原文:Building an Image Hashing Search Engine with VP-Trees and OpenCV - 2019.08.26
本文旨在介绍如何采用 Python 实现基于 OpenCV 和 VP-Trees 的图片哈希搜索引擎.
图像哈希算法(Image Hashing algorithms) 被用于:
[1] - 将图片的内容转化为单个整数(a single integer).
[2] - 基于计算得到的哈希值,处理图片数据集中的相同或者接近相同的图片.
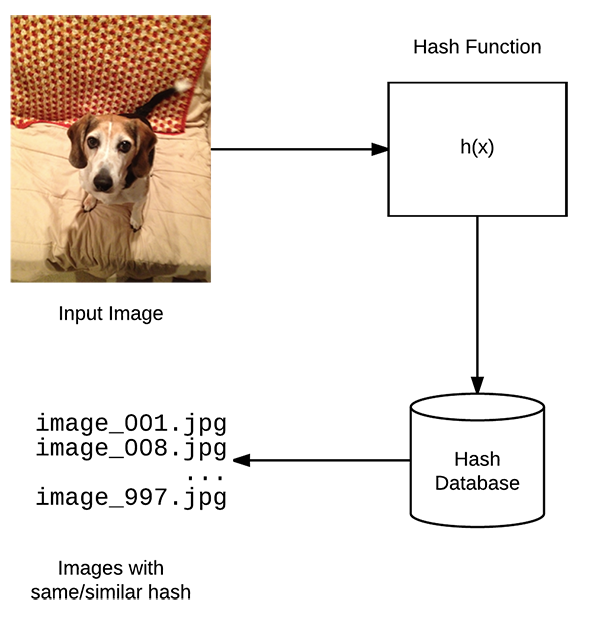
1. 图片哈希
Image hashing with OpenCV and Python - 2017.11.27
图片哈希(Image hashing) 和感知哈希(perceptual hashing) 的处理过程为:
[1] - 检查图片的内容;
[2] - 基于图片的内容来构建哈希值,以唯一的表征输入图片.

这一部分主要包含三个方面的内容:
[1] - 介绍图片哈希和感知哈希;
[2] - 图片哈希的实现,尤其是 dHash(difference hashing).
[3] - 采用图片哈希处理实际问题和数据集.
1.1. md5 哈希
Ubuntu - md5sum 文件校验工具 - AIUAI
md5 也是用于计算和校验文件的.
identify test.png
md5 test.png
convert test.png -resize 250x test_resize.png
md5 test_resize.png但这种加密哈希算法的问题在于:即使改变文件的一个字节,也会得到不同的哈希值. 对于图片而言,哪怕仅仅改变了输入图片的一个像素的颜色,也会得到不同的指纹,即使实际上肉眼很难感知到单个像素已经发生了变化;但是对于肉眼来说,这两张图片感知上是相同的(perceptually identical).
比如,对于一张输入图片,仅仅是将其尺寸由 500 pixels 缩小为 250 pixels,而不修改图片其它任何内容,但其 md5 哈希值也会发生改变,即使图片的视觉内容没有发生任何变化.
但,图片哈希和感知哈希希望解决的是相似图片能够具有相似哈希.
1.2. dHash
图片相似性比较之哈希算法(aHash 和 pHash) - AIUAI
dHash 大致包含四步处理,相对直接和易于理解.
[1] - 将图片转化为灰度图(grayscale)
首先,将输入图片转化为灰度图,舍弃掉图片的所有颜色信息.
舍弃图片颜色信息的好处在于:
(1)-哈希计算速度更快,因为只需要在一个通道上进行计算.
(2)-图片相似性匹配时减少颜色空间的变化的影响.
不过,如果需要关注颜色,也可以对图片的每个通道分别单独计算哈希,然后再进行组合(最终得到的哈希值会 3x 倍).
[2] - 调整灰度图尺寸(resize)
输入图片转换为灰度图后,再压缩到 9x8 pixels 的大小,忽略长宽比(aspect ratio). 对于大部分图片数据集,resize/interploation 操作是算法最慢一步处理.
