题目: Rethinking Atrous Convolution for Semantic Image Segmentation
作者: Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam
团队: Google Inc.
Code-TensorFlow
DeepLabV3-Tensorflow
1. 摘要
DeeplabV1&V2 - 带孔卷积(atrous convolution), 能够明确地调整filters的接受野(field-of-view),并决定DNN计算得到特征的分辨率;
DeeplabV3 - 多尺度(multiple scales)分割物体,设计了串行和并行的带孔卷积模块,采用多种不同的atrous rates来获取多尺度的内容信息;
DeeplabV3 - 提出 Atrous Spatial Pyramid Pooling(ASPP)模块, 挖掘不同尺度的卷积特征,以及编码了全局内容信息的图像层特征,提升分割效果;
DeeplabV3 - 无需DenseCRF后处理.
2. Introduction
Atrous convolution:
Atrous convolution, 即dilated convolution, 它通过移除最后几层的下采样操作以及对应filter 核的上采样操作,来提取更紧凑的特征,相当于在不同的 filter权重间插入 holes;
Atrous convolution, 决定了DCNNs计算的特征的分辨率,而不增加新的额外学习参数.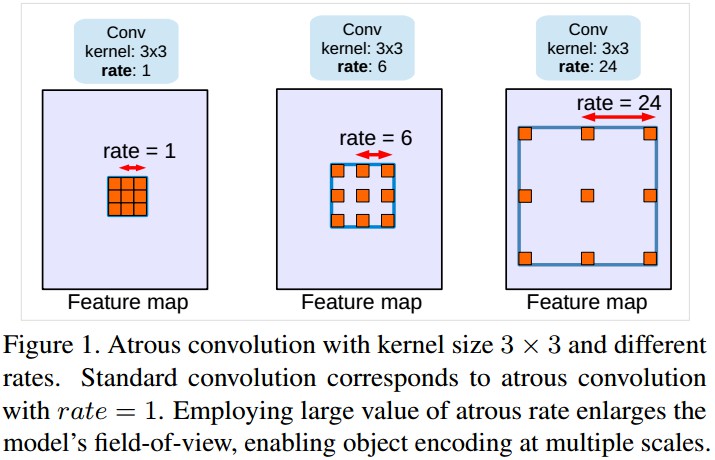
Multiple scales 常见的多尺度处理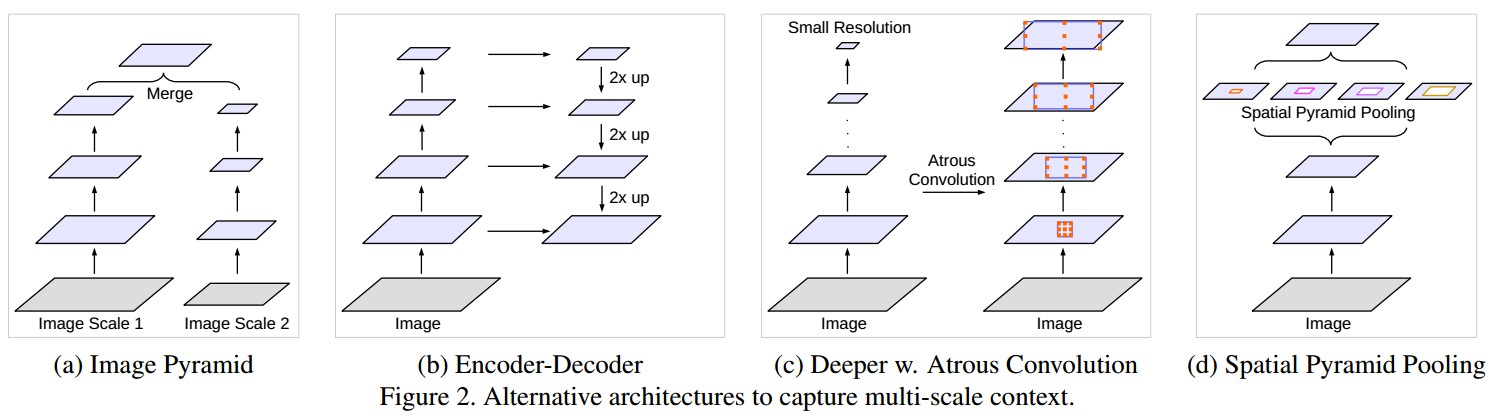
DeeplabV3
在串行模块和 spatial pyramid pooling 模块的网络结构中,atrous convolution,都能够有效增加filters的接受野,整合多尺度信息.
提出的串行和并行ASPP网络模块包含了不同rates 的atrous convolution处理与batch normalization layers,对于网络训练很重要.
