使用 DALI 库时,数据处理任务都时基于 Pipeline 实现的. Pipeline 对象是 nvidia.dali.Pipeline 的实例,或衍生类.
DALI Pipeline 的定义有如下方式:
[1] - 采用 DALI 内置 operators 来定义函数,并用 pipeline_def() 装饰器进行装饰;
[2] - 直接实例化 Pipeline 对象,构建图并通过 Pipeline.set_outputs() 进行定义;
[3] - 继承 Pipeline 类,并重写 Pipeline.define_graph(). (这是 DALI Pipelines 定义的遗留方式.)
1. 数据处理 Graphs
DALI Pipeline 被表示为操作子组成的图(graph),图中由两种节点(node):
[1] - Operators - 调用的操作子定义
[2] - Data node(DataNode) - 表示 operators 的输入和输出.
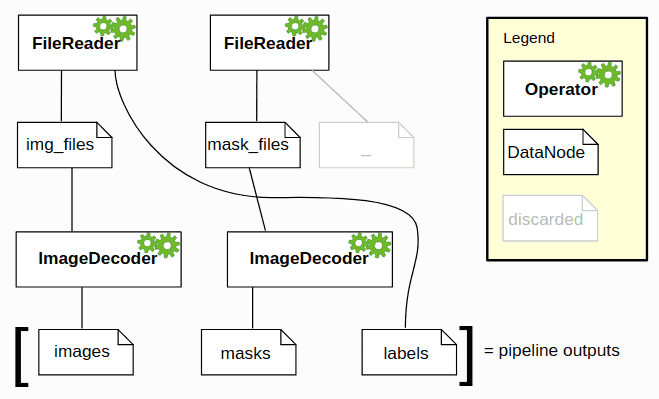
如:
#create a pipeline with processing graph defined by the function below
@pipeline_def
def segm_pipeline():
"""
Create a pipeline which reads images and masks, decodes the images and returns them.
"""
img_files, labels = fn.readers.file(file_root="image_dir", seed=1)
mask_files, _ = fn.readers.file(file_root="mask_dir", seed=1)
images = fn.decoders.image(img_files, device="mixed")
masks = fn.decoders.image(mask_files, device="mixed")
return images, masks, labels
#
pipe = my_pipeline(batch_size=4, num_threads=2, device_id=0)
pipe.build()得到的图如:
2. nvidia.dali.Pipeline
Class nvidia.dali.Pipeline(batch_size=-1,
num_threads=-1,
device_id=-1,
seed=-1,
exec_pipelined=True,
prefetch_queue_depth=2,
exec_async=True,
bytes_per_sample=0,
set_affinity=False,
max_streams=-1,
default_cuda_stream_priority=0,
*,
enable_memory_stats=False,
py_num_workers=1,
py_start_method='fork')具体参数说明可见: nvidia.dali.Pipeline