[原文-Background removal with deep learning]
基于深度学习的图像背景移除
主要是介绍 greenScreen.AI 中所涉及的工作.
1. Intro
深度学习技术的发展为很多以往难以实现解决的问题提供了可能性方案.
给自己设定的目标:
- 提升深度学习技巧
- 提高AI产品的部署水平
- 设计一种具有市场需求的产品
- Have Fun
- 经验分享
针对以上目标,这里考虑了一下几个方面:
- 还未做的(或还没有合理解决的)问题
- 实施难度不是太大的问题
- 能够有简单且吸引人的用户界面——希望产品能够具有实用性,而不只是例子
- 训练数据易于获取——有时数据比算法更难得
- 使用最新的深度学习技术(Google,Amazon等云平台可能已经存在),但不够先进(因此,可以在网络上找到相似的例子)
- 有达到“产品化”的可能
我们早期的想法是做一下医疗项目,因为医疗领域与我们更密切相关,且现在深度学习在医疗领域的有效成果还比较少. 然而,我们意识到,可能遇到数据收集和法律法规的问题,这与保持项目简单相冲突. 因此采用了第二方案——背景移除.
背景移除是手工或着半手工(利用 Photoshop,甚至 Power Point 的相关工具)可以容易完成的任务. 例如 Clipping Magic. 但是,据我们所知,全自动的背景移除,是一项具有挑战性的工作,虽然已经有相关的尝试工作,但现在仍没有能够取得满意结果的产品.
需要移除的背景是什么?这显然是一个重要的问题. 如果指定了物体(objects)或者轮廓(angle) 等的模型,就可以得到较为高质量的分离结果. 当开始我们的工作时,我们把问题想的很大:通用的背景移除器以自动分辨各种类型图片的前景和背景. 但是,当训练完初步模型时,我们认识到,将注意力集中到特定图像集是更合理的. 因此,这里只针对自拍照(selfie)和人像(human portraits) 进行分析处理.

Figure 1. (almost)人像的背景移除
自拍照是具有突出和集中前景的图像(一个或多个 persons),确保了物体(face+upperbody)和背景(background)能够有较好的可区分度,且角度相对不变(quite an constant angle),往往都是相同的物体(object, person).
基于这些假设,我们开始进行项目研究,以实现一个 one-click 的简单操作来完成背景移除的服务.
需要进行的主要工作是模型训练,但不能低估合理部署的重要性. 好的分割模型仍然与分类模型(e.g. SqueezeNet) 结合的不够紧凑,我们测试了在服务器(server)和浏览器(browser)的部署.
如果想了解关于产品部署过程的更多细节,欢迎访问 server 和 client.
如果想了解模型和模型训练的过程,请继续.
2. 语义分割Semantic Segmentation
与我们的产品相近的深度学习和计算机视觉任务,最佳选项是语义分割. 其它的策略,如 separation by depth detection,对于我们的研究不够成熟.
语义分割,和分类、目标检测,是计算机视觉的三大任务. 分割实际上是分类任务,将每一个像素分类. 但不像分类或者检测,分割模型表示着对图像的一些“理解”,而不是仅是说“图像里有一只猫”,而是要在像素级指出猫在的位置和猫是什么.
分割如何进行呢?为了更好的理解,我们首先介绍该领域的一些早期工作.
最早的想法是,采用早期的分类网络,如 VGG 和 Alexnet. VGG 是2014年出现的图像分类模型,由于其简单和直接的网络结构而被普遍应用. 分析 VGG 的浅层网络层,可以发现,需要分类的物体的附近具有较高的激活程度. 越深度的网络层,激活程度越高. 但由于 Pooling 层的影响,激活结果比较粗糙(coarse). 基于该理解,假设分类网络经过某些调整可以来寻找/分割物体.
语义分割的早起结果是伴随着分类算法产生的. 在 Post 中,可以看到一些基于 VGG 的粗略分割结果:
输入图片:

后期网络输出结果:
bilinear upsampling 结果:
这些结果仅是取自全连接层输出转换为原始尺寸的结果,保持了其空间特征,得到全卷积网络.
在上述例子中,输入 768*1024 的图片到VGG网络,得到 24*32*1000 的网络层输出. 24*32是图像池化后的特征图尺寸(缩小了32倍),1000 是图像类别数. 从该结果可以得到上述的分割效果.
为了平滑预测结果,研究者采用简单的 bilinear upsampling 层.
在 FCN 论文 中,进一步改善了这种idea. 他们将某些层进行连接,以获取更丰富的表达信息,根据上采样率(up-sampling rate),分别记作 FCN-32, FCN-16 和 FCN-8.
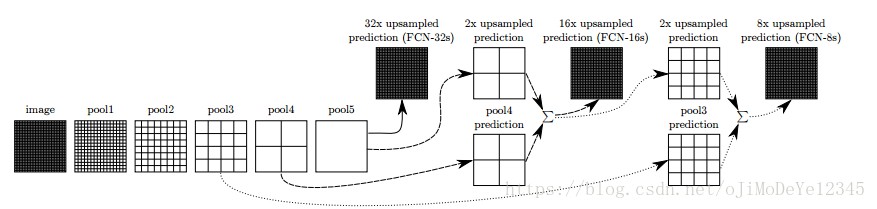
通过在网络层间添加一些跳跃连接(skip connections),使得预测结果能够编码原始图像的更好的细节信息. 进一步的训练可以提高预测结果. 该技术说明了基于深度学习的技术对于语义分割确实是可能有效的.

Figure 4. FCN 论文的分割结果
FCN 开启了分割的篇章,研究者基于不同的网络继续语义分割工作. 其主要思想是相同的: 基于已有网络,上采样,采用跳跃连接.
推荐阅读的几篇博客:
A 2017 Guide to Semantic Segmentation with Deep Learning
Semantic Segmentation using Fully Convolutional Networks over the years
A Brief History Of CNNs In Image Segmentation From Rcnn to Mask-Rcnn
也可以关注一些 encoder-decoder 网络结构.
3. 背景移除项目
在进行分析调研后,我们选择了三种模型: FCN,Unet 和 Tiramisu —— 深度 encoder-decoder 结构. 我们也考虑了 Mask-RCNN ,但是其实现有点超出项目范围.
FCN 由于其效果达不到期望好的效果,似乎与项目无关. 但是,其余的两个模型结果不太差. 基于 CamVid 数据集的 Tiramisu ,Unet的主要优势在于其紧凑性和速度快. Unet是相对容易实现的(基于 keras),Tiramisu 也是可以实现的. 这里采用 Jeremy Howard’s 的深度学习课堂 的 Tiramisu 实现.
基于这两种模型,我们开始在数据集上进行训练. 这里需要说明的是,我们先尝试了 Tiramisu ,发现该方法更适用于项目,因为其能够捕捉图像中的形状边缘(sharp edges). Unet 似乎不够适用,其结果差强人意.

3.1 数据
确定了模以后,开始选择合适的数据集. 分割数据与分类和检测数据不太相同. 另外,手工标注也不是一种可能. 最广泛的分割数据集是 COCO dataset,其包括 80K 张图片,共 90 类;VOC Pascal dataset,其共 11K 张图片,20 类;以及 ADE20K dataset.
由于COCO dataset 有更多的 person 类的标注图片,与我们的人像背景去除任务较为相关,这里选取该数据集.
根据我们的任务,分析了是,采用只与我们任务相关的图片,还是更通用的数据集. 一方面,采用具有更多图片和种类的通用数据集,可以使得模型能够应对更多场景和挑战. 另一方面,整晚的训练能够允许超过 150K 张图片. 如果我们对整个 COCO dataset进行模型训练,可以对每张图片训练两次,稍微修剪下是有帮助的. 另外,对于我们的任务能够更好的聚焦在模型上.
值得提到的是,Tiramisu 模型是基于 CamVid dataset 进行训练,其有一些缺点,最重要的是,该数据集的图片非常单调——所有的图片都是从一辆车得到的路照(road pics). 容易理解,从该数据集进行学习,即使其有 person,对于我们的任务是没有帮助的. 因此,经过一些尝试,我们继续.

Figure 2. CamVid dataset中的图片
COCO dataset 提供了直接的 API ,便于我们准确的知道每一张图片中的物体(90 中预定义类).
经过实验,我们决定梳理下 COCO dataset:
- 首先,只保留图片中存在 person 的图片,共得到 40K 张;
- 然后,删除图片中存在很多 person 的图片,确保每张图片只有 1-2 个 person; 这是我们的产品需要处理的.
- 最后,只保留图片中被标注为 person 的区域占 20% - 70% 的图片,去除背景中非常小的 person,以及某些奇怪的标注.
最终的数据集包含 11K 张图片,应该是够用于训练.

