scikit-learning 提供了 sklearn.cluster 模块,以用于无标签数据的聚类.
sklearn.cluster 模块共提供了一下几种聚类算法:
[1] - K-means
[2] - Affinity Propagation
[3] - Mean Shift
[4] - Spectral clustering
[5] - Hierarchical clustering
[6] - DBSCAN
[7] - OPTICS
[8] - Birch
每一种聚类算法包含两部分:
[1] - 一个类(class),实现 fit 方法,以对训练数据进行聚类.
[2] - 一个函数(function),对于给定训练数据,返回对应于不同聚类的整数类别标签数组.
对于该 class,训练数据的聚类标签可以通过 labels_ 属性得到.
输入数据:
[1] - sklearn.cluster 中的聚类算法支持不同类型的矩阵作为输入.
[2] - 所有的聚类算法都支持标准的 [nsamples, nfeatures] 形式的数据矩阵.
特征提取模块:
sklearn.feature_extraction
[3] - AffinityPropagation, SpectralClustering 和 DBSCAN 还支持 [nsamples, nsamples]形式的相似性矩阵作为输入.
相似性矩阵计算模块:
sklearn.metrics.pairwise
1. 不同聚类算法对比
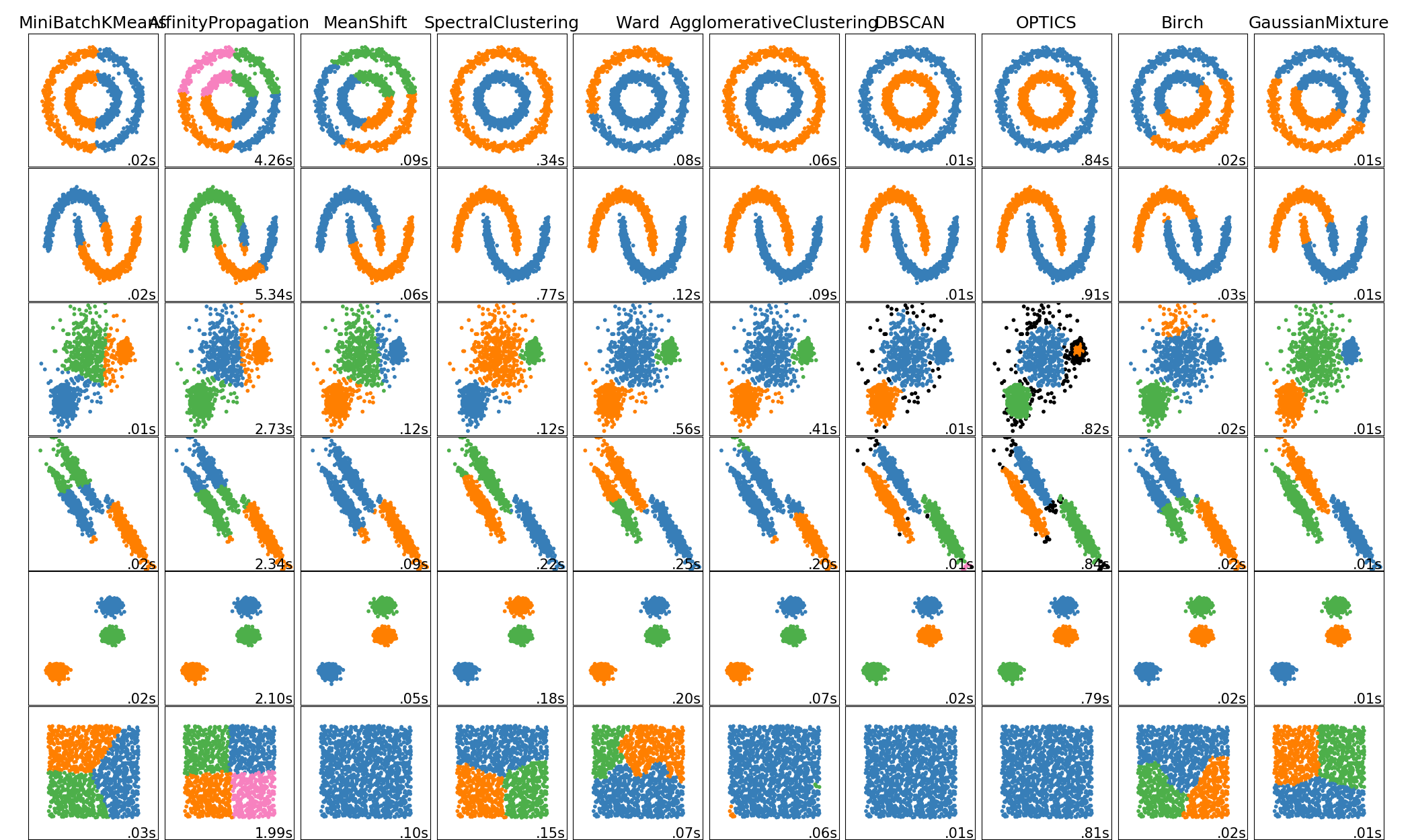
| 算法名 | 参数 | Scalability | 使用场景 | Geometry (metric used) |
|---|---|---|---|---|
| K-Means | number of clusters | Very large n_samples, medium n_clusters with MiniBatch code | General-purpose, even cluster size, flat geometry, not too many clusters | Distances between points |
| Affinity propagation | damping, sample preference | Not scalable with n_samples | Many clusters, uneven cluster size, non-flat geometry | Graph distance (e.g. nearest-neighbor graph) |
| Mean-shift | bandwidth | Not scalable with n_samples | Many clusters, uneven cluster size, non-flat geometry | Distances between points |
| Spectral clustering | number of clusters | Medium n_samples, small n_clusters | Few clusters, even cluster size, non-flat geometry | Graph distance (e.g. nearest-neighbor graph) |
| Ward hierarchical clustering | number of clusters or distance threshold | Large n_samples and n_clusters | Many clusters, possibly connectivity constraints | Distances between points |
| Agglomerative clustering | number of clusters or distance threshold, linkage type, distance | Large n_samples and n_clusters | Many clusters, possibly connectivity constraints, non Euclidean distances | Any pairwise distance |
| DBSCAN | neighborhood size | Very large n_samples, medium n_clusters | Non-flat geometry, uneven cluster sizes | Distances between nearest points |
| OPTICS | minimum cluster membership | Very large n_samples, large n_clusters | Non-flat geometry, uneven cluster sizes, variable cluster density | Distances between points |
| Gaussian mixtures | many | Not scalable | Flat geometry, good for density estimation | Mahalanobis distances to centers |
| Birch | branching factor, threshold, optional global clusterer. | Large n_clusters and n_samples | Large dataset, outlier removal, data reduction. | Euclidean distance between points |