原文-Understanding SSD MultiBox — Real-Time Object Detection In Deep Learning
SSD MultiBox 理解 - 基于深度学习的实时目标检测
该博客主要对 SSD MultiBox 目标检测技术进行介绍. 希望对于 MultiBox 算法以及 SSD 有更好的理解.

Figure 1. End-to-end 目标检测例示[From Microsoft].
自从 2012 ImageNet Large-Scale Visual Recognition Challenge(ILSVRC) 中,AlexNet 相比较传统计算机视觉(CV)方法,取得了较突出的成绩,深度学习已经成为图像识别任务中的主流方法. 在 CV 领域,CNN 擅长处理图像分类任务. 图像分类任务是基于类别标记的图片数据集,根据给定类别(classes),如 cat、dog 等,采用 CNN 网络检测图片中的物体类别.

Figure 2. cats 和 dogs 图片 [From Kaggle]
如今,深度学习已经比人类在图像分类具有更高的准确度. 然而,人类不仅对图片分类,还对视野内的每个物体进行定位(localize)与分类(classify). 这就对于机器来说,想达到人类的表现,具有很大的挑战. 实际上,如果目标检测精度较高,则能使得机器更接近真实的场景理解.

Figure3. 图片是只有 cat?还是只有 dog? 或者两者都有?[From Kaggle]
1. R-CNN(Region-Convolution Neural Network)
R-CNNs 是深度学习在目标检测任务的较早应用. 宽泛来讲,R-CNN 是 CNN 的一种特殊形式,能够对图片中的 objects 进行位置确定和类别检测. R-CNN 的输出,一般是一系列的 bounding boxes 和每个检测到的 object 的类别标签. Bounding box 是对每个检测到的 object 的近似匹配. 如:

Figure 4. R-CNN 的输出例示.
这些工作都在将 R-CNN 往更快、实时目标检测的方向努力. 虽然目标检测结果已经很好,但仍不是实时目标检测器. 其遇到的主要问题有:
[1] - 数据训练不够灵活,且比较耗时;
[2] - 训练是多阶段(multiple phases)的,two-stages 方法,如 region proposal 训练和分类器(classifier)训练;
[3] - 网络模型的部署时间太慢,在测试数据集上.
新的网络框架被提出,以克服 R-CNN 类方法的局限,如 YOLO - You Only Look Once 和 SSD - Single Shot Detector MultiBox . 下面即将对 SSD 进行介绍.
2. SSD - Single Shot MultiBox Detector
SSD 是 2016 年 11 月 C. Szegedy 等提出的方法,在目标检测任务的实时性和精度方面达到了新的记录 —— 在标准数据集上,如 PascalVOC 和 COCO,取得了 74% mAP(mean Average Precision),59 帧/秒. 为了更好的理解 SSD,这里先对网络结构名字解释:
[1] - Single Shot - 网络一次 forward 来输出 object localization 和 classification.
[2] - MultiBox - Szegedy 等提出的一种 bounding box regression 技术.
[3] - Detector - 网络是目标检测器,同时对检测到的 objects 分类.
SSD 网络结构:
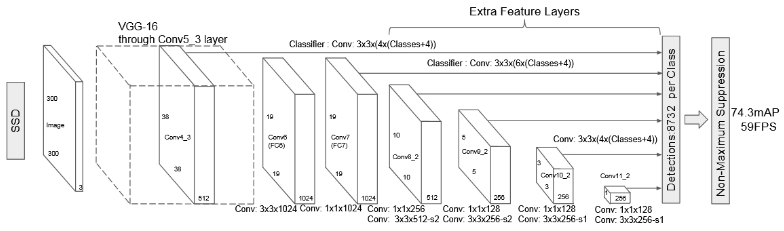
Figure 5. SSD 网络结构(input 是 300x300x3)
SSD 网络结构是基于 VGG16 网络的,去除了全连接层. 采用 VGG16 作为 base network 的原因是其在图像分类任务的良好表现,以及其应用普遍性,迁移学习(transfer learning) 对于提升结果精度更有利. 去除原始 VGG 全连接层,而添加一系列辅助卷积层(从 conv6 卷积层开始),能够提取多种尺度(multiple scales)的特征,并逐步地降低后面层的输入尺寸.
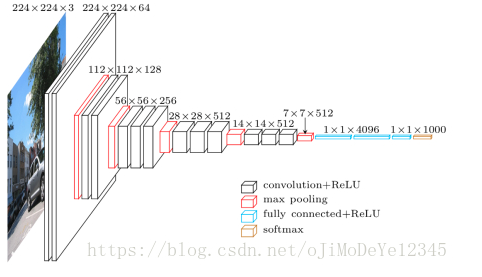
Figure 6. VGG 网络结构 (input 是 224x224x3)
3. MultiBox
SSD 的 bounding box regression 是受 Syegedy 的 MultiBox 启发.
MultiBox 是一种快速的类别不可知(class-agnostic)边界框坐标(bounding box coordinate) proposals 方法. 有趣的是,MultiBox 是采用的 Inception-style 的卷积网络. 1×1 卷积起降维作用(width 和 height 保持不变).
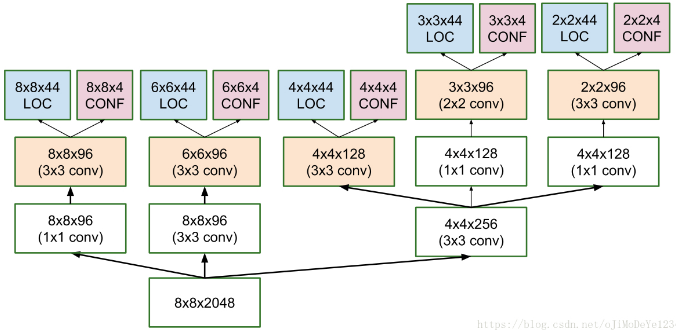
Figure 7. MultiBox 的 location 和 confidence 多尺度卷积预测网络结构
MultiBox 的 loss 函数包括两部分(SSD同样采用):
[1] - Confidence Loss - 计算的 bounding box 内的 object 的类别置信度. 采用类别交叉熵( cross-entropy) 计算损失函数.
[2] - Location Loss - 计算训练集中网络预测的 bounding box 与对应 ground truth box 的偏移程度. 采用 L2-Norm 计算损失函数.
MultiBox Loss 即为:$multibox\_loss = confidence\_loss + alpha * location\_loss $. 其中, alpha 参数控制两个 loss 的贡献度.
类似于其它深度学习任务,MultiBox 的目标是计算loss 函数的最优解时的参数值,使预测值尽可能的接近真实值.
4. MultiBox Priors 和 IoU
MultiBox Priors,也被叫做 anchors(Faster RCNN),是预计算的,其是与原始 groundtruth boxes 分布很接近的固定尺寸的 bounding boxes.
MultiBox Priors 是根据其与 groundtruth boxes 的 IoU (Intersection over Union ratio) 大于 0.5 选取的. 虽然 IoU 大于 0.5 仍不够好,但能够为 bounding box regression 算法提供可靠的初始化 boxes,尤其是与随机坐标选取的初始化 bounding boxes.

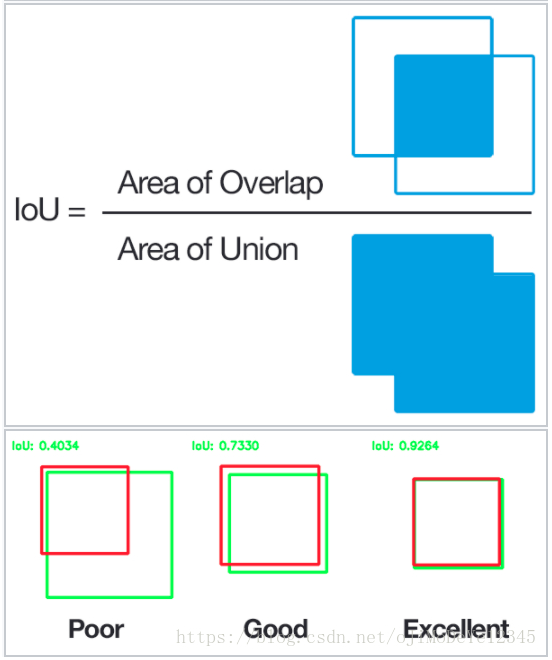
Figure 8. IoU 图示(From Wikipedia)
因此,MultiBox 采用 Priors 作为预测的初始化 bounding boxes,并回归与 groundtruth boxes 最接近的预测 boxes. MultiBox 网络结构,每个 feature map 单元包括 11 个 Priors(8x8, 6x6, 4x4, 3x3, 2x2)和只有一个 1x1 的 feature map,最终每张图片得到共 1420 个 Priors,基本上包括了输入图片的多种尺度(multiple scales) 范围,以检测不同尺寸的物体. 最终,MultiBox 只保留 top K 的预测结果,其具有最小的 location(LOC) 和 confidence(CONF) losses.
5. SSD 对 MultiBox 的改进
5.1. Fixed Priors
与 MultiBox 不同的是,SSD 中每个 feature map 单元与一系列默认 bounding boxes 集相关联,这些默认 bounding boxes 具有不同的维度和长宽比(dimensions and aspect ratios). 这些 Priors 是手工选取的;而 MultiBox 采用与 groundtruth boxes 的 IoU 大于 0.5 进行选取的. 理论上,SSD 能够生成任何类型的输入,而不需要对 priors 生成的预训练阶段.
例如,假设每个 feature map 单元有 $b$ 个 bounding boxes,每个默认 bounding box 配置了对角线的 2 个点 (x1, y1), (x2, y2),待分类目标类别数 $c$, 给定的 feature map 尺寸为 f = m×n,SSD 将计算该 feature map 的 f ×b ×(4 +c) 个值.
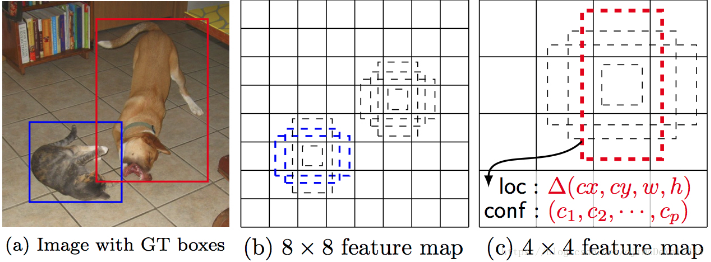
Figure 9. SSD 在 8x8 和 4x4 feature maps 的默认 boxes.
5.2. Location Loss
SSD 采用 smooth L1-Norm 来计算 location loss. 虽然不如 L2-Norm 精度高,但仍具有较高效率;且由于其不追求 bounding box 预测的 “像素级准确”,给了 SSD 更多可处理空间(例如,少许像素的偏差可能很难被发现.)
5.3. Classification
MultiBox 没有进行目标分类,但 SSD 有对目标的分类. 因此,对于每个预测的 bounding box,将计算对数据集中全部 $c$ 类类别的预测值.
6. SSD 训练与运行
6.1. 数据集
目标检测数据集包含 grountruth boxes 和对应的 class labels,且每个 bounding box 仅有一个对应的 class label. 可以采用 PASCAL VOC 和 COCO 数据集开始.

Figure 10. Pascal VOC 数据集图片及标注
6.2. 默认 Bounding Boxes
推荐配置多种默认 bounding boxes,包含不同的尺度(scales) 和长宽比(aspect ratios),以捕捉尽可能多的 objects. SSD 论文对每个 feature map 单元采用了 6 种 bounding boxes.
6.3. Feature Maps
Feature Map (如卷积层输出) 是图片在不同尺度的特征表示. 采用 MultiBox 对多种 feature maps 进行计算,能够增加 objects 最终被检测、定位和分类的精度. 如下图,给出了对于给定图片,网络计算 feature maps 的过程:
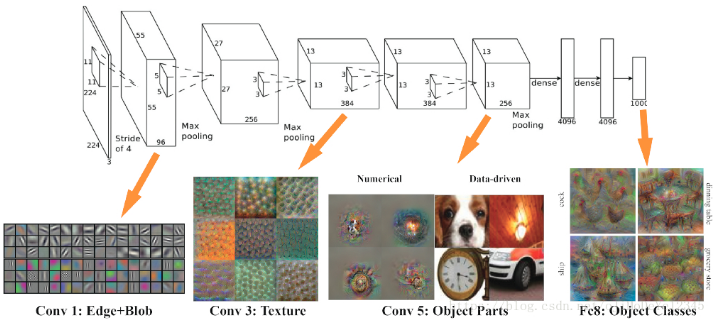
Figure 11. VGG Feature Map 可视化(From Brown Uni)
6.4. Hard Negative Mining
SSD 训练时,大部分 bounding boxes 的 IoU 较低,被记作 negative 训练样本,需要在训练集中保持合适的 negative 样本数. 训练时不是使用全部的 negative 预测,而是保持 negative 和 positive 样本的比例为 $3:1$. 采用 negative 样本的原因是,网络不仅要学习 positve 样本的信息,还需要学习造成不正确检测的信息.
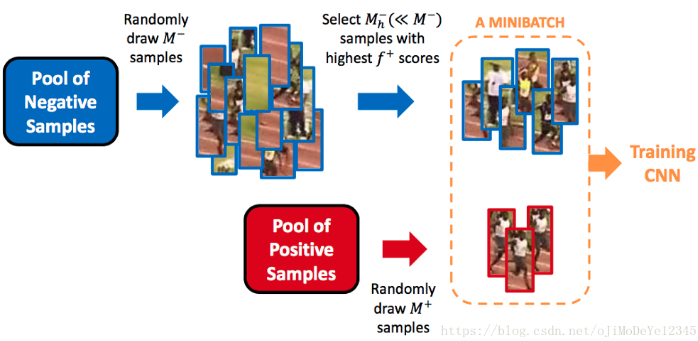
Figure 12. hard negative mining 示例(From jamie Kang blog)
6.5. Data Augmentation
数据增广对于深度学习应用比较重要,目标检测中,其能够使网络对于输入的不同 object 尺寸具有鲁棒性. SSD 根据原始图片裁剪生成新的训练样本,其与原始图片具有不同的 IoU 比例(如0.1, 0.3, 0.5 等),同时随机裁剪. 每张图片被随机水平翻转,以对 objects 镜像鲁棒.

Figure 13. 水平翻转图片示例(From Behavioural Cloning Blog)
6.6. NMS
SSD 对图片进行推断时, 一次 forward 生成大量的 boxes,需要采用 NMS (Non-Maximum Suppression) 滤除大部分的 bounding boxes:当boxes 的 confidence 阈值小于 $ct$(如 0.01) 与 IoU 小于 $lt$(如0.45) 时,则丢弃. 只保留 top $N$ 的预测结果. 这样只保留了网络预测的最可能的预测值,更多的干扰预测值被去除.

Figure 14. NMS 示例(From DeepHub tweet).
7. SSD Notes
[1] - 更多默认 boxes 会影响速度,但能增加目标检测精度;
[2] - MultiBox 同样能够提高检测精度,因为 MultiBox 检测器对不同分辨率的 features 处理;
[3] - 80% 的时间是 VGG16 base network 消耗的,也就是说,更快更有效的 base network 能够提高 SSD 的效果;
[4] - SSD 对于相似类别(如 animals) 的 objects 容易混淆,其原因很可能是 locations 是多种 objects 类别共享造成的;
[5] - SSD-500( 512x512 输入图片的最高分辨率输出) 在 Pascal VOC上的 mAP 为 76.8%,但牺牲了效率,其速率为 22 帧/秒;SSD-300 达到一个好的时间和精度平衡, mAP=74.3%,59帧/秒.
[6] - SSD 对于小物体的检测效果较差,因为小物体不是在所有的 feature maps 中都出现. 增加输入图片分辨率能够缓解这样问题,但不能完全解决.
8. SSD 实现
[1] - Caffe-SSD
[2] - TensorFlow-SSD
博主打算将基于传统计算机视觉技术实现的车辆检测( Vehicle Detection) ,再采用 SSD 进行实现. Teaching Cars To See — Vehicle Detection Using Machine Learning And Computer Vision
9. 相关
[1] - YOLO9000: Better, Faster, Stronger
[2] - Mask R-CNN - 像素级的精确实例分割