 softmax 处理,以得到概率值
[5] - Multiply Softmax Output with Value vector
接着,将 attention 权重和 value 向量相乘,以得到输出向量. 较高的 softmax scores 值将使模型学习的单词的 value 值更重要. 而较低的 scores 值将淹没为无关的单词. 然后,将相乘的输出送到线性层进行处理.

2.3.1.2. Computing Multi-headed Attention
multi-headed attention 的计算,需要在 Self-Attention 前,将 query, key, value f分别划分为 N 个向量. 然后,划分后的向量分别经过 Self-Attention 处理. 每个 Self-Attention 处理称为一个 head. 每个 head 输出一个向量,该向量在经过最后的线性层处理之前,被连接为一个向量.
理论上来说,每个 head 会学习到一些不同的信息,因此可以赋予编码器模型更多的表示能力.

图:Self-Attention 处理前,将 Q, K, V 分为 N 块
综上,multi-headed attention 是 Transformer 网络中的一个模块,其可以计算输入的 attention 权重,并输出向量;该输出向量编码了序列中单词和其他单词之间的关联性信息.
2.3.2. Residual Connections, Layer Normalization 和 Feed Forward Network
multi-headed attention 的输出向量,被添加到原始的 postional input embedding. 即残差连接(residual connection). 残差连接的输出再经过 layer normalization 处理.
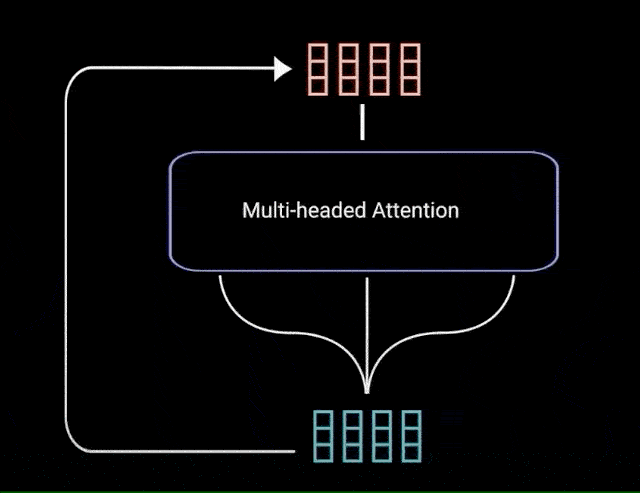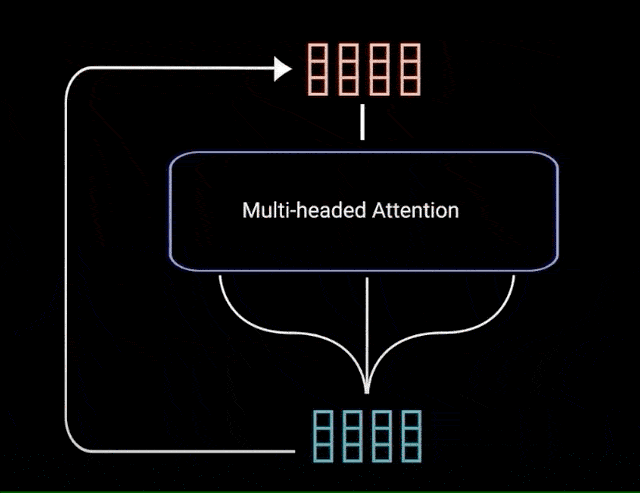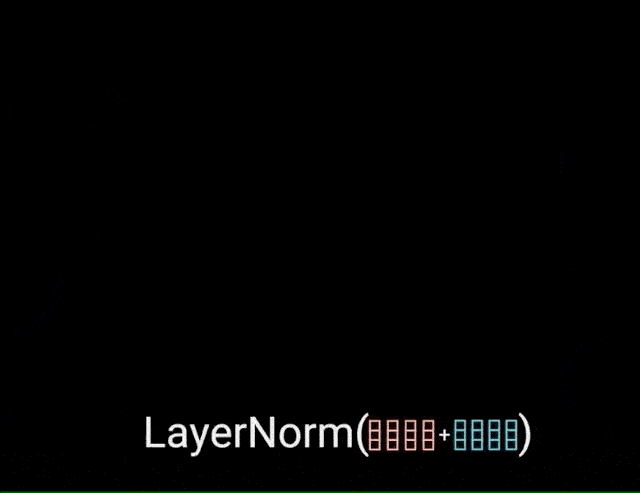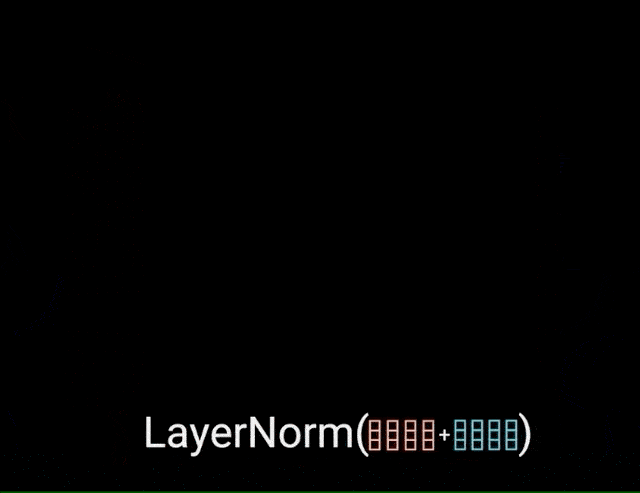
图:postional input embedding 和 multi-headed attention 输出的残差连接
归一化化后的残差输出再通过 pointwise feed-forward network 进一步处理. pointwise feed-forward network 是一对线性层,中间有一个 ReLU 激活层. 然后,将其输出再次添加到 pointwise feed-forward network 的输入中,并进一步进行归一化.
