原文:跨越时空的难样本挖掘 - 知乎 - 2020.06.19
作者:王珣
码隆科技在深度度量学习继续深耕,又做了一点点改进的工作,承蒙审稿人厚爱,被CVPR-2020接收为Oral,并进入best paper候选(共26篇文章进入了候选).
本文中提出了一个叫做 XBM 方法,通过记住过去迭代里的特征,使得模型的训练不再仅仅依靠当前 mini-batch 的样本,而是可以跨越“时空”(mini-batch)构建样本对,从而可以用极小的代价来获得巨量的样本对.
1. 背景和动机
难例挖掘是深度度量学习领域中的核心问题,最近很多工作都是在改进采样或者加权方案. 目前的改进方法主要有两种思路:
第一种思路是在mini-batch内下功夫,对于mini-batch内的样本对,从各种角度去衡量他们的难度, 然后对于难样本对,给予更高的权重,比如N-pair Loss、Lifted Struture Loss、MS Loss就是这种做法;
第二种思路是在mini-batch的生成做文章,比如 HTL、divide and conquer,他们的做法虽然看上去各有不同,甚至复杂精妙,但其实大差不差. 不严谨地说,大致思路都是对整个数据集进行聚类,每次生成mini-batch不是从整个数据集去采样,而是从一个子集,或者说一个聚类小簇中去采样. 这样的做法,由于采样范围本身更加集中,生成的mini-batch中难例的比例自然也会很高.
然而,无论是第一种方法的额外照顾难样本,还是第二种方法的小范围采样,他们对难例的挖掘能力其实依然有一个天花板:mini-batch的大小. mini-batch的大小决定了在模型中单次迭代更新中,可以利用的样本对的总量. 所以,类比厨师做菜,mini-batch的大小就是食材的数量. 巧妇难为无米之炊,即便是中华小当家,没有足够的食材,也做不出来闪闪发光的美味呀.
我们在三个标准图像检索数据库上,对于三种标准的pair-based方法,发现随着mini-batch变大,效果(Recall@1)大幅提升. 实验结果如下:
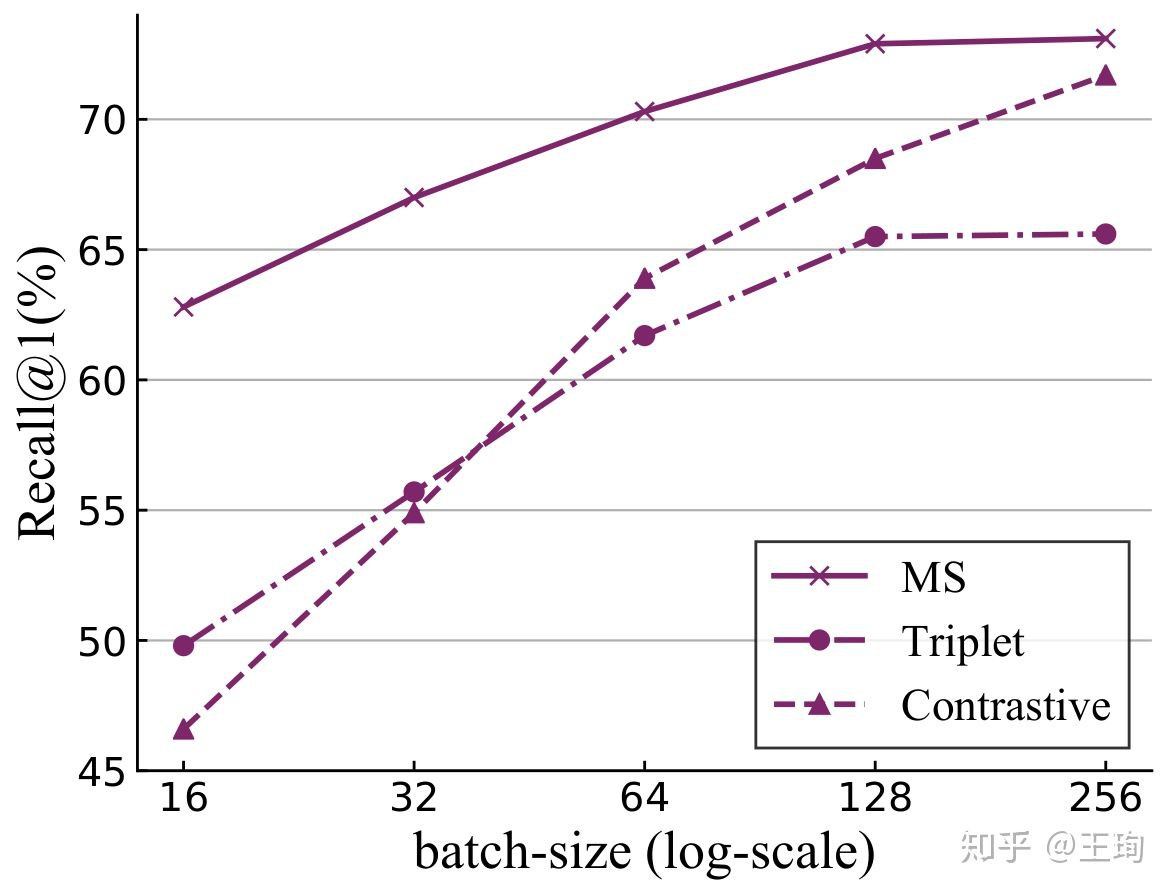
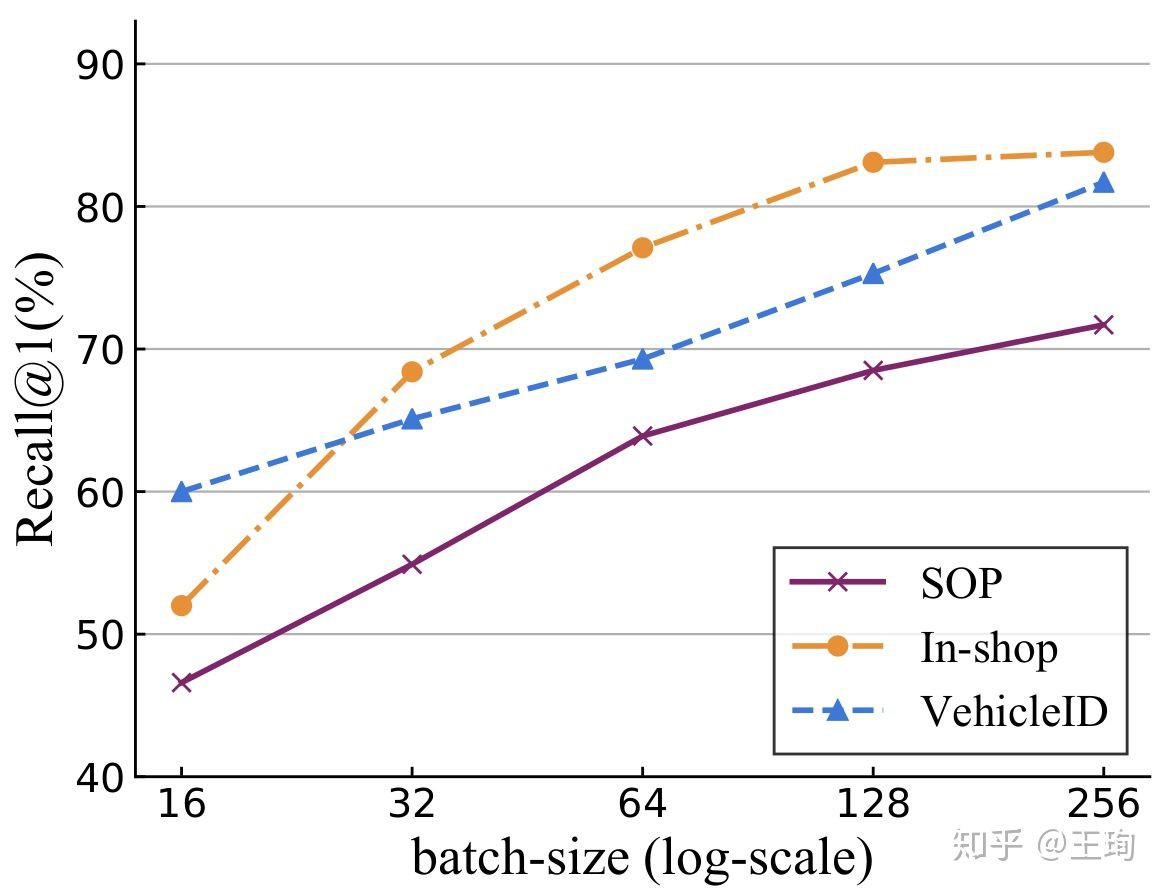
看着这个mini-batch增大带来的奇效,有小朋友就会问了,那我们还搞什么采样方法,改进什么加权方法呢?直接无脑上大的batch-size就行啦!