一个重要的实际问题是,采用rate非常大的 3×3 atrous convolution,由于图像边界效应,不能捕捉图像的大范围信息,effectively simply degenerating to 1×1 convolution, 故这里提出将图像层特征整合仅ASPP模块中.
3 DeepLabV3 Methods
这里主要回顾如何应用atrous convolution来提取紧凑的特征,以进行语义分割; 然后介绍在串行和并行中采用atrous convolution的模块.
3.1 Atrous Convolution for Dense Feature Extraction
假设2-d信号,针对每个位置 ${i}$,对应的输出 ${y}$, 以及 filter ${w}$,对于输入 feature map ${x}$ 进行 atrous convlution 计算:
${ y[i]=\sum_{k}x[i + r*k]w[k] }$
其中,atrous rate ${r}$ 表示对输入信号进行采样的步长( stride),等价于将输入${x}$ 和通过在两个连续的filters值间沿着各空间维度插入 ${r-1}$ 个零值得到的上采样filters进行卷积. 通过改变 Atrous convolution 的 rate 值,来修改 filter 的接受野,也可以控制 FCN网络(fully convolutional networks)计算的特征紧凑程度. 如 Figure1 所示.
标准卷积即是atrous convlution 的一种rate ${r=1}$的特殊形式.
3.2 Going Deeper with Atrous Convolution
以串行方式设计 atrous convolution 模块
- 复制ResNet的最后一个block,如Figure3的 block4,并将复制后的blocks以串行方式级联;
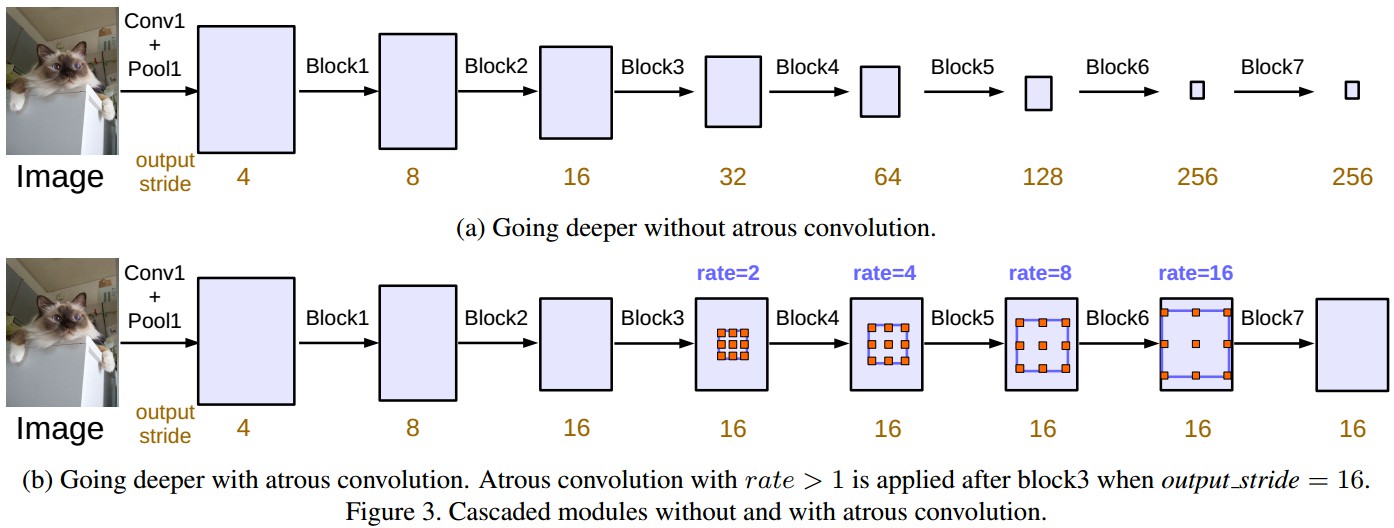
- 各block中有三个convolutions, 除了最后一个block, 其它block的最后一个convolution的步长都为2, 类似于原来的ResNet.
这种网络模型设计的动机,引入的 stride 能更容易的捕获较深的blockes中的大范围信息. 例如,整体图像feature可以融合到最后一个小分辨率的 feature map 中,如Figure3(a). 不过,这种连续的步长式设计,对于语义分割是不利的,会破坏图像的细节信息.
因此,这里采用由期望 outpur_stride 值来确定 rates 的atrous convolution 进行模型设计,如Figure3(b).
采用串行的ResNet, 级联block为block5、block6、block7,均为block4的复制,如果没有 atrous convolution, 其output_stride=256.
3.2.1 Multigrid
对 block4~block7 采用不同 atrous rates.
即,定义 Multi_Grid=(r_1, r_2, r_3) 为 block4~block7的三个convolutional layers的 unit rates.
convolutional layer 最终的 atrous rate 等于 unit rate 与对应的 rate 的乘积. 例如,当 output_stride=16, Multi_Grid=(1,2,4)时, block4 中三个 three convolutions 的 rate 分别为:rates=2*(1,2,4) = (2,4,8).
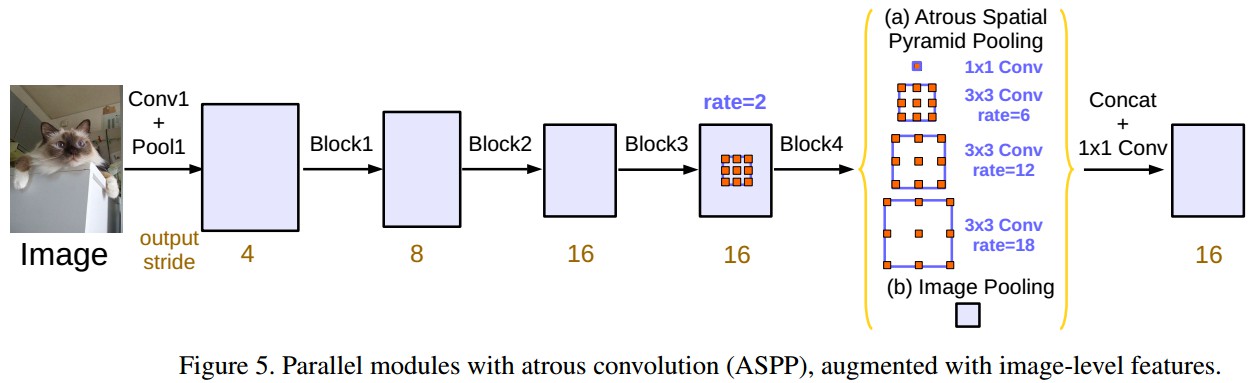
3.3 Atrous Spatial Pyramid Pooling
ASPP, 采用四个并行的不同 atrous rates 的 atrous convolutions对 feature map 进行处理,灵感来自 spatial pyramid pooling.
ASPP, deeplabv3 中,将 batch normalization 加入到 ASPP模块.
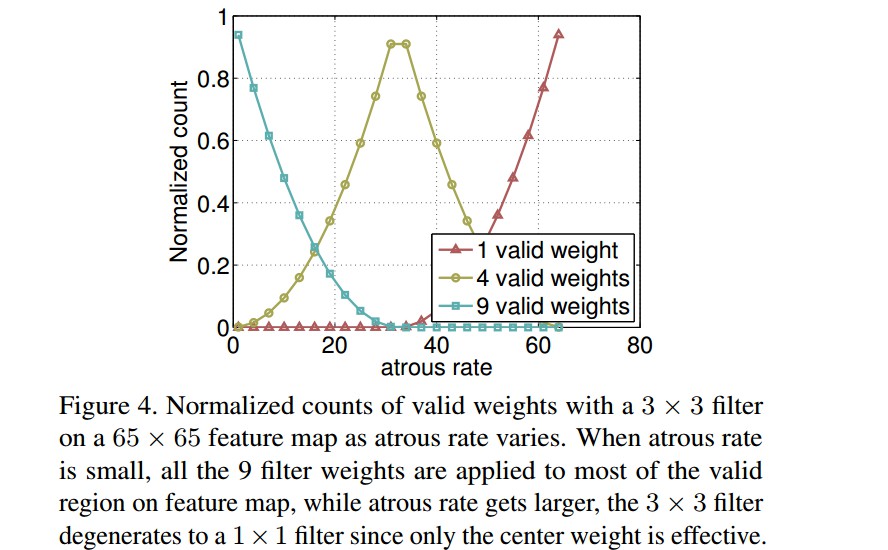
具有不同 atrous rates 的 ASPP 能够有效的捕获多尺度信息. 不过,论文发现,随着sampling rate的增加,有效filter特征权重(即有效特征区域,而不是补零区域的权重)的数量会变小. 如图Figure4,当采用具有不同 atrous rates的 3×3 filter 应用到 65×65 feature map时,在 rate 值接近于 feature map 大小的极端情况,该 3×3 filter 不能捕获整个图像内容嘻嘻,而退化成了一个简单的 1×1 filter, 因为只有中心 filter 权重才是有效的.
针对上面的问题,并将全局内容信息整合进模型中,论文采用图像级特征.
即,采用全局平均池化(global average pooling)对模型的 feature map 进行处理,将得到的图像级特征输入到一个 1×1 convolution with 256 filters(加入 batch normalization)中,然后将特征进行双线性上采样(bilinearly upsample)到特定的空间维度.
最后,论文改进了ASPP, 即,
(a) 当 output_stride=16时,包括一个 1×1 convolution 和三个3×3 convolutions,其中3×3 convolutions的 rates=(6,12,18),(所有的filter个数为256,并加入batch normalization). 需要注意的是,当output_stride=8时,rates将加倍.
(b) 图像级特征, 如 Figure5.
连接所有分支的最终特征,输入到另一个 1×1 convolution(所有的filter个数也为256,并加入batch normalization),再进入最终的 1×1 convolution,得到 logits 结果.
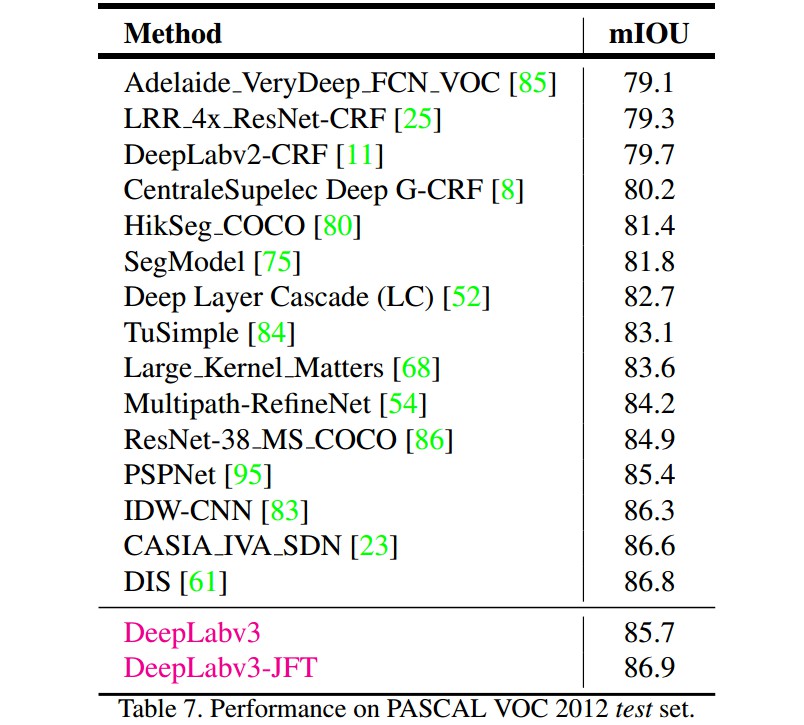
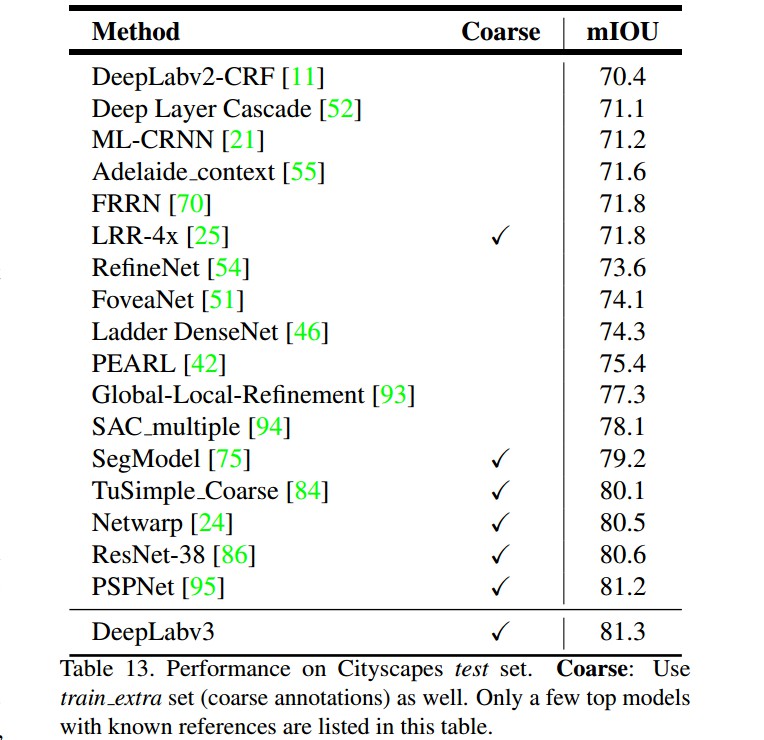
results