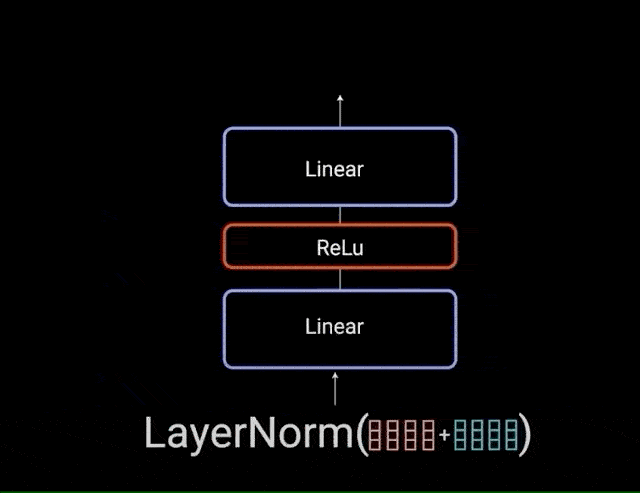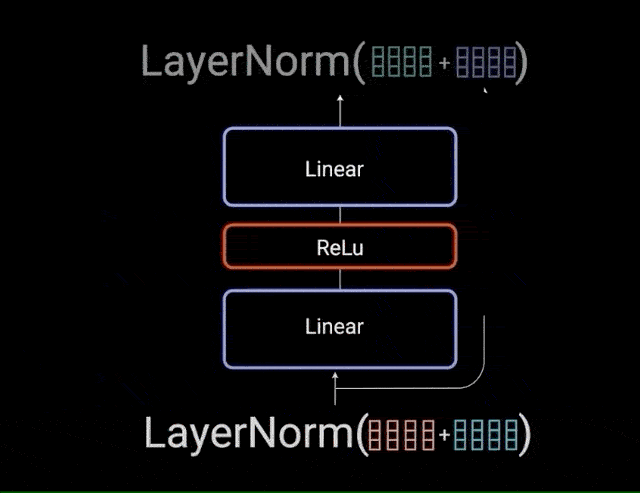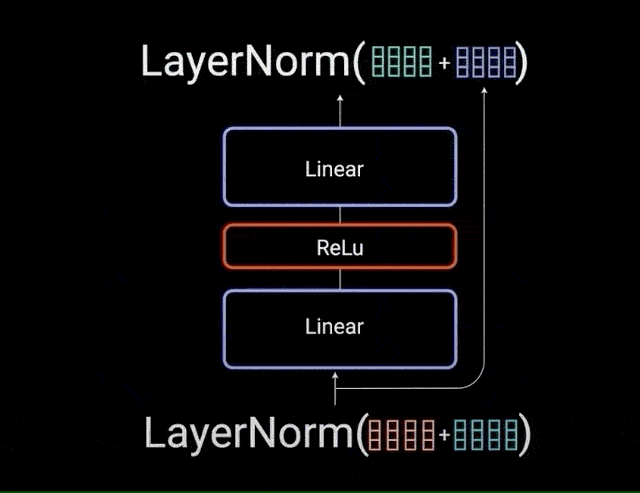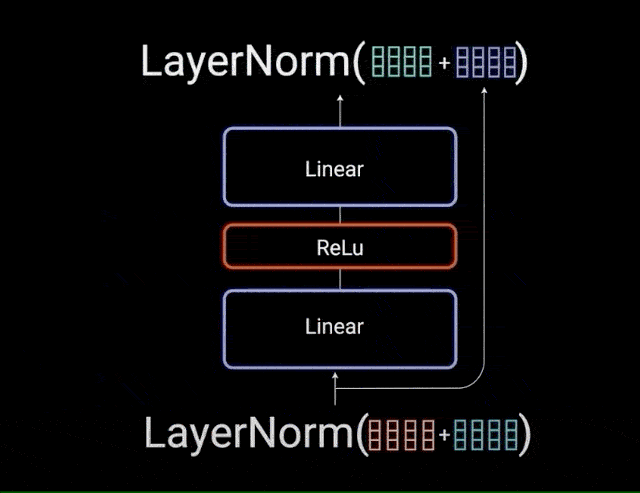
图:point-wise feedforward layer 网络层输入和输出的残差连接
残差连接通过允许梯度直接流过网络,有助于网络训练. Layer normalizations 用于稳定网络,从而大大减少训练所需时间. pointwise feedforward layer 用于投影 attention 输出,从而可能使其具有更丰富的表示形式.
