生产级解决方案是使用多机多卡进行网络模型的训练.
Multiple GPU Support 给出了如何采用多张 GPUs 运行 DALI Pipeline.
1. 指定 GPU 运行 Pipeline
如:
import nvidia.dali.fn as fn
import nvidia.dali.types as types
from nvidia.dali.pipeline import Pipeline
image_dir = "../data/images"
batch_size = 4
def test_pipeline(device_id):
pipe = Pipeline(batch_size=batch_size, num_threads=1, device_id=device_id)
with pipe:
jpegs, labels = fn.readers.file(file_root=image_dir, random_shuffle=False)
images = fn.decoders.image(jpegs, device='mixed', output_type=types.RGB)
pipe.set_outputs(images, labels)
return pipe
#需要至少 2 GPUs
pipe = test_pipeline(device_id=1)
pipe.build()
#运行
images, labels = pipe.run()
#可视化
import matplotlib.gridspec as gridspec
import matplotlib.pyplot as plt
def show_images(image_batch):
columns = 4
rows = (batch_size + 1) // (columns)
fig = plt.figure(figsize = (32,(32 // columns) * rows))
gs = gridspec.GridSpec(rows, columns)
for j in range(rows*columns):
plt.subplot(gs[j])
plt.axis("off")
plt.imshow(image_batch.at(j))
plt.show()
#
show_images(images.as_cpu())如:

2. 分片(Sharding)
在不同 GPUs 上运行 Pipeline 是不够的.
在训练时,每个 GPU 分别同时处理不同的样本,这种技术叫做分片(Sharding).
为了进行分片,数据集被划分为多个部分或分区,每个 GPU 分别取到相应的分区进行处理.
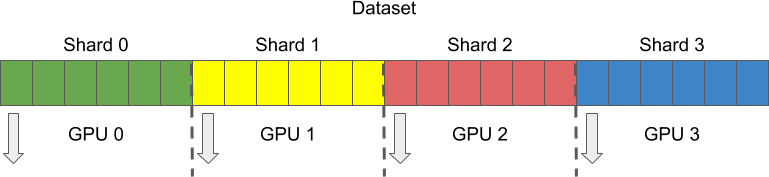
DALI 是通过控制每个 reader 操作子的 shard_id 和 num_shards 参数实现分片的.
示例如,
def sharded_pipeline(device_id, shard_id, num_shards):
pipe = Pipeline(batch_size=batch_size, num_threads=1, device_id=device_id)
with pipe:
jpegs, labels = fn.readers.file(
file_root=image_dir, random_shuffle=False, shard_id=shard_id, num_shards=num_shards)#shard_id&num_shards
images = fn.decoders.image(jpegs, device='mixed', output_type=types.RGB)
pipe.set_outputs(images, labels)
return pipe
#在两张GPU上构建Pipeline
pipe_one = sharded_pipeline(device_id=0, shard_id=0, num_shards=2)
pipe_one.build()
pipe_two = sharded_pipeline(device_id=1, shard_id=1, num_shards=2)
pipe_two.build()
#运行
images_one, labels_one = pipe_one.run()
images_two, labels_two = pipe_two.run()
#可视化
show_images(images_one.as_cpu())
show_images(images_two.as_cpu())