论文:CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images - ECCV2018
论文阅读学习 - CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images - AIUAI
CurriculumNet 框架:
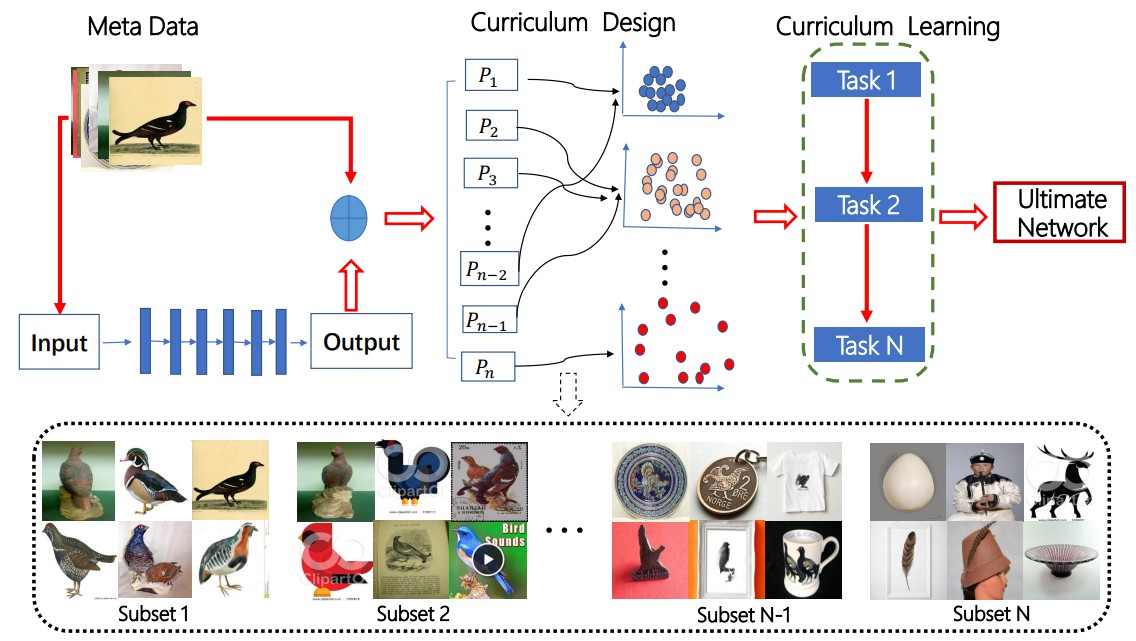
这里实现了关于论文里基于密度聚类算法(density-based clustering algorithm) 创建学习课程,以采用数据分布密度来评估训练样本的复杂度 - curriculum_clustering.
1. Models
基于的 Caffe 版本: OpenMPI-based Multi-GPU - https://github.com/yjxiong/caffe/
Models
[1] - CurriculumNet(WebVision)
- 预训练模型 - inception_v2_webvision.caffemodel
- 网络定义 - inception_v2_deploy_webvision.prototxt
- 训练数据集 - WebVision 1.0
[2] - CurriculumNet(WebVision+ImageNet)
- 预训练模型 - inception_v2_web_img.caffemodel
- 网络定义 - inception_v2_deploy_web_img.prototxt
- 训练数据集 - WebVision 1.0 + ImageNet
模型精度:
| Name | WebVision (Top-1) | WebVision (Top-5) | ImageNet (Top-1) | ImageNet (Top-5) |
|---|---|---|---|---|
| CurriculumNet(WebVision) | 27.9 | 10.8 | 35.2 | 15.1 |
| CurriculumNet(WebVision+ImageNet) | 24.7 | 8.5 | 24.8 | 7.1 |
2. curriculum_clustering
curriculum_clustering
课程聚类算法(Curriculum clustering algorithm):
在教授特定概念时,将学习的课程分解为由易到难,由简单到复杂,是很有帮助的.
对于机器学习中的一个课程,其包含不同难度的子集. 相比较于随机采样,从最简单的样本开始学习,然后逐渐到最复杂的样本.
这样,机器在遇到很复杂的样本前,能够建立对特定概念的坚实基础. 从简单样本开始学习,有助于机器对噪声(noisy, complex) 样本的学习.
这种半监督学习方法被称为课程学习(Curriculum Learning, CurriculumNet).
课程学习的输入是特征向量集合和其对应的概念(类别)标签.
正常情况下,聚类算法不需要标签,但,课程学习算法需要标签(通常是噪声的noisy). 因为课程学习算法时根据递增复杂的课程来表示待学习概念的(they represent the concepts that should be learned over a curriculum of increasing complexity).
课程的数据子集数量是由子集参数设定的.
课程聚类算法会以无监督方式,根据样本的分布密度,将每个概念类别的样本聚类为 N 个样本子集(The algorithm will cluster each concept category into N subsets using distribution density in an unsupervised manner.)
对于计算机视觉领域的应用,每个向量表示一张图像.
具有较高分布密度值的课程样本子集,其在特征空间内,所有的图像彼此很接近,即图像间具有较强的相似性. 称之为 干净(clean)数据集,其大部分样本标签时正确的.
具有较小分布密度值的课程样本子集,其图像具有较大的视觉表征差异性,可能包含更多的不正确标签的不相关图像. 称之为 噪声(noisy) 数据集.
因此,对于每一类别图像,这里生成多个样本子集,根据复杂度递增的顺序分别为: clean, noisy, highly noisy.
# -*- coding: utf-8 -*-
import time
import numpy as np
from sklearn.base import BaseEstimator, ClusterMixin
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.utils import check_array, check_consistent_length, gen_batches
def cluster_curriculum_subsets(X, y,
n_subsets=3,
method='default',
density_t=0.6,
verbose=False,
dim_reduce=256,
batch_max=500000,
random_state=None,
calc_auxiliary=False):
"""
对向量数组或距离矩阵,计算 Curriculum Clustering.
通过分析分布密度,将每一类别样本聚类为 n 个样本子集.
Parameters
----------
X : 数组或稀疏CSR矩阵,shape 为 (n_samples, n_features) 或 (n_samples, n_samples).
特征数组(样本的嵌入空间表示.)
y : array-like, size=[n_samples]
类别标签.
curriculum 会将每一类别自动聚类为 N 个子集.
verbose : bool, optional, default False
是否打印处理信息.
density_t : float, optional
邻近样本被聚类到一个子集的密度阈值.
n_subsets : int, optional (default = 3)
每一类别被聚类到的子集数量.
例如,设为 3,则输出类别会被设为 0,1,2.
0 - 最简单的样本(最相似样本);
1 - 中级难度样本(有些相似样本);
2 - 最复杂样本(大部分不同样本).
random_state : int, RandomState instance or None (default), optional
算法内用于随机选择的生成器.
设置 int 值,实现随机的确定化.
method : {'default', 'gaussian'}, optional
用于计算局部密度值的算法.
默认采用参考 CurriculumNet 论文里说明的算法.
dim_reduce : int, optional (default = 256)
特征向量降维后的数,先于距离计算.
维数越低,则速度越快,但精度降低. 反之.
batch_max : int, optional (default = 500000)
一次处理特征向量的最大 batch 数.(加载到内存的)
calc_auxiliary : bool, optional (default = False)
提供的辅助参数,如 delta centers 和 density centers.
有助于可视化,代码调试等.
其会导致处理时间明显增加.
Returns
-------
all_clustered_labels : array [n_samples]
每个样本点的聚类标签.根据由简单到复杂的次序整合.
如,如果 curriculum subsets=3,
则,label=0 - simplest, labels=1 - harder, label=n - hardest.
auxiliary_info : list
如果设置 calc_auxiliar=True,则该列表会包含在聚类过程中收集的辅助信息,
如,delta centers 等.
"""
if not density_t > 0.0:
raise ValueError("density_thresh must be positive.")
X = check_array(X, accept_sparse='csr')
check_consistent_length(X, y)
unique_categories = set(y)
t0 = None
pca = None
auxiliary_info = []
if X.shape[1] > dim_reduce:
pca = PCA(n_components=dim_reduce,
copy=False,
random_state=random_state)
# 初始化所有的标签为 negative,表示 un-clustered 'noise'.
# 聚类处理后,标签里应该包含 no negatives.
all_clustered_labels = np.full(len(y), -1, dtype=np.intp)
for cluster_idx, current_category in enumerate(unique_categories):
if verbose:
t0 = time.time()
# 收集特定类别的“学习材料”("learning material")
dist_list = [i for i, label in enumerate(y)
if label == current_category]
for batch_range in gen_batches(len(dist_list), batch_size=batch_max):
batch_dist_list = dist_list[batch_range]
# 加载数据样本子集
subset_vectors = np.zeros((len(batch_dist_list), X.shape[1]), dtype=np.float32)
for subset_idx, global_idx in enumerate(batch_dist_list):
subset_vectors[subset_idx, :] = X[global_idx, :]
# 计算距离 distances
if pca:
subset_vectors = pca.fit_transform(subset_vectors)
m = np.dot(subset_vectors, np.transpose(subset_vectors))
t = np.square(subset_vectors).sum(axis=1)
distance = np.sqrt(np.abs(-2 * m + t + np.transpose(np.array([t]))))
# 计算密度 densities
if method == 'gaussian':
densities = np.zeros((len(subset_vectors)), dtype=np.float32)
distance = distance / np.max(distance)
for i in xrange(len(subset_vectors)):
densities[i] = np.sum(1 / np.sqrt(2 * np.pi) * np.exp((-1) * np.power(distance[i], 2) / 2.0))
else:
densities = np.zeros((len(subset_vectors)), dtype=np.float32)
flat_distance = distance.reshape(distance.shape[0] * distance.shape[1])
dist_cutoff = np.sort(flat_distance)[int(distance.shape[0] * distance.shape[1] * density_t)]
for i in xrange(len(batch_dist_list)):
densities[i] = len(np.where(distance[i] < dist_cutoff)[0]) - 1 # remove itself
if len(densities) < n_subsets:
raise ValueError("Cannot cluster into {} subsets due to "
"lack of density diversification, "
"please try a smaller n_subset number."
.format(n_subsets))
# 可选, 计算辅助信息 auxiliary info
if calc_auxiliary:
# 计算 deltas
deltas = np.zeros((len(subset_vectors)), dtype=np.float32)
densities_sort_idx = np.argsort(densities)
for i in xrange(len(densities_sort_idx) - 1):
larger = densities_sort_idx[i + 1:]
larger = larger[np.where(larger != densities_sort_idx[i])] # remove itself
deltas[i] = np.min(distance[densities_sort_idx[i], larger])
# 找出 centers 和 package
center_id = np.argmax(densities)
center_delta = np.max(distance[np.argmax(densities)])
center_density = densities[center_id]
auxiliary_info.append((center_id, center_delta, center_density))
model = KMeans(n_clusters=n_subsets, random_state=random_state)
model.fit(densities.reshape(len(densities), 1))
clusters = [densities[np.where(model.labels_ == i)]
for i in xrange(n_subsets)]
n_clusters_made = len(set([k for j in clusters for k in j]))
if n_clusters_made < n_subsets:
raise ValueError("Cannot cluster into {} subsets,"
" please try a smaller n_subset number, "
" such as {}."
.format(n_subsets, n_clusters_made))
cluster_mins = [np.min(c) for c in clusters]
bound = np.sort(np.array(cluster_mins))
# 分发到 curriculum 样本子集,
# 并打包成全局调整的可返回数组.
# Distribute into curriculum subsets, and
# package into global adjusted returnable array,
# optionally aux too
other_bounds = xrange(n_subsets - 1)
for i in xrange(len(densities)):
# Check if the most 'clean'
if densities[i] >= bound[n_subsets - 1]:
all_clustered_labels[batch_dist_list[i]] = 0
# Else, check the others
else:
for j in other_bounds:
if bound[j] <= densities[i] < bound[j + 1]:
all_clustered_labels[batch_dist_list[i]] =
len(bound) - j - 1
if verbose:
print "Clustering {} of {} categories into {} "
"curriculum subsets ({:.2f} secs)."
.format(cluster_idx + 1,
len(unique_categories),
n_subsets,
time.time() - t0)
if (all_clustered_labels > 0).all():
raise ValueError("A clustering error occurred: incomplete labels detected.")
return all_clustered_labels, auxiliary_info
class CurriculumClustering(BaseEstimator, ClusterMixin):
"""
对向量数组或距离矩阵计算 Curriculum Clustering.
参数和返回值,同:cluster_curriculum_subsets() 函数.
"""
def __init__(self,
n_subsets=3,
method='default',
density_t=0.6,
verbose=False,
dim_reduce=256,
batch_max=500000,
random_state=None,
calc_auxiliary=False):
self.n_subsets = n_subsets
self.method = method
self.density_t = density_t
self.verbose = verbose
self.output_labels = None
self.random_state = random_state
self.dim_reduce = dim_reduce
self.batch_max = batch_max
self.calc_auxiliary = calc_auxiliary
def fit(self, X, y):
"""
进行 curriculum clustering.