这里解释两个问题:
(1)-为什么在 resize 时忽略图片的长宽比? —— 确保相似图片不受其初始空间维度的影响.
(2)-为什么是 9x8?(后面会解释)
[3] - 计算差值(difference)
dHash 旨在计算 64-bit 的哈希值,采用 8x8=64 更接近与此. 但为什么将灰度图尺寸调整为 9x8 呢?
dHash,差异性哈希(difference hash),顾名思义,计算的是临近像素间的差值(即:相对梯度(relative gradients),computing the difference between adjacent pixels).
对于每行 9 pixels 的输入图像,计算临近列 pixels 间的差值,可以得到 8 个差值. 8 行 8 个差值即 8x8=64,即 64-bit 的哈希值.
[4] - 构建哈希值(hash)
dHash 的最后一步处理是字节分配和构建哈希值.
根据计算得到的差值图像 D 和对应的像素集合 P,哈希构建的方式为:P[x] > P[x+1] = 1 else 0.
这里,判断左边像素是否大于右边像素,如果左边像素大于(亮于)右边像素,则输出值为 1;如果左边像素小于(暗于)右边像素,则输出值为 0.
将 8x8 pixels 的输出组合为 64-bit 的二值整数,即真正的图片哈希.
1.3. dHash 的特点
dHash 有很多优点,基本特点包括:
[1] - 即使输入图像的长宽比发生变化,图片哈希值也不会改变.
[2] - 调整亮度(brightness) 或者对比度(contrast),其一般不会改变图片哈希值. 即使发生轻微变化,也能保证相似图片的哈希值比较接近.
[3] - dHash 计算速度快(extremely fast).
1.4. dHashes 对比
一般情况下,采用 Hamming 距离对比不同图片的哈希值,其衡量了两个哈希值间不相同字节的位数.
两个哈希值的 Hamming 距离为 0 ,则表示两个哈希值完全一致(即,没有不相同的字节),两张图片则是一致或者感知相似的.
HackerFactor 中建议哈希值间的 Hamming 距离 >10 bits 则两张图片是不同的,如果哈希值在 1-10 bits 则可以认为两张图片是相同或相似的. 实际中可以根据应用场景和数据集特点调整 Hamming 距离阈值.
1.5. dHash 实现
from imutils import paths
import time
import sys
import cv2
import os
image = cv2.imread("test.png")
def dhash(image, hashSize=8):
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#调整输入图片尺寸
#添加一列,用于计算水平梯度(horizontal gradient)
resized = cv2.resize(image, (hashSize + 1, hashSize))
#计算临近列像素间的相对水平梯度.
diff = resized[:, 1:] > resized[:, :-1]
#差值图片转化为哈希值
return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v])2. 图片搜索引擎
图片搜索引擎,也可以认为是以图搜图,给定输入的查询图片(非文本等关键词),图片搜索引擎基于图片的内容,返回相似图片搜索结果.

2.1. 图片哈希表示
这里采用图片哈希(Image Hashing,Perceptual Hashing) 构建搜索引擎.
图片哈希的一个优势在于,图片的表征占用存储很少.
例如,对于尺寸为 800x600 的 3 通道的RGB图片,如果采用 8-bit 无符号整数的数据类型进行存储,需要大概 1.44MB RAM. 当然,如果只是保存图像的原始像素值,占用内存可以少些.
也可以采用一些特征提取算法,如关键点检测、局部不变描述子(SIFT, SURF 等). 这些算法一般得到的每张图片的特征维度为 100s-1000s.
假设检测 500 个关键点,每个关键点得到 128-d 的特征向量,其数据类型为 32-bit 浮点数类型. 则需要总共 0.256MB 来保存数据集中每张图片的特征表示.
而,图片哈希采用32-bit 整数来表示图片,其只需要 4 bytes 的内存.
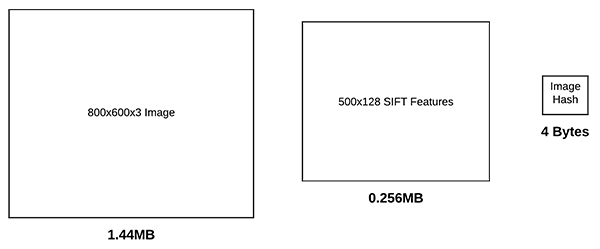
另一方面,图片哈希具有可对比性.
假设计算得到三张输入图片的哈希值,其中两个是接近相似的,如下图.
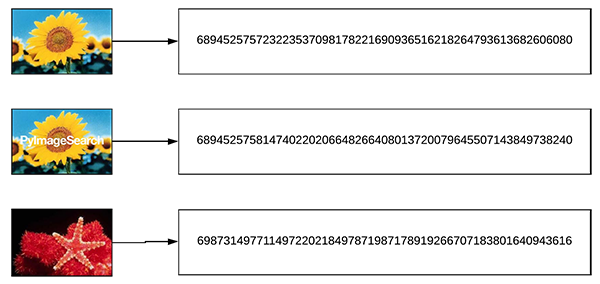
采用 Hamming 距离计算哈希值之间的相似性,对比两个哈希值串之间不同字节位数的数量. 实际上计算的是对两个哈希值之间求 XOR,并计算值为 1 的数量.
上图中,两张相似图片的哈希值间 Hamming 距离应该是很小的,而与第三个不相似图片的 哈希值间 Hamming 距离应该是大一些.

2.2. 图片哈希搜索引擎
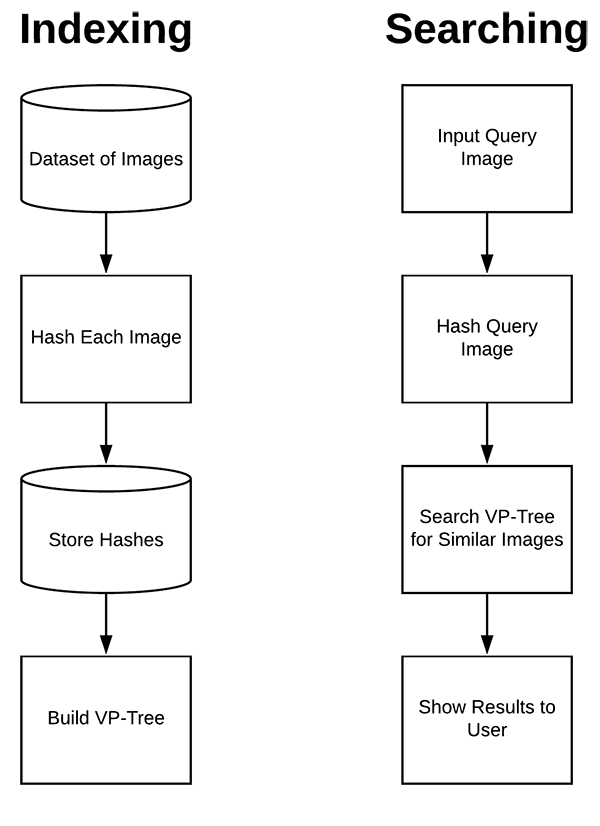
图片哈希搜索引擎主要包括两部分:
[1] - 索引(Indexing)
对于输入图片数据集,计算每张图片的哈希值,并保存到便于有效搜索的数据结构中(如 VP-Tree).
[2] - 搜索/查询(Searching/Querying)
给定查询图片,计算其哈希值,并在索引数据集中查询所有相似图片.
2.3. 面临的问题
图片哈希搜索引擎面临的最大问题是可扩展性(scalability),图片数据量越大,搜索的时间会越长.
例如,假设有如下场景:
[1] - 已有一个 1000000 张图片的数据集;
[2] - 已经分别计算每张图片的图片哈希;
[3] - 用户提供一张输入图片,然后要求查询数据集中所有相似图片.
对此,该如何进行搜索呢?是需要对所有 1000000 张图片哈希进行逐个与输入图片的图片哈希进行对比吗?
实际上这是不可能的,哪怕每次 Hamming 距离计算只话费 0.00001 秒,完成一次完整搜索也需要 10 秒,这是比任何类型的搜索引擎都是很慢的.
