正如论文里所给出的 BackgroundMattingV2 网络结构图如下:
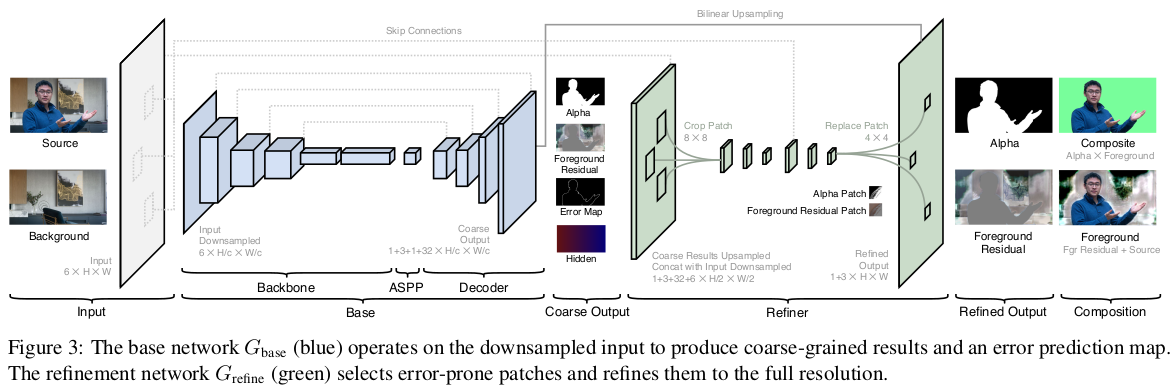
网路结构包含两个网络组成:
[1] - base 网络在将采样后的分辨率上输出粗略抠图结果;
[2] - refine 网络仅对容易出错(error-prone)的图像部分进行处理,输出全分辨率的结果. 其能够节省冗余计算量,有助于调整耗时.
1. 总体模型定义
model.py
import torch
from torch import nn
from torch.nn import functional as F
from torchvision.models.segmentation.deeplabv3 import ASPP
from .decoder import Decoder
from .mobilenet import MobileNetV2Encoder
from .refiner import Refiner
from .resnet import ResNetEncoder
from .utils import load_matched_state_dict
class Base(nn.Module):
"""
A generic implementation of the base encoder-decoder network inspired by DeepLab.
Accepts arbitrary channels for input and output.
"""
def __init__(self, backbone: str, in_channels: int, out_channels: int):
super().__init__()
#支持的 Encoder-Decoder Base 网络
assert backbone in ["resnet50", "resnet101", "mobilenetv2"]
if backbone in ['resnet50', 'resnet101']:
self.backbone = ResNetEncoder(in_channels, variant=backbone)
self.aspp = ASPP(2048, [3, 6, 9])
self.decoder = Decoder([256, 128, 64, 48, out_channels], [512, 256, 64, in_channels])
else:
self.backbone = MobileNetV2Encoder(in_channels)
self.aspp = ASPP(320, [3, 6, 9])
self.decoder = Decoder([256, 128, 64, 48, out_channels], [32, 24, 16, in_channels])
def forward(self, x):
x, *shortcuts = self.backbone(x)
x = self.aspp(x)
x = self.decoder(x, *shortcuts)
return x
def load_pretrained_deeplabv3_state_dict(self, state_dict, print_stats=True):
# Pretrained DeepLabV3 models are provided by <https://github.com/VainF/DeepLabV3Plus-Pytorch>.
# This method converts and loads their pretrained state_dict to match with our model structure.
# This method is not needed if you are not planning to train from deeplab weights.
# Use load_state_dict() for normal weight loading.
# Convert state_dict naming for aspp module
state_dict = {k.replace('classifier.classifier.0', 'aspp'): v for k, v in state_dict.items()}
if isinstance(self.backbone, ResNetEncoder):
# ResNet backbone does not need change.
load_matched_state_dict(self, state_dict, print_stats)
else:
# Change MobileNetV2 backbone to state_dict format, then change back after loading.
backbone_features = self.backbone.features
self.backbone.low_level_features = backbone_features[:4]
self.backbone.high_level_features = backbone_features[4:]
del self.backbone.features
#
load_matched_state_dict(self, state_dict, print_stats)
self.backbone.features = backbone_features
del self.backbone.low_level_features
del self.backbone.high_level_features
#网络结构中的 Base 网络
class MattingBase(Base):
"""
MattingBase is used to produce coarse global results at a lower resolution.
