From: 百度云 - 时序数据库 TSDB
更新时间:2019-04-12
百度智能云时序数据库(Time Series Database,简称TSDB)是一种存储和管理时间序列数据的专业化数据库,为时间序列的存储提供高性能读写、低成本存储、强计算能力和多生态支持的多种能力.
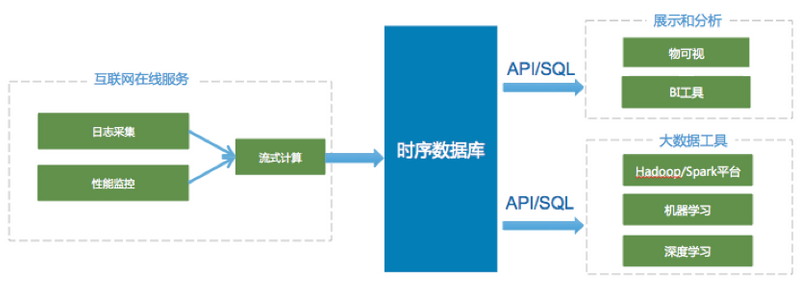
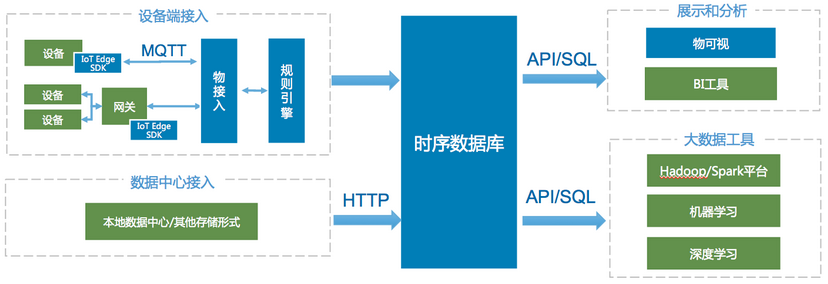
在物联网场景下,TSDB有广泛的应用. 如工业生产环境下,每个厂区有大量的监测点,如果以10秒的频率发送数据. 50万监测点每年会产生1.58万亿左右数据点. TSDB不仅可以轻松存储海量数据点,还可以对这些数据进行快速查询并做可视化展示,帮助企业管理者分析数据. 典型的物联网场景下,数据从端侧到云端的数据流如下所示.
1. TSDB 功能
1.1. 数据读写
[1] - 数据写入
支持Restful API方式高并发写入数据;支持物联网设备通过规则引擎写入数据,可以支撑每秒千万级数据点写入,并可线性扩展.
[2] - 数据查询
支持通过Restful API和控制台来查询数据,可以对数据进行标签过滤、值过滤、分组等查询,并可以支持控制台可视化展示.
1.2. 时间序列数据管理
[1] - 数据管理
支持时间序列数据的写入、查询和删除
[2] - 数据时效
可以开启数据时效,系统可以自动清除不在有效期内的数据
[3] - 数据导入导出
提供数据导入导出接口
1.3. 数据计算
[1] - 插值查询
提供插值查询能力,将未上传的数据补齐,并支持多种插值算法
[2] - 聚合计算
提供AVG、SUM、MAX等15种聚合函数,可以将数据降精度聚合,并支持嵌套聚合
[3] - 预处理
提供对数据的预处理能力,可将相关数据提前过滤和聚合,实现快速返回查询结果
1.4. 压缩存储
采用高效压缩算法,可达10-20倍压缩率,大大降低存储成本.
1.5. 数据库管理
实时监控,提供对数据库的写入、读取状态进行实时监控
1.6. 示范数据
提供示范数据,帮助用户体验时序数据库的各项功能
1.7. TSDB 优势
[1] - 高性能读写
每秒千万级数据点写入,亿级数据点聚合结果秒级返回
[2] - 低成本存储
高效压缩算法,大大节省存储空间
[3] - 强计算能力
提供插值、预处理等多种计算方式;支持15种聚合函数
[4] - 多生态支持
支持SQL查询、主流Hadoop/spark等大数据分析平台、多种可视化工具
[5] - 高可靠服务
三副本、分布式部署,保证数据可靠性
2. TSDB 名词解释
[1] - TSDB :Time Series Database,时序数据库,用于保存时间序列(按时间顺序变化)的海量数据.
[2] - 度量(metric):数据指标的类别,如发动机的温度、发动机转速、模拟量等.
[3] - 域(field):在指定度量下数据的子类别. 即一个metric支持多个field,如metric为wind,该metric可以有两个field:direction和speed.
[4] - 时间戳(timestamp):数据产生的时间点.
[5] - 数值(value):度量对应的数值,如56°C、1000r/s等(实际中不带单位). 如果有多个field,每个field都有相应的value. 不同的field支持不同的数据类型写入. 对于同一个field,如果写入了某个数据类型的value之后,相同的field不允许写入其他数据类型.
[6] - 标签(tag):一个标签是一个key-value对,用于提供额外的信息,如"设备号=95D8-7913"、“型号=ABC123”、“出厂编号=1234567890”等.
[7] - 数据点(data point):“1个metric+1个field(可选)+1个timestamp+1个value + n个tag(n>=1)”唯一定义了一个数据点. 当写入的metric、field、timestamp、n个tag都相同时,后写入的value会覆盖先写入的value.
[8] - 时间序列 :“1个metric+1个field(可选) +n个tag(n>=1)”定义了一个时间序列. (单域和多域的数据点和时间序列如2.1. 单域和多域的数据点和时间序列中的例示.)
[9] - 分组(group):可以按标签(tag)对数据点进行分组.
[10] - 聚合函数(aggregator):可以对一段时间的数据点做聚合,如每10分钟的和值、平均值、最大值、最小值等. TSDB目前支持的聚合函数请参考文档
[11] - 数据库(database):一个用户可以有多个数据库,一个数据库可以写入多个“度量”的“数据点”.
2.1. 单域和多域的数据点和时间序列示例
2.1.1. 单域
监测温度的值,把温度(temperature)作为一个度量(metric),用标签(tag)来标识每一个数据的额外信息,比如每个数据点都有3个tag,tag是一个key-value对,tag 的 key 分别是deivceID、floor、room.
如图所示,表示对温度的时间序列监测值,共4个数据点. 在该图中的4个数据点使用的metric、tag是相同的,所以是同一个时间序列.

2.1.2. 多域
监测风力的值,把风力(wind)作为一个度量(metric),风力(wind)分为两个域:风向(direction)和速度(speed). 这些监测数据是从不同的传感器传输到云端的,用标签(tag)来标识每一个数据的额外信息,比如每个数据点有三个tag,tag是一个key-value对;tag的key分别是sensor、city、province.
为了表示在广东省深圳市传感器编号95D8-7913上传风向(direction)数据,可以将这个数据点的tag为标记为sensor=95D8-7913、city=深圳、province=广东.
如图,展示了metric为wind的两个域(speed和direction)的监测数据. 当使用的是metric、field和tag是相同的时,是同一个时间序列. 即图中有2个时间序列,8个数据点.
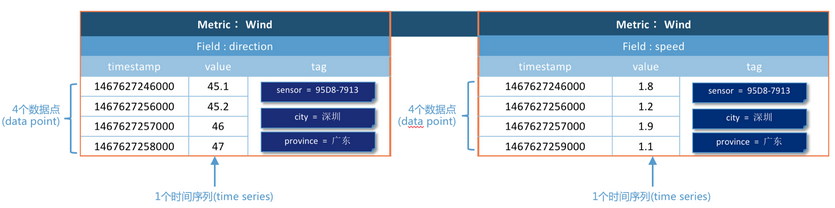
将数据采用metric+field的方式存储的优势在于,可以在同一个时间序列下联合查询. 以上图为例,要查询1467627246000-1467627249000时间内风力(wind)的情况,可以联合查询多个field的值,得到下图的数据.

如果写入时没有数据,在查询时,可以采用插值方案将值补充完整,插值的使用说明见数据库操作相关文档.
- tag的key值和value值都相同才算过同一个tag,即deviceid=1和deviceid=2是两个标签.
- 请不要将时间戳作为tag,否则会导致时间序列超过限制,关于时间序列的限制请参考费率表.
2.2. 数据结构
2.2.1. 单域
采用TSDB提供的示范数据库来举例说明数据结构,请参考示范数据库的操作指南.
示范数据库含有2015年全年北京、上海、广州3个城市多个空气监测站的温度、湿度、风力、PM2.5、紫外线指数等数据(非真实数据),数据来源于每个城市的多个空气监测站.
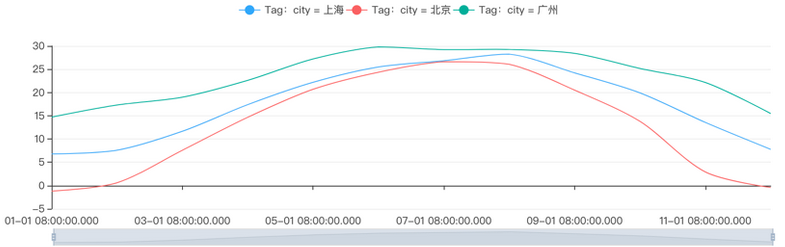
在TSDB中,温度、湿度、风力、PM2.5、紫外线指数都用metric表示,代表监测维度. 不同的城市、不同的空气监测站(用不同的经度和维度表示)则用Tag的方式表示. 拿温度举例,如下图所示.

如果我们希望查看北京、上海、广州在2015年每个月的平均温度,即按照1个月的采样周期进行AVG的聚合,并按照city标签分组. 可以得到以下图表:
更多操作请参见百度云示范数据库的操作指南.
2.2.2. 多域
多域的结构允许在同一个metric下有多个field,比如风力是一个矢量数据,由风速和风向组成,这样适合将风力和风向作为风(metric)的的field存储.
所有查询操作都要先指定metric,如果采用多域的结构,可以在同一个查询中将多个field的值进行过滤,并同时返回多个field.

以上图为例,要查询1467627246000-1467627249000时间内风力(wind)的情况,可以联合查询多个field的值,得到下图的数据.

3. 应用场景
3.1. 物联网设备状态监控存储分析
各种物联网设备通过百度智能云天工物联网平台接入上云,设备的状态数据实时高效写入到时序数据库中. 可以实现:
[1] - 通过时序数据库的数据API接口读取实时数据;
[2] - 利用时序数据库查询快的优势对数据进行各种聚合运算得到数据报表;
[3] - 通过时序数据库的控制台或者物可视直观得到数据的变化趋势和曲线,帮助用户分析数据内涵.
3.2. 互联网业务性能监控服务
互联网服务可以将用户的访问延迟、查询返回效率、业务服务指标监控数据写入时序数据库中,时序数据库可以做多维度的聚合分析和监控项展示. 举个例子,一个音视频点播的服务商,需要将每个房间的清晰度、流畅度、是否卡顿等监控信息实时记录下来,即可以将这些监控项以一定的频率写入时序数据库. 您可以:
- 按照一定的聚合条件得到某一段时间内哪一个运营商的网络更流畅
- 查看过去一天/一周某个房间的流畅度曲线
- 分析同时在线的房间数与房间清晰度、流畅度之间的关系