论文: Background Matting: The World is Your Green Screen - CVPR2020
Projects:Background Matting: The World is Your Green Screen
Github: senguptaumd/Background-Matting
Blog: Background Matting: The World is Your Green Screen - Medium
Background Matting 示例:

图:手持智能手机相机,拍摄同一场景的两张照片 - 一张有目标(如,人物)和一张无目标;采用对抗损失(adversarial loss) 的神经网络来重建 alpha matte 和前景(foreground);最后合并结果到新的背景(backgroud).
1. Matting 问题
Matting 是将图像分解为前景和背景的处理,以便于将前景合并到新的背景上. 这也是绿幕(green screen) 的关键技术,被广泛应用于视频生产、图形和APPs 中.
Matting 问题的建模,将图像的每个像素表示为前景和背景的组合:
$$ C = F * \alpha + B * (1 - \alpha) $$
Matting 问题的求解是,给定图像 C,计算每个像素的前景F、背景B 和透明度alpha.
由于图像有 RGB 三个通道,该公式需要基于 3 个已知量来求解 7 个未知量,问题是难以求解的.
1.1. Matting 与 Segmentation
一种可行方式是,采用分割(segmentation) 将前景从图像中分离出来. 但是,尽管分割技术近年取得了很大进步,其并没有解决 matting 公式里的问题.
分割是对图像中每个像素分配一个二值标签(0, 1),以表示背景和前景,而不是求解连续的 alpha 值.
Segmention 和 Matting 的区别可以如下图简单例示:

图:Segmentation 采用 DeepLabv3+ 得到.
图中,边缘区域,尤其是头发,是由 0-1 之间的真实 alpha 值的. 因此,分割的二值性导致前景边界周围出现严格边界,留下可见的不好效果. 解决了部分透明度和前景问题,对第二帧的合成更有利.
1.2. Matting 与背景提取
Is This Method Like Background Subtraction?
Matting 问题和另一个接近的问题是,是否和背景提取类似呢?
首先,如果使用任意背景组合这么简单,电影产业就不会每年花费大量美元投资在绿幕(green screens) 上.

图:背景提取并不能对于任意拍摄背景取得较好效果.
此外,背景提取并不能解决 alpha 值的问题,与分割一样存在相同的硬边缘问题. 且,当背景和前景比较相似、背景存在运动时,背景提取也不能很好的解决.
2. 使用任意拍摄的背景
Using A Casually Captured Background
由于 matting 是比 segmentation 更难得问题,即使是采用深度学习技术,往往需要再利用其他信息来解决 matting 无约束问题.
比如,很多算法需要采用 trimap 或手工标注的已知前景、背景和未知区域. 尽管其对于单张图片是可行的,但视频的标注是极其费时的,因此并不是视频抠图的一个可行研究方向.
而这里,采用拍摄的背景作为真实背景的一种估计. 其使得前景和 alpha 值得求解更容易. 称之为“随意拍摄(casually captured)”背景,因为其包含轻微的抖动、颜色差一、轻微阴影、或者与前景相似的颜色.

图:拍摄过程. 当目标离开场景后,再拍摄的一张背景有助于算法.

图:拍摄的输入、背景和新背景组合后的结果.
需要注意的是,这张图片是很有挑战的,因为其前景颜色和背景颜色非常相似(尤其是的头发周围). 而且,其是采用手持设备拍摄的,会包含轻微的背景抖动.

“We call it a casually captured background because it can contain slight movements, color differences, slight shadows, or similar colors as the foreground.”
2.1. 拍摄建议
尽管本文算法能够处理一定的背景干扰,但如果背景是固定的且最好是室内,其效果会更好. 例如,算法对于由于目标所导致的存在高度可见阴影、背景移动(如水流、车流、树木) 或大曝光变化的情况时,是效果不好的.

图:失败情况. 人物在移动的喷泉前面.
此外,还推荐在视频结束时,让人物离开场景;然后从连续的视频中拉出那一帧画面. 许多智能手机对于视频模式切换到照片模式时,都会有不同的变焦(zoom)和曝光(exposure)设置. 当采用手机拍摄时,也应该启用自动曝光(auto-exposure)锁定.