可是真的不行呢!
为什么呢?答案很简单,因为不是所有人可以买得起那么多食材,mini-batch越大,你需要的卡(GPUs/TPUs)越多,即便你卡够多,卡之间的通信也是考验一点点工程能力的.
2. 特征偏移
到了这一步,我们似乎陷入“贫穷”陷阱,有小朋友就会问了,有没有什么办法,不用很大的mini-batch,也可以获得超大的样本对呢?有没有白送的难例来让我的模型变得更高更强呢?
我的答案就是,别问,问就是白送.
这里我们正式进入我们的主题:XBM,让样本们即使隔着时空,也可以成双成对,双宿双飞.
XBM的想法是这样的,如果要在没有大的mini-batch的情况下,依然可以获得大量的样本对. 那么必须突破大家做深度度量学习一直以来的一个思维局限:仅在对当前mini-batch里的样本对两两比较,形成样本对. XBM就是突破这个局限,跨越时空进行难例挖掘,把过去的mini-batch的样本提取的特征也拿过来作比较,形成样本对.
这时候有小朋友就又会问了,过去的mini-batch的特征是由过去的模型提取出来的,而模型在训练过程中是一直更新迭代的,那么过去的样本特征,如果用现在的模型提取,其实是不一样的. 但是,不一样并不代表一定不行. 关键点是有多不一样,与其猜测,不如去测试看看. 我们观察样本特征随着模型训练的偏移量,称之为feature drift(特征偏移),精确定义参见原论文(原论文链接).
