题目: Semantic Image Segmentation With Deep Convolutional Nets and Fully Connected CRFs - ICLR2015
作者: Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille
团队: Univ. of California, Google Inc.
将CNN和概率图模型结合,来处理像素级分类问题,即语义图像分割.
由于CNN具有不变性,适合于 high-level 任务,如图像分类.
但CNN网络最后一层的输出不足以精确物体分割.
这里结合CNN最后输出层的特征与全连接CRF相结合,提升语义分割效果.
语义分割的目标——Goal:
将图像分割为不同的语义部分,并对不同部分进行分类.

主要是两部分:
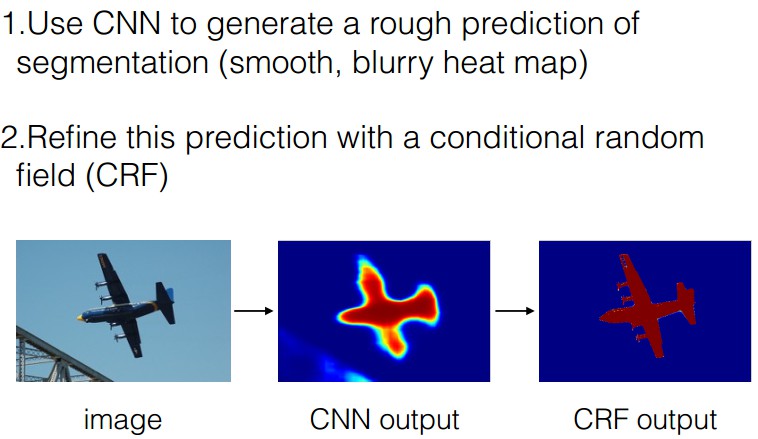
- 1. 采用CNN来初步得到图像分割结果
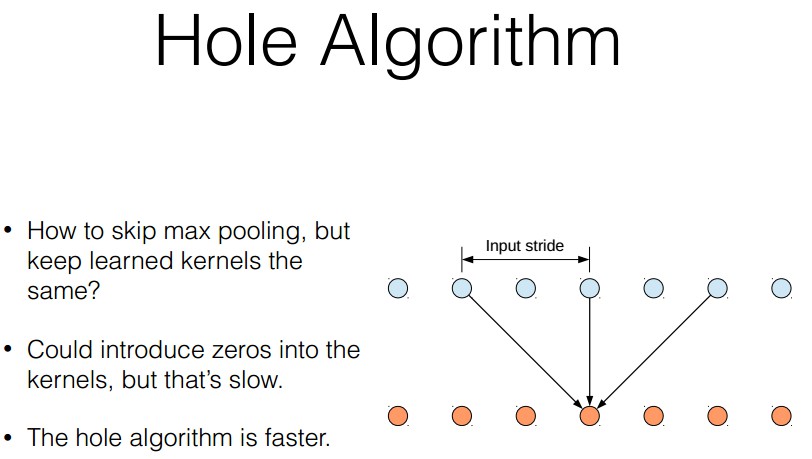
- hole algorithm (atrous algorithm),应对subsampling问题.
- train 阶段 - loss function 采用 CNN输出特征图的各像素空间位置的 sum of cross-entropy term (SoftmaxWithLoss). 原始图片的尺寸是CNN输出特征图的 8 倍, ground truth labels 也降采样到与CNN输出尺寸一致.
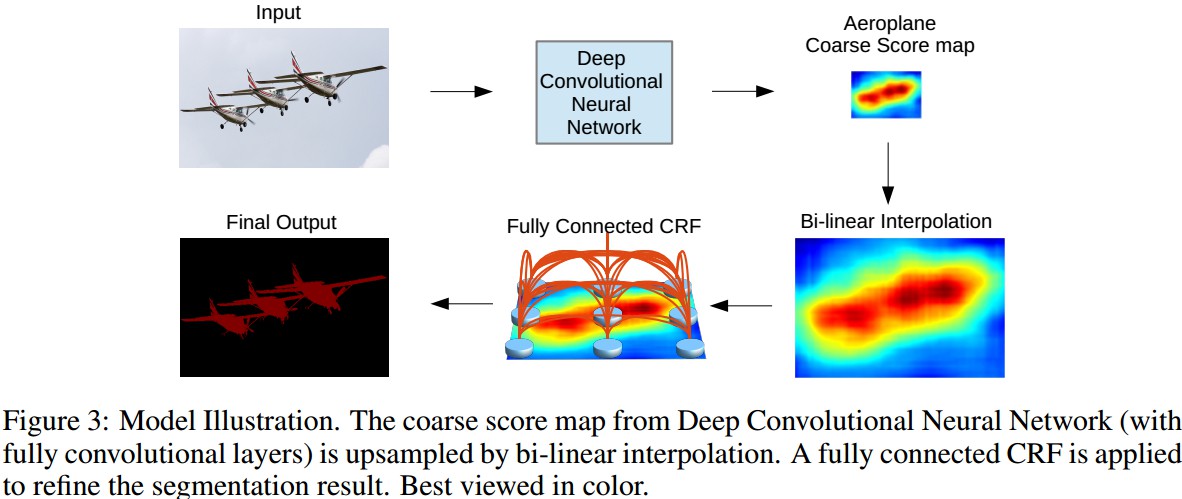
- test 阶段 - 将CNN输出转换到原始图像分辨率. CNN输出图具有很好的平滑性,故采用 bilinear interpolation 来增加其分辨率(factor=8).
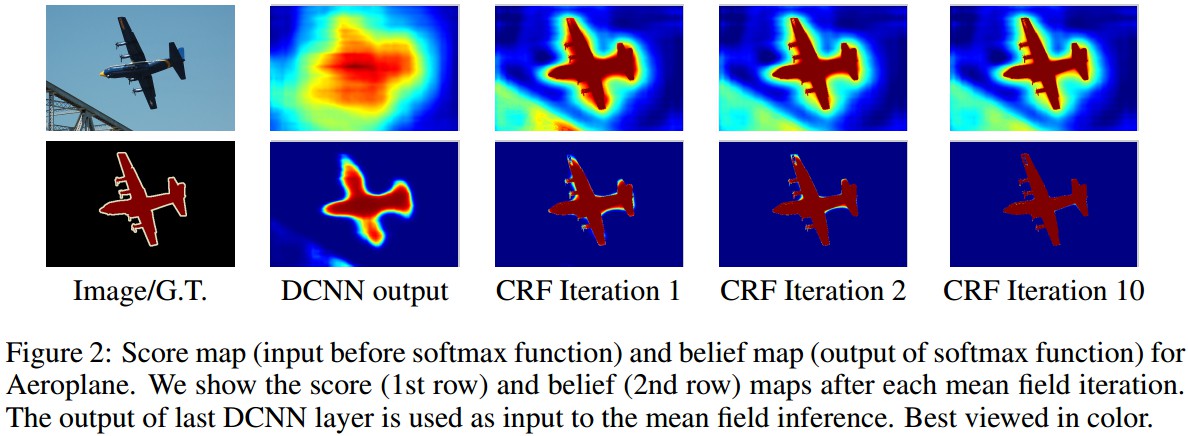
- 2. 采用CRF将CNN分割结果精细化
- spatial invariance
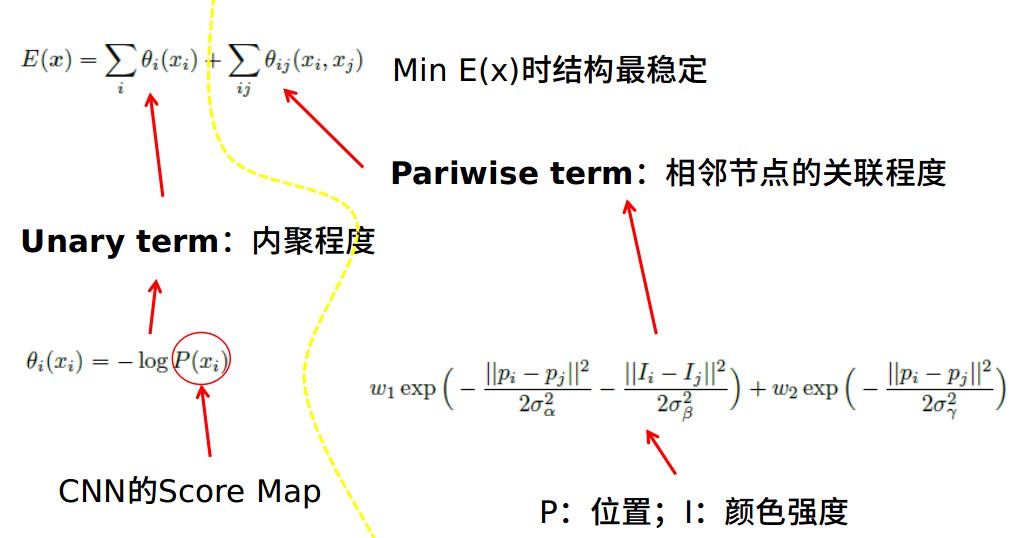
1. CNN


2. CRF



3. Results


好的分割结果:

差的分割结果:

4. Conclusion
- Modify the CNN architecture to become less spatially invariant.
- Use the CNN to compute a rough score map.
- Use a fully connected CRF to sharpen the score map.
5. Reference
[1] - Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
[2] - Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs - slides
[3] - 深度学习轻松学-核心算法与视觉实践 - 第九章-应用:图像的语意分割