2.3.2.1. LayerNorm
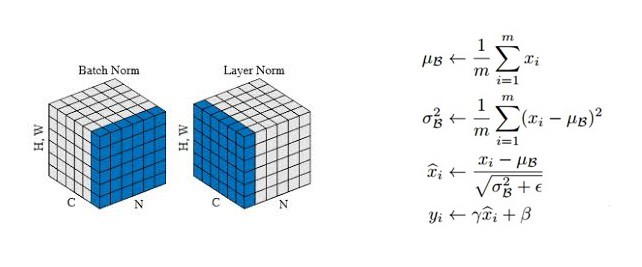
实现如:
models/layers/layer_norm.py
import torch
from torch import nn
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# '-1' means last dimension.
out = (x - mean) / (std + self.eps)
out = self.gamma * out + self.beta
return out2.3.2.2. PositionwiseFeedForward

实现如:
models/layers/position_wise_feed_forward.py
from torch import nn
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, hidden, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=drop_prob)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x2.3.3. Encoder Wrap-up
封装编码器层. 所有的编码器操作都是将输入编码为带有 attention 信息的连续表示形式. 其将有助于解码器在解码过程中,更着重于输入中的适当单词.
可以将编码器堆叠 N 次,以进一步对信息进行编码,其中每一层都有可能学习不同的 Attention 表示,因此有可能提升 Transformer 的预测能力.
实现如:
models/model/encoder.py
from torch import nn
from models.blocks.encoder_layer import EncoderLayer
from models.embedding.transformer_embedding import TransformerEmbedding
class Encoder(nn.Module):
def __init__(self, enc_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
max_len=max_len,
vocab_size=enc_voc_size,
drop_prob=drop_prob,
device=device)
self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
def forward(self, x, s_mask):
x = self.emb(x)
for layer in self.layers:
x = layer(x, s_mask)
return x2.4. Decoder Layer
解码器的工作是,生成文本序列.
解码器具有和编码器相似的子网络层(sub-layer),其包含 2 个 multi-headed attention 层,1 个 pointwise feed-forward 层,残差连接, layer normalization 层. 这些 sub-layers 具有类似于在解码器中的相似作用,但是,每个 multi-headed attention 层的作用却不用. 解码器的输出为采用线性层和 softmax 层作为分类器,以得到单词的概率.

图:Decoder Layer
解码器是自回归的(autoregressive),其以起始 token 作为开始,并且将先前输出的列表,以及包含来自输入的 Attention 信息的编码器输出,作为输入. 当解码器生成 token 作为输出时,停止解码器解码.