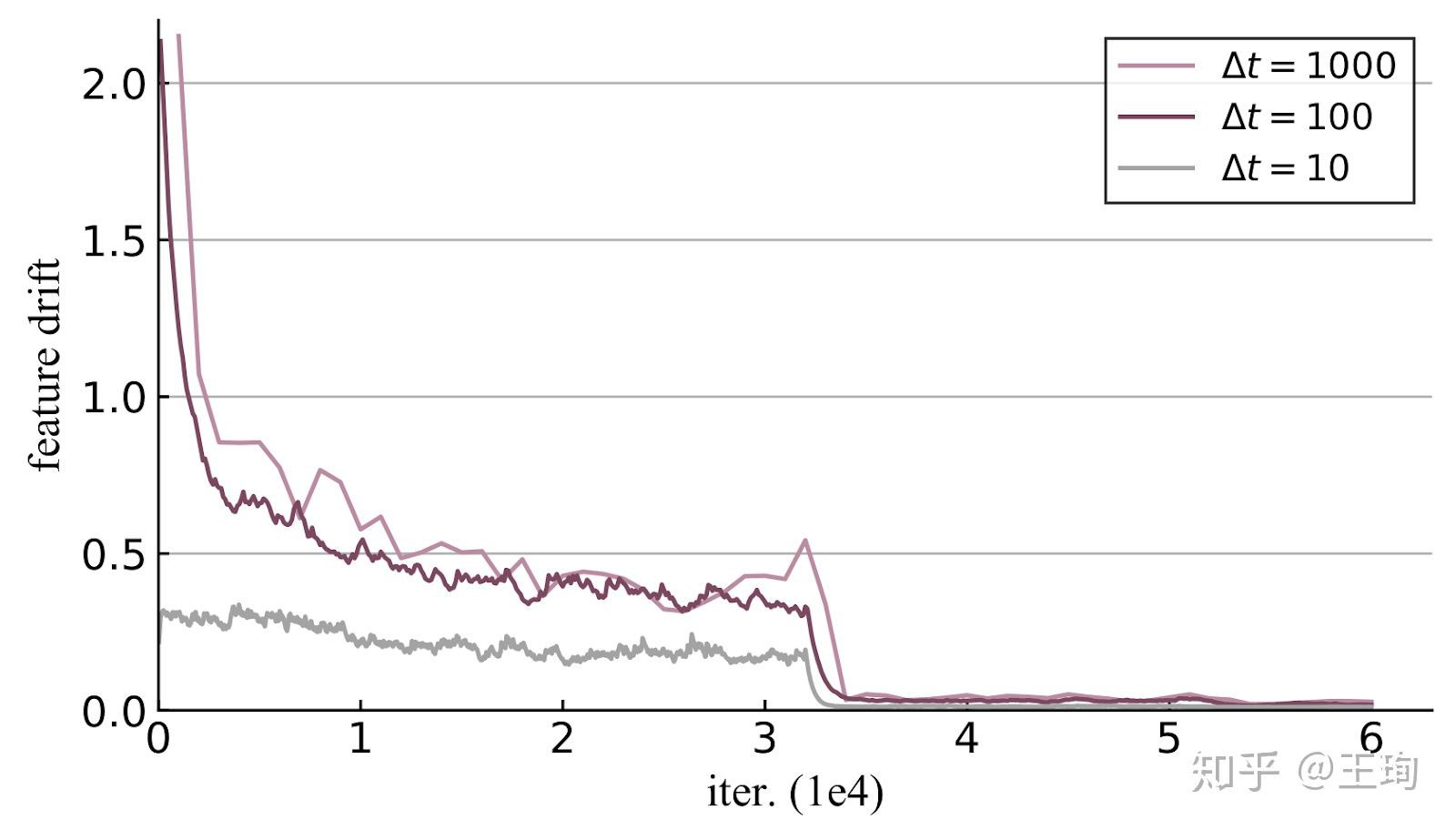
从上图我们发现,在训练的一开始,模型还没有稳定,特征剧烈变化, 每过100次迭代,特征偏移大约0.7以上,但是,随着训练的进行,模型逐步稳定,特征的偏移也变小. 我们称这个现象为“slow drift”.
3. 方法梗概
所以,虽然在训练的前3K iteration,过去的mini-batch提取的特征与当前模型偏差太大,但是只要我们愿意等待一会儿,过去的迭代里所提取过的特征其实可能是当前模型的一个有用的近似了. 我们要做的不过是把这些特征给存下来. 你要知道,每个特征不过是128个float的数组,即便我们存下了过去100个mini-batch的特征,不过是6400个(假设batch size=64)个float数组,所需要的不过是几十MB的显存. 而它带来的好处是,我们能够组成的样本对的个数是仅仅利用当前mini-batch的一百倍. 而如果你胆子大点,即便是imagenet这种百万级别的数据集的特征,也是可以整个儿塞到一张显卡上的(大约需要6000MB的显存). 即便这些特征不能精准的反映当前模型的信息,但是只要特征偏移在合理的范围内,这种数量上带来的好处,可以完全补足这种误差带来的副作用. 通俗的来讲,就是三个臭皮匠,顶个诸葛亮. 虽然这个特征不够准确. 但是架不住我人多势众呀.