MattingBase extends Base.
Args:
backbone: ["resnet50", "resnet101", "mobilenetv2"]
Input:
src: (B, 3, H, W) the source image. Channels are RGB values normalized to 0 ~ 1.
bgr: (B, 3, H, W) the background image . Channels are RGB values normalized to 0 ~ 1.
Output:
pha: (B, 1, H, W) the alpha prediction. Normalized to 0 ~ 1.
fgr: (B, 3, H, W) the foreground prediction. Channels are RGB values normalized to 0 ~ 1.
err: (B, 1, H, W) the error prediction. Normalized to 0 ~ 1.
hid: (B, 32, H, W) the hidden encoding. Used for connecting refiner module.
Example:
model = MattingBase(backbone='resnet50')
pha, fgr, err, hid = model(src, bgr) # for training
pha, fgr = model(src, bgr)[:2] # for inference
"""
def __init__(self, backbone: str):
super().__init__(backbone, in_channels=6, out_channels=(1 + 3 + 1 + 32))
def forward(self, src, bgr):
x = torch.cat([src, bgr], dim=1)
x, *shortcuts = self.backbone(x)
x = self.aspp(x)
x = self.decoder(x, *shortcuts)
pha = x[:, 0:1].clamp_(0., 1.)
fgr = x[:, 1:4].add(src).clamp_(0., 1.)
err = x[:, 4:5].clamp_(0., 1.)
hid = x[:, 5: ].relu_()
return pha, fgr, err, hid
#网络结构中 Refine 网络
class MattingRefine(MattingBase):
"""
MattingRefine includes the refiner module to upsample coarse result to full resolution.
MattingRefine extends MattingBase.
Args:
backbone: ["resnet50", "resnet101", "mobilenetv2"]
backbone_scale: The image downsample scale for passing through backbone, default 1/4 or 0.25.
Must not be greater than 1/2.
如 1920x1080 分辨率降低到 480x270.
refine_mode: refine area selection mode. Options:
"full" - No area selection, refine everywhere using regular Conv2d.
"sampling" - Refine fixed amount of pixels ranked by the top most errors.
"thresholding" - Refine varying amount of pixels that has more error than the threshold.
refine_sample_pixels: number of pixels to refine. Only used when mode == "sampling".
refine_threshold: error threshold ranged from 0 ~ 1. Refine where err > threshold. Only used when mode == "thresholding".
refine_kernel_size: the refiner's convolutional kernel size. Options: [1, 3]
refine_prevent_oversampling: prevent sampling more pixels than needed for sampling mode. Set False only for speedtest.
Input:
src: (B, 3, H, W) the source image. Channels are RGB values normalized to 0 ~ 1.
bgr: (B, 3, H, W) the background image. Channels are RGB values normalized to 0 ~ 1.
Output:
pha: (B, 1, H, W) the alpha prediction. Normalized to 0 ~ 1.
fgr: (B, 3, H, W) the foreground prediction. Channels are RGB values normalized to 0 ~ 1.
pha_sm: (B, 1, Hc, Wc) the coarse alpha prediction from matting base. Normalized to 0 ~ 1.
fgr_sm: (B, 3, Hc, Hc) the coarse foreground prediction from matting base. Normalized to 0 ~ 1.
err_sm: (B, 1, Hc, Wc) the coarse error prediction from matting base. Normalized to 0 ~ 1.
ref_sm: (B, 1, H/4, H/4) the quarter resolution refinement map. 1 indicates refined 4x4 patch locations.
