原文:How to Implement Progressive Growing GAN Models in Keras - 2019.08.14
作者: Jason Brownlee
ProGAN,progressive growing generative adversarial network.
ProGAN 是用于生成合成图像的一种深度神经网络模型的训练的方法.
ProGAN 是 GANs 结构的一种扩展,其在训练过程中增量式的增加生成图像的尺寸,从非常小的图像开始,如,4x4 pixels. 这种增量式的方式有助于网络的稳定训练,GAN 模型的增长可以生成非常大且高质量的图像,比如 合成的 celebrity 人脸图像的尺寸可以达到 1024x1024 pixels.
这里,主要介绍基于 Keras 从零开始开发 ProGAN 网络模型. 主要包括几个方面:
[1] - 如何在输出图像增长的每一层,开发 pre-defined 辨别器和生成器模型;
[2] - 如何通过辨别器模型定义组合模型,以训练生成模型;
[3] - 如何在输出图像增长的每一层,循环训练 fade-in 版和 normal 版的模型.
1. ProGAN 简述
GANs 能够有效的生成合成图像,但往往生成图像的尺寸是受限的.
ProGAN 的关键创新是生成器输出的图像尺寸的渐进式增长,从 4x4 pixels 增长到 8x8, 16x16 等等,直到期望的输出分辨率.
Our primary contribution is a training methodology for GANs where we start with low-resolution images, and then progressively increase the resolution by adding layers to the networks.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
其实现是通过在训练程序中,周期性的微调给定输出分辨率的模型,在更高分辨率的新模型中缓慢消失.
When doubling the resolution of the generator (G) and discriminator (D) we fade in the new layers smoothly
在训练过程中,所有的网络层都是保持训练的,包括在新增网络层前已经存在的网络层.
All existing layers in both networks remain trainable throughout the training process.
ProGAN 的网络结构如图:

ProGAN 渐进式增加网络层,可以让模型的生成器和判别器有效的从粗层次开始到更细节的学习.
This incremental nature allows the training to first discover the large-scale structure of the image distribution and then shift attention to increasingly finer-scale detail, instead of having to learn all scales simultaneously.
ProGAN 的模型结构是复杂的,比较难直接实现. 下面分块进行实现.
2. ProGAN - Discriminator
判别器模型,对给定图像作为输入,必须将他们分类为 real (来自数据集) 和 fake (生成的图像).
ProGAN 训练过程中,判别器必须渐进的增长,以支持增长的图像尺寸,从 4x4 pixels 的 RGB 图像开始,逐渐翻倍到 8x8, 16x16, 32x32 等等.
其是通过插入新的输入层,以支持更大输入图像. 该新增的网络层的输出再被降采样. 此外,新图像也被直接降采样,并在其与新网络层的输出进行组合前,先送入 old 输入层处理.
低分辨率到高分辨率的过渡过程中,如 16x16 到 32x32,判别器模型会有两个输入路线:
- [32×32 Image] -> [fromRGB Conv] -> [NewBlock] -> [Downsample] ->
- [32×32 Image] -> [Downsample] -> [fromRGB Conv] ->
新增网络块(block) 的输出进行降采样,和 old 输入处理层的输出,一起加权处理;其中,权重是通过 alpha 超参数来控制的. 加权和的公式如下:
- Output = ((1 – alpha) fromRGB) + (alpha NewBlock)
两个输入路线的加权和然后被送入已有模型中.
初始阶段,权重完全偏向于 old 输入处理层(alpha=0),在训练迭代中线性的增加,以使得新增网络层块给予更多的权重,直到结束,其输出完全是新增网络层块的输出(alpha=1). 此时,old 输入路线被移除.
如图:
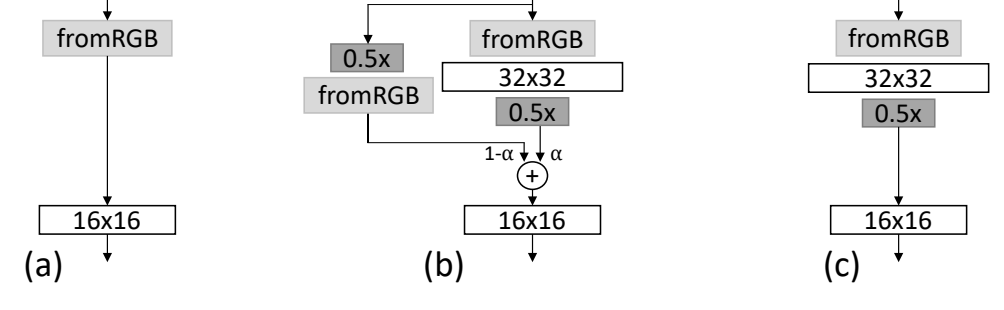
其中, fromRGB 层是通过 1x1 conv 层来实现的. 网络层块是有两个 3x3 conv 层和 slope=0.2 的 leaky ReLU 激活函数,后接降采样层. Average polling 用于降采样,而并未采用其他很多 GAN 所采用的 transpose conv 层.
