阿里云 Elasticsearch 目前是公有云营收增长最快的大数据产品之一. 随着客户数的增长,以及AI技术的不断普及,针对向量检索场景的需求量在逐步提升. 从人脸识别、音/视频识别到商品智能推荐等场景,技术上都离不开向量检索的能力作为支撑.
以某专有云客户为例,客户的场景是视频安全监控,摄像头每天会产生500万帧采样图片,每个月产生TB级的向量数据,业务上需要实时对这些视频采样数据进行图片比对搜索. 该客户属于典型的时序+向量检索的场景,而时序分析场景刚好是 Elasticsearch 最擅长的部分,那么能否在Elasticsearch现有能力的基础上补充向量检索的支持能力呢?
基于这个朴素的想法,开始了与阿里巴巴达摩院向量检索团队的合作,希望借助达摩院自研的向量检索引擎补充阿里云 Elasticsearch 在向量检索方面的能力,一站式解决云上用户全文检索、时序分析及向量检索的需求.
阿里云 Elasticsearch 始终致力于为云上用户提供一站式的高性能、低成本的大数据检索分析服务. 向量检索引擎是在人工智能领域迈出的第一步,后续的发力点还有很多,比如支持更丰富的近似算法、支持离线训练、硬件加速等,有很多有意思的方向等待进一步探索.
目前商业版的6.7和7.4版本,可以使用向量检索
1. Proxima 向量检索
简单介绍一下阿里云 Elasticsearch 使用的 Proxima 向量引擎库:阿里巴巴达摩院提供的 Proxima 向量检索引擎是一个运用于大数据下,实现向量近邻搜索的高性能软件库,能够提供业内性能和效果领先的基础方法模块,支持图像搜索、视频指纹、人脸识别、语音识别和商品推荐等各种场景. 同时,引擎对向量检索的一些基础能力,如聚类、距离计算、高并发、Cache 等做了深层次的优化.
目前 Proxima 向量检索库在阿里集团覆盖的生产业务如图所示:
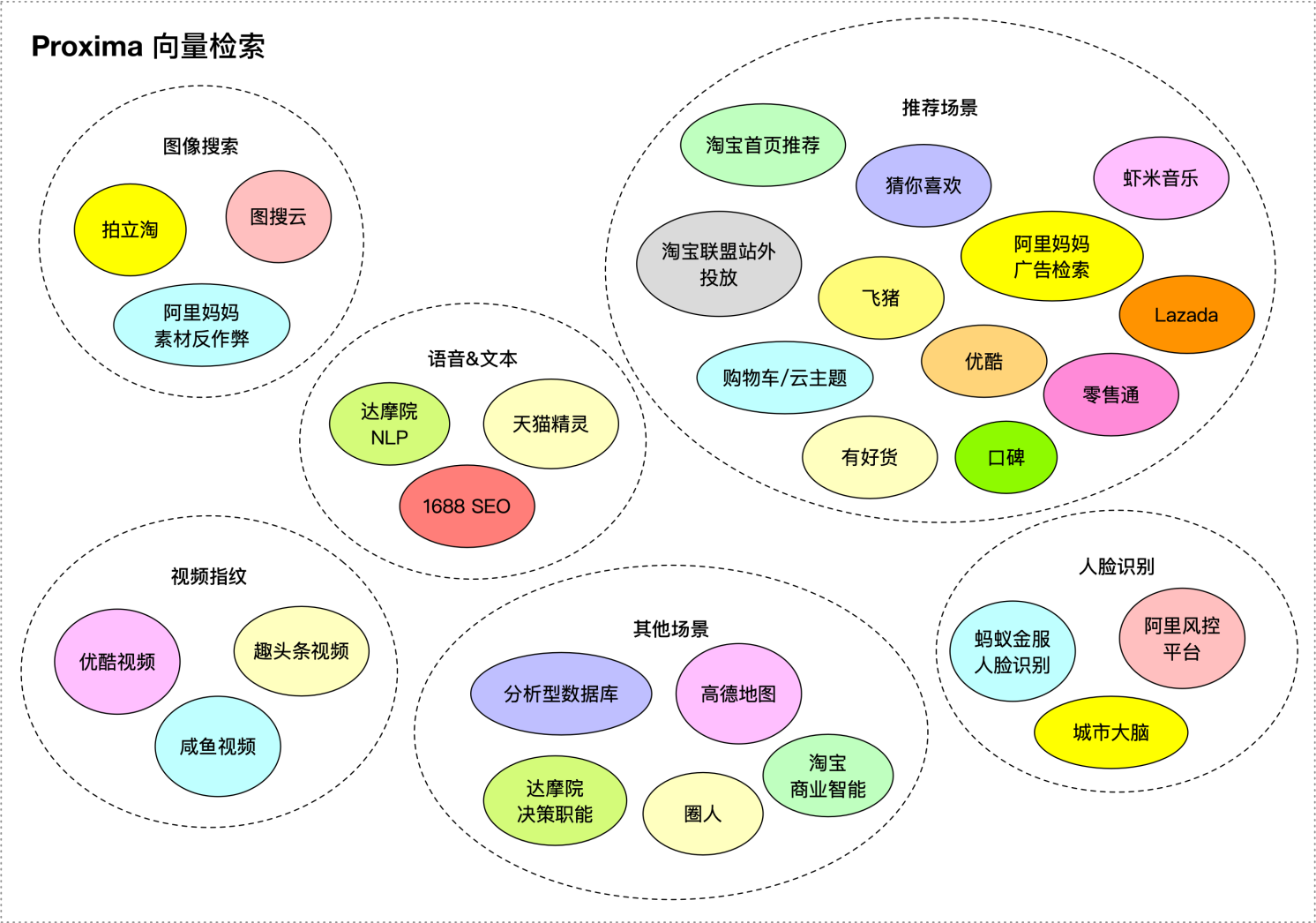
2. 优选在线方案
如何将 Proxima 引擎库集成到阿里云 Elasticsearch 生态中,有两个方向摆在眼前:
[1] - 一种是最直观也是最简单的离线方案,也是集团内其它团队大部分采用的方案,依赖独立的离线资源做索引全量 Build;
[2] - 另一种是在线方案,也是无缝对接 Elasticsearch 现有能力、易用性最好的方案,但写入性能和存储相对会有一些Overhead.
两种方案优劣势对比如下:

考虑到云上客户大多数对弹性和稳定性要求比较高,最终选择了易用性、稳定性更好的在线方案.
3. 详解设计方案
在确定在线方案的前提下,如何能满足 Proxima 向量索引和 Elasticsearch 原生索引无缝集成呢?答案是利用 Lucene的 Codec 扩展机制.
Codec 可以理解为 Lucene 索引文件格式的一种协议,用户只要实现对应的写入/读取的业务流程,即可自定义正排、倒排、StoreFields 等不同索引的具体实现. 在阿里云 Elasticsearch 的实现中,包装并扩展了Lucene 的 Latest Codec,当向量数据写入es的某个字段时,前期流程跟原生的流程一致,先放入 indexBuffer 中;等内部发起 Refresh 时,调用底层的 Proxima 库,消费向量数据构建出 Proxima 的向量索引.
查询的时候,由于向量索引和原生索引一样都是 Segment 粒度生成,所以只要很轻量的实现向量 Segment 对应的 Weight 和 Scorer即可. 具体的,当查询到了 BuildScorer 阶段,利用底层 Proxima 库加载当前 Segment的向量索引文件,通过 Native 方法查询出TopN的 id 和 Score 后,通过docID和分数生成当前 Segment 的 Scorer,交给indexSearcher继续执行上层的求交/求并操作即可.
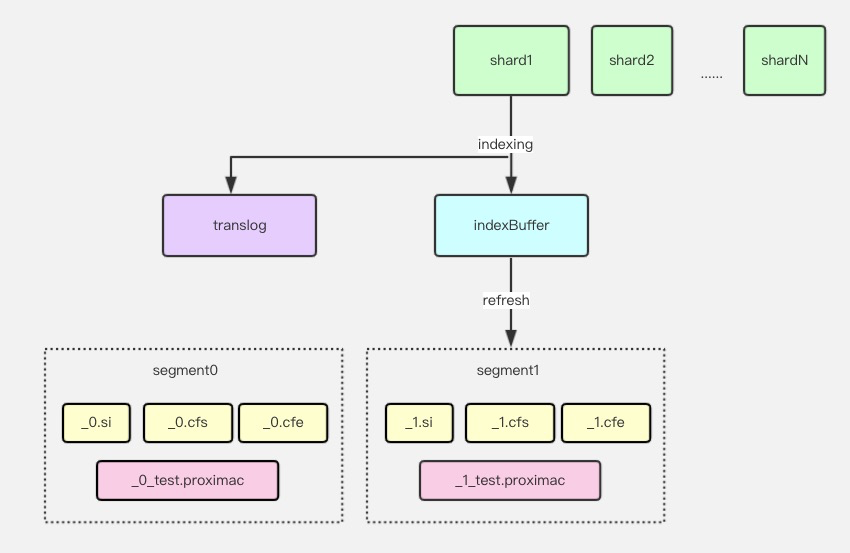
基于 Codec 机制,向量索引已经可以被 Lucene 当成普通索引来管理,这对上层的 Elasticsearch 来说是完全透明的,所以可以实现不修改上层业务的前提下,兼容 Elasticsearch 所有上层的分布式文件操作;所有扩副本、本地 Failover 、阿里云快照备份/恢复等功能都与原生普通索引无异. 因此大大提高了索引的稳定性,降低了用户的使用成本.
4. 性能与效果评测
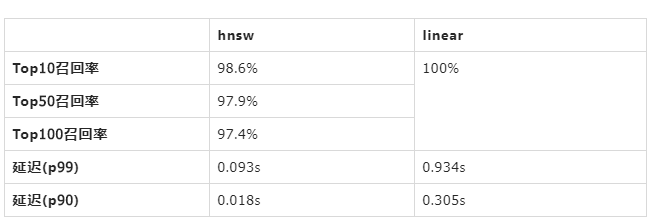
以下是阿里云Elasticsearch 6.7.0版本环境实测数据,机器配置为数据节点16c64g*2 + 100G ssd云盘,数据集为Sift128维 Float 向量(http://corpus-texmex.irisa.fr/),数据总量为2千万. 索引配置全部是默认参数.
5. 使用说明
5.1. 创建索引
PUT test
{
"settings": {
"index.codec": "proxima",
"index.vector.algorithm": "hnsw" # 可选值: hnsw/linear
},
"mappings": {
"_doc": {
"properties": {
"feature": {
"type": "proxima_vector", # 向量字段
"dim": 2 # 向量维度,支持1~2048维
},
"id": {
"type": "keyword"
}
}
}
}
}5.2. 添加文档
POST test/_doc
{
"feature": [1.0, 2.0], # float数组,数组长度必须与mapping指定的dim保持一致
"id": 1
}5.3. 检索
GET test/_search
{
"query": {
"hnsw": { # 与创建索引时指定的algorithm一致
"feature": {
"vector": [1.5, 2.5], # float数组,数组长度必须与mapping指定的dim保持一致
"size": 10 # 指定召回的topN
}
}
}
}