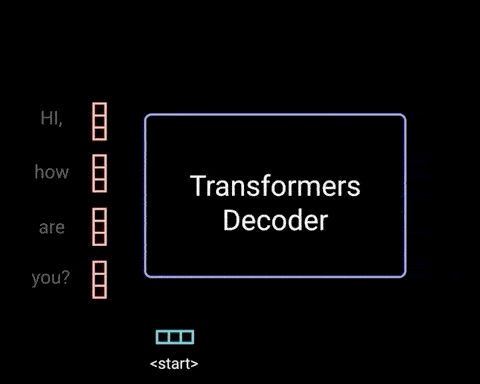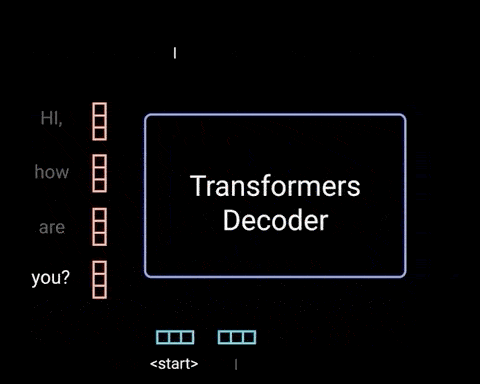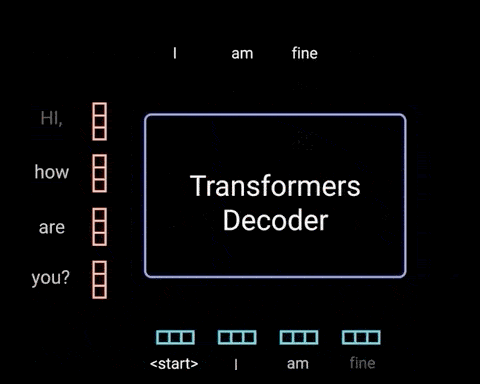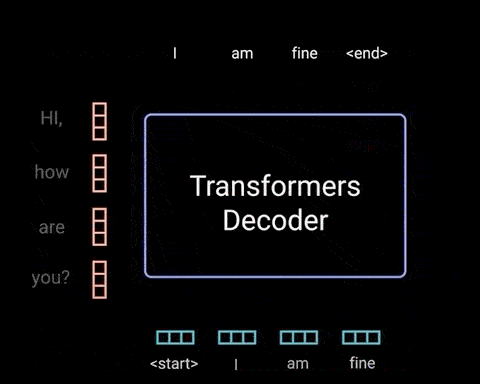
解码器实现如:
models/blocks/decoder_layer.py
from torch import nn
from models.layers.layer_norm import LayerNorm
from models.layers.multi_head_attention import MultiHeadAttention
from models.layers.position_wise_feed_forward import PositionwiseFeedForward
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.enc_dec_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm3 = LayerNorm(d_model=d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec, enc, t_mask, s_mask):
# 1. compute self attention
_x = dec
x = self.self_attention(q=dec, k=dec, v=dec, mask=t_mask)
# 2. add and norm
x = self.norm1(x + _x)
x = self.dropout1(x)
if enc is not None:
# 3. compute encoder - decoder attention
_x = x
x = self.enc_dec_attention(q=x, k=enc, v=enc, mask=s_mask)
# 4. add and norm
x = self.norm2(x + _x)
x = self.dropout2(x)
# 5. positionwise feed forward network
_x = x
x = self.ffn(x)
# 6. add and norm
x = self.norm3(x + _x)
x = self.dropout3(x)
return x2.4.1. Input Embeddings 和 Positional Encoding
解码器的开始部分与编码器几乎相同. 输入经过 input embedding 层和 positional encoding 层处理. positional embeddings 被送入第一个 multi-head attention 层,以计算解码器输入的 attention scores.
2.4.2. Decoders First Multi-Headed Attention
解码器第一个 multi-head attention 层的操作略有不同.
因为解码器是自回归的,且逐个单词的生成序列,需要避免其受到未来 tokens 的约数限制. 例如,当计算单词 "am" 的 attention scores 时,不应该包含单词 "fine",因为这个单词是未来才生成的单词. 单词 "am" 应该仅能访问其自己以及其前面的单词. 同理,对于其他所有单词,也智能访问其先前的单词.

因此需要一种方法来避免计算未来单词的 attention scores. 即:masking. 为了避免解码器的查看到未来 tokens,可以采用 look ahead mask. 再计算 softmax 前,和scores 缩放之后,添加 mask. 其工作如下.
2.4.2.1. Look-Ahead Mask
mask 是一个与 attention scores 相同大小的矩阵,其值填充为 0 和 -inf. 当将 mask 添加到缩放 attention socres 后,得到一个 scores 的矩阵,其右上三角填充为 -inf.

图: 添加 look-ahead mask 到 scaled scores
设置 mask 的原因是,一旦得到 masked scores 的 softmax 值,-inf 会被清零,从而使得未来 tokens 的 attention scores 值为0. 如下图所示,"am" 的 attention scores值,有其自身以及其之前的值,而对于单词 "fine" 的值为0. 本质上是告诉模型不要将重点放到这些单词上.
