原文:ProGAN: How NVIDIA Generated Images of Unprecedented Quality - 2018.12.17
Github - progressive_growing_of_gans
作者:Sarah Wolf

上面两张高分辨率图像中人物看起来很真实,但实际上并不是真的,其是由在百万级名人图像(celebrity images) 上训练的 ProGAN 所合成得到的.
ProGAN, Progressive Growing of GANs For Improved Quality, Stability, and and Variation, 是 NVIDIA 2017 年所提出的.
这里,主要是关于 ProGAN 网络的工作原理的理解,如何生成高分辨率的图像,以及为什么其是一个突破.
1. GANs 简介
生成模型,Generative Model.
GANs,Generative Adversarial Networks.
1.1. GANs 是一种新的生成模型
GANs 是 Ian Goodfellow 等 2014 年 Generative Adversarial Nets 所提出,并流行起来的.
GANs 是一种生成模型,其尝试合成与训练数据不同的新数据. 这是一种无监督学习. GANs 包含两个神经网络,互相博弈:
[1] - 生成网络(Generator): 其输入为随机向量,输出为合成的数据;
[2] - 判别网络(Discriminator): 其输入为真实数据,输出为训练集的概率分布.
生成网络生成“假数据(fakes)”,判别网络尝试从真实数据中区分这些假数据.
两个网络在刚开始训练时,对于各自的任务都能力较差;但随着网络的训练,他们依次迭代进行提升,直到生成网络能够产生较为可信的假数据.
两个网络进行的是零和博弈(zero sum game),其中一个的成功,则对应着另一个的失败. 对此,训练时的损失函数值并不能表明网络是否被很好的训练,只能说明生成网络或判别网络相对于彼此的博弈情况.
如图:
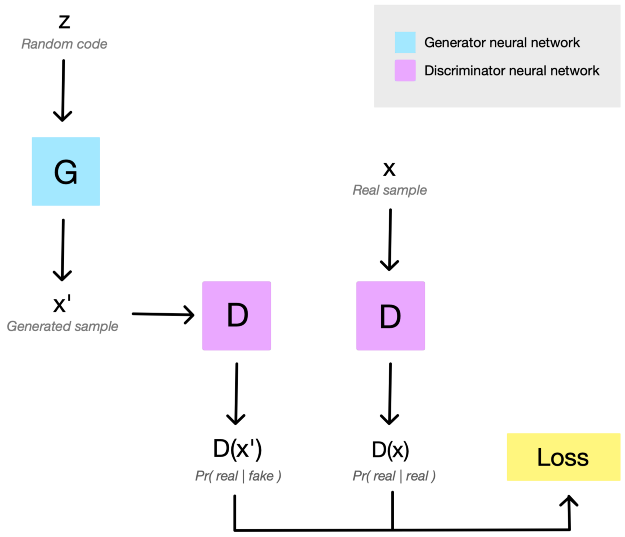
图:典型的 GAN 网络,随机值(random code) z 送入生成网络 G 以生成假数据x’. 然后,假数据x’和训练数据集中真实数据x,分别被送入判别网络 D. D 分别对 x’ 和 x 分配一个为 “真(real)” 的概率分布D(x’) 和 D(x),这取决于假数据的真实程度以及判别网络 D 的复杂程度. 接着,概率分布 D(x’) 和 D(x)被用于计算对抗损失函数(adversarial loss),采用 BP 训练 D 和 G.
输入到生成网络 G 中的随机值(random code) 是尤其重要的. 其是噪声源,使得合成样本是新的且唯一的(new & unique). 其还倾向于以有趣的方式来控制输出. 当在随机值的向量空间周围进行线性插值时,对应生成的输出也是平滑插值的,有时甚至是以人类直观的方式.
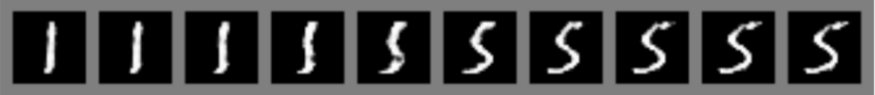
图:MNIST 训练的 GAN,通过在随机值 z 的线性插值,得到的数字. 可以看出,从 1 到 5 的过渡是平滑的, 说明了其学习到了数字的某种内在表示.
1.2. GANs 挑战和局限
尽管 GANs 是一种非常令人兴奋的无标签数据学习表示的方式,但实际上 GANs 往往是比较难的.
GANs 的训练是很有挑战性的. 其很大程度上是因为 模式坍塌(mode collapse) 问题.
当判别网络基本上赢了游戏时,模式坍塌就会发生,生成网络的训练梯度变得越来越没有用. 这种情况在训练过程中,发生的相对比较快;当模式坍塌出现时,生成网络开始每次输出几乎相同的样本数据. 网络不再变好.
即使 Ian Goodfellow 也承认其是幸运的,他午餐时间所尝试的,第一次 GAN 所选择的超参数即比较有效. 实际上,往往是容易失败的. 近些年,研究者在尝试很多方式以保证 GANs 网络的训练更加可靠. 可参考 Are GANs Created Equal? A Large Scale Study.
但现在,模式坍塌问题仍没有完全解决,模式坍塌的理论原因仍是一个开放问题.
1.3. GANs 生成图像
图像生成的一个重要提升出现在 2016 年,Radford 等的论文 Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks . 他们发现一个能够很好的生成图像的 GAN 结构家族,即 “DCGANs”. DCGANs 去除了一些 CNNs 中的 pooling 层,依赖于 conv 和 transpose conv 来改变表示的特征图尺寸. 大部分网络层后接 BN 和 leaky ReLU 激活层.
然而,DCGANs 只能生成固定尺寸的图像. 图像的分辨率越高,判别网络越容易区分 real 图像和 fakes 图像. 其更容易出现模型坍塌问题. 虽然合成 28x28 的图像或 128x128 的图像已经逐渐成为常规操作,但生成高于 512x512 分辨率的图像实际上仍很有挑战.
这里需要注意的是,虽然 Image-to-Image Translation with Conditional Adversarial Networks-2016 中可以处理高分辨,但其是非常困难的任务. 因为这些只是学习改变输入图像的表面特征(surface-level feature),而不是从头开始生成一个全新的图像.
至此,可以想象的到,对于很多实际应用而言,完全从零生成大分辨率图像的难度,限制了 GANs 的场景.
2. ProGAN
NVIDIA 采用 ProGAN 生成了 1024x1024 分辨率的图像. 更好的是,他们的技术没有理由不能被用于合成更高分辨率的图像. ProGAN 就训练时间而言,甚至比以前的 GANs 更有效.
2.1. 增长型GANs
Growing GANs.
相比于尝试一次性训练生成网络和判别网络的全部网络层,NVIDIA 逐渐增长其 GAN,一次一个网络层,以处理渐进式越来越高分辨率的图像.
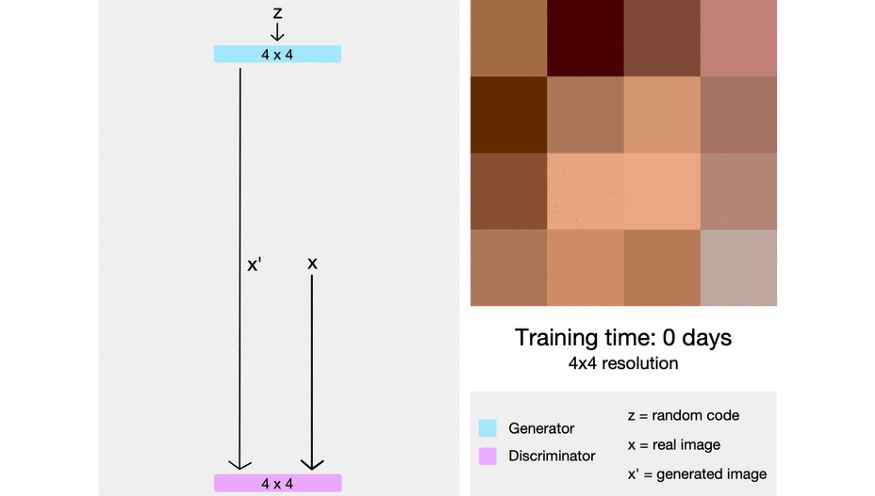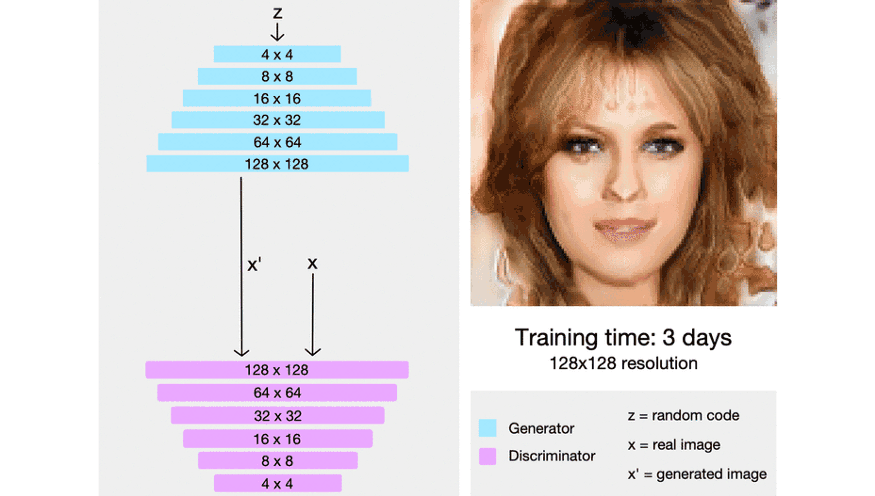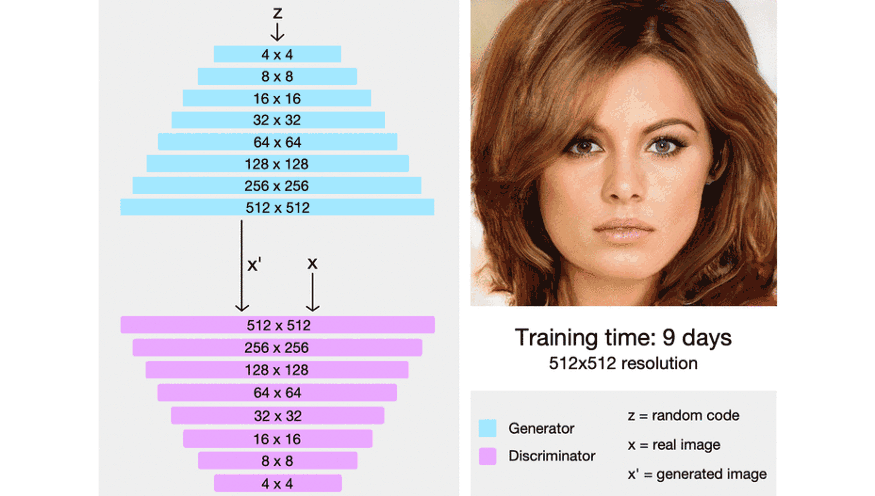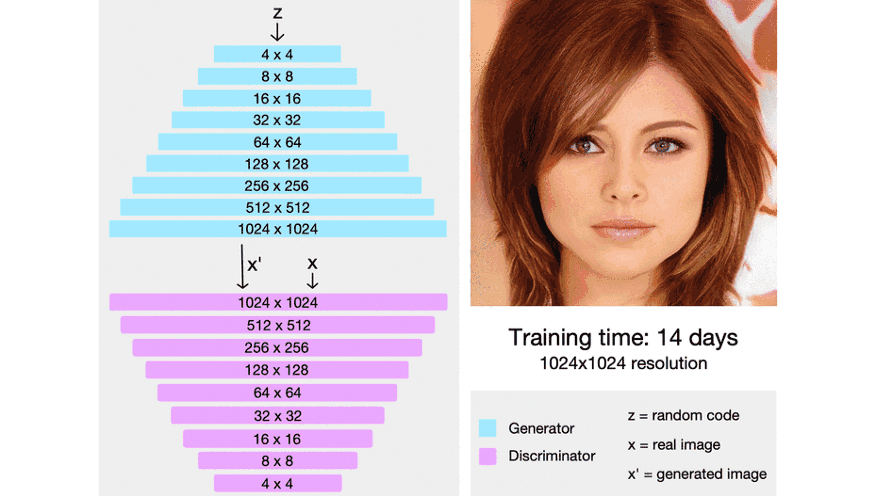
图:ProGAN 开始时生成非常低分辨率的图像. 当训练稳定时,新增一个网络层,且分辨率翻倍. 重复该过程,直到输出达到期望的分辨率. 以这种渐进式增长网络,首先会学习到高层结构,且训练稳定.
ProGAN 首先人工缩小训练图像到非常小的起始分辨率(仅 4x4 像素). 创建仅有少量网络层的生成网络,以合成该低分辨率的图像,并创建一个对应的结构的判别器. 由于网络非常小,因此其训练相对较快,且仅学习到高度模糊化图像的大尺度结构.
当第一层完成训练时,然后,在 G 和 D 上新增一个网络层,将输出分辨率翻倍到 8x8. 保留先前网络层训练的权重,但并不锁定权重, 新增网络层逐渐淡入,以帮助稳定过渡(后面详细介绍). 继续训练直到 GAN 再次能合成真实图像,此时是新的 8x8 分辨率.
按照这种方式,ProGAN 继续新增网络层,分辨率翻倍,训练网络直至达到期望的输出分辨率.
2.2. 增长型GANs 的有效性
通过逐渐增加分辨率,可以持续的要求网络从整体问题中的一个简单的分片. 这种增量学习过程大大提升了训练的稳定性. 其可以减少模式坍塌发生的几率.
此外,由低到高(low-to-high)分辨率使得渐进式增长网络首先关注与高层结构(图像最模糊版本中可以辨别的模式),在逐渐填入细节. 这种方式通过降低网络完全错误陷入某种高层结构的可能性,有助于提升最终图像的质量.
逐渐增加网络尺寸,相比于一次性初始化所有网络层的传统方法,具有更高的计算效率. 少量的网络层训练更快速,因为仅有简单的少量参数. 由于除了最后一次训练迭代的数据集,其它的均是在最终层的一个子集上进行的,这会带来令人印象深刻的效率提高. Karras 等发现,ProGAN 相比于对应的传统 GAN,一般会有 2-6x 的速度提升,取决于输出分辨率.
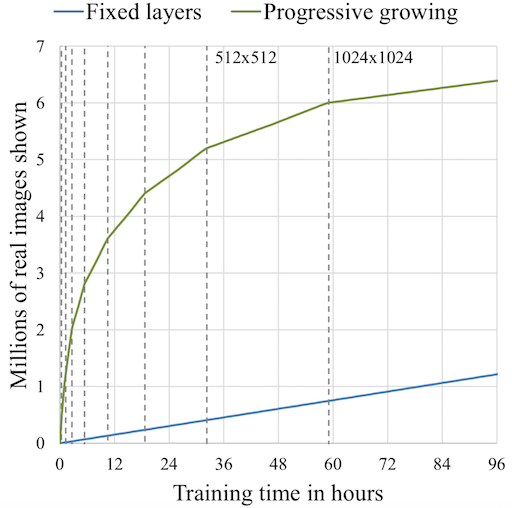
图:渐进式增长的训练有效性图示. 对于给定的训练时间,ProGAN 比传统 GAN 训练更多的图像. 尤其是在刚开始训练阶段,差别更明显,这是因为渐进式增长网络的起始训练网络是非常小的.