图:理想拍摄场景. 背景在室内、非移动、目标无阴影.
拍摄建议总结:
- [1] - 选择最固定的背景;
- [2] - 不要和背景站的太近,避免投下阴影.
- [3] - 开启手机的自动曝光(auto-exposure) 和自动对焦(auto-focus)锁定.

3. 网络细节
主要思路:进行拍照时额外拍一张对应的没有前景目标的背景图片,以辅助视频抠图.
网络包括监督学习步骤和无监督精细化(refinement).
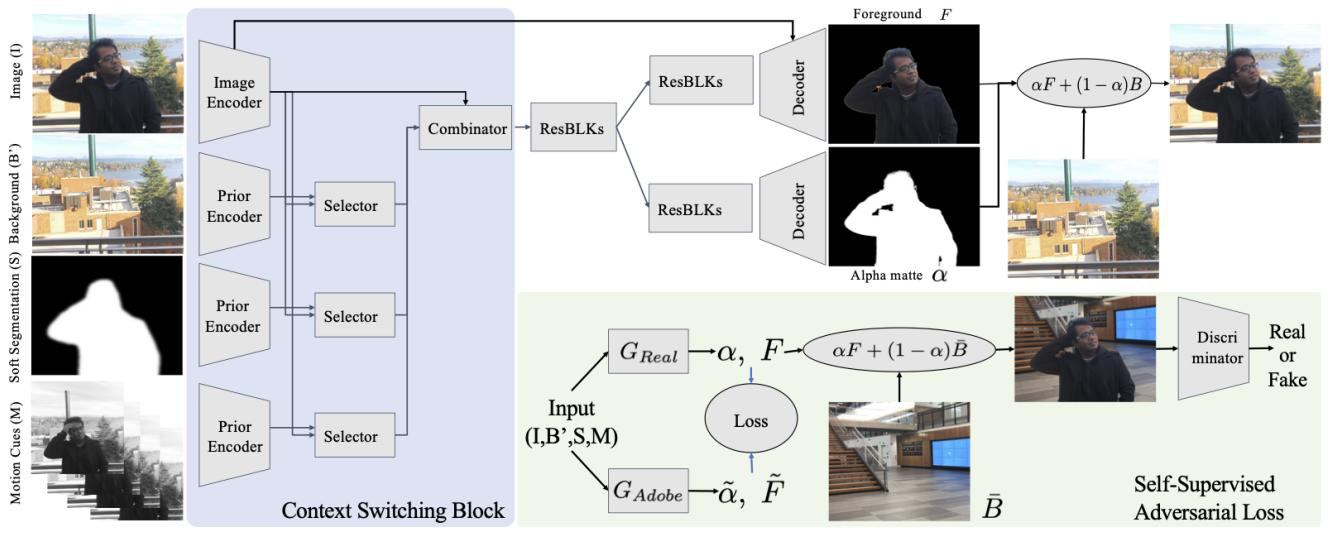
图:白底区域-监督学习网络;浅色区域-无监督学习网络.
3.1. 监督学习网络
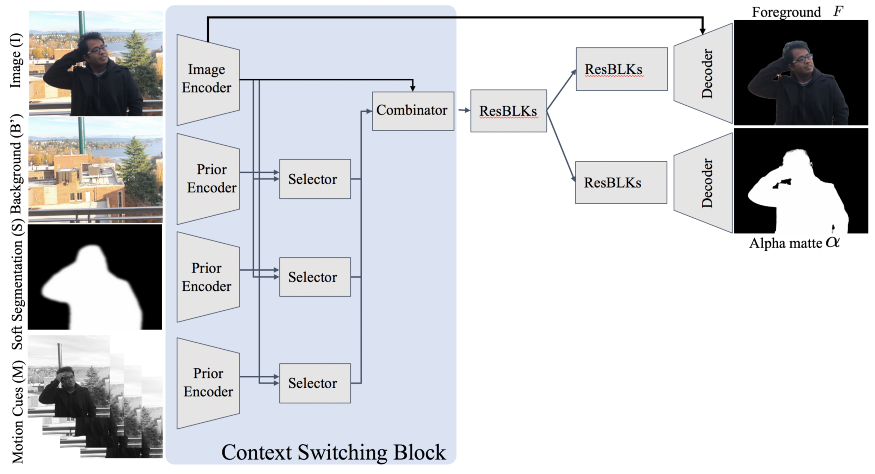
图:监督学习网络. 采用多个输入,输出 alpha matte 和预测的前景.
监督网络的训练,采用 Adobe Composition-1k 数据集,包含 450 张仔细标注 GT alpha mattes. 网络的训练采用完全监督的方式,输出层采用逐像素 loss.
网络包含多个输入:图像(I),背景(B',需要将其预处理进行对齐),软分割(S, 采用分割算法生成,如DeepLabv3+),运动线索(M,时序运动信息,当前帧的前两帧和后两帧,需要数据处理为灰度图以忽略颜色信息,专注于运动信息).
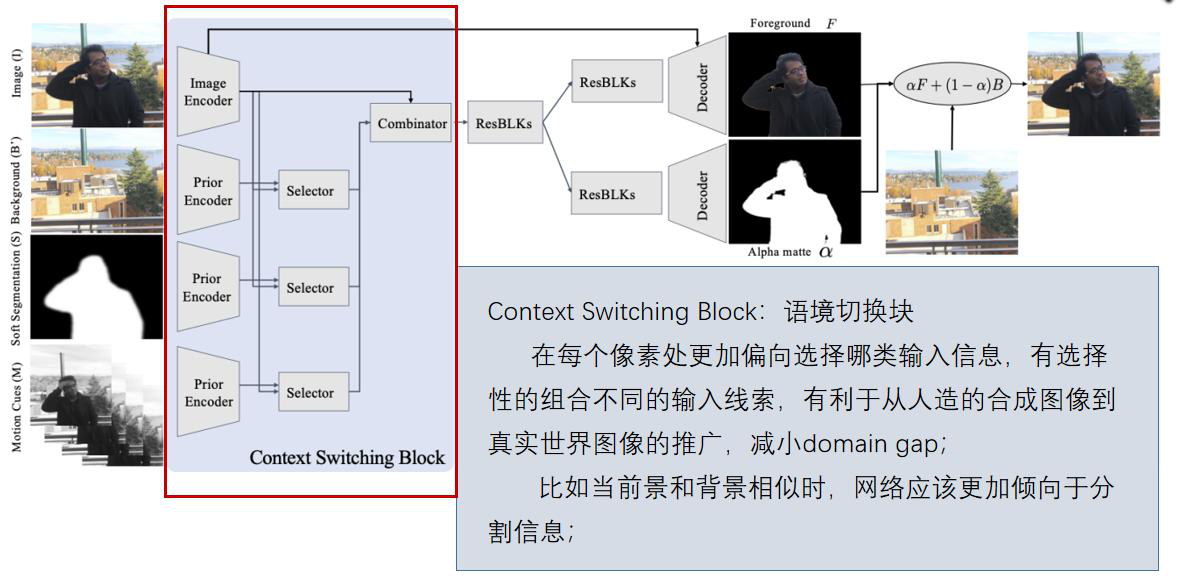
其中,提出的 Context Switching Block (对4个输入分别用编码器生成特征图;Selector块和Combinator 都由 1x1 Conv+BN+Relu组成) 对于不好的输入,仍具有鲁棒性.
From: 关于CVPR2020论文 Background Matting的一些理解
3.2. 基于 GANs 的无监督精细网络
监督学习的问题在于,adobe 数据集近包含 450 张 GT,其是不足以训练较好的网络的. 而,获取更多的数据是极其有难度的,因为需要手工标注图像的 alpha matte.
为了解决这个问题,这里采用 GAN 精细化处理. 采用监督网络所输出的 alpha matte,并将其组合到新的背景. 然后,判别网络(Discriminator) 尝试判断其是 real 或 fake 图片. 相应地,生成网络(Generator) 学习地更新 alpha matte;因此,最终的组合结果会越来越真实,以欺骗判别网络.
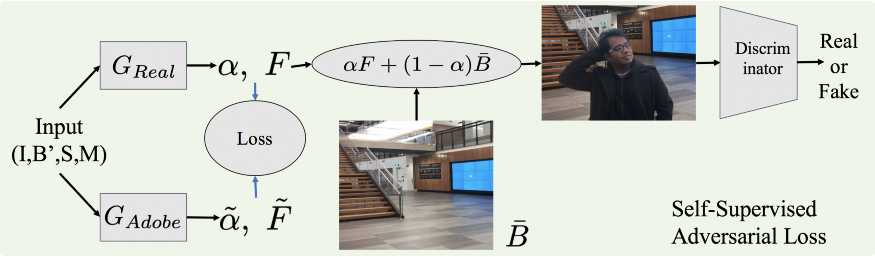
图:无监督 GAN 精细网络.
训练过程主要分为两步:
[1] - 在Adobe数据集上进行有监督的训练,得到GAdobe;
[2] - 在未标注的真实数据上进行自监督的对抗训练,得到Greal;
无监督 GAN 处理的重要性在于,其不需要任何标注的训练数据. 判别网络的训练是在很多 real 图像上进行的,也是非常容易得到的.
