From: 时序时空数据库 TSDB - 产品文档
更新时间: 2018-10-15 09:00:09
时序时空数据库(Time Series & Spatial Temporal Database,简称 TSDB)是一种高性能、低成本、稳定可靠的在线时序时空数据库服务,提供高效读写、高压缩比存储、时序数据插值及聚合计算等服务,广泛应用于物联网(IoT)设备监控系统、企业能源管理系统(EMS)、生产安全监控系统和电力检测系统等行业场景;除此以外,还提供时空场景的查询和分析的能力.
TSDB 具备秒级写入百万级时序数据的性能,提供高压缩比低成本存储、预降采样、插值、多维聚合计算、可视化查询结果等功能,解决由设备采集点数量巨大、数据采集频率高造成的存储成本高、写入和查询分析效率低的问题.
1. TSDB 应用场景
更新时间:2019-01-24 15:08:23
1.1. 物联网设备监控分析
物联网设备无时无刻不在产生海量的设备状态数据和业务消息数据,这些数据有助于进行设备监控、业务分析预测和故障诊断.
设备将原始数据通过 MQTT 协议发送到物联网套件,经由物联网套件将数据转发到消息服务系统,继而通过流计算系统对这些数据进行实时计算处理后写入到 TSDB 中存储,或者经由物联网套件直接将原始数据写入 TSDB 中存储. 前端的监控系统和大数据处理系统会利用 TSDB 的数据查询和计算分析能力进行业务监控和分析结果的实时展现.
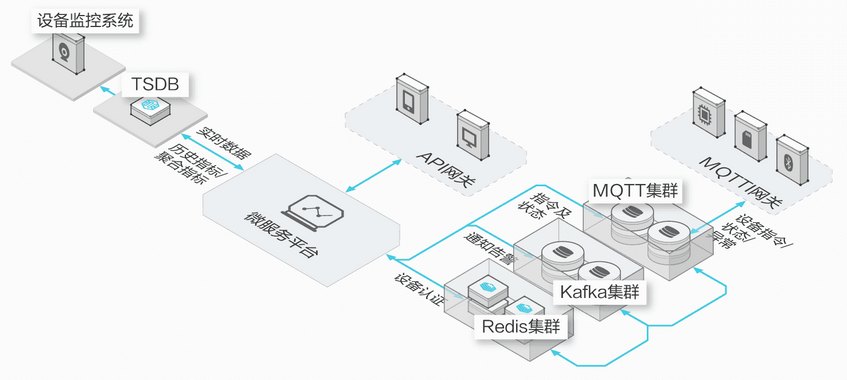
1.2. 电力化工及工业制造监控分析
传统电力化工以及工业制造行业需要通过实时的监控系统进行设备状态检测,故障发现以及业务趋势分析.
设备通过工业接口协议将自身状态数据和生产业务数据接入工业设备网关,然后通过 MQTT 协议发送到物联网套件,继而传输到云上的消息服务系统并经过流计算系统处理后写入 TSDB,完成时序数据的存储和分析.
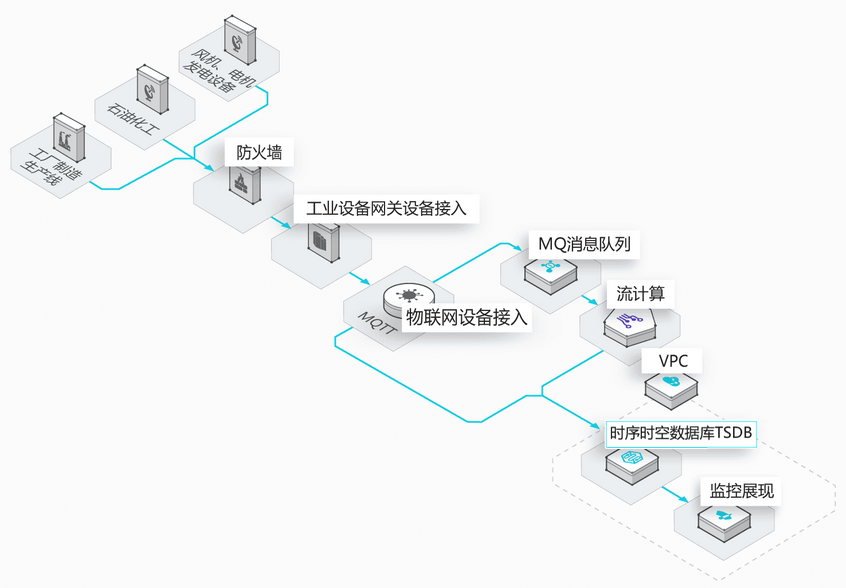
1.3. 系统运维和业务实时监控
通过对大规模应用集群和机房设备的监控,实时关注设备运行状态、资源利用率和业务趋势,实现数据化运营和自动化开发运维.
通过日志或者其他方式对原始指标数据进行采集和实时计算,最后将实时计算的结果数据存储到 TSDB,实现监控和分析的展现.

1.4. 物联网设备数据上云存储
From: 物联网设备数据上云存储 - 阿里云最佳实践
更新时间:2019-03-06 22:08:40
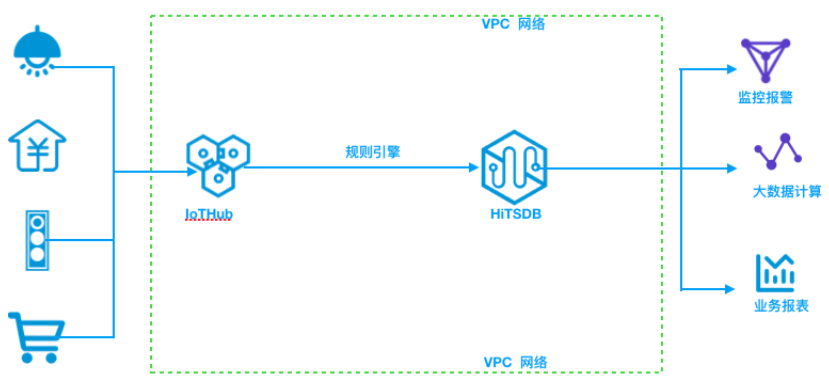
“物联网套件+TSDB”是经典的物联网平台方案.
使用阿里云物联网套件和 TSDB 进行数据打通, 实现物联网设备系统的开发和管理、数据采集、数据上报、数据存储和分析的一体化方案, 构建智能物联网平台. 架构参考:
“物联网套件+TSDB”方案的实现架构如下:
[1] - 物联网设备通过 IoT 套件设备连接管理.
[2] - 设备数据通过规则引擎的无缝路由传到 TSDB 时序数据库.
[3] - 业务基于 TSDB 进行数据分析、监控和大数据分析.
2. TSDB 产品功能
2.1. 时序数据高效读写
TSDB 提供时序数据的高效读写. 对于百万数据点的读取,响应时间小于 5 秒,且最高可以支撑每秒千万数据点的写入.
[1] - 数据写入
TSDB 支持通过 HTTP 协议 和 TSDB Java Client 两种方式进行数据写入.
[2] - 数据查询
TSDB 支持通过 HTTP 协议、TSDB Java Client 以及 TSDB 控制台三种方式进行数据的查询操作. 用户也可以通过 TSDB 产品控制台的数据查询功能进行数据分组、降采样、空间聚合的可视化数据查询展现.
2.2. 数据管理
[1] - 数据时效设置
可以通过控制台或者 API 设置数据的有效期. 数据时效开启并设置完成后,系统对于定义的过期数据将立即标记失效,并在特定时间进行自动化清理.
[2] - 数据清理
可以在控制台上根据度量(Metric)进行数据清理,或者通过 API 进行更灵活的数据清理.
2.3. 高效压缩存储
TSDB 使用高效的数据压缩技术,将单个数据点的平均使用存储空间降为1~2个字节,可以降低90%存储使用空间,同时加快数据写入的速度.
2.4. 时序数据计算能力
TSDB 使用高效的数据压缩技术,将单个数据点的平均使用存储空间降为1~2个字节,可以降低90%存储使用空间,同时加快数据写入的速度.
2.5. 监控运维
TSDB 提供实例运维系统,可以实时的掌握实例的运行情况、性能指标和存储空间使用情况,并通过设置报警通道,实时发现资源瓶颈.
2.6. 数据和实例安全
TSDB 提供以下方案保证您的数据和实例的安全:
[1] - 提供 VPC 的实例访问方式,充分保证实例访问的安全性.
[2] - 提供网络白名单功能:可以通过设置允许访问实例的机器名单,进一步保证实例和数据的访问安全. 如果一台机器在 VPC 内部,但不在设置的白名单内,则不能访问实例.
[3] - TSDB 的数据存储默认采取三副本策略,充分保证数据的可用性.
2.7. 流计算支持
TSDB 已与阿里云流计算(StreamCompute)产品集成. 详细的集成说明请参见阿里云创建 TSDB 结果表.
2.8. 产品优势
[1] - 性能卓越
具有高效的读写能力,相比较开源的 OpenTSDB 和 InfluxDB,读写效率提升数倍.
[2] - 存储成本低
基于高效压缩算法有效压缩原始数据,最多可节约 90% 的存储空间.
[3] - 使用简单
兼容 OpenTSDB 的数据访问协议,开发简单.
控制台提供丰富的数据管理和运维功能,操作简单便捷,轻松完成日常数据管控和运维.
[4] - 专业运维支持
TSDB 的研发团队具备全球一流的数据库专家,提供专业技术支持.
提供专业的监控和报警系统,快速具备运维能力.
3. 阿里云 TSDB 名词解释
[1] - 时序数据库 TSDB :英文全称为 Time Series Database,提供高效存取时序数据和统计分析功能的数据管理系统.
[2] - 时序数据(Time Series Data):基于稳定频率持续产生的一系列指标监测数据. 例如,监测某城市的空气质量时,每秒采集一个二氧化硫浓度的值而产生的一系列数据.
[3] - 度量(Metric):监测数据的指标,例如风力和温度.
[4] - 标签(Tag):度量(Metric)虽然指明了要监测的指标项,但没有指明要针对什么对象的该指标项进行监测. 标签(Tag)就是用于表明指标项监测针对的具体对象,属于指定度量下的数据子类别.
一个标签(Tag)由一个标签键(TagKey)和一个对应的标签值(TagValue)组成,例如“城市(TagKey)= 杭州(TagValue)”就是一个标签(Tag). 更多标签示例:机房 = A 、IP = 172.220.110.1.
注意:当标签键和标签值都相同才算同一个标签;标签键相同,标签值不同,则不是同一个标签.
在监测数据的时候,指定度量是“气温”,标签是“城市 = 杭州”,则监测的就是杭州市的气温.
[5] - 标签键(TagKey,Tagk):为指标项(Metric)监测指定的对象类型(会有对应的标签值来定位该对象类型下的具体对象),例如国家、省份、城市、机房、IP 等.
[6] - 标签值(TagValue,Tagv):标签键(TagKey)对应的值. 例如,当标签键(TagKey)是“国家”时,可指定标签值(TagValue)为“中国”.
[7] - 值(Value):度量对应的值,例如 15 级(风力)和 20 ℃(温度).
[8] - 时间戳(Timestamp):数据(度量值)产生的时间点.
[9] - 数据点 (Data Point):针对监测对象的某项指标(由度量和标签定义)按特定时间间隔(连续的时间戳)采集的每个度量值就是一个数据点. “一个度量 + N 个标签(N >= 1)+ 一个时间戳 + 一个值”定义一个数据点.
[10] - 时间序列(Time Series):针对某个监测对象的某项指标(由度量和标签定义)的描述. “一个度量 + N 个标签KV组合(N >= 1)”定义为一个时间序列,某个时间序列上产生的数据值的增加,不会导致时间序列的增加. 时间序列的示意图如下:
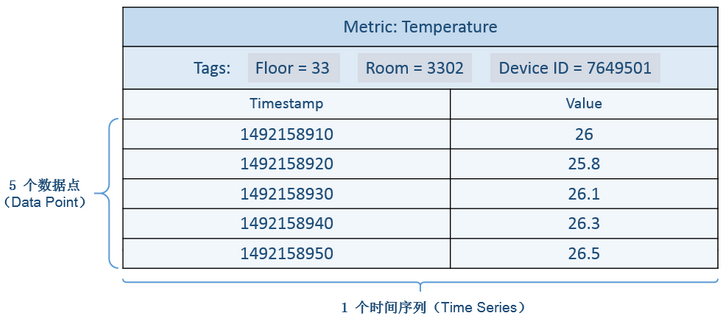
[11] - 时间线(Timeline):等同于时间序列的概念.
[12] - 时间精度:时间线数据的写入时间精度——毫秒、秒、分钟、小时或者其他稳定时间频度. 例如,每秒一个温度数据的采集频度,每 5 分钟一个负载数据的采集频度.
[13] - 数据组(Data Group):如果需要对比不同监测对象(由标签定义)的同一指标(由度量定义)的数据,可以按标签这些数据分成不同的数据组. 例如,将温度指标数据按照不同城市进行分组查询,操作类似于该 SQL 语句:select temperature from xxx group by city where city in (shanghai, hangzhou).
[14] - 聚合( Aggregation):当同一个度量(Metric)的查询有多条时间线产生(多个指标采集设备),那么为了将空间的多维数据展现为成同一条时间线,需要进行合并计算,例如,当选定了某个城市某个城区的污染指数时,通常将各个环境监测点的指标数据平均值作为最终区域的指标数据,这个计算过程就是空间聚合.
[15] - 降采样(Downsampling):当查询的时间区间跨度较长而原始数据时间精度较细时,为了满足业务需求的场景、提升查询效率,就会降低数据的查询展现精度,这就叫做降采样,比如按秒采集一年的数据,按照天级别查询展现.
[16] - 数据时效(Data’s Validity Period):数据时效是设置的数据的实际有效期,超过有效期的数据会被自动释放.
4. 阿里云 TSDB 相比OpenTSDB优势
From 相比OpenTSDB优势 - 阿里云
OpenTSDB 是可扩展的分布式时序数据库,底层依赖HBase. 作为基于通用存储开发的时序数据库典型代表,起步比较早,在时序市场的认可度相对较高.
阿里云智能TSDB高度兼容OpenTSDB协议,采用自研的索引,数据模型,流式聚合等技术手段提供更强大的时序能力. 本文从运维管控,功能,成本,性能等方面对比阿里云智能TSDB和OpenTSDB的优势.
4.1. 分类对比
| OpenTSDB | TSDB | ||
|---|---|---|---|
| 运维管控 | 服务可用性 | 需自行保障,自行搭建集群,自建组件依赖 | 99.9% |
| 数据可靠性 | 需自行保障,自行搭建集群,自建组件依赖 | 99.9999% | |
| 软硬件投入 | 数据库服务器成本相对较高 | 无软硬件投入,按需付费 | |
| 维护成本 | 需招聘专职TSDB DBA人员来维护,花费大量人力成本 | 无需运维 | |
| 部署扩容 | 需硬件采购、机房托管、机器部署等工作,周期较长 | 即时开通,快速部署,弹性扩容 | |
| 依赖组件繁重, | 依赖AysncHBase,HBase等运维成本高 | 运维托管,无需组件运维 | |
| 配置调优参数繁多 | SALT、连接数,同步刷盘参数,Compaction等等 | 默认参数采用最佳实践 | |
| 建表语句 | 需要运维静态建表语句 | 建表语句托管,用户透明 | |
| 监控报警体系 | 依赖外部搭建 | 完整的自监控链路 | |
| 功能 | 数据模型 | 单值模型 | 同时支持多值模型和单值模型 |
| SDK | 开源SDK不支持查询 | 健壮稳定的Java SDK | |
| 数据类型多样性 | 数值类型 | 支持数值,布尔,字符串等多种数据类型 | |
| SQL查询能力 | 不具备 | 支持SQL的分析查询 | |
| 管理控制台 | 内置简单的图形展示 | 支持丰富的详情展示,数据管理,时序洞察等 | |
| 中文支持 | 仅支持英文字符 | 支持英文字符和中文字符 | |
| 单一维度(tags 可选择) | tags是必选参数 | tags是可选参数 | |
| TagKey个数 | 最多8个 | 可支持16个 | |
| 集成能力 | 开源产品,与云产品集成能力弱 | 同Flink,物联网平台无缝对接,生态丰富 | |
| 成本 | 数据压缩 | 通用压缩,压缩率低 | 时序领域专用压缩,压缩率高 |
| 稳定性 | 数据读取 | 读写耦合,容易造成连接数耗尽,读写失败概率大 | 读写线程池分离,易于管理连接,读写稳健 |
| 聚合器 | 内存物化聚合,容易造内存OOM | 流式聚合,内存管理粒度细,可控性强 |
4.2. OpenTSDB协议兼容性
由于阿里云TSDB底层技术架构同OpenTSDB的实现区别巨大,对于OpenTSDB的一些运维接口不会兼容. 比如OpenTSDB的元数据管理接口/api/tree, /api/uid等等. 根据OpenTSDB的官网API Endpoints(http://opentsdb.net/docs/build/html/api_http/index.html) ,下表列举了TSDB的兼容程度.
| OpenTSDB 协议API | TSDB是否兼容 |
|---|---|
| /s | 否 |
| /api/aggregators | 是 |
| /api/annotation | 否 |
| /api/config | 是 |
| /api/dropcaches | 否 |
| /api/put | 是 |
| /api/rollup | 否 |
| /api/histogram | 否 |
| /api/query | 是 |
| /api/query/last | 是 |
| /api/search/lookup | 是 |
| /api/serializers | 是 |
| /api/stats | 是 |
| /api/suggest | 是 |
| /api/tree | 否 |
| /api/uid | 否 |
| /api/version | 是 |
除此之外,TSDB提供了一些面向时序更友好的接口. 包括
| TSDB 自定义协议API | 描述 |
|---|---|
| /api/mput | 多值写入 |
| /api/mquery | 多值查询 |
| /api/query/mlast | 多值查询最新数据点 |
| /api/dump_meta | 查询 Tagk 下的 Tagv |
| /api/ttl | 设置数据时效 |
| /api/delete_data | 清理数据 |
| /api/delete_meta | 清理时间线 |
2 comments
TDengine 性能更好,集群也开源了
赞!