模型的输出包含两个 3x3 和 4x4 的 conv 层,以及 Leaky ReLU 激活函数,后接 FC 层以输出单个预测值. 模型往往采用线性激活函数,而不是 sigmoid 激活函数.
模型训练是直接通过 WGAN-GP (Wasserstein loss) 损失函数或最小二乘损失函数(least squares loss). 这里采用的是后者. 模型权重初始化采用的是 He Gaussian(he_normal).
ProGAN 在输出网络层块开始处,采用了一个 Minibatch standard devisation 定制网络层;此外,并未采用 batch normalization 层,每个网络层采用了 LRN(local response normalization),称为 pixel-wise normalization.
ProGAN 的一种实现方式是,训练时根据需要扩展模型;另一种方式是,训练前先验地预定义所有的模型,并仔细的利用 Keras API,以确保跨模型间的网络层共享和连续训练. 这里采用后一种方式.
首先,必须定义定制网络层,用于 fading-in 新的更高分辨率的输入图像和 block. 该新增网络层必须要包含两个具有相同维度(width, height, channels)的激活图集合(two sets of activation maps),并采用加权和将其相加.
故,定义 WeightedSum 层,其功能是合并网络层,并利用超参数 alpha 控制每个输入的贡献. WeightedSum 层仅有两个输入:第一个是 old 网络层(exists 网络层) 的输出;第二个是新增网络层.
# weighted sum output
class WeightedSum(Add):
# init with default value
def __init__(self, alpha=0.0, **kwargs):
super(WeightedSum, self).__init__(**kwargs)
self.alpha = backend.variable(alpha, name='ws_alpha')
# output a weighted sum of inputs
def _merge_function(self, inputs):
# only supports a weighted sum of two inputs
assert (len(inputs) == 2)
# ((1-a) * input1) + (a * input2)
output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1])
return outputProGAN 的判别器模型的增长比生成器模型更复杂,因为必须改变模型的输入. 下面逐步进行.
首先,定义一个判别器模型,其输入为 4x4 RGB 图像,输出图像是 real 和 fake 的预测值. 该模型包含一个 1x1 输入处理层(formRGB)和输出网络层块(block). 如:
...
# base model input
in_image = Input(shape=(4,4,3))
# conv 1x1
g = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image)
g = LeakyReLU(alpha=0.2)(g)
# conv 3x3 (output block)
g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
# conv 4x4
g = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
# dense output layer
g = Flatten()(g)
out_class = Dense(1)(g)
# define model
model = Model(in_image, out_class)
# compile model
model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))然后,需要定义新的模型来处理该模型到新的判别模型之间的过渡阶段,后者新的判别模型的输入为 8x8 RGB 图像.
existing 输入处理层必须接受新的 8x8 图像的降采样版本. new 输入处理层必须采用 8x8 输入图像,并将其送入一个包含 2 个 conv 层和一个降采样层的 block. new block 降采样后的输出和 old 输入处理层必须采用加权和(WeightedSum 层)相加在一起;并复用相同的输出 block( 2 个 conv 层和输出层).
给定第一个定义的模型和对模型的已知情况(如,对于 Conv2D 和 Leaky ReLU输入处理层的网络层数为2 ),可以构建新的中间过渡层,即:采用 old 模型索引的网络层的fade-in 模型.
...
old_model = model
# get shape of existing model
in_shape = list(old_model.input.shape)
# define new input shape as double the size
input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value)
in_image = Input(shape=input_shape)
# define new input processing layer
g = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image)
g = LeakyReLU(alpha=0.2)(g)
# define new block
g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
g = AveragePooling2D()(g)
# downsample the new larger image
downsample = AveragePooling2D()(in_image)
# connect old input processing to downsampled new input
block_old = old_model.layers[1](downsample)
block_old = old_model.layers[2](block_old)
# fade in output of old model input layer with new input
g = WeightedSum()([block_old, g])
# skip the input, 1x1 and activation for the old model
for i in range(3, len(old_model.layers)):
g = old_model.layers[i](g)
# define straight-through model
model = Model(in_image, g)
# compile model
model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))此外,还需要一个具有相同网络层的相同模型的版本,其不包含从 old 模型输入处理层的输入 fade-in.
该 straight-through 版本对于训练是需要的,在 fade-in 下一个翻倍的输入图像尺寸之前.
故,可以更新上述示例,以创建两个版本的模型. 第一个是 straight-through 版本相对简单,第二个是 fade-in 版本,其复用了从 new block 和 old 模型的输出层的网络层. 定义 add_discriminatro_block(),该函数返回两个定义的模型(straight-through 和 fade-in),并采用 old 模型作为参数;同时还定义了输入层的数量参数.
此外,为了确保 WeightedSum 层的正常计算,必须将所有 conv 层固定为 64x64,输出为 64 特征图(feature maps). 如果存在 old 模型的输入处理层和 new blocks 输出(特征图的 channels 数)不匹配的情况,加权和计算会出错.