Example:
model = MattingRefine(backbone='resnet50', backbone_scale=1/4, refine_mode='sampling', refine_sample_pixels=80_000)
model = MattingRefine(backbone='resnet50', backbone_scale=1/4, refine_mode='thresholding', refine_threshold=0.1)
model = MattingRefine(backbone='resnet50', backbone_scale=1/4, refine_mode='full')
pha, fgr, pha_sm, fgr_sm, err_sm, ref_sm = model(src, bgr) # for training
pha, fgr = model(src, bgr)[:2] # for inference
"""
def __init__(self,
backbone: str,
backbone_scale: float = 1/4,
refine_mode: str = 'sampling',
refine_sample_pixels: int = 80_000,
refine_threshold: float = 0.1,
refine_kernel_size: int = 3,
refine_prevent_oversampling: bool = True,
refine_patch_crop_method: str = 'unfold',
refine_patch_replace_method: str = 'scatter_nd'):
assert backbone_scale <= 1/2, 'backbone_scale should not be greater than 1/2'
super().__init__(backbone)
self.backbone_scale = backbone_scale
self.refiner = Refiner(refine_mode,
refine_sample_pixels,
refine_threshold,
refine_kernel_size,
refine_prevent_oversampling,
refine_patch_crop_method,
refine_patch_replace_method)
def forward(self, src, bgr):
assert src.size() == bgr.size(), 'src and bgr must have the same shape'
assert src.size(2) // 4 * 4 == src.size(2) and src.size(3) // 4 * 4 == src.size(3), \
'src and bgr must have width and height that are divisible by 4'
# Downsample src and bgr for backbone
src_sm = F.interpolate(src,
scale_factor=self.backbone_scale,
mode='bilinear',
align_corners=False,
recompute_scale_factor=True)
bgr_sm = F.interpolate(bgr,
scale_factor=self.backbone_scale,
mode='bilinear',
align_corners=False,
recompute_scale_factor=True)
# Base
x = torch.cat([src_sm, bgr_sm], dim=1)
x, *shortcuts = self.backbone(x)
x = self.aspp(x)
x = self.decoder(x, *shortcuts)
pha_sm = x[:, 0:1].clamp_(0., 1.)
fgr_sm = x[:, 1:4]
err_sm = x[:, 4:5].clamp_(0., 1.)
hid_sm = x[:, 5: ].relu_()
# Refiner
pha, fgr, ref_sm = self.refiner(src, bgr, pha_sm, fgr_sm, err_sm, hid_sm)
# Clamp outputs
pha = pha.clamp_(0., 1.)
fgr = fgr.add_(src).clamp_(0., 1.)
fgr_sm = src_sm.add_(fgr_sm).clamp_(0., 1.)
return pha, fgr, pha_sm, fgr_sm, err_sm, ref_sm2. Base 网络之 Encoder
Encoder 支持三种:ResNet50、ResNet101、MobileNetV2.
2.1. resnet
resnet.py
from torch import nn
from torchvision.models.resnet import ResNet, Bottleneck
class ResNetEncoder(ResNet):
"""
ResNetEncoder inherits from torchvision's official ResNet.
It is modified to use dilation on the last block to
maintain output stride 16, and deleted the
global average pooling layer and the fully connected layer that was originally
used for classification. The forward method additionally returns the feature
maps at all resolutions for decoder's use.
"""
layers = {
'resnet50': [3, 4, 6, 3],
'resnet101': [3, 4, 23, 3],
}
def __init__(self, in_channels, variant='resnet101', norm_layer=None):
super().__init__(
block=Bottleneck,
layers=self.layers[variant],
replace_stride_with_dilation=[False, False, True],
norm_layer=norm_layer)
# Replace first conv layer if in_channels doesn't match.
if in_channels != 3:
self.conv1 = nn.Conv2d(in_channels, 64, 7, 2, 3, bias=False)
# Delete fully-connected layer
del self.avgpool
del self.fc
def forward(self, x):
x0 = x # 1/1
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x1 = x # 1/2
x = self.maxpool(x)
x = self.layer1(x)
x2 = x # 1/4
x = self.layer2(x)
x3 = x # 1/8
x = self.layer3(x)
x = self.layer4(x)
x4 = x # 1/16
return x4, x3, x2, x1, x02.2. mobilenet
mobilenet.py
from torch import nn
from torchvision.models import MobileNetV2
class MobileNetV2Encoder(MobileNetV2):
"""
MobileNetV2Encoder inherits from torchvision's official MobileNetV2.
It is modified to use dilation on the last block to
maintain output stride 16, and deleted the
classifier block that was originally used for classification. The forward method
additionally returns the feature maps at all resolutions for decoder's use.
"""
def __init__(self, in_channels, norm_layer=None):
super().__init__()
# Replace first conv layer if in_channels doesn't match.
if in_channels != 3:
self.features[0][0] = nn.Conv2d(in_channels, 32, 3, 2, 1, bias=False)
# Remove last block
self.features = self.features[:-1]
# Change to use dilation to maintain output stride = 16
self.features[14].conv[1][0].stride = (1, 1)
for feature in self.features[15:]:
feature.conv[1][0].dilation = (2, 2)
feature.conv[1][0].padding = (2, 2)
# Delete classifier
del self.classifier
def forward(self, x):
x0 = x # 1/1
x = self.features[0](x)
x = self.features[1](x)
x1 = x # 1/2
x = self.features[2](x)
x = self.features[3](x)
x2 = x # 1/4
x = self.features[4](x)
x = self.features[5](x)
x = self.features[6](x)
x3 = x # 1/8
x = self.features[7](x)
x = self.features[8](x)
x = self.features[9](x)
x = self.features[10](x)
x = self.features[11](x)
x = self.features[12](x)
x = self.features[13](x)
x = self.features[14](x)
x = self.features[15](x)
x = self.features[16](x)
x = self.features[17](x)
x4 = x # 1/16
return x4, x3, x2, x1, x03. Base 网络之 Decoder
decoder.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class Decoder(nn.Module):
"""
Decoder upsamples the image by combining the feature maps at all resolutions from the encoder.
Input:
x4: (B, C, H/16, W/16) feature map at 1/16 resolution.
x3: (B, C, H/8, W/8) feature map at 1/8 resolution.
x2: (B, C, H/4, W/4) feature map at 1/4 resolution.
x1: (B, C, H/2, W/2) feature map at 1/2 resolution.
x0: (B, C, H, W) feature map at full resolution.
Output:
x: (B, C, H, W) upsampled output at full resolution.
"""
def __init__(self, channels, feature_channels):
super().__init__()
self.conv1 = nn.Conv2d(feature_channels[0] + channels[0], channels[1], 3, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(channels[1])
self.conv2 = nn.Conv2d(feature_channels[1] + channels[1], channels[2], 3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(channels[2])
self.conv3 = nn.Conv2d(feature_channels[2] + channels[2], channels[3], 3, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(channels[3])
self.conv4 = nn.Conv2d(feature_channels[3] + channels[3], channels[4], 3, padding=1)
self.relu = nn.ReLU(True)
def forward(self, x4, x3, x2, x1, x0):
x = F.interpolate(x4, size=x3.shape[2:], mode='bilinear', align_corners=False)
x = torch.cat([x, x3], dim=1)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = F.interpolate(x, size=x2.shape[2:], mode='bilinear', align_corners=False)
x = torch.cat([x, x2], dim=1)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = F.interpolate(x, size=x1.shape[2:], mode='bilinear', align_corners=False)
x = torch.cat([x, x1], dim=1)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
x = F.interpolate(x, size=x0.shape[2:], mode='bilinear', align_corners=False)
x = torch.cat([x, x0], dim=1)
x = self.conv4(x)
return x4. Refine 网络
refiner.py
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from typing import Tuple
class Refiner(nn.Module):
"""
Refiner refines the coarse output to full resolution.
Args:
mode: area selection mode. Options:
"full" - No area selection, refine everywhere using regular Conv2d.
"sampling" - Refine fixed amount of pixels ranked by the top most errors.
"thresholding" - Refine varying amount of pixels that have greater error than the threshold.
sample_pixels: number of pixels to refine. Only used when mode == "sampling".
threshold: error threshold ranged from 0 ~ 1. Refine where err > threshold. Only used when mode == "thresholding".
kernel_size: The convolution kernel_size. Options: [1, 3]
prevent_oversampling: True for regular cases, False for speedtest.
Compatibility Args:
patch_crop_method: the operation for cropping patches. Options:
"unfold" - Best performance for PyTorch and TorchScript.
"roi_align" - Best compatibility for ONNX export.
patch_replace_method: the operation for replacing patches. Options:
"scatter_nd" - Best performance for PyTorch and TorchScript.
"scatter_element" - Best compatibility for ONNX export.
Input:
src: (B, 3, H, W) full resolution source image.
bgr: (B, 3, H, W) full resolution background image.
pha: (B, 1, Hc, Wc) coarse alpha prediction.
fgr: (B, 3, Hc, Wc) coarse foreground residual prediction.
err: (B, 1, Hc, Hc) coarse error prediction.
hid: (B, 32, Hc, Hc) coarse hidden encoding.
Output:
pha: (B, 1, H, W) full resolution alpha prediction.
fgr: (B, 3, H, W) full resolution foreground residual prediction.
ref: (B, 1, H/4, W/4) quarter resolution refinement selection map. 1 indicates refined 4x4 patch locations.