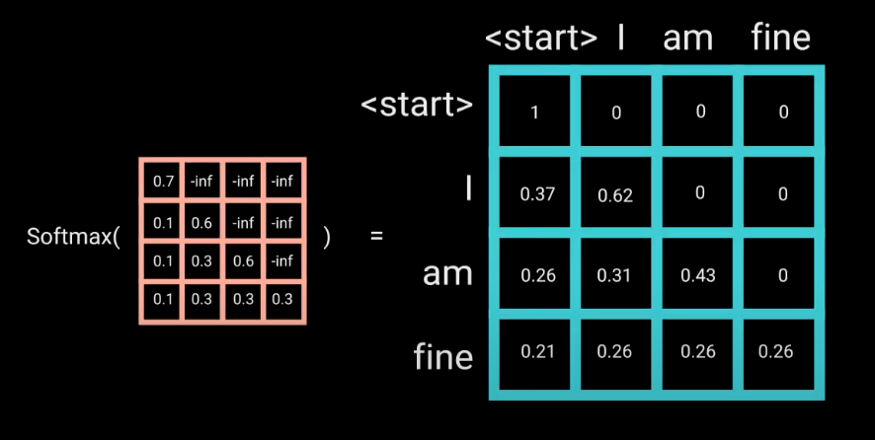
masking 是第一个 multi-headed attention 层的 attention scores 计算中的唯一区别. 第一个 multi-headed attention 层的输出是 masked 输出向量,其包含了模型应该如何参与解码器输入的信息.
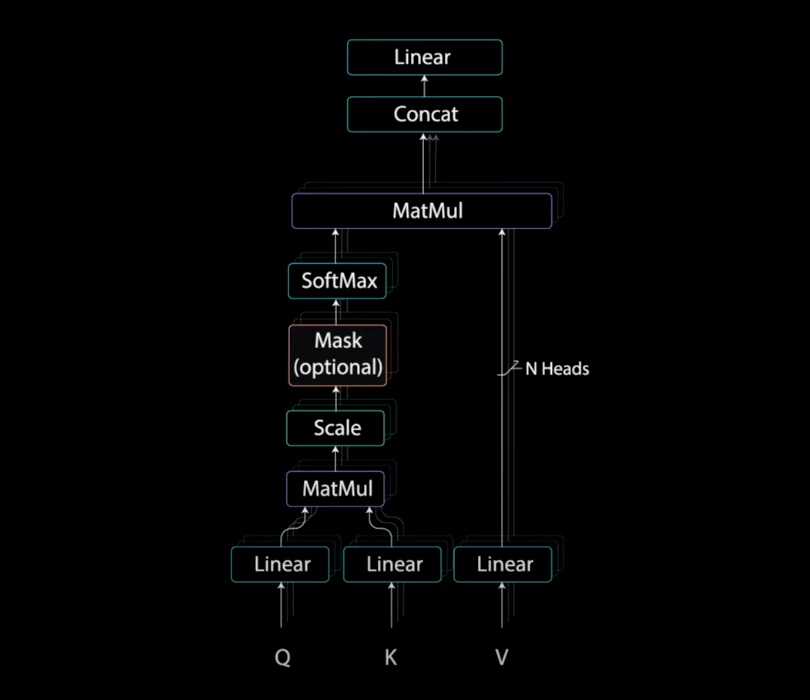
图:Multi-Headed Attention with Masking
#### 2.4.3. Decoder Second Multi-Headed Attention 和 Point-wise Feed Forward Layer
对于解码器的第二个 multi-headed attention 层,编码器的输出是 queries 和 keys,第一个 multi-headed attention 的输出是 values. 此过程使得编码器的输入和解码器的输入相匹配,从而使解码器可以确定哪些编码器输入是与重点关注的是相关的.
第二个 multi-headed attention 层的输出经过 pointwise feedforward 进一步处理.
2.4.4. Linear Classifier and Final Softmax for Output Probabilities
pointwise feedforward 的输出经过最终的线性层处理,该线性层作为作为分类器. 分类器是与类别数一样大的. 例如,假设 10000 个单词有 10000 个类,则分类器的输出是 10000. 分类器的输出被送入 Softmax 层处理,以输出 0-1 之间的概率值. 采用最大概率的索引,该索引对应于要预测的单词.
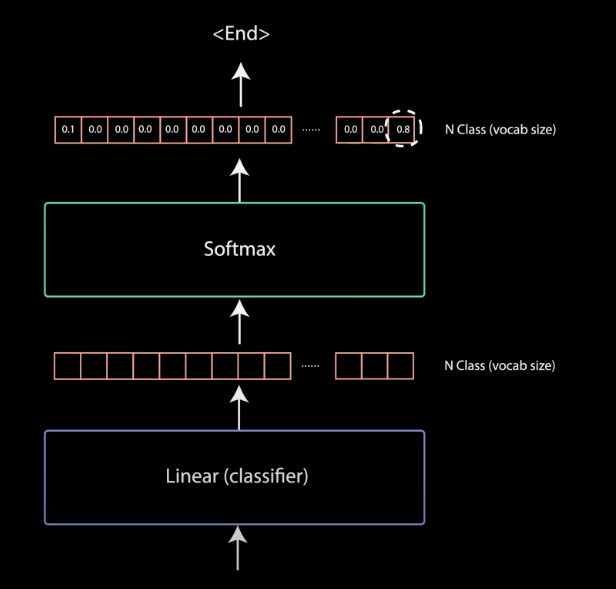
图:Linear Classifier with Softmax to get the Output Probabilities
然后,解码器得到输出,将其添加到解码器的输入列表中,然后再次继续解码,知道预测处 token 位置. 比如,最高的概率预测为分配给结束 token 的类别.
解码器也可以堆叠 N 层,每层接收来自编码器及其之前各层的输入. 通过堆叠网络层,模型可以学习从其 attention heads 中提取并关注与不同的 attention 组合,从而有可能增强其预测能力.

图:Stacked Encoder and Decoder
其实现如:
models/model/decoder.py
import torch
from torch import nn
from models.blocks.decoder_layer import DecoderLayer
from models.embedding.transformer_embedding import TransformerEmbedding
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, enc_src, trg_mask, src_mask):
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, enc_src, trg_mask, src_mask)
# pass to LM head
output = self.linear(trg)
return output2.5. Transformer 实现
如:
models/model/transformer.py
import torch
from torch import nn
from models.model.decoder import Decoder
from models.model.encoder import Encoder
class Transformer(nn.Module):
def __init__(self, src_pad_idx, trg_pad_idx, trg_sos_idx, enc_voc_size, dec_voc_size, d_model, n_head, max_len,
ffn_hidden, n_layers, drop_prob, device):
super().__init__()
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.trg_sos_idx = trg_sos_idx
self.device = device
self.encoder = Encoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
enc_voc_size=enc_voc_size,
drop_prob=drop_prob,
n_layers=n_layers,
device=device)
self.decoder = Decoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
dec_voc_size=dec_voc_size,
drop_prob=drop_prob,
n_layers=n_layers,
device=device)
def forward(self, src, trg):
src_mask = self.make_pad_mask(src, src)
src_trg_mask = self.make_pad_mask(trg, src)
trg_mask = self.make_pad_mask(trg, trg) * \
self.make_no_peak_mask(trg, trg)
enc_src = self.encoder(src, src_mask)
output = self.decoder(trg, enc_src, trg_mask, src_trg_mask)
return output
def make_pad_mask(self, q, k):
len_q, len_k = q.size(1), k.size(1)
# batch_size x 1 x 1 x len_k
k = k.ne(self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# batch_size x 1 x len_q x len_k
k = k.repeat(1, 1, len_q, 1)
# batch_size x 1 x len_q x 1
q = q.ne(self.src_pad_idx).unsqueeze(1).unsqueeze(3)
# batch_size x 1 x len_q x len_k
q = q.repeat(1, 1, 1, len_k)
mask = k & q
return mask
def make_no_peak_mask(self, q, k):
len_q, len_k = q.size(1), k.size(1)
# len_q x len_k
mask = torch.tril(torch.ones(len_q, len_k)).type(torch.BoolTensor).to(self.device)
return mask3. Transformer 训练与测试
3.1. Transformer 训练
实现如:
hyunwoongko/transformer/train.py
import math
import time
from torch import nn, optim
from torch.optim import Adam
from data import *
from models.model.transformer import Transformer
from util.bleu import idx_to_word, get_bleu
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def initialize_weights(m):
if hasattr(m, 'weight') and m.weight.dim() > 1:
nn.init.kaiming_uniform(m.weight.data)
#
model = Transformer(src_pad_idx=src_pad_idx,
trg_pad_idx=trg_pad_idx,
trg_sos_idx=trg_sos_idx,
d_model=d_model,
enc_voc_size=enc_voc_size,
dec_voc_size=dec_voc_size,
max_len=max_len,
ffn_hidden=ffn_hidden,
n_head=n_heads,
n_layers=n_layers,
drop_prob=drop_prob,
device=device).to(device)
print(f'The model has {count_parameters(model):,} trainable parameters')
model.apply(initialize_weights)
optimizer = Adam(params=model.parameters(),
lr=init_lr,
weight_decay=weight_decay,
eps=adam_eps)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
verbose=True,
factor=factor,
patience=patience)
criterion = nn.CrossEntropyLoss(ignore_index=src_pad_idx)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg[:, :-1])
output_reshape = output.contiguous().view(-1, output.shape[-1])
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output_reshape, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
