Loading...
原文:计算机图形学(四)-MVP变换之视图(View)变换 - 2021.08.07作者:点燃火柴 - CSDN1. 视口变换视口变换(Viewport ...
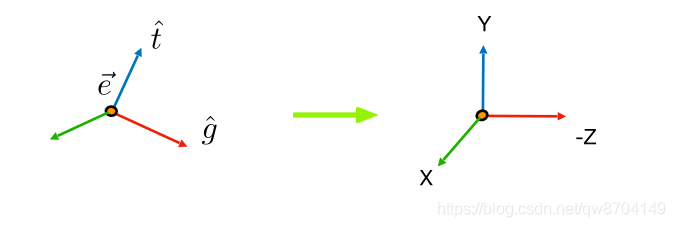
原文:计算机图形学(四)-MVP变换之视图(View)变换 - 2021.07.21作者:点燃火柴 - ...
原文:计算机图形学(五)-MVP变换之投影(Projection)变换 - 2021.07.22作者:点燃火柴 - CSDN1. 投影变换介绍之前已经提到...
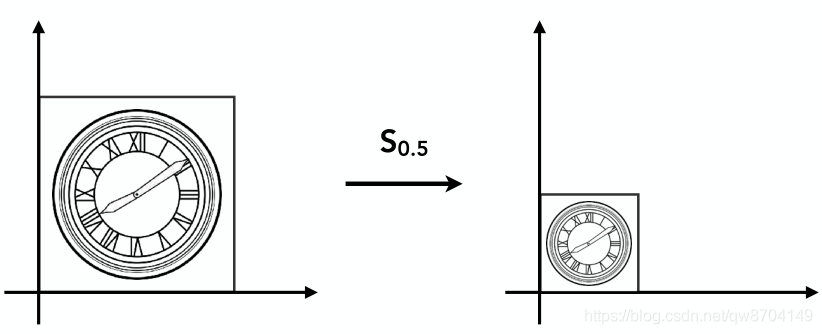
原文:计算机图形学(三)-图形学中的基本变换(缩放、平移、旋转、剪切、镜像) - 2021.07.18作...
原文:计算机图形学(一)-向量、向量加减法、向量的点积(乘)及应用、向量的叉积(乘)及应用 - 2021.05.08作者:点燃火柴 - CSDN1. 向量...
原文:5大提问,揭秘Style3D年度仿真模拟技术成果!- 2021.02.25出处:Style3D 官...
原文:干货 | Elasticsearch 向量搜索的工程化实战 - 2021.12.20出处:铭毅天下Elasticsearch - 微信公众号1. 背...
Python plt 画图时,结果图片的边缘会有比较大的空白,对此,可以在保存结果图像时,设置参数,去除...