3.3. 图像对齐
test_pre_process.py: 采用 AKAZE 算法图像对齐.
import numpy as np
import cv2
MAX_FEATURES = 500
GOOD_MATCH_PERCENT = 0.15
def alignImages(im1, im2,masksDL):
# Convert images to grayscale
im1Gray = cv2.cvtColor(im1, cv2.COLOR_BGR2GRAY)
im2Gray = cv2.cvtColor(im2, cv2.COLOR_BGR2GRAY)
akaze = cv2.AKAZE_create()
keypoints1, descriptors1 = akaze.detectAndCompute(im1, None)
keypoints2, descriptors2 = akaze.detectAndCompute(im2, None)
# Match features.
matcher = cv2.DescriptorMatcher_create(cv2.DESCRIPTOR_MATCHER_BRUTEFORCE)
matches = matcher.match(descriptors1, descriptors2, None)
# Sort matches by score
matches.sort(key=lambda x: x.distance, reverse=False)
# Remove not so good matches
numGoodMatches = int(len(matches) * GOOD_MATCH_PERCENT)
matches = matches[:numGoodMatches]
# Extract location of good matches
points1 = np.zeros((len(matches), 2), dtype=np.float32)
points2 = np.zeros((len(matches), 2), dtype=np.float32)
for i, match in enumerate(matches):
points1[i, :] = keypoints1[match.queryIdx].pt
points2[i, :] = keypoints2[match.trainIdx].pt
# Find homography
h, mask = cv2.findHomography(points1, points2, cv2.RANSAC)
# Use homography
height, width, channels = im2.shape
im1Reg = cv2.warpPerspective(im1, h, (width, height))