print('step :', round((i / len(iterator)) * 100, 2), '% , loss :', loss.item())
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
batch_bleu = []
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg[:, :-1])
output_reshape = output.contiguous().view(-1, output.shape[-1])
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output_reshape, trg)
epoch_loss += loss.item()
total_bleu = []
for j in range(batch_size):
try:
trg_words = idx_to_word(batch.trg[j], loader.target.vocab)
output_words = output[j].max(dim=1)[1]
output_words = idx_to_word(output_words, loader.target.vocab)
bleu = get_bleu(hypotheses=output_words.split(), reference=trg_words.split())
total_bleu.append(bleu)
except:
pass
total_bleu = sum(total_bleu) / len(total_bleu)
batch_bleu.append(total_bleu)
batch_bleu = sum(batch_bleu) / len(batch_bleu)
return epoch_loss / len(iterator), batch_bleu
def run(total_epoch, best_loss):
train_losses, test_losses, bleus = [], [], []
for step in range(total_epoch):
start_time = time.time()
train_loss = train(model, train_iter, optimizer, criterion, clip)
valid_loss, bleu = evaluate(model, valid_iter, criterion)
end_time = time.time()
if step > warmup:
scheduler.step(valid_loss)
train_losses.append(train_loss)
test_losses.append(valid_loss)
bleus.append(bleu)
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_loss:
best_loss = valid_loss
torch.save(model.state_dict(), 'saved/model-{0}.pt'.format(valid_loss))
f = open('result/train_loss.txt', 'w')
f.write(str(train_losses))
f.close()
f = open('result/bleu.txt', 'w')
f.write(str(bleus))
f.close()
f = open('result/test_loss.txt', 'w')
f.write(str(test_losses))
f.close()
print(f'Epoch: {step + 1} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\tVal Loss: {valid_loss:.3f} | Val PPL: {math.exp(valid_loss):7.3f}')
print(f'\tBLEU Score: {bleu:.3f}')
if __name__ == '__main__':
run(total_epoch=epoch, best_loss=inf)其中涉及的函数有:
3.1.1. 配置conf
conf.py
import torch
# GPU device setting
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# model parameter setting
batch_size = 16 # 128
max_len = 256
d_model = 512
n_layers = 6
n_heads = 8
ffn_hidden = 2048
drop_prob = 0.1
# optimizer parameter setting
init_lr = 1e-5
factor = 0.9
adam_eps = 5e-9
patience = 10
warmup = 100
epoch = 1000
clip = 1.0
weight_decay = 5e-4
inf = float('inf')3.1.2. 数据data
data.py
from conf import *
from util.data_loader import DataLoader
from util.tokenizer import Tokenizer
tokenizer = Tokenizer()
loader = DataLoader(ext=('.en', '.de'),
tokenize_en=tokenizer.tokenize_en,
tokenize_de=tokenizer.tokenize_de,
init_token='<sos>',
eos_token='<eos>')
train, valid, test = loader.make_dataset()
loader.build_vocab(train_data=train, min_freq=2)
train_iter, valid_iter, test_iter = loader.make_iter(train, valid, test,
batch_size=batch_size,
device=device)
src_pad_idx = loader.source.vocab.stoi['<pad>']
trg_pad_idx = loader.target.vocab.stoi['<pad>']
trg_sos_idx = loader.target.vocab.stoi['<sos>']
enc_voc_size = len(loader.source.vocab)
dec_voc_size = len(loader.target.vocab)util/bleu.py
import math
from collections import Counter
import numpy as np
def bleu_stats(hypothesis, reference):
"""Compute statistics for BLEU."""
stats = []
stats.append(len(hypothesis))
stats.append(len(reference))
for n in range(1, 5):
s_ngrams = Counter(
[tuple(hypothesis[i:i + n]) for i in range(len(hypothesis) + 1 - n)]
)
r_ngrams = Counter(
[tuple(reference[i:i + n]) for i in range(len(reference) + 1 - n)]
)
stats.append(max([sum((s_ngrams & r_ngrams).values()), 0]))
stats.append(max([len(hypothesis) + 1 - n, 0]))
return stats
def bleu(stats):
"""Compute BLEU given n-gram statistics."""
if len(list(filter(lambda x: x == 0, stats))) > 0:
return 0
(c, r) = stats[:2]
log_bleu_prec = sum(
[math.log(float(x) / y) for x, y in zip(stats[2::2], stats[3::2])]
) / 4.
return math.exp(min([0, 1 - float(r) / c]) + log_bleu_prec)
def get_bleu(hypotheses, reference):
"""Get validation BLEU score for dev set."""
stats = np.array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
for hyp, ref in zip(hypotheses, reference):
stats += np.array(bleu_stats(hyp, ref))
return 100 * bleu(stats)
def idx_to_word(x, vocab):
words = []
for i in x:
word = vocab.itos[i]
if '<' not in word:
words.append(word)
words = " ".join(words)
return wordsutil/tokenizer.py
import spacy
class Tokenizer:
def __init__(self):
self.spacy_de = spacy.load('de_core_news_sm')
self.spacy_en = spacy.load('en_core_web_sm')
def tokenize_de(self, text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in self.spacy_de.tokenizer(text)]
def tokenize_en(self, text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in self.spacy_en.tokenizer(text)]3.1.3. DataLoader
util/data_loader.py
from torchtext.legacy.data import Field, BucketIterator
from torchtext.legacy.datasets.translation import Multi30k
class DataLoader:
source: Field = None
target: Field = None
def __init__(self, ext, tokenize_en, tokenize_de, init_token, eos_token):
self.ext = ext
self.tokenize_en = tokenize_en
self.tokenize_de = tokenize_de
self.init_token = init_token
self.eos_token = eos_token
print('dataset initializing start')
def make_dataset(self):
if self.ext == ('.de', '.en'):
self.source = Field(tokenize=self.tokenize_de, init_token=self.init_token, eos_token=self.eos_token,
lower=True, batch_first=True)
self.target = Field(tokenize=self.tokenize_en, init_token=self.init_token, eos_token=self.eos_token,
lower=True, batch_first=True)
elif self.ext == ('.en', '.de'):
self.source = Field(tokenize=self.tokenize_en, init_token=self.init_token, eos_token=self.eos_token,
lower=True, batch_first=True)
self.target = Field(tokenize=self.tokenize_de, init_token=self.init_token, eos_token=self.eos_token,
lower=True, batch_first=True)
train_data, valid_data, test_data = Multi30k.splits(exts=self.ext, fields=(self.source, self.target))
return train_data, valid_data, test_data
def build_vocab(self, train_data, min_freq):
self.source.build_vocab(train_data, min_freq=min_freq)
self.target.build_vocab(train_data, min_freq=min_freq)
def make_iter(self, train, validate, test, batch_size, device):
train_iterator, valid_iterator, test_iterator = BucketIterator.splits((train, validate, test),
batch_size=batch_size,
device=device)
print('dataset initializing done')
return train_iterator, valid_iterator, test_iterator3.2. Transformer 测试
hyunwoongko/transformer/test.py
import math
from collections import Counter
import numpy as np
from data import *
from models.model.transformer import Transformer
from util.bleu import get_bleu, idx_to_word
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
#
model = Transformer(src_pad_idx=src_pad_idx,
trg_pad_idx=trg_pad_idx,
trg_sos_idx=trg_sos_idx,
d_model=d_model,
enc_voc_size=enc_voc_size,
dec_voc_size=dec_voc_size,
max_len=max_len,
ffn_hidden=ffn_hidden,
n_head=n_heads,
n_layers=n_layers,
drop_prob=0.00,
device=device).to(device)
print(f'The model has {count_parameters(model):,} trainable parameters')
def test_model(num_examples):
iterator = test_iter
model.load_state_dict(torch.load("./saved/model-saved.pt"))
with torch.no_grad():
batch_bleu = []
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg[:, :-1])
total_bleu = []
for j in range(num_examples):
try:
src_words = idx_to_word(src[j], loader.source.vocab)
trg_words = idx_to_word(trg[j], loader.target.vocab)
output_words = output[j].max(dim=1)[1]
output_words = idx_to_word(output_words, loader.target.vocab)
print('source :', src_words)
print('target :', trg_words)
print('predicted :', output_words)
print()
bleu = get_bleu(hypotheses=output_words.split(), reference=trg_words.split())
total_bleu.append(bleu)
except:
pass
total_bleu = sum(total_bleu) / len(total_bleu)
print('BLEU SCORE = {}'.format(total_bleu))
batch_bleu.append(total_bleu)
batch_bleu = sum(batch_bleu) / len(batch_bleu)
print('TOTAL BLEU SCORE = {}'.format(batch_bleu))
if __name__ == '__main__':
test_model(num_examples=batch_size)