# add a discriminator block
def add_discriminator_block(old_model, n_input_layers=3):
# get shape of existing model
in_shape = list(old_model.input.shape)
# define new input shape as double the size
input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value)
in_image = Input(shape=input_shape)
# define new input processing layer
d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image)
d = LeakyReLU(alpha=0.2)(d)
# define new block
d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
d = AveragePooling2D()(d)
block_new = d
# skip the input, 1x1 and activation for the old model
for i in range(n_input_layers, len(old_model.layers)):
d = old_model.layers[i](d)
# define straight-through model
model1 = Model(in_image, d)
# compile model
model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# downsample the new larger image
downsample = AveragePooling2D()(in_image)
# connect old input processing to downsampled new input
block_old = old_model.layers[1](downsample)
block_old = old_model.layers[2](block_old)
# fade in output of old model input layer with new input
d = WeightedSum()([block_old, block_new])
# skip the input, 1x1 and activation for the old model
for i in range(n_input_layers, len(old_model.layers)):
d = old_model.layers[i](d)
# define straight-through model
model2 = Model(in_image, d)
# compile model
model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
return [model1, model2]当多次翻倍输入图像尺寸是,可以重复调用该函数.
重要的一点是,该函数期望先验模型是 straight-through 版本来作为输入.
下面的示例定义了一个新的函数 define_discriminatro(),其作用是,定义 base 模型,输入为 4x4 RGB 图像,然后重复增加 blocks 以创建新的判别模型,每次图像的面积翻四倍.
# define the discriminator models for each image resolution
def define_discriminator(n_blocks, input_shape=(4,4,3)):
model_list = list()
# base model input
in_image = Input(shape=input_shape)
# conv 1x1
d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image)
d = LeakyReLU(alpha=0.2)(d)
# conv 3x3 (output block)
d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# conv 4x4
d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# dense output layer
d = Flatten()(d)
out_class = Dense(1)(d)
# define model
model = Model(in_image, out_class)
# compile model
model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# store model
model_list.append([model, model])
# create submodels
for i in range(1, n_blocks):
# get prior model without the fade-on
old_model = model_list[i - 1][0]
# create new model for next resolution
models = add_discriminator_block(old_model)
# store model
model_list.append(models)
return model_list以上函数返回模型列表,其中,列表中的每个项是一个包含两个元素的列表. 这两个元素为两个模型,第一个模型为某个分辨率的模型的 straight-through 版本,第二个为该分辨率的模型的 fade-in 版本.
将以上整合在一起,定义一个新的判别器模型,其从 4x4, 到 8x8 ,最后到 16x16,逐渐增长. n_blocks 参数设置为 3.
完整实现如:
# example of defining discriminator models for the progressive growing gan
from keras.optimizers import Adam
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Conv2D
from keras.layers import AveragePooling2D
from keras.layers import LeakyReLU
from keras.layers import BatchNormalization
from keras.layers import Add
from keras.utils.vis_utils import plot_model
from keras import backend
# weighted sum output
class WeightedSum(Add):
# init with default value
def __init__(self, alpha=0.0, **kwargs):
super(WeightedSum, self).__init__(**kwargs)
self.alpha = backend.variable(alpha, name='ws_alpha')
# output a weighted sum of inputs
def _merge_function(self, inputs):
# only supports a weighted sum of two inputs
assert (len(inputs) == 2)
# ((1-a) * input1) + (a * input2)
output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1])
return output
# add a discriminator block
def add_discriminator_block(old_model, n_input_layers=3):
# get shape of existing model
in_shape = list(old_model.input.shape)
# define new input shape as double the size
input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value)
in_image = Input(shape=input_shape)
# define new input processing layer
d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image)
d = LeakyReLU(alpha=0.2)(d)
# define new block
d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
d = AveragePooling2D()(d)
block_new = d
# skip the input, 1x1 and activation for the old model
for i in range(n_input_layers, len(old_model.layers)):
d = old_model.layers[i](d)
# define straight-through model
model1 = Model(in_image, d)
# compile model
model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# downsample the new larger image
downsample = AveragePooling2D()(in_image)
# connect old input processing to downsampled new input
block_old = old_model.layers[1](downsample)
block_old = old_model.layers[2](block_old)
# fade in output of old model input layer with new input
d = WeightedSum()([block_old, block_new])
# skip the input, 1x1 and activation for the old model
for i in range(n_input_layers, len(old_model.layers)):
d = old_model.layers[i](d)
# define straight-through model
model2 = Model(in_image, d)
# compile model
model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
return [model1, model2]
# define the discriminator models for each image resolution
def define_discriminator(n_blocks, input_shape=(4,4,3)):
model_list = list()
# base model input
in_image = Input(shape=input_shape)
# conv 1x1
d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image)
d = LeakyReLU(alpha=0.2)(d)
# conv 3x3 (output block)
d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# conv 4x4
d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# dense output layer
d = Flatten()(d)
out_class = Dense(1)(d)
# define model
model = Model(in_image, out_class)
# compile model
model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# store model
model_list.append([model, model])
# create submodels
for i in range(1, n_blocks):
# get prior model without the fade-on
old_model = model_list[i - 1][0]
# create new model for next resolution
models = add_discriminator_block(old_model)
# store model
model_list.append(models)
return model_list
# define models
discriminators = define_discriminator(3)
# spot check
m = discriminators[2][1]
m.summary()
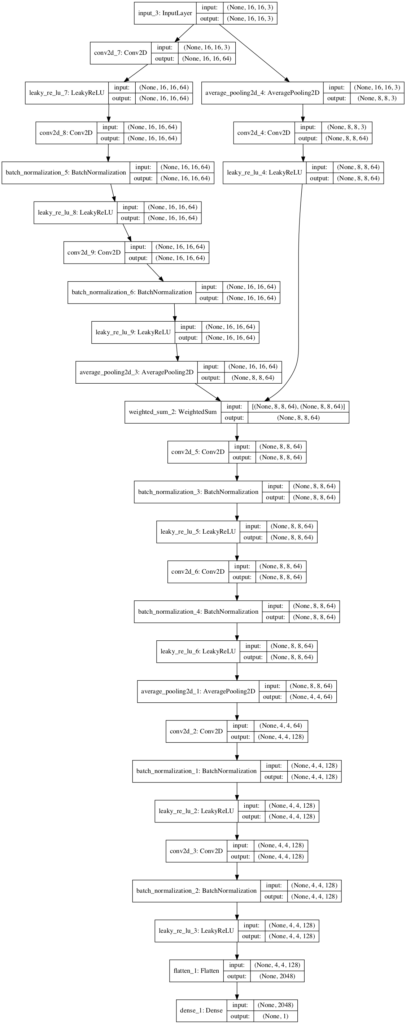
plot_model(m, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True)运行该示例代码,可以看到第三个模型的 fade-in 版本,16x16 RGB 图像作为输入和单个值输出.
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) (None, 16, 16, 3) 0
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 16, 16, 64) 256 input_3[0][0]
__________________________________________________________________________________________________
leaky_re_lu_7 (LeakyReLU) (None, 16, 16, 64) 0 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_7[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 16, 16, 64) 256 conv2d_8[0][0]
__________________________________________________________________________________________________
leaky_re_lu_8 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_8[0][0]
__________________________________________________________________________________________________
average_pooling2d_4 (AveragePoo (None, 8, 8, 3) 0 input_3[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 16, 16, 64) 256 conv2d_9[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 64) 256 average_pooling2d_4[0][0]
__________________________________________________________________________________________________
leaky_re_lu_9 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 8, 8, 64) 0 conv2d_4[1][0]
__________________________________________________________________________________________________
average_pooling2d_3 (AveragePoo (None, 8, 8, 64) 0 leaky_re_lu_9[0][0]
__________________________________________________________________________________________________
weighted_sum_2 (WeightedSum) (None, 8, 8, 64) 0 leaky_re_lu_4[1][0]
average_pooling2d_3[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 64) 36928 weighted_sum_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 8, 8, 64) 256 conv2d_5[2][0]
__________________________________________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_3[2][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 8, 8, 64) 36928 leaky_re_lu_5[2][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 8, 8, 64) 256 conv2d_6[2][0]
__________________________________________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_4[2][0]
__________________________________________________________________________________________________
average_pooling2d_1 (AveragePoo (None, 4, 4, 64) 0 leaky_re_lu_6[2][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 4, 4, 128) 73856 average_pooling2d_1[2][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 4, 4, 128) 512 conv2d_2[4][0]
__________________________________________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_1[4][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 4, 4, 128) 262272 leaky_re_lu_2[4][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 4, 4, 128) 512 conv2d_3[4][0]
__________________________________________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_2[4][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 2048) 0 leaky_re_lu_3[4][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 2049 flatten_1[4][0]
==================================================================================================
Total params: 488,449
Trainable params: 487,425
Non-trainable params: 1,024
__________________________________________________________________________________________________从 8x8 到 16x16 输入图像分辨率的网络结构:
3. ProGAN - Generator
ProGAN 的生成器网络的实现在 Keras 中比判别器模型容易实现. 其原因是,每个 fade-in 都需要一个对应于模型输出的的镜像版本.
增加生成器网络的分辨率包括,首先上采样最后一个网络层块(block) 的输出;然后,将其连接到一个新的 block 和图像的新的输出层,后者将图像的 height 和 width 翻倍,或者面积翻四倍. 此外,在 phase-in 时,上采样还与 old 模型的输出层相连接,两个输出层的输出采用加权平均进行合并.
当 phase-in 完成后,old 输出层被移除.
如下图:
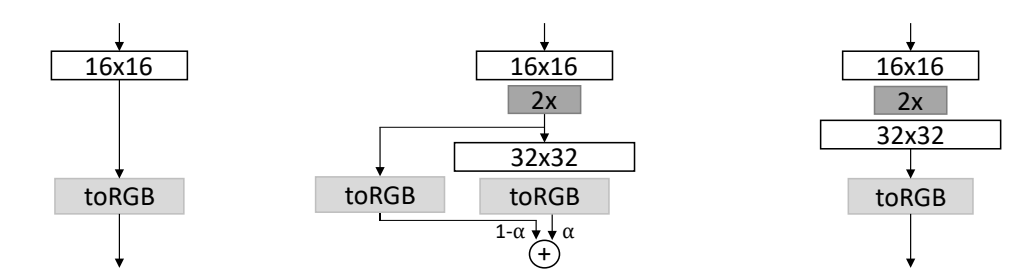
图:Before (a), During (b), and After (c) the Phase-In of a High Resolution.
