论文:Real-Time High-Resolution Background Matting
作者:Shanchuan Lin Andrey Ryabtsev Soumyadip Sengupta
团队:cs.washington.edu
Homepage - Real-Time High Resolution Background Matting
Github - PeterL1n/BackgroundMattingV2
针对视频背景抠图,该论文的几个着重点:
[1] - 实时且高分辨率, 在 GPU 上,4K 分辨率(3840x2160) 30fps; HD 分辨率(1920x1080) 60 fps.
[2] - 基于背景抠图(background matting),其需要单独捕捉一帧背景图,以用于重建 alpha matte 和前景层.
[3] - 最关键的挑战是,高分辨率 alpha matte 的计算,在实时处理高分辨率图像的同时,保持发丝级细节.
[4] - 采用两个神经网络,base 网络计算低分辨率结果; refine 网络对高分辨率图像所选择的图片块( selective patches) 上进一步处理.
[5] - 两个视频和图像抠图数据集:VideoMatte240K 和 PhotoMatte 13K/85.
1. 抠图数据集
获取大量、高分辨率、高质量的、由人工标注的抠图数据集是非常难的.
1.1. 公开数据集
Adobe Deep Image Matting 数据集提供了 269 张人物训练样本和 11 张测试图像,分辨率平均为 1000x1000.
Attention-Guided Hierarchical Structure Aggregation for Image Matting 中362 张人物相关的训练样本和 11 张测试样本,分辨率平均为 1700x2000.
以上两个数据集共 631 张训练样本,是远远不够的.
1.2. VideoMatte240K
VideoMatte240K 中采集了 484 段高分辨率绿幕(green screen) 视频,并采用色度键抠图(Chroma-key)软件 Adobe After Effects 生成了 240709 张 alpha mattes 和 foregrounds 的视频帧.
其中,384 段视频的分辨率为 4K, 100 段视频的分辨率为 HD. 根据 479:5 的比例将视频划分为 tran 和 validataion 数据集.
如图:

1.3. PhotoMatte13K/85
PhotoMatte13K/85 中采集了 13665 张图像集合,这些图像是采用摄影棚质量的光照,在绿幕前的相机所拍摄的,并采用色度键抠图算法(Chroma-key) 和手工调整以及错误修正所提取的 mattes.
根据 13165:500 的比例划分为 train 和 validation 数据集.
数据集图像分辨率平均为 2000x2500,包括了一些头发.

2. 算法细节
给定图像 I 以及捕捉的背景 B, 算法会预测输出 alpha matte $\alpha$ 和前景 F, 基于如下公式,其可以被任何背景来组合,
$$ I' = \alpha F + (1 - \alpha) B' $$
其中,$B'$ 为新背景.
相比于直接求解前景,这里求解的是前景残差 $F^{R} = F - I$. 因此,F 可以通过添加适当的约束将 $F^R$ 和输入图像 I 相加:
$$ F = max(min( F^{R} + I, 1), 0) $$
高分辨率抠图是很有挑战的,因为直接进行深度网络计算,其计算量和内存消耗是不切实际的. 如图所示:

人物 mattes 往往是非常稀疏的,大面积的像素要么是背景($\alpha=0$),要么是前景($\alpha = 1$),仅有少量的区域包含更多的细节,如头发、眼镜、人物轮廓等周围.
对此,相比于设计直接在高分辨率图像直接操作的一个网络,这里采用了两个网络:
[1] - base 网络 $G_{base}$ - 对低分辨率图像进行处理;
[2] - refinement 网络 $G_{refine}$ - 基于低分辨率预测结果,从原始图像分辨率选择特定图像块进行处理.
网络结构如图:
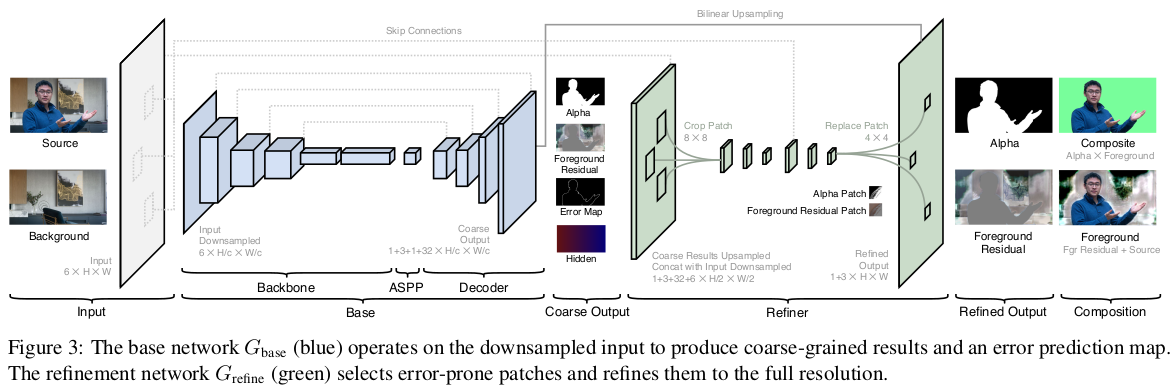
给定原始输入图像 I 和捕捉的背景图 B,首先采用缩放因子 $c$ 进行将采样到 $I_c$ 和 $B_c$.
$G_{base}$ 采用 $I_c$ 和 $B_c$ 作为输入,并预测输出粗略的 alpha matte $\alpha_c$、foreground residual $F_c^R$、error prediction map $E_c$ 以及 hidden feature $H_c$.
$G_{refine}$ 采用 $H_c$、I 和 B 仅对 $E_c$ 比较大的区域,进一步的精细化 $\alpha_c$ 和 $F_c^R$,并在原始分辨率输出 alpha $\alpha$ 和 $F^R$.
网络模型是全卷积的,且能在任意尺寸和长宽比(aspect ratios) 上进行训练.
2.1. Base 网络
Base 网络受到 DeepLabV3 和 DeepLabV3+ 结构的启发,设计为全卷积的 encoder-decoder 网络,其中主要包括三个模块:Backbone, ASPP,Decoder.
[1] - Backbone
采用 ResNet50 作为 encoder backbone,其也可以采用 ResNet101 和 MobileNetV2,以平衡速度和精度.
[2] - ASPP
类似于 DeepLabV3,在 backbone 网络后接 ASPP(Atrous Spatial Pyramid Pooling) 模块.
ASPP 模块由多个不同 dilation rates 为 3, 6, 9 的 dialted conv filters 组成.
[3] - Decoder
Decoder 网络的每一步采用双线性上采样(bilinear upsampling),并通过 skip connection 从 backbone 进行连接,其后接一个 3x3 conv, Batch Normalization 和 ReLU(最后一层例外).
Decoder 网络输出粗略的 alpha matte $\alpha _c$,foreground residual $F_c^R$,error prediction map $E_c$ 和 32 通道 hidden features $H_c$. $H_c$ 包含了有用于 refinement 网络的全局内容信息.
2.2. Refinement 网络
Refinement 网络的目标是,降低冗余计算量,并重建高分辨率抠图细节.
Base 网络是对整张图像进行处理,而 Refinement 网络仅对基于 error prediction map $E_c$ 所选择的图像块进行处理.
Refinement 网络是 two-stage 的,分别处理原始分辨率的二分之一和全分辨率.
在推断时,精细化 k 个图像块,k 是提前设定的,或着是根据抠图质量和计算量平衡的阈值计算来设定的.
给定在原始分辨率的 $\frac{1}{c}$ 时的 error prediction map $E_c$,首先将其重采样为原始分辨率的 $\frac{1}{4}$,记 $E_4$,其每个像素对应于原始图像分辨率的一个 4x4 图像块. 然后,从 $E_4$ 中选取前 k 个最高的 predicted error 的像素,以表示 k 个 4x4 图像块位置,用于 refinement 模块进一步精细化处理. 原始分辨率的 refined 像素总数是 16k.
Refinement 是 two-stage 的,
[1] - 首先,双线性重采样粗略的输出,如 alpha matte $\alpha_c$、foreground residual $F_c^R$、hidden features $H_c$、输入图像 I和背景图像的分辨率重采样为原始分辨率的 $\frac{1}{2}$,并将这些链接作为特征.
[2] - 然后,在 $E_4$ 中选择出的 error 位置的周围裁剪出多个 8x8 图像块,并将其分别送入两个 valid padding 的 3x3 conv 层、BN 层和 ReLU 层,以将图像块的分辨率降低为 4x4.
接着,这些中间特征再一次被上采样到 8x8,并与从原始分辨率输入 I 和 B 中所提取的 8x8 图像块拼接在一起.
其后,再采用一个两个 valid padding 的 3x3 conv 层、BN 层和 ReLU 层(最后一层除外)处理,得到 4x4 alpha matte 和 foreground residuals 结果.
最后,上采样粗略的 alpha matte $\alpha_c$、foreground residual $F_c^R$ 到原始分辨率,并交换被 refine 后的 4x4 图像块,以得到最终的 alpha matte $\alpha$ 和 foreground residual $F^R$.
2.3. Loss 函数
关于 GT $\alpha^*$ 和 $\alpha$ ,采用 L1 loss 计算整个 alpha matte 和对应的 Sobel 梯度损失函数:
$$ L_{\alpha} = ||\alpha - \alpha^*||_1 + ||\nabla \alpha - \nabla \alpha^*||_1 $$
根据预测的 foreground residual $F^R$ 以及如下计算公式,得到前景层:
$$ F = max(min(F^R + I, 1), 0) $$
仅对 $\alpha^* > 0$ 的像素区域计算 L1 loss:
$$ L_F = ||(\alpha^* > 0) * (F - F^*)||_1 $$
其中,$\alpha^* > 0$ 为布尔表达式.
对于 refinement 区域选择,首先定义 ground truth error map 为:
$$ E^* = |\alpha - \alpha^*| $$
然后,计算预测的 error map 和 ground truth error map 间的均方误差:
$$ L_E = ||E - E^*||_2 $$
Base 网络:
$$ (\alpha_c, F_c^R, E_c, H_c) = G_{base}(I_c, B_c) $$
对原始图像分辨率的 $\frac{1}{c}$ 进行处理,其训练的损失函数如下:
$$ L_{base} = L_{\alpha_c} + L_{F_C} + L_{E_c} $$
Refinement 网络:
$$ (\alpha, F^R) = G_{refine}(\alpha_c, F_{c}^R, E_c, H_c, I, B) $$
其训练的损失函数如下:
$$ L_{refine} = L_{\alpha} + L_{F} $$
2.4. 训练
抠图数据集提供了 alpha matte 和 foreground 层,其可以组合到多种高分辨率背景上.
数据增强:仿射变换(affine transformation)、水平翻转(horizontal flipping)、光照色调饱和度调整(brightness, hue, and saturation adjustment)、模糊(blurring)、锐化(sharpening)、随机噪声(random noise) 等,分别对前景层和背景层进行处理.
此外,轻微平移背景以模拟不对齐; 生成阴影效果,以模拟真实环境的效果.
如:

每个 minibatch 随机裁剪图像,以使得 height 和 width 是在 [1024, 2048] 区间的均匀分布,便于支持推断时支持任意分辨率和长宽比.
模型训练次序:
[1] - 首先,仅训练 base 网络 $G_{base}$; 在数据集 VideoMatte240K 上,联合训练整个模型 $G_{base}$ 和 $G_{refine}$ ;
[2] - 然后,在数据集 PhotoMatte 13K 联合训练模型,以提升高分辨率细节.
[3] - 最后,在公开数据集(646 张训练数据)上联合训练模型.
3. Results
抠图效果对比如图:



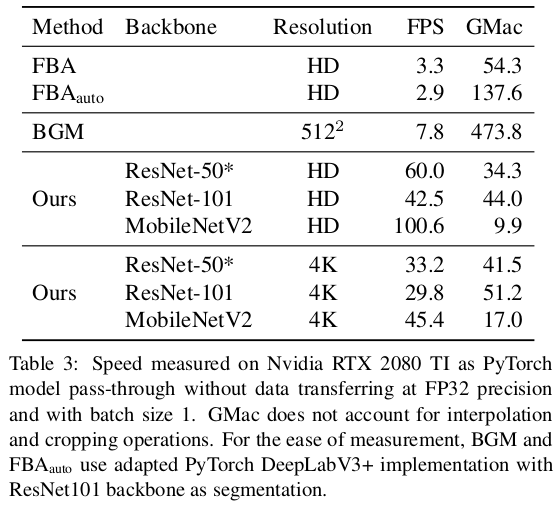
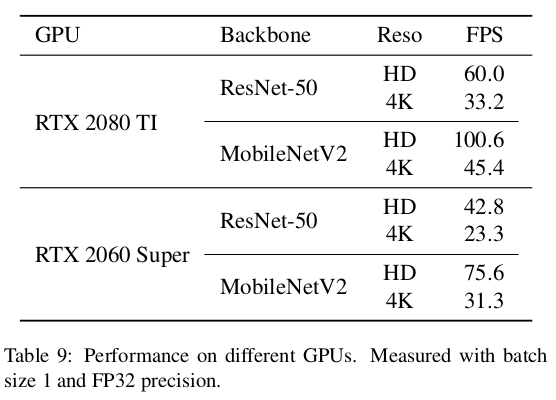
抠图速率对比:(NVIDIA RTX 2080Ti GPU)
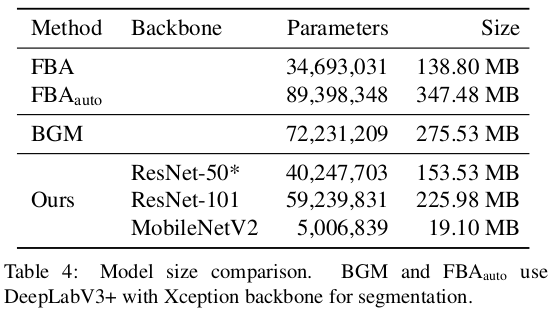
模型参数及大小对比: