Visual Genome dataset
李飞飞组
数据子集: 区域描述, 对象, 属性, 关系, 区域图, 场景图, 问答对
Visual Genome 数据集总览:
- 108077 张图片
- 5.4 Million Region Descriptions
- 1.7 Million Visual Question Answers
3.8 Million Object Instances
2.8 Million Attributes
2.3 Million Relationships
Everything Mapped to Wordnet Synsets
标注数据:
objects,attributes,图片内的 relationships共 108K 张图片,每张图片平均有, 35 个 objects,26 个 attributes,21对 objects 见的成对 relationships.
1. Visual Genome 数据标注
数据集主要包括七个主要部分:
- region descriptions
- objects
- attributes
- relationships
- region graphs
- scene graphs
- question answer pairs
1.1. Region Descriptions

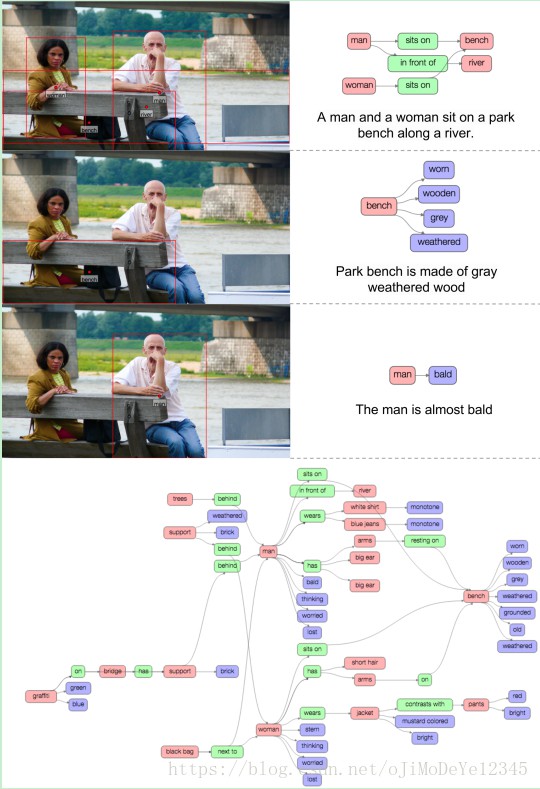
数据集标注了图片的 regions descriptions,每个 region 有一个 bounding box.
如上图中,图片有三个 regions descriptions: “man jumping over a fire hydrant,”,“yellow fire hydrant,” 和
“woman in shorts is standing behind the man.”.
1.2. Objects
数据集中每张图片平均有 35 个 objects,每个 object 采用 bounding box 标注.
如图:

MS-COCO 数据集 只标注了 80 个 object categories,没有描述图片中的所有 objects. 实际场景中,可能有更多的 objects 类别.
Visual Genome 数据集旨在对图片里出现的所有视觉 objects 进行标注,objects categories 类别达到 33877 种.
1.3. Attributes
数据集中每张图片平均有 26 个 attributes. Objects 可能没有或者有更多的相关 attributes.
Attributes 可以是 color(如 yellow),states(如 standing) 等,如图:

Attributes 能够对 objects 进行更容易的描述、对比与分类. 即使以前未见到某 object,根据 attributes 仍能推断出与 object 相关的东西. 如,“yellow and brown spotted with long neck(长脖子上有黄色和棕色的斑点)”,很可能推断出 object 是 giraffe(长颈鹿).
关于 attributes 的研究:
- 采用examplar SVMs,利用相似特征来寻找 objects;
- 采用纹理(textures) 研究 objects,或者预测颜色.
- 采用 attributes 来提高目标分类结果. 如 fine-grained 识别.
Attributes 一般被定义为 parts(如 has legs)、shapes(如,spherical球形的)、materials(如 furry毛皮的);用于对新的 objects 类别进行分类.
Visual Genome 数据集对于 attributes 进行扩展,其 attributes 不是 image-specific 的,而是真实场景中 object-specific 的. attributes 类型包括:size(如 small), pose(如bent), state (如 transparent), emotion (如 happy)等等.
- 基于 VGG16 的 attributes 预测结果:

1.4. Relationships
Relationships 是两个 objects 的连接关系.
Relationships 可以是 actions(如 jumping over),spatial(如 is build),comparative(如 taller than),prepositional phrases (如 drive on). 如图:

- Relationship 预测结果:

1.5. Region Graphs
结合 objects、attributes 以及 region descriptions 提取的 relationships,创建每个 regions 的 graph representation.
1.6. Scene Graphs
Region graphs 是图片的局部区域表示,将 region graphs 结合,生成单个 scene graph来表示整张图片.
Scene graph 是全部 region graphs 的统一,包含了全部的 objects、attributes以及每个 region description 的 relationships.
Scene Graph 将多种不同层次的 scene 信息以更加一致的方式结合在一起.
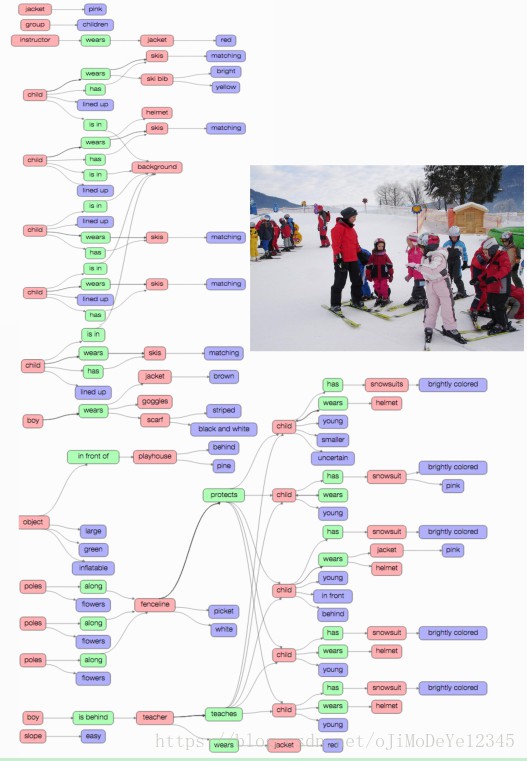
1.7. Question Answer(QA) Pairs
数据集中每张图片有两种类型的 QA pairs:
- freeform QAs - 基于整张图片;
- region-based QAs - 基于图片的选择区域.
每张图片标注了 6 中不同类型的问题:what, where, how, when, who, why.
如图:

Figure . Visual Genome 数据集. 每张图片包括:region descriptions - 描述了图像的局部信息;两种类型的 question answer pairs(QAs) - free form QAs 和 region-based QAs. 每个 region 转化为 objects、attributes 和 pairwise relationships region 构成的 region graph 表示. 最终, 结合 region graphs 以形成图片内全部 objects 的 scene graph.
2. Visual Genome 数据集应用
基本应用:
- attribute classification 属性分类
- relationship classification 关系分类
- description generation 描述生成
- question answering QA
更多应用:
- Dense image captioning
- Visual question answering
- Image understanding
- Relationship extraction
- Semantic image retrieval
- Completing the Set of Annotations
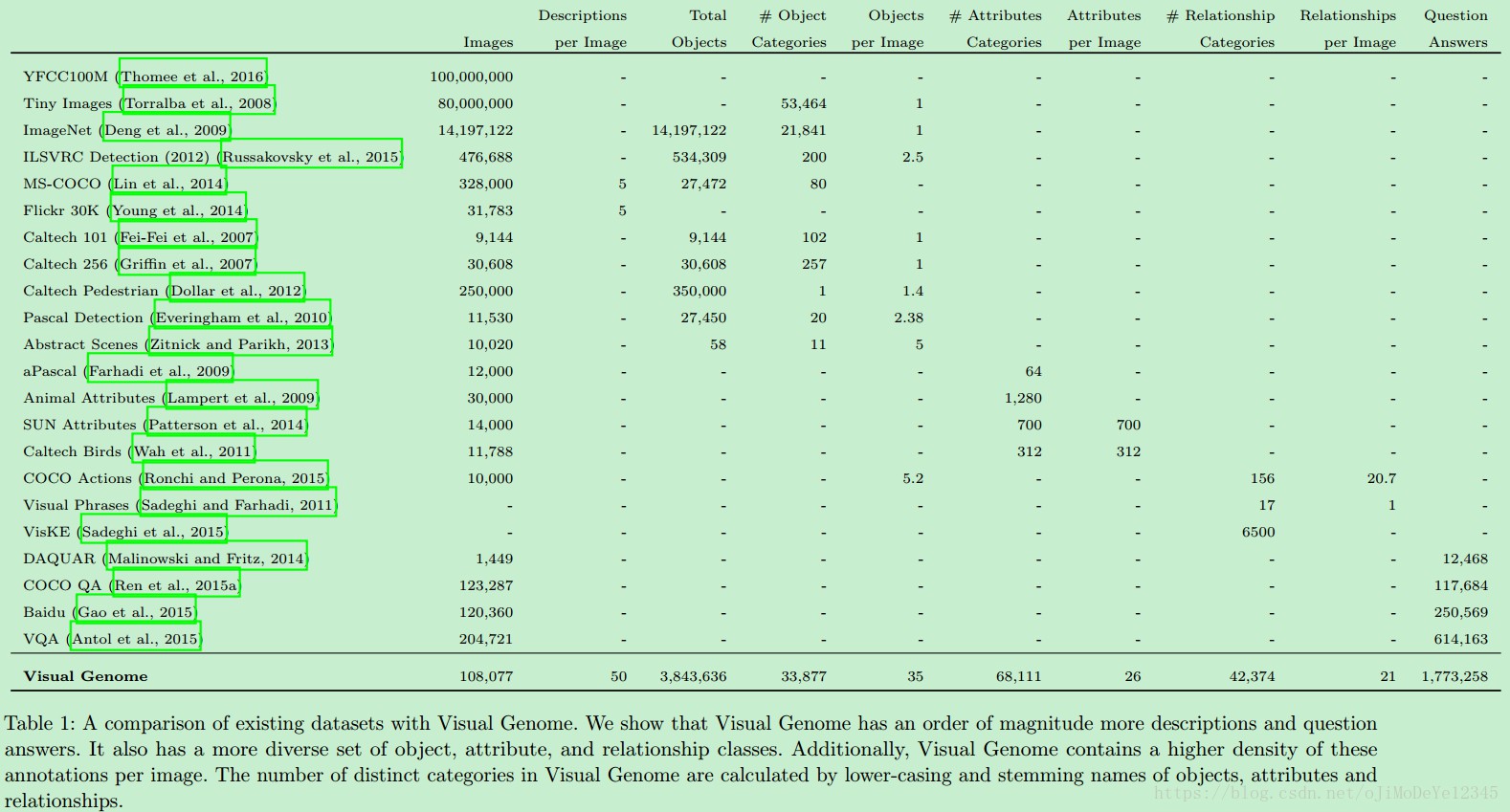
注 - 与其它数据集对比:
3. Reference
[1] - Visual Genome Home
[1] - Visual Genome Doc