到了这里,我们应该差不多已经接近答案了. 我们的XBM的方法架构大致如下:

伪代码如下:

我们的XBM是极其简单的,我们先训练一会儿,等待特征偏移变小,然后我们使用XBM:一个特征队列去记忆过去mini-batch的特征,每次迭代,都会把当前mini-batch提取出来的新鲜特征加入队列,并把最老的特征踢出队列,从而保证XBM里的食材(划掉)特征尽量是最新的. 每次去构建样本队的时候. 我们将当前mini-batch和XBM里的所有特征都进行配对比较. 从而形成了巨量的样本对,XBM存储了过去100个mini-batch,那么其所产生的样本对就是基于mini-batch方法的100倍. 所以,XBM其实是等等党的胜利.
机智勇敢的小朋友们不难发现,XBM可以直接和过去的基于样本对的方法结合,只需要把原来的mini-batch内的样本对换成当前mini-batch和XBM的特征构成的样本对就可以了. 所以,我们通过XBM这种存储特征的机制,让不同mini-batch跨越时空,再续前缘,成功配对.
4. 实验
4.1. 消融实验一
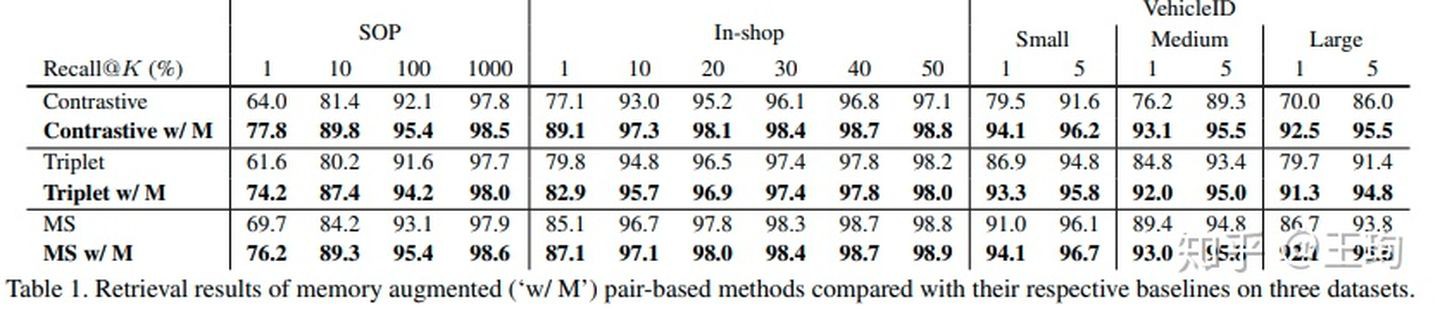
我们首先在三个常用的检索数据集,和三个基于样本对的深度学习的方法上,用上我们的XBM,其他的设置全部不变,我们发现,XBM带来的效果很明显. 尤其是在最基本的对比损失(contrastive loss)上,可以看到,本来这个方法只利用mini-batch内的样本时,它的效果很一般,但是XBM给它插上了腾飞的翅膀,在三个数据集, Recall@1都至少提升10个点,尤其是VehicleID这个数据集的大(Large)测试集,效果提升了22个点(70.0-->92.5).
4.2. 消融实验二
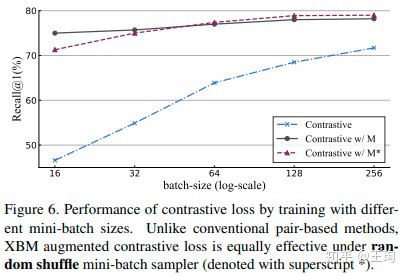
mini-batch的大小,从下图可发现三点,
- 无论是否使用XBM,mini-batch越大,效果越好;
- XBM即便是使用很小的batch(16), 也比没有XBM使用大的batch(256)效果好;
- 由于XBM可以提供正样本对,所以不一定要用PK sampler来生成mini-batch,可以直接使用原始的shuffle sampler,效果也差不多.
4.3. 计算资源消耗
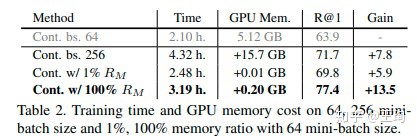
上图我们展示了在SOP上训练XBM的计算资源消耗,即便把整个训练集(50K+)的特征都加载到XBM,不过需要0.2GB的显存,而如果是增大batch,会另外需要显存15GB的,是XBM的80倍,但是效果的提升XBM要强得多. 毕竟XBM仅仅需要存特征,特征也只是过去的mini-batch的前向计算的结果,四舍五入不要钱,这个XBM婚介所中介费可以说是真的很低了.
4.4. 对比SOTA
与最近的深度度量学习方法对比,我们在四个较大的检索数据库上,效果均大幅提升,这里仅列出在 VehicleID数据的效果,其他数据集的结果对比参见论文.
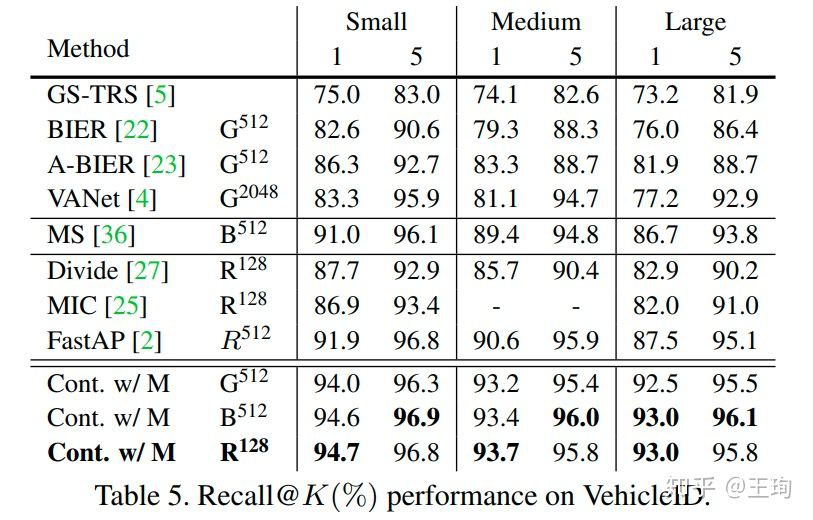
简单来说,不同于部分文章会用更好的网络结构,更大的嵌入维度或者更大的mini-batch来提升效果,强行SOTA,我们列出了XBM在64的mini-batch,不同的主干网络下,各种维度下的效果,公平对比,XBM的效果一直是最棒的,而且好出一大截.
5. 可视化

更多好看的示例图片,可以去论文补充材料里发现呀.
6. 总结与展望
[1] - 本文的XBM,记住过去的特征,使得模型的训练不再仅仅依靠当前mini-batch的样本,而是可以跨越时空,进行样本配对. 从而用极小的代价,提供巨量的样本对,为pair-based的深度度量学习方法插上了腾飞的翅膀. 这种提升难例挖掘的方式,也是突破了过去的难例挖掘的两个套路:加权和聚类. 方法也是更加直接暴力,效果拔群,我觉得这种做法命中了深度度量学习的要害.
[2] - 其实Memory机制并不是本文原创,但是用Memory来做深度度量学习的难例挖掘,据我所知,我们是第一个. 同时期的CVPR-2020由FAIR团队(何恺明等)提出的MoCo也是这种思路,虽然恺明把他的方法称为动态字典. 本文的方法是MoCo在m=0的特例,恺明通过动量更新key encoder,可以直接控制住特征偏移. 我们认为,这种方法还会在很多任务(比如few-shot learning等)带来较大的性能提升,不局限于MoCo的自监督学习和XBM的度量学习(或者称为监督表示学习).
[3] - 在本文中,虽然XBM在所有的pair-based的方法都有提升,但是明显在contrastive loss(对比损失)上提升格外大. 这个原因我们暂时不清楚,正在进一步探索. 另外,我们也把在无监督表示上表现很好的infoNCE方法在深度度量学习数据上进行了初步尝试,发现效果还是没有contrastive loss 好的,这个也需要进一步探索原因. 我认为这两个问题的答案是同一个,而且会非常有意思.