Figure 3. (左)-好图片;(中)包含太多person;(右)物体太小
3.2 Tiramisu 模型
我们在 Jeremy Howard’s course 介绍了 Tiramisu 模型. 尽管其全名是 “100 层 Tiramisu” ,表示是一个较大的网络,但其还是比较经济的,仅有 94M 参数. 而 VGG 网络超过 130M 参数.
Tiramisu 是基于 DenseNet 的,DenseNet是最近出现的图像分类模型,其所有层都是内部连接的(interconnected). 而且,类似于 Unet, Tiramisu 添加了一些跳跃连接(skip connections)到上采样层( up-sampling layers).
回忆下可知,该网络采用了 FCN 中的思想: 基于分类网络,上采样,添加跳跃连接以提升结果.
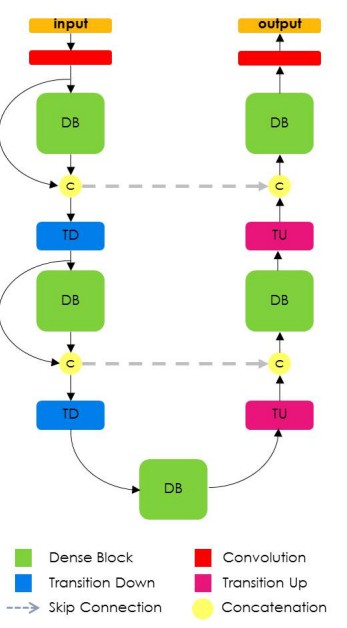
Figure 5. Tiramisu 网络
DenseNet 网络可以看作是 Resnet 模型的自然进化版本,但是,DenseNet 记住网络所有层的信息,而不是只记住直到下一层的每一层信息. 这种连接成为高速连接(highway connections). DenseNet 会引起 filter 数量的膨胀,记为“增长率(growth rate)”. Tiramisu 的 growth rate 是16,即每一层都添加 16 个新的 filters,直到网络层的 filters 数达到 1072. 然而,100 层的 tiramisu 可能会有 1600 层,上采样层裁剪了部分 filters.
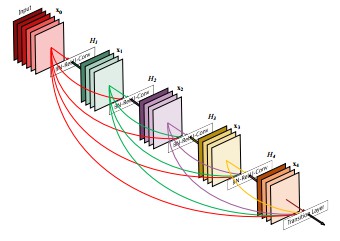
Figure 6. DenseNet 模型结构——前面的 filters 被堆积到整个网络.
3.3 训练
训练网络采用的损失函数是—— 标准的cross entropy loss,1e-3学习率和较小的 decay 的RMSProp optimizer 优化算子.
11K 的数据集的 70% 用于训练,20% 用于验证(validation), 10% 用于测试. 下面的图片都是测试集中的.
为了与原文的训练保持一致,我们设定 epoch size 为 500 张图片. 这就使得们可以周期的保存训练模型.
此外,我们只在两类的数据集上进行训练——背景和person. 论文里是 12 类. 我们首先在 COCO 的类别上进行训练,然而对于模型的训练影响不大.
3.4 数据问题
以下几方面的数据问题影响了预测结果:
- 动物(Animals) - 模型有时分割动物,这就会降低 IoU. 在我们的任务中添加动物类作为相同的主类或者其它类,都会影响预测结果;
- 肢体部分(Body Parts) - 虽然我们已经过滤了图片数据集,但是对于图片中的标注是 person类 还是某些人体部分,如,脚、手等,仍无法确认. 这些图片不在我们的研究范围,但仍是会出现的情况.

Figure 6. 动物、部分肢体、手持物体的图片 - 手持物体(Handheld Objects) - 数据集中的需要图片都是与体育相关的,如球棒、球拍、滑雪板等. 我们的模型会对如何分割它们产生混淆. 类似于动物的情况,这些图片数据会影响分割效果.
- Coarse ground truth - COCO dataset 的标注不是 pixel by pixel, 而是基于多边形(polygons)的. 有些情况,方法足够有效,但某些 groundtruth 可能非常粗糙,这对于模型的学习也是有影响的.

Figure 7. COCO dataset中的图片及对应的粗糙分割标注
4. 结果
我们的结果是令人满意的,虽然不够完美. 最终的测试集IOU是 84.6, 现在能达到 85. 虽然这个结果还不够稳定,其会在不同的数据集和类别间波动. 某些类容易分割,比如马,路等,很容易能达到 90 的IOU. 其它有挑战性的物体类是 树和人,大部分模型能达到大约 60 的IOU. 针对这种情况,我们将网络关注与单一类别,以及有限的图片类型.
我们的工作还未达到预计的产品化,但已经有50%的图片可以取得较高的分割结果,可以对结果进行讨论分析了.
下面是一些好的分割结果:



5. Debugging and logging
神经网络训练的一个重要部分是 debugging. 当工作开始时,能够对数据和网络,训练过程,网络输出进行监控,是有意义的. 但是,我们发现,追踪每一部分都是及其重要的,能够便于检查每一步的结果.
以下是遇到的问题:
- 早期问题:
模型不能训练. 这可能是因为内在问题,或者是某些预处理错误,比如忘记对某些数据快进行归一化,简单的结果可视化是有帮助的. 可以参考该Post. - 网络自身的调试:
在确认没有重要问题,网络训练开始,基于预定义的 loss 函数和度量. 分割度量采用的是 IoU- intersect over union. 另一个有帮助的是技巧是,对每一个 epoch 的模型预测结果进行显示. 可以参考该 Post 来了解机器学习模型调试的技巧. IOU不是 keras的标准度量/loss,可以从网络上找到其IOU实现. 这里我们给出了loss画图和每一个epoch 的预测结果的 Code-plot_loss+sample.py. - 机器学习版本控制:
当训练一个模型时,会有很多参数,某些可能是有用的. 我们可以说的是,我们还没有找到一种完美的方法,除了频繁地写明网络配置.(自动保存 keras callback的最佳模型). - Debugging 工具:
完成以上的工作后,我们可以对每一步的工作进行检测,但不是无缝隙的(seamlessly). 因此,最终的一步是结合以上的步骤,创建Jupyter notebook, 以便于我们无缝的加载每个模型和每张图片,快速验证结果. 基于这种方式,我们可以简单地比较不同模型的区别,错误和其它问题.
下面是模型提升的例子,通过参数调整和额外的训练:

保存最佳的验证 IoU 模型(Keras 提供了很好的 callback 以便于进行模型保存).
callbacks = [keras.callbacks.ModelCheckpoint(hist_model, verbose=1,save_best_only =True, monitor= ’val_IOU_calc_loss’), plot_losses]
除了正常的代码错误调试,我们注意到模型错误是可预测的,比如截断的肢体部分,大分割区域的小区域(Bites),不必要的连续的扩展肢体部分,较差的灯光,较差的质量,等等其它细节. 这些问题某些可以通过添加不同数据集的特定图片来解决,但仍有一些十分具有挑战性. 为了提高下一个版本模型的结果,我们将对困难图片进行扩增.
我们已经在上面提到数据集存在的问题,现在说一下模型问题:
- 服装:
非常深或非常浅的衣服某些情况下往往被当作背景; - Bites:
在好的分割结果中,有一些零星的错误小区域

Figure 8. 服装和 bite - 光照:
COCO dataset中,较差的光照和不清晰的图片是比较普遍. 除了模型要处理的标准困难问题外,我们还没有准备更难分割的图片. 这个问题可以通过扩增更多数据来提升效果.

Figure 9. 差光照的图片
6. 未来的改进方向
6.1 进一步训练
我们的模型结果是在训练数据集上训练了大约 300 epoches 后得到的. 此后,模型开始过拟合. 我们已经达到接近于发行的分割结果,因此,还没有进一步的应用数据增广.
模型训练采用的是 224*224 尺寸的输入图片. 进一步的训练,基于更多的数据,更大的图片尺寸(原始的COCO dataset 图片尺寸为 600 *1000),可能提升分割效果.
6.2 CRF 和其它后处理方法
在某些阶段,我们的分割结果在边缘存在一些噪声,一种能够改善的方法是CRF. CRF的使用方法参考 Post.
然而,CRF对于我们的工作不是帮助很大的,可能是由于CRF一般对于结果更 coarser 的情况有效.
6.3 Matting
基于现在的分割结果,仍是不完美的. 头发,衣服细节,树枝等其它精细objects 不能被完美分割. 即使背景分割中不包含这些子类. 对于这些精细化分割,被成为 Matting,也是具有挑战性的工作.
下面是 NVIDIA conference 上的 Matting 的一个例子:

Figure 10. Matting 例子 —— 输入包括 trimap
Matting 任务与其它的图像相关任务是不同的,因为其输入不仅包括图片,还需要其 trimap——图像边缘的轮廓,可以认为其是一个半监督问题.
我们尝试了一点 Matting 实验,采用分割结果作为 trimap,但没有取得明显效果提升.
另一个问题是,缺少适当的数据集来进行训练.
7. 总结
如开始所说,我们的目标是,设计一个深度学习产品. 从 Alion’s Posts 可知,部署变得越来越简单快速. 但模型的训练是复杂的. 网络训练需要仔细的设计与计划,调试,以及结果记录.
另外,研究与尝试新事物、训练和提升之间的工作,是难以平衡的. 由于我们采用深度学习技术,我们经常能感觉到,最佳的模型,或者我们需要的精确模型,一直就在附近,只需要 google 搜索一下或者相关的文章就可以让我们找到它. 但是,实际上,效果的提升来自对我们最初模型的一点一点的“挤压(squeezing)”. 正如上面说的,我们仍有很大的空间来提升最初模型的精度.