# copy image in the empty region, unless it is a foreground. Then copy background
mask_rep=(np.sum(im1Reg.astype('float32'),axis=2)==0)
im1Reg[mask_rep,0]=im2[mask_rep,0]
im1Reg[mask_rep,1]=im2[mask_rep,1]
im1Reg[mask_rep,2]=im2[mask_rep,2]
mask_rep1=np.logical_and(mask_rep , masksDL[...,0]==255)
im1Reg[mask_rep1,0]=im1[mask_rep1,0]
im1Reg[mask_rep1,1]=im1[mask_rep1,1]
im1Reg[mask_rep1,2]=im1[mask_rep1,2]
return im1Reg参考材料
[1] S. Sengupta, V. Jayaram, B. Curless, S. Seitz, and I. Kemelmacher-Shlizerman, Background Matting: The World is Your Green Screen (2020), CVPR 2020
[2] L.C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (2018), ECCV 2018
[3] Y.Y. Chuang, B. Curless, D. H. Salesin, and R. Szeliski, A Bayesian Approach to Digital Matting (2001), CVPR 2001
[4] Q. Hou and F. Liu. Context-Aware Image Matting for Simultaneous Foreground and Alpha Estimation (2019), ICCV 2019
[5] H. Lu, Y. Dai, C. Shen, and S. Xu, Indices Matter: Learning to Index for Deep Image Matting (2019), ICCV 2019
5 条评论
[...]Matting – Background Matting 简单理解 – AI备忘录 (aiuai.cn)[...]
您好,我想请问一下您复现了这篇论文么?我在训练过程中遇到了一些问题
问题细节呢?
训练时提示的是cudnn error:CUDNN_STATUS_INTERNAL_ERROR,请问您训练的时候那个代码有错误需要改动嘛?还是我这边和cudnn之间的问题呢?困扰我五六天了,麻烦您了
显卡型号和cuda、cudnn版本对应吗?试试docker呢