Parameters
----------
X : array or sparse (CSR) matrix,
shape - (n_samples, n_features), 或 (n_samples, n_samples)
y : array-like, size=[n_samples]
category labels
"""
X = check_array(X, accept_sparse='csr')
check_consistent_length(X, y)
self.output_labels, _ = cluster_curriculum_subsets(X, y, **self.get_params())
return self
def fit_predict(self, X, y=None):
"""
对 X 进行 curriculum clustering,
并返回聚类后的标签(样本子集).
"""
self.fit(X, y)
return self.output_labels3. Curriculum 聚类 demo
参考:test_via_webvision.py
基于 WebVision dataset v1.0 数据集的 curriculum_clustering 测试.
这里提供的测试数据集包含了模型提取的特征和 WebVision dataset 1.0 数据集的前 10 类别的标签.
类别名:class names - webvision_cls0-9.txt
提取的特征:https://sai-pub.s3.cn-north-1.amazonaws.com.cn/malong-research/curriculumnet/webvision_cls0-9.npy(约 100MB)
将模型提取的特征文件到本地路径后,即可测试 demo.py
# -*- coding: utf-8 -*-
import os
import shutil
import tempfile
import urllib
import numpy as np
from curriculum_clustering import CurriculumClustering
def test_curriculum_cluster():
# 加载特征数据
# X - 25744x1024
# y - 25744x1
X, y, metadata = load_webvision_data()
# CurriculumClustering 聚类
cc = CurriculumClustering(n_subsets=3, verbose=True, random_state=0)
cc.fit(X, y)
# 将结果写入到 txt 文件
verify_webvision_expected_clusters(labels=cc.output_labels,
n_subsets=cc.n_subsets,
metadata=metadata)
def load_webvision_data():
# 加载 WebVision 数据的一个子集
# (包含 0-9 类别的特征和标签名.)
# X: features
features_file = 'test-data/input/webvision_cls0-9.npy'
X = np.load(features_file)
# y: labels
cluster_list = 'test-data/input/webvision_cls0-9.txt' # imagenet train list
with open(cluster_list) as f:
metadata = [x.strip().split(' ') for x in f]
y = [int(item[1]) for item in metadata]
return X, y, metadata
def verify_webvision_expected_clusters(labels, n_subsets, metadata):
# 创建写入结果的保存路径
test_dir = tempfile.mkdtemp()
# 根据聚类结果的索引,转换为metadata 的标签
# 创建输出文件,如, 1.txt - clean, 2.txt - medium, 3.txt - dirty
clustered_by_levels = [list() for _ in xrange(n_subsets)]
for idx, _ in enumerate(metadata):
clustered_by_levels[labels[idx]].append(idx)
for idx, level_output in enumerate(clustered_by_levels):
with open("{}/{}.txt".format(test_dir, idx + 1), 'w') as f:
for i in level_output:
f.write("{}\n".format(str.join(' ', metadata[i])))
# Verify matches expectation
for i in range(1, n_subsets + 1):
with open('{}/{}.txt'.format(test_dir, i), 'r') as file1:
with open('test-data/output-expected/{}.txt'.format(i), 'r') as file2:
diff = set(file1).difference(file2)
if len(diff) != 0:
with open('{}/err.txt'.format(test_dir), 'w') as file_out:
for label_lines in diff:
file_out.write(label_lines)
raise RuntimeError("ERROR: Found {} differences "
"in expected output file {} "
"See {}/err.txt.".format(len(diff), i, test_dir))
# Clean up
shutil.rmtree(test_dir)
print "Test is successful."
if __name__ == "__main__":
test_curriculum_cluster()处理过程如:
Clustering 1 of 10 categories into 3 curriculum subsets (0.42 secs).
Clustering 2 of 10 categories into 3 curriculum subsets (0.76 secs).
Clustering 3 of 10 categories into 3 curriculum subsets (1.33 secs).
Clustering 4 of 10 categories into 3 curriculum subsets (0.74 secs).
Clustering 5 of 10 categories into 3 curriculum subsets (0.28 secs).
Clustering 6 of 10 categories into 3 curriculum subsets (0.51 secs).
Clustering 7 of 10 categories into 3 curriculum subsets (0.53 secs).
Clustering 8 of 10 categories into 3 curriculