Github - Proxima Bilin Engine
Docs - Proxima Bilin Engine
Proxima 是阿里巴巴达摩院系统 AI 实验室自研的向量检索内核。目前,其核心能力广泛应用于阿里巴巴和蚂蚁集团内众多业务,如淘宝搜索和推荐、蚂蚁人脸支付、优酷视频搜索、阿里妈妈广告检索等。同时,Proxima 还深度集成在各式各类的大数据和数据库产品中,如阿里云 Hologres、搜索引擎 Elastic Search 和 ZSearch、离线引擎 MaxCompute (ODPS) 等,为其提供向量检索的能力。
ProximaBE,全称 Proxima Bilin Engine,是 Proxima 团队开发的服务化引擎,实现了对大数据的高性能相似性搜索,支持流式 CRUD,支持 RESTful API,支持 GPRC 协议,支持数据库全量和增量同步。
核心能力
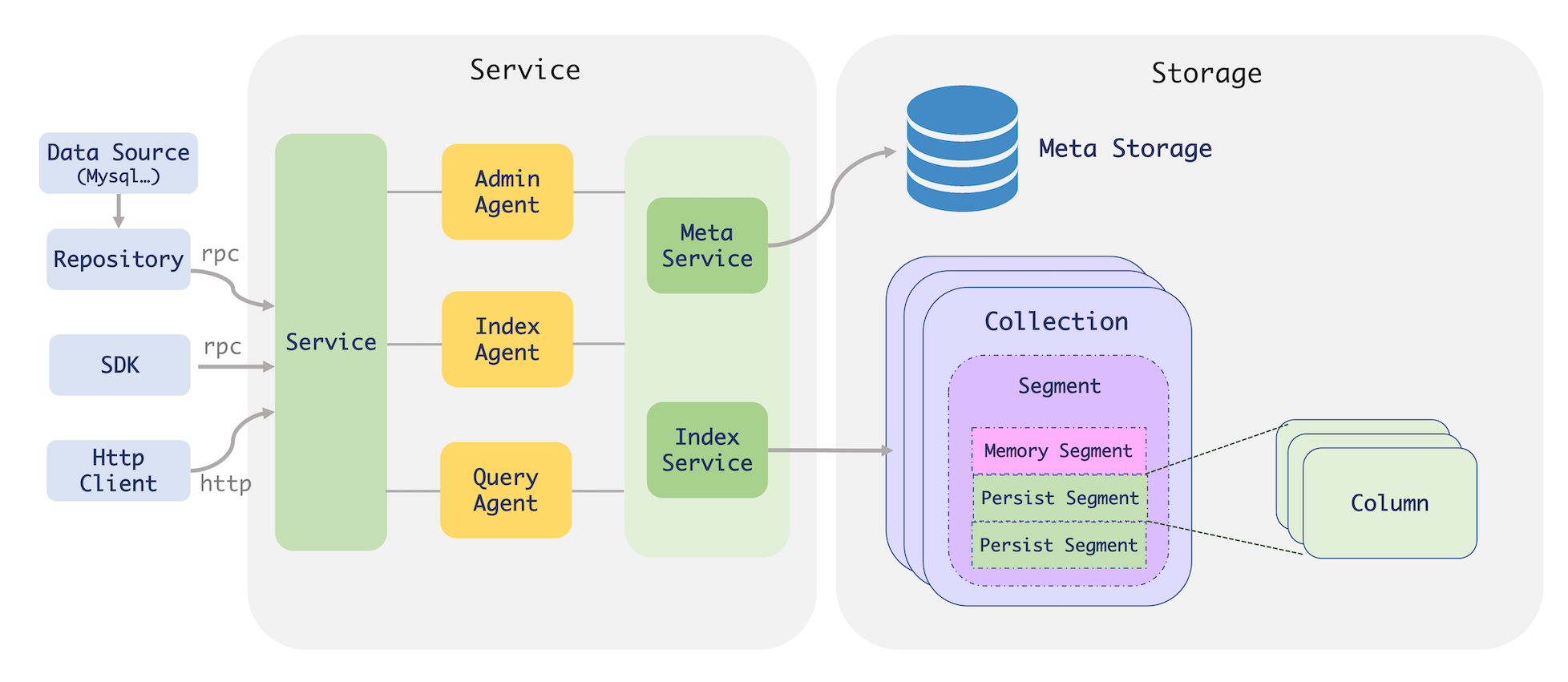
Proxima BE 的主要核心能力有以下几点:
- 支持单机超大规模索引:基于底层向量索引的工程和检索算法优化,使得有限成本下,实现了高效率的检索方法,并支持磁盘索引,单片索引可达几十亿的规模。
- 支持多数据源全量和增量同步:通过 Mysql Repository 等组件,可将 mysql 等数据源中的数据,实时同步至索引服务,提供查询能力,简化数据处理流程。
- 支持向量索引实时增删改查:基于全新 CRUD 图索引,支持在线大规模向量索引的从 0 到 1 的流式写入,并实现了索引即时增删改查,避免索引需定期重建。
- 支持正排数据查询:支持在查询时,可展示文档的所有结构化字段。同时后期将基于此功能,进一步扩展出与文本与向量联合检索等功能。
设计架构
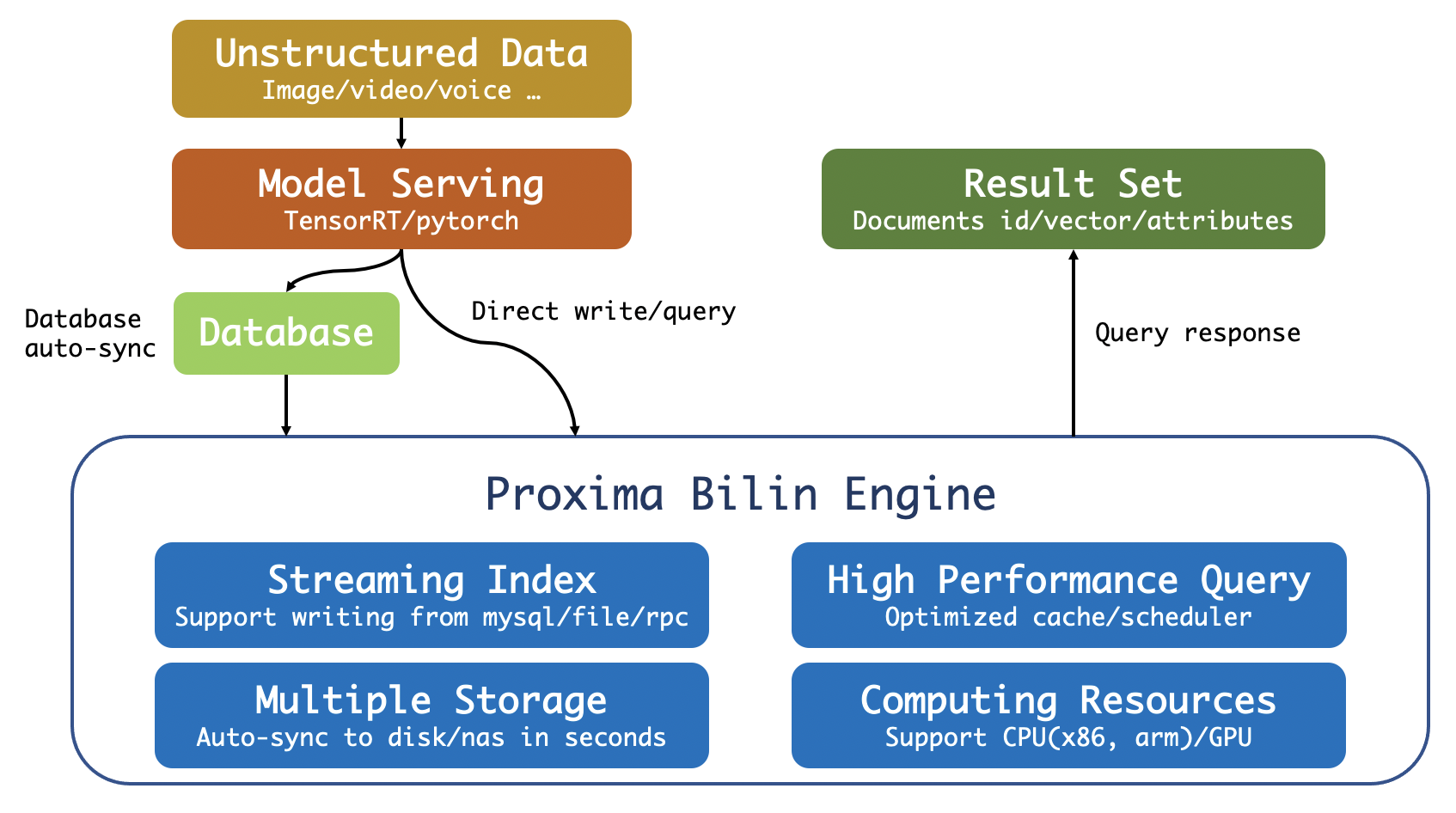
ProximaBE 定位为数据旁路的云原生向量检索服务引擎,其角色为计算节点或缓存服务,同时也支持独立部署以及服务能力。核心功能点包括:
- 支持高性能实时向量增删查改;
- 支持多数据源全量和增量同步;
- 支持正排数据查询;
- 支持多表隔离和查询;
- 支持索引多分片查询;
基础概念
ProximaBE 中定义了集合(Collection),文档(Document), 索引(Index), 正排(Forward)等基础概念,以上概念与传统数据库概念对比可以参考下图:
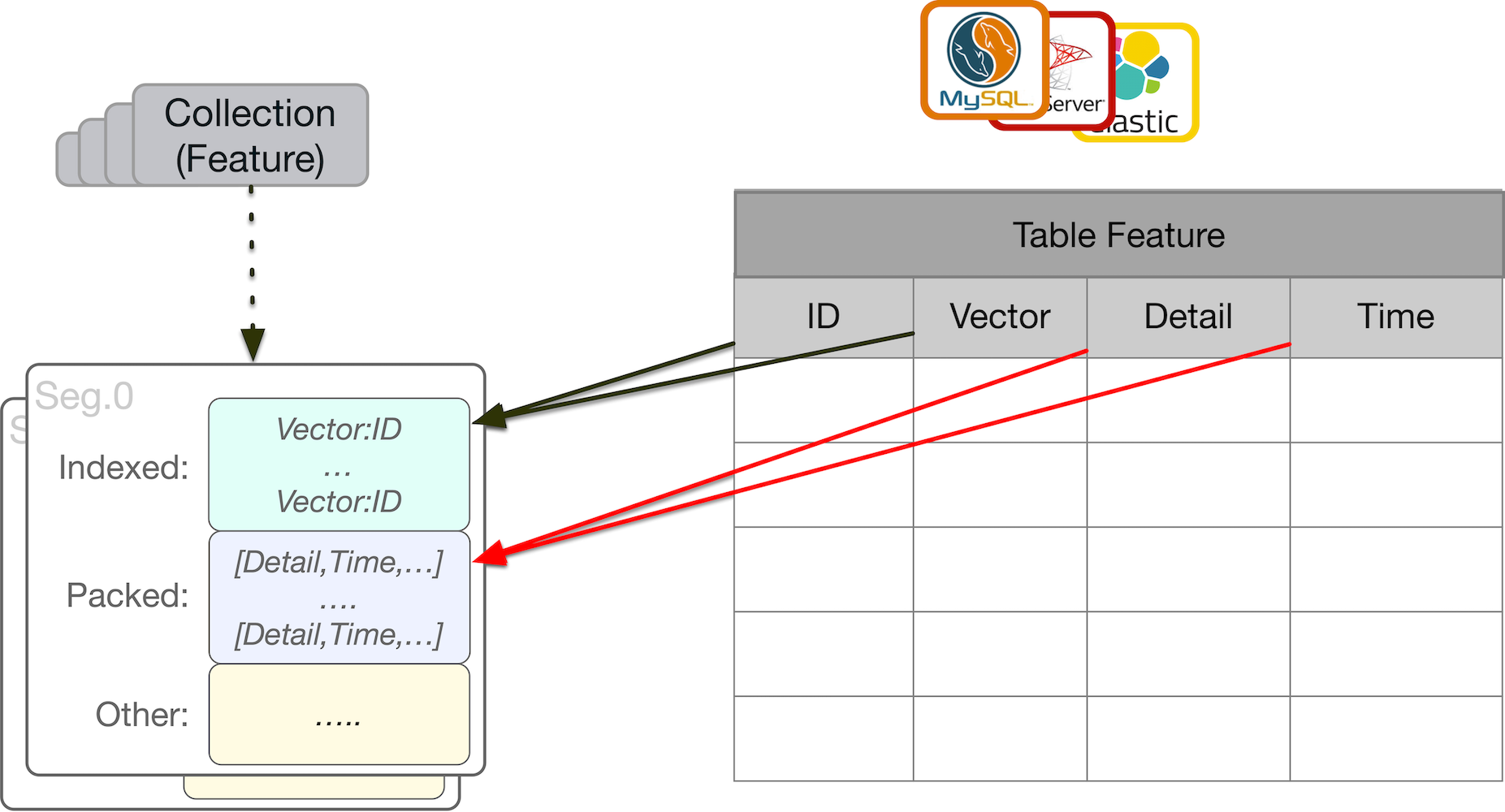
如上图所示, 集合与数据库中的 Table 是映射关系,索引(Index)映射数据库表中的某列数据,属性(Forward)映射为数据库表中的多列数据。
集合(Collection) : 集合用于描述用户具有相同数据结构的文档集合,它对应数据库中的表概念。
文档(Document) : 文档用于描述用户结构化数据,它包含基本的一些存储数据元,一个文档可包含多个索引列,以及属性列。
索引(Index) : 用于描述一个文档中需要被建立索引的列数据,该字段为查询接口的主要计算单元,用户加快计算过程。
正排(Forward) : 只存储需要与文档关联的一些属性列,该字段不参与查询时的逻辑计算,只用于数据展示。文档中可包含多个属性列,并且存储时多字段合并后压缩存储。
名词解释
| 名词 | 解释 |
|---|---|
| 向量检索 | 向量是一种将实体代数化的表示,如同数学空间中的坐标,标识着各个实体,其将实体间的关系抽象成向量空间中的距离,而距离的远近代表着相似程度。向量检索便是对这类结构化的数据进行快速搜索和匹配的方法。 |
| KNN | KNN,全称 K-Nearest Neighbor,查找离查询点最近的 K 个点。 |
| RNN | RNN,全称 Radius Nearest Neighbor,查找查询点某半径范围内的所有点或 K 个点。 |
| ANN | ANN,全称 Approximate Nearest Neighbor。在涉及到大数据量的情况下,百分之百准确求解 KNN 或 RNN 问题的计算成本较高,于是引入了求近似性解的方法,尽可能地或按概率的方式满足检索需求,因此大数据量检索实际要解决的是 ANN 的问题。 |
| KNN Graph | 一种索引方法,预先建立好向量之间的邻居关系,形成 Graph 的索引结构。检索时,通过在图上的游走遍历获取最终的 KNN 结果。 |
| 量化 | 量化,将连续值(或者大量的离散取值)近似为有限多个(或较少的)离散值的过程。例如,聚类便是一种量化方法。量化索引是指利用量化方法构建和检索的索引方法,特征量化则是指对向量特征本身进行数值变化。 |