因此,需要采用特定的数据结构.
2.4. VP-Tree 数据结构
为了构建可扩展的图片哈希搜索引擎,需要采用特定的数据结构,其要满足:
[1] - 减少搜索的线性复杂度(linear complexity), O(n) ...
[2] - 降低到 sub-linear complexity,如理想值 O(log n) ...
对此,可以采用 VP-Trees (Vantage-point Trees).
VP-Trees 是一种在度量空间进行操作的度量树,通过选择度量空间中的一个给定位置,如有利点(vantage point),将数据点划分为两个数据子集:
- 靠近 vantage point 的数据点;
- 远离 vantage point 的数据点.
然后,递归地进行该过程,将数据点划分为越来越小的数据子集,然后创建一个树,树里临近点具有较小的距离.
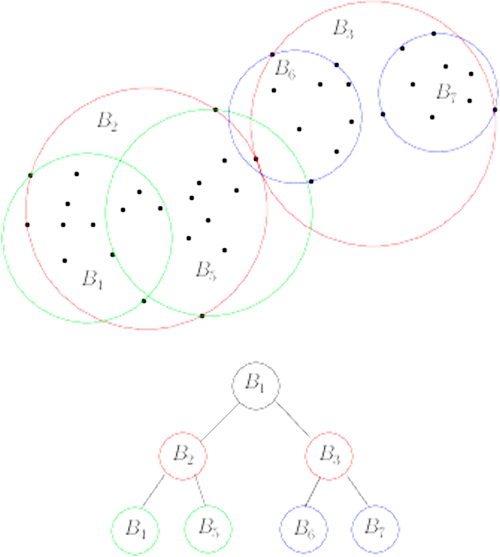
图:VP-Trees 基于递归算法,其计算 vantage point 和 medians,直到所有子节点(child nodes)只包含单个图片哈希. 更靠近的子节点(这里是 Hamming 距离更小)则被认为彼此更相似.
VP-Tree 的构建过程如图:
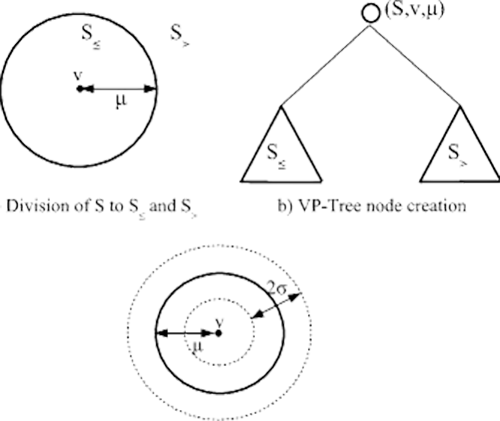
首先,选择空间中的一个点,记为图中圆圈中心处的 $v$,该点 v 被称为 vantage point. vantage point 是与树中 parent vantage point 最远的点.
然后,计算所有点 $X$ 的均值(median) $\mu$
得到 $\mu$ 后,将所有数据点 $X$ 分为两个数据子集 $S1$ 和 $S2$:
- 距离小于等于 $\mu$ 的所有点,属于 $S1$;
- 距离大于 $\mu$ 的所有点,属于 $S2$.
接着,递归地进行该过程,直到只剩一个子节点(child node).
一个子节点仅包含单个数据点(这里是单个图片哈希). 树中互相接近的子节点,具有的特点为:
- 其距离都较小;
- 相比于树中其它数据点,其更相似.
最终得到的 VP-Tree 数据结构,例如:
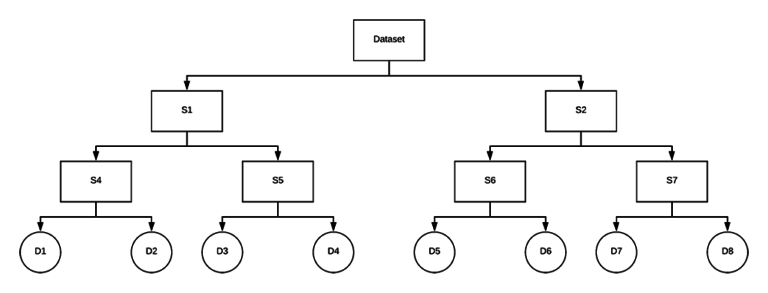
VP-Trees 构建的复杂度为 O(nlogn),但是仅需要构建一次;而单词查询的复杂度只需 O(logn),即,将搜索时间复杂度降低到了 sub-linear complexity.
3. 图片哈希搜索引擎 Python 实现
[1] - 图片哈希相关辅助函数 - hashing.py:
import numpy as np
import cv2
def dhash(image, hashSize=8):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
resized = cv2.resize(gray, (hashSize + 1, hashSize))
diff = resized[:, 1:] > resized[:, :-1]
return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v])
def convert_hash(h):
#将哈希值转换为 numpy 的 64-bit 浮点数;
#然后再转换为 int 格式.
return int(np.array(h, dtype="float64"))
def hamming(a, b):
#计算 Hamming 距离
return bin(int(a) ^ int(b)).count("1")[2] - CALTECH-101 图片数据集,共 101 个类别,9144 张图片,每个类别大概有 40-800 张图片.

3.1. 图片数据集索引(Index)
index_image.py:
from hashing import convert_hash
from hashing import hamming
from hashing import dhash
from imutils import paths
import pickle
import vptree
import cv2
#
imagePaths = list(paths.list_images("/path/to/CALTECH-101/images/"))
hashes = {}
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# load the input image
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
image = cv2.imread(imagePath)
#计算图片哈希值,并转化数据格式
h = dhash(image)
h = convert_hash(h)
#update the hashes dictionary
l = hashes.get(h, [])
l.append(imagePath)
hashes[h] = l
#构建VP-Tree
print("[INFO] building VP-Tree...")
points = list(hashes.keys())
tree = vptree.VPTree(points, hamming)
#将 VP-Tree 序列化写入到磁盘
print("[INFO] serializing VP-Tree...")
f = open("/path/to/output/vptree.pickle", "wb")
f.write(pickle.dumps(tree))
f.close()
#将哈希值序列化到字典
print("[INFO] serializing hashes...")
f = open("/path/to/output/hashes.pickle", "wb")
f.write(pickle.dumps(hashes))
f.close()3.2. 图片查询(Search)
search.py:
from hashing import convert_hash
from hashing import dhash
import pickle
import time
import cv2
#加载 VP-Tree 和哈希字典
print("[INFO] loading VP-Tree and hashes...")
tree = pickle.loads(open("/path/to/output/vptree.pickle", "rb").read())
hashes = pickle.loads(open("/path/to/output/hashes.pickle", "rb").read())
#读取输入的查询图片
image = cv2.imread("/path/to/test.jpg")
cv2.imshow("Query", image)
#计算查询图片的哈希值,并转换数据格式
queryHash = dhash(image)
queryHash = convert_hash(queryHash)
#查询
print("[INFO] performing search...")
start = time.time()
#maximum_hamming_distance - 相似度阈值
results = tree.get_all_in_range(queryHash, "maximum_hamming_distance")
results = sorted(results)
end = time.time()
print("[INFO] search took {} seconds".format(end - start))
# loop over the results
for (d, h) in results:
# grab all image paths in our dataset with the same hash
resultPaths = hashes.get(h, [])
print("[INFO] {} total image(s) with d: {}, h: {}".format(
len(resultPaths), d, h))
# loop over the result paths
for resultPath in resultPaths:
#加载查询结果图片,并显示result = cv2.imread(resultPath)
cv2.imshow("Result", result)
cv2.waitKey(0)4. 相关材料
[1] - The complete guide to building an image search engine with Python and OpenCV]
[2] - Image Search Engines Blog Category
[3] - PyImageSearch Gurus
[4] - VP trees: A data structure for finding stuff fast - Steve Hanov
[5] - VP Tree - Ivan Chen
[6] - 相似图片搜索的原理 - 阮一峰
[7] - 相似图片搜索的原理(二)- 阮一峰