其中,toRGB 层是 1x1 conv 层,足以输出 RGB 图像(color image).
生成模型采用隐空间(latent space) 中的一个点作为输入,如,100-dim 或 512-dim 向量. 其可以通过缩放(scaled up) 来提供 4x4 激活图(activation maps) 的基点(basis),其后接一个 4x4 conv 层和另一个 3x3 conv 层. 与判别模型一样,使用 LeakyReLU 激活函数以及 pixel normalization.
一个网络层模块(block) 包括一个上采样层和其后接的两个 3x3 conv 层. 上采样是通过 UpSampling2D 层采用最近邻方法(nearest neighbor,如复制输入的行和列)得到的,而不是采用更通用的 transpose conv 层.
完整实现如:
# example of defining generator models for the progressive growing gan
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Reshape
from keras.layers import Conv2D
from keras.layers import UpSampling2D
from keras.layers import LeakyReLU
from keras.layers import BatchNormalization
from keras.layers import Add
from keras.utils.vis_utils import plot_model
from keras import backend
# weighted sum output
class WeightedSum(Add):
# init with default value
def __init__(self, alpha=0.0, **kwargs):
super(WeightedSum, self).__init__(**kwargs)
self.alpha = backend.variable(alpha, name='ws_alpha')
# output a weighted sum of inputs
def _merge_function(self, inputs):
# only supports a weighted sum of two inputs
assert (len(inputs) == 2)
# ((1-a) * input1) + (a * input2)
output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1])
return output
# add a generator block
def add_generator_block(old_model):
# get the end of the last block
block_end = old_model.layers[-2].output
# upsample, and define new block
upsampling = UpSampling2D()(block_end)
g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
# add new output layer
out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g)
# define model
model1 = Model(old_model.input, out_image)
# get the output layer from old model
out_old = old_model.layers[-1]
# connect the upsampling to the old output layer
out_image2 = out_old(upsampling)
# define new output image as the weighted sum of the old and new models
merged = WeightedSum()([out_image2, out_image])
# define model
model2 = Model(old_model.input, merged)
return [model1, model2]
# define generator models
def define_generator(latent_dim, n_blocks, in_dim=4):
model_list = list()
# base model latent input 隐空间输入
in_latent = Input(shape=(latent_dim,))
# linear scale up to activation maps
g = Dense(128 * in_dim * in_dim, kernel_initializer='he_normal')(in_latent)
g = Reshape((in_dim, in_dim, 128))(g)
# conv 4x4, input block
g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
# conv 3x3
g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
# conv 1x1, output block
out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g)
# define model
model = Model(in_latent, out_image)
# store model
model_list.append([model, model])
# create submodels
for i in range(1, n_blocks):
# get prior model without the fade-on
old_model = model_list[i - 1][0]
# create new model for next resolution
models = add_generator_block(old_model)
# store model
model_list.append(models)
return model_list
# define models
generators = define_generator(100, 3)
# spot check
m = generators[2][1]
m.summary()
plot_model(m, to_file='generator_plot.png', show_shapes=True, show_layer_names=True)运行示例代码,可以看到,最后一个模型采用隐空间的点作为输入,并输出 16x16 的 RGB 图像. 这样与期望相同,baseline 模型输出 4x4 图像,增加一个 block 分辨率增加到 8x8,再增加一个 block 分辨率增加到 16x16.
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 100) 0
__________________________________________________________________________________________________
dense_1 (Dense) (None, 2048) 206848 input_1[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 4, 4, 128) 0 dense_1[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 4, 4, 128) 147584 reshape_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 4, 4, 128) 512 conv2d_1[0][0]
__________________________________________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 4, 4, 128) 147584 leaky_re_lu_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 4, 4, 128) 512 conv2d_2[0][0]
__________________________________________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
up_sampling2d_1 (UpSampling2D) (None, 8, 8, 128) 0 leaky_re_lu_2[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 64) 73792 up_sampling2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 8, 8, 64) 256 conv2d_4[0][0]
__________________________________________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 64) 36928 leaky_re_lu_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 8, 8, 64) 256 conv2d_5[0][0]
__________________________________________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
up_sampling2d_2 (UpSampling2D) (None, 16, 16, 64) 0 leaky_re_lu_4[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 16, 16, 64) 36928 up_sampling2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 16, 16, 64) 256 conv2d_7[0][0]
__________________________________________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_5[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 16, 16, 64) 256 conv2d_8[0][0]
__________________________________________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) multiple 195 up_sampling2d_2[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 3) 195 leaky_re_lu_6[0][0]
__________________________________________________________________________________________________
weighted_sum_2 (WeightedSum) (None, 16, 16, 3) 0 conv2d_6[1][0]
conv2d_9[0][0]
==================================================================================================
Total params: 689,030
Trainable params: 688,006
Non-trainable params: 1,024
__________________________________________________________________________________________________网络结构如图:
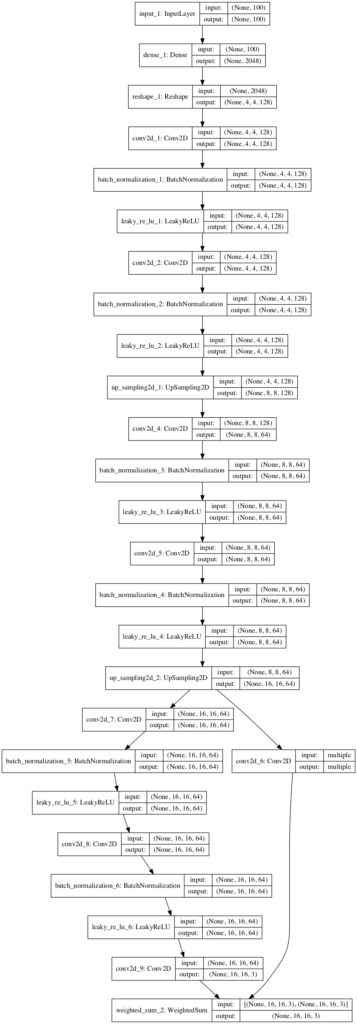
图:8x8 到 16x16 输出图像的 Fade-in 生成网络结构.
可以看出,从最后一个 block 的输出,经过一个 UpSample2D 层处理,才再送入新增的 block和新增输出层;并和 old 输出层一起加权和合并送入最终的输出层.
4. ProGAN - Composite
How to Implement Composite Models for Updating the Generator?
判别模型是采用 real 和 fake 图像作为输入进行直接训练的,其输出值 fake 为 0,real 为 1.
但,生成模型不是直接训练的,其是通过判别模型间接进行训练的,类似于其他 GAN 模型.
对此,可以对于每一个模型增长层创建一个 composite 模型,如,4x4 生成模型和 4x4 判别模型对(pair). 此外,还可以将 straight-through 模型组队在一起,fade-in 模型组队在一起.
例如,对于给定增长层,检索其生成模型和判别模型,如:
g_models, d_models = generators[0], discriminators[0]然后,将他们用于创建 composite 模型,以训练 straight-through 生成模型. 生成模型的输出被直接送入判别模型,以进行分类.
# straight-through model
d_models[0].trainable = False
model1 = Sequential()
model1.add(g_models[0])
model1.add(d_models[0])
model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))同样地,创建 fade-in 生成模型的 composite 模型:
# fade-in model
d_models[1].trainable = False
model2 = Sequential()
model2.add(g_models[1])
model2.add(d_models[1])
model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))对此,可以定义函数 define_composite(),其功能为:给定定义的判别模型和生成模型的列表,自动创建 composite 模型,以训练每个生成模型.
# define composite models for training generators via discriminators
def define_composite(discriminators, generators):
model_list = list()
# create composite models
for i in range(len(discriminators)):
g_models, d_models = generators[i], discriminators[i]
# straight-through model
d_models[0].trainable = False
model1 = Sequential()
model1.add(g_models[0])
model1.add(d_models[0])
model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# fade-in model
d_models[1].trainable = False
model2 = Sequential()
model2.add(g_models[1])
model2.add(d_models[1])
model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# store
model_list.append([model1, model2])
return model_listDiscriminator、Generator、Composite 模型定义完整实现如下:
# example of defining composite models for the progressive growing gan
from keras.optimizers import Adam
from keras.models import Sequential
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Reshape
from keras.layers import Conv2D
from keras.layers import UpSampling2D
from keras.layers import AveragePooling2D
from keras.layers import LeakyReLU
from keras.layers import BatchNormalization
from keras.layers import Add
from keras.utils.vis_utils import plot_model
from keras import backend
# weighted sum output
class WeightedSum(Add):
# init with default value
def __init__(self, alpha=0.0, **kwargs):
super(WeightedSum, self).__init__(**kwargs)
self.alpha = backend.variable(alpha, name='ws_alpha')
# output a weighted sum of inputs
def _merge_function(self, inputs):
# only supports a weighted sum of two inputs
assert (len(inputs) == 2)
# ((1-a) * input1) + (a * input2)
output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1])
return output
# add a discriminator block
def add_discriminator_block(old_model, n_input_layers=3):
# get shape of existing model
in_shape = list(old_model.input.shape)
# define new input shape as double the size
input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value)
in_image = Input(shape=input_shape)
# define new input processing layer
d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image)
d = LeakyReLU(alpha=0.2)(d)
# define new block
d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
d = AveragePooling2D()(d)
block_new = d
# skip the input, 1x1 and activation for the old model
for i in range(n_input_layers, len(old_model.layers)):
d = old_model.layers[i](d)
# define straight-through model
model1 = Model(in_image, d)
# compile model
model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# downsample the new larger image
downsample = AveragePooling2D()(in_image)
# connect old input processing to downsampled new input
block_old = old_model.layers[1](downsample)
block_old = old_model.layers[2](block_old)
# fade in output of old model input layer with new input
d = WeightedSum()([block_old, block_new])
# skip the input, 1x1 and activation for the old model
for i in range(n_input_layers, len(old_model.layers)):
d = old_model.layers[i](d)
# define straight-through model
model2 = Model(in_image, d)
# compile model
model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
return [model1, model2]
# define the discriminator models for each image resolution
def define_discriminator(n_blocks, input_shape=(4,4,3)):
model_list = list()
# base model input
in_image = Input(shape=input_shape)
# conv 1x1
d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image)
d = LeakyReLU(alpha=0.2)(d)
# conv 3x3 (output block)
d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# conv 4x4
d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# dense output layer
d = Flatten()(d)
out_class = Dense(1)(d)
# define model
model = Model(in_image, out_class)
# compile model
model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# store model
model_list.append([model, model])
# create submodels
for i in range(1, n_blocks):
# get prior model without the fade-on
old_model = model_list[i - 1][0]
# create new model for next resolution
models = add_discriminator_block(old_model)
# store model
model_list.append(models)
return model_list
# add a generator block
def add_generator_block(old_model):
# get the end of the last block
block_end = old_model.layers[-2].output
# upsample, and define new block
upsampling = UpSampling2D()(block_end)
g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
# add new output layer
out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g)
# define model
model1 = Model(old_model.input, out_image)
# get the output layer from old model
out_old = old_model.layers[-1]
# connect the upsampling to the old output layer
out_image2 = out_old(upsampling)
# define new output image as the weighted sum of the old and new models
merged = WeightedSum()([out_image2, out_image])
# define model
model2 = Model(old_model.input, merged)
return [model1, model2]
# define generator models
def define_generator(latent_dim, n_blocks, in_dim=4):
model_list = list()
# base model latent input
in_latent = Input(shape=(latent_dim,))
# linear scale up to activation maps
g = Dense(128 * in_dim * in_dim, kernel_initializer='he_normal')(in_latent)
g = Reshape((in_dim, in_dim, 128))(g)
# conv 4x4, input block
g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
# conv 3x3
g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g)
g = BatchNormalization()(g)
g = LeakyReLU(alpha=0.2)(g)
# conv 1x1, output block
out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g)
# define model
model = Model(in_latent, out_image)
# store model
model_list.append([model, model])
# create submodels
for i in range(1, n_blocks):
# get prior model without the fade-on
old_model = model_list[i - 1][0]
# create new model for next resolution
models = add_generator_block(old_model)
# store model
model_list.append(models)
return model_list
# define composite models for training generators via discriminators
def define_composite(discriminators, generators):
model_list = list()
# create composite models
for i in range(len(discriminators)):
g_models, d_models = generators[i], discriminators[i]
# straight-through model
d_models[0].trainable = False
model1 = Sequential()
model1.add(g_models[0])
model1.add(d_models[0])
model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# fade-in model
d_models[1].trainable = False
model2 = Sequential()
model2.add(g_models[1])
model2.add(d_models[1])
model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
# store
model_list.append([model1, model2])
return model_list
# define models
discriminators = define_discriminator(3)
# define models
generators = define_generator(100, 3)
# define composite models
composite = define_composite(discriminators, generators)5. ProGAN 训练
Generator、Discriminator、Composite 模型的定义是比较困难的一步;而模型训练是比较直接的,和其他 GAN 的训练相似.
重要的点是,在每次训练迭代中,每个 WeightedSum 层的 alpha 变量必须被设置为一个新的值. 且必须是对生成模型和判别模型中的 WeightedSum 网络层都是要设置的,以使得 old 模型网络层到 new 模型网络层能够平滑线性过渡,如,alpha 值设定为训练迭代的固定数量的 0-1 之间的值.
定义 update_fadein() 函数如下:
# update the alpha value on each instance of WeightedSum
def update_fadein(models, step, n_steps):
# calculate current alpha (linear from 0 to 1)
alpha = step / float(n_steps - 1)
# update the alpha for each model
for model in models:
for layer in model.layers:
if isinstance(layer, WeightedSum):
backend.set_value(layer.alpha, alpha)定义 train_epochs 函数,其主要实现,第一个判别模型对于 real 和 fake 图像进行更新,然后生成模型进行更新. 重复该过程.
train_epochs 函数会调用如下几个函数:
generate_real_samples()- 检索一个 real images batch;generate_fake_samples()- 生成模型生成一个 fake 样本 batch;generate_latent_points()- 在隐空间生成样本点.
# train a generator and discriminator
def train_epochs(g_model, d_model, gan_model, dataset, n_epochs, n_batch, fadein=False):
# calculate the number of batches per training epoch
bat_per_epo = int(dataset.shape[0] / n_batch)
# calculate the number of training iterations
n_steps = bat_per_epo * n_epochs
# calculate the size of half a batch of samples
half_batch = int(n_batch / 2)
# manually enumerate epochs
for i in range(n_steps):
# update alpha for all WeightedSum layers when fading in new blocks
if fadein:
update_fadein([g_model, d_model, gan_model], i, n_steps)
# prepare real and fake samples
X_real, y_real = generate_real_samples(dataset, half_batch)
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
# update discriminator model
d_loss1 = d_model.train_on_batch(X_real, y_real)
d_loss2 = d_model.train_on_batch(X_fake, y_fake)
# update the generator via the discriminator's error
z_input = generate_latent_points(latent_dim, n_batch)
y_real2 = ones((n_batch, 1))
g_loss = gan_model.train_on_batch(z_input, y_real2)
# summarize loss on this batch
print('>%d, d1=%.3f, d2=%.3f g=%.3f' % (i+1, d_loss1, d_loss2, g_loss))图像必须根据每个模型的尺寸进行缩放. 如果图像是 in-memory,则可以定义个简单的 scale_dataset() 函数用于缩放加载的图像.
# scale images to preferred size
def scale_dataset(images, new_shape):
images_list = list()
for image in images:
# resize with nearest neighbor interpolation
new_image = resize(image, new_shape, 0)
# store
images_list.append(new_image)
return asarray(images_list)首先,训练 baseline 模型多个 epochs,如,模型输出 4x4 图像. 此时,需要将加载的图像缩放到生成模型输出层的 shape.
# fit the baseline model
g_normal, d_normal, gan_normal = g_models[0][0], d_models[0][0], gan_models[0][0]
# scale dataset to appropriate size
gen_shape = g_normal.output_shape
scaled_data = scale_dataset(dataset, gen_shape[1:])
print('Scaled Data', scaled_data.shape)
# train normal or straight-through models
train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch)然后,也可以处理每个增长层,如, 8x8. 此时,需要先检测模型,将图像缩放到对应的尺寸;然后送入 fade-in 模型. 以循环的方式重复.
# process each level of growth
for i in range(1, len(g_models)):
# retrieve models for this level of growth
[g_normal, g_fadein] = g_models[i]
[d_normal, d_fadein] = d_models[i]
[gan_normal, gan_fadein] = gan_models[i]
# scale dataset to appropriate size
gen_shape = g_normal.output_shape
scaled_data = scale_dataset(dataset, gen_shape[1:])
print('Scaled Data', scaled_data.shape)
# train fade-in models for next level of growth
train_epochs(g_fadein, d_fadein, gan_fadein, scaled_data, e_fadein, n_batch)
# train normal or straight-through models
train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch)整合以上函数,定义 train() 函数,以训练 ProGAN :
# train the generator and discriminator
def train(g_models, d_models, gan_models, dataset, latent_dim, e_norm, e_fadein, n_batch):
# fit the baseline model
g_normal, d_normal, gan_normal = g_models[0][0], d_models[0][0], gan_models[0][0]
# scale dataset to appropriate size
gen_shape = g_normal.output_shape
scaled_data = scale_dataset(dataset, gen_shape[1:])
print('Scaled Data', scaled_data.shape)
# train normal or straight-through models
train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch)
# process each level of growth
for i in range(1, len(g_models)):
# retrieve models for this level of growth
[g_normal, g_fadein] = g_models[i]
[d_normal, d_fadein] = d_models[i]
[gan_normal, gan_fadein] = gan_models[i]
# scale dataset to appropriate size
gen_shape = g_normal.output_shape
scaled_data = scale_dataset(dataset, gen_shape[1:])
print('Scaled Data', scaled_data.shape)
# train fade-in models for next level of growth
train_epochs(g_fadein, d_fadein, gan_fadein, scaled_data, e_fadein, n_batch, True)
# train normal or straight-through models
train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch)e_norm 参数用于指定 normal 阶段训练的 epochs 数;e_fadein 参数用于指定 fade-in 阶段的 epochs 数.
epochs 数必须基于图像数据集来指定,每个阶段可以设置相同的 epochs 数,如论文里所述.
We start with 4×4 resolution and train the networks until we have shown the discriminator 800k real images in total. We then alternate between two phases: fade in the first 3-layer block during the next 800k images, stabilize the networks for 800k images, fade in the next 3-layer block during 800k images, etc.
# number of growth phase, e.g. 3 = 16x16 images
n_blocks = 3
# size of the latent space
latent_dim = 100
# define models
d_models = define_discriminator(n_blocks)
# define models
g_models = define_generator(100, n_blocks)
# define composite models
gan_models = define_composite(d_models, g_models)
# load image data
dataset = load_real_samples()
# train model
train(g_models, d_models, gan_models, dataset, latent_dim, 100, 100, 16)6. 相关材料
Official
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, Official.
- progressive_growing_of_gans Project (official), GitHub.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation. Open Review.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, YouTube.
- Progressive growing of GANs for improved quality, stability and variation, KeyNote, YouTube.
API
- Keras Datasets API.
- Keras Sequential Model API
- Keras Convolutional Layers API
- How can I “freeze” Keras layers?
- Keras Contrib Project
- skimage.transform.resize API
Articles
- Keras-progressive_growing_of_gans Project, GitHub.
- Hands-On-Generative-Adversarial-Networks-with-Keras Project, GitHub.
- How to Accelerate Learning of Deep Neural Networks With Batch Normalization
- Generative Adversarial Networks with Python
- How to Train a Progressive Growing GAN in Keras for Synthesizing Faces