2.3. 网络结构
除了逐渐增长网络,NVIDIA 论文作者还对网络结果进行了一些修改,以使得网络更加稳定、训练更有效.
对于给定分辨率 k 的生成网络,采用比较熟悉的高层模式,每个网络层集合,将特征表示的尺寸翻倍,将通道数减半,直到输出层创建的图像是与 RGB 对应的 3 通道. 判别网络进行几乎完全相反的处理,每个网络层集合,将特征表示的尺寸减半,将通道数翻倍. 在这两个网络中,通过将 filters 的数量限制在一个合理的值,如 512,来中断通道翻倍(channel-doubling)的模式,以避免参数总数变得过高.
从这个意义上说,ProGAN 类似于早期图像生成的 GANs,DCGAN 也采用了类似的结构.
不过,DCGAN 采用 transpose conv 来改变表示的尺寸(特征图的分辨率. 而 ProGAN 采用 nearest neighbors(最近邻) 来放大尺度(upscaling),采用 average pooling(平均池化) 来缩小尺度(downscaling). 这是不需要参数学习的简单操作. 其后接两个 conv 层.

图:生成网络的结构, 网络分辨率增长到 k. 每个网络层子集采用 nearest neighbor upscaling 及两个 conv 层,将分辨率尺寸翻倍. 为了训练的稳定性,最新新增的网络层被逐渐消失(faded in). 该过程是由 $\alpha$ 来控制的,$\alpha \in [0, 1]$, 其随着训练迭代线性增加,知道新增网络层完全 inplace.
2.4. 新增网络层逐渐消失(Fading in)
ProGAN 网络通过在现有分辨率训练完成后,新增网络层子集将分辨率翻倍,以渐进式的增长的. 当新增网络层后,先前网络层的参数仍会保持训练,
为了避免突然新增的 top 网络层冲击原有较低层,top 网络层会线性的逐渐消失(faded in). 该过程是由 $\alpha$ 来控制的,$\alpha\in [0, 1]$,随着多次训练迭代线性插值得到的. 从上图可以看出,最终生成的图像是由生成网络中最后一层和倒数第二层的加权和得到的.
2.5. 像素归一化(Pixel Normalization)
相比于通用的采用 Batch Normalization(BN) 层,ProGAN 采用了像素归一化. pixelnorm 层没有可训练的权重, 其是将每个像素的特征向量的归一化到单位长度, 用于在生成网络中的 conv 层之后. 该目的主要是用于避免信号值在训练过程中脱离控制.
$$ b_{x, y} = \frac{a_{x, y}}{\sqrt{\frac{1}{C} \sum_{j=0}^C a_{x, y}^j + \epsilon}} $$
其中,C 通道的每个像素(x, y)值被归一化为固定长度. $a$ 为输入 tensor,$b$ 为输出 tensor,$\epsilon$ 是很小的值,避免分母为 0.
2.6. 判别网络
生成网络和判别网络可以粗略地认为是互为镜像,往往是同步增长的.
判别网络的输入图像 $x$,可以是生成网络的输出,或者是训练数据集降采样到当前训练分辨率的图像. 作为 GAN 判别网络的典型结构,其尝试区分训练数据集中 real 图像和生成网络的 fake 图像. 判别网络的输出为 D(x),表示输入图像 x 是来自训练集中的置信度.
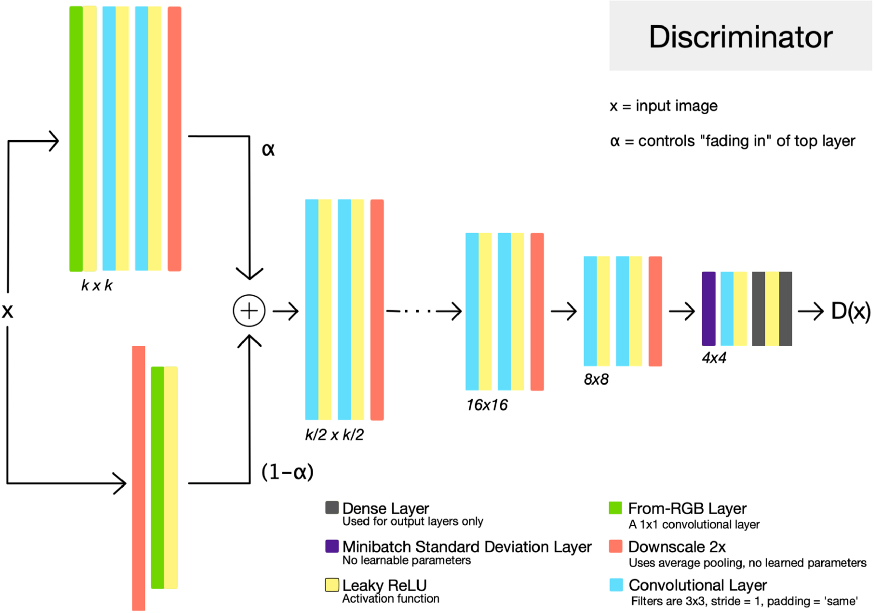
图:判别网络结构. 分辨率增长到 k. 这里 x 为输入图像(生成图像或训练数据集图像), $\alpha$ 为生成网络最后一层 fade in 的参数. D(x) 为生成网络输出的 x 是来自训练数据集的概率. 表示尺寸(特征图尺寸) 在每个网络层子集后采用 average pool 操作被减半.
2.7. Minibatch 标准偏差
Minibatch Standard Deviation.
一般来说,GANs 生成的样本比训练数据集的偏差更小. 一种解决方案是,用判别网络计算 batch 的统计数据,并采用该统计信息来从生成的 fake batches 中区分 real 训练数据 batches. 这种操作鼓励生成网络的输出更多样性,以使得在生成 batch 计算的统计信息更接近与训练数据 batch 的统计数据.
而,ProGAN 通过在判别网络输出端附近插入 “minibatch standard deviation” 层. 该层没有可训练参数. 其对 batch 内的特征图像素计算标准偏差,并将他们作为一个额外的通道.
2.8. 均衡学习率
Equalized Learning Rate.
ProGAN 的作者发现,为了保证生成网络和判别网络的健康竞赛,有必要保持相似的学习速度. 为了达到均衡学习率的目的,他们根据网络层所包含的去那种数来缩放该网络层的权重. 采用了与 He initialization 相同的表达式,唯一区别是,其在训练中每一次 forward 中都进行,而不仅仅是初始化是才进行.
$$ W_f = W_i * \sqrt{\frac{2}{k * k* c}} $$
例如,在 f filters,size [k, k, c] 的 conv 操作前,可以采用上述工时将该 filters 的权重进行缩放.
基于该操作,无需其它权重初始化技巧,仅采用标准归一化分布的初始化权重即可表现良好.
2.9. 损失函数
ProGAN 表示,其损失函数选择正交于其分布,即,上述提升均不依赖于指定损失函数的. 也就是的,未来任何 GAN 的损失函数都可以被用到.
然而,仔细阅读论文会发现,ProGAN 采用了 improved Wassersein 损失函数,即 WGAN-GP. 其是一种很通用的损失函数,并被用于稳定网络训练,提升收敛的可能性.

图:WGAN-GP 损失函数. $x'$ 为生成图像,$x$ 为训练数据集图像. D 为判别网络. GP 为梯度惩罚以稳定网络训练. $a$ 为梯度惩罚,其0-1之间的为随机数 tensor,随机选择的. 一般 $\lambda=10$. 由于网络训练是 batches 的,因此该损失函数往往是在 minibatch 内求平均的.
一个很重要的注意事项是,WGAN-GP 损失函数期望 D(x) 和 D(x’) 是无界实数值. 换句话说,判别网络的输出并不是期望在 0到1 之间的值. 这一点是与传统 GAN 表达式略有不同的,后者将判别器的输出看作为概率.
3. Results

当平滑的插值输入向量 z 时,ProGAN 的输出.
1 条评论
老板,注册打开了~