"""
# For TorchScript export optimization.
__constants__ = ['kernel_size', 'patch_crop_method', 'patch_replace_method']
def __init__(self,
mode: str,
sample_pixels: int,
threshold: float,
kernel_size: int = 3,
prevent_oversampling: bool = True,
patch_crop_method: str = 'unfold',
patch_replace_method: str = 'scatter_nd'):
super().__init__()
assert mode in ['full', 'sampling', 'thresholding']
assert kernel_size in [1, 3]
assert patch_crop_method in ['unfold', 'roi_align']
assert patch_replace_method in ['scatter_nd', 'scatter_element']
self.mode = mode
self.sample_pixels = sample_pixels
self.threshold = threshold
self.kernel_size = kernel_size
self.prevent_oversampling = prevent_oversampling
self.patch_crop_method = patch_crop_method
self.patch_replace_method = patch_replace_method
channels = [32, 24, 16, 12, 4]
self.conv1 = nn.Conv2d(channels[0] + 6 + 4, channels[1], kernel_size, bias=False)
self.bn1 = nn.BatchNorm2d(channels[1])
self.conv2 = nn.Conv2d(channels[1], channels[2], kernel_size, bias=False)
self.bn2 = nn.BatchNorm2d(channels[2])
self.conv3 = nn.Conv2d(channels[2] + 6, channels[3], kernel_size, bias=False)
self.bn3 = nn.BatchNorm2d(channels[3])
self.conv4 = nn.Conv2d(channels[3], channels[4], kernel_size, bias=True)
self.relu = nn.ReLU(True)
def forward(self,
src: torch.Tensor,
bgr: torch.Tensor,
pha: torch.Tensor,
fgr: torch.Tensor,
err: torch.Tensor,
hid: torch.Tensor):
H_full, W_full = src.shape[2:]
H_half, W_half = H_full // 2, W_full // 2
H_quat, W_quat = H_full // 4, W_full // 4
src_bgr = torch.cat([src, bgr], dim=1)
if self.mode != 'full':
err = F.interpolate(err, (H_quat, W_quat), mode='bilinear', align_corners=False)
ref = self.select_refinement_regions(err)
idx = torch.nonzero(ref.squeeze(1))
idx = idx[:, 0], idx[:, 1], idx[:, 2]
if idx[0].size(0) > 0:
x = torch.cat([hid, pha, fgr], dim=1)
x = F.interpolate(x, (H_half, W_half), mode='bilinear', align_corners=False)
x = self.crop_patch(x, idx, 2, 3 if self.kernel_size == 3 else 0)
y = F.interpolate(src_bgr, (H_half, W_half), mode='bilinear', align_corners=False)
y = self.crop_patch(y, idx, 2, 3 if self.kernel_size == 3 else 0)
x = self.conv1(torch.cat([x, y], dim=1))
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = F.interpolate(x, 8 if self.kernel_size == 3 else 4, mode='nearest')
y = self.crop_patch(src_bgr, idx, 4, 2 if self.kernel_size == 3 else 0)
x = self.conv3(torch.cat([x, y], dim=1))
x = self.bn3(x)
x = self.relu(x)
x = self.conv4(x)
out = torch.cat([pha, fgr], dim=1)
out = F.interpolate(out, (H_full, W_full), mode='bilinear', align_corners=False)
out = self.replace_patch(out, x, idx)
pha = out[:, :1]
fgr = out[:, 1:]
else:
pha = F.interpolate(pha, (H_full, W_full), mode='bilinear', align_corners=False)
fgr = F.interpolate(fgr, (H_full, W_full), mode='bilinear', align_corners=False)
else:
x = torch.cat([hid, pha, fgr], dim=1)
x = F.interpolate(x, (H_half, W_half), mode='bilinear', align_corners=False)
y = F.interpolate(src_bgr, (H_half, W_half), mode='bilinear', align_corners=False)
if self.kernel_size == 3:
x = F.pad(x, (3, 3, 3, 3))
y = F.pad(y, (3, 3, 3, 3))
x = self.conv1(torch.cat([x, y], dim=1))
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
if self.kernel_size == 3:
x = F.interpolate(x, (H_full + 4, W_full + 4))
y = F.pad(src_bgr, (2, 2, 2, 2))
else:
x = F.interpolate(x, (H_full, W_full), mode='nearest')
y = src_bgr
x = self.conv3(torch.cat([x, y], dim=1))
x = self.bn3(x)
x = self.relu(x)
x = self.conv4(x)
pha = x[:, :1]
fgr = x[:, 1:]
ref = torch.ones((src.size(0), 1, H_quat, W_quat), device=src.device, dtype=src.dtype)
return pha, fgr, ref
def crop_patch(self,
x: torch.Tensor,
idx: Tuple[torch.Tensor, torch.Tensor, torch.Tensor],
size: int,
padding: int):
"""
Crops selected patches from image given indices.
Inputs:
x: image (B, C, H, W).
idx: selection indices Tuple[(P,), (P,), (P),], where the 3 values are (B, H, W) index.
size: center size of the patch, also stride of the crop.
padding: expansion size of the patch.
Output:
patch: (P, C, h, w), where h = w = size + 2 * padding.
"""
if padding != 0:
x = F.pad(x, (padding,) * 4)
if self.patch_crop_method == 'unfold':
# Use unfold. Best performance for PyTorch and TorchScript.
return x.permute(0, 2, 3, 1) \
.unfold(1, size + 2 * padding, size) \
.unfold(2, size + 2 * padding, size)[idx[0], idx[1], idx[2]]
else:
# Use roi_align. Best compatibility for ONNX.
idx = idx[0].type_as(x), idx[1].type_as(x), idx[2].type_as(x)
b = idx[0]
x1 = idx[2] * size - 0.5
y1 = idx[1] * size - 0.5
x2 = idx[2] * size + size + 2 * padding - 0.5
y2 = idx[1] * size + size + 2 * padding - 0.5
boxes = torch.stack([b, x1, y1, x2, y2], dim=1)
return torchvision.ops.roi_align(x, boxes, size + 2 * padding, sampling_ratio=1)
def replace_patch(self,
x: torch.Tensor,
y: torch.Tensor,
idx: Tuple[torch.Tensor, torch.Tensor, torch.Tensor]):
"""
Replaces patches back into image given index.
Inputs:
x: image (B, C, H, W)
y: patches (P, C, h, w)
idx: selection indices Tuple[(P,), (P,), (P,)] where the 3 values are (B, H, W) index.
Output:
image: (B, C, H, W), where patches at idx locations are replaced with y.
"""
xB, xC, xH, xW = x.shape
yB, yC, yH, yW = y.shape
if self.patch_replace_method == 'scatter_nd':
# Use scatter_nd. Best performance for PyTorch and TorchScript. Replacing patch by patch.
x = x.view(xB, xC, xH // yH, yH, xW // yW, yW).permute(0, 2, 4, 1, 3, 5)
x[idx[0], idx[1], idx[2]] = y
x = x.permute(0, 3, 1, 4, 2, 5).view(xB, xC, xH, xW)
return x
else:
# Use scatter_element. Best compatibility for ONNX. Replacing pixel by pixel.
iH, iW = xH // yH, xW // yW
i = self.crop_patch(torch.arange(0, xB * xC * xH * xW).view(xB, xC, xH, xW).type_as(x), idx, 4, 0)
i, x, y = i.view(-1), x.view(-1), y.view(-1)
x.scatter_(0, i.long(), y)
x = x.view(xB, xC, xH, xW)
return x
def select_refinement_regions(self, err: torch.Tensor):
"""
Select refinement regions.
Input:
err: error map (B, 1, H, W)
Output:
ref: refinement regions (B, 1, H, W). FloatTensor. 1 is selected, 0 is not.
"""
if self.mode == 'sampling':
# Sampling mode.
b, _, h, w = err.shape
err = err.view(b, -1)
idx = err.topk(self.sample_pixels // 16, dim=1, sorted=False).indices
ref = torch.zeros_like(err)
ref.scatter_(1, idx, 1.)
if self.prevent_oversampling:
ref.mul_(err.gt(0).float())
ref = ref.view(b, 1, h, w)
else:
# Thresholding mode.
ref = err.gt(self.threshold).float()
return ref5. load_matched_state_dict
def load_matched_state_dict(model, state_dict, print_stats=True):
"""
Only loads weights that matched in key and shape. Ignore other weights.
仅加载 key 和 shape 一致的权重参数,其余的忽略.
"""
num_matched, num_total = 0, 0
curr_state_dict = model.state_dict()
for key in curr_state_dict.keys():
num_total += 1
if key in state_dict and curr_state_dict[key].shape == state_dict[key].shape:
curr_state_dict[key] = state_dict[key]
num_matched += 1
model.load_state_dict(curr_state_dict)
if print_stats:
print(f'Loaded state_dict: {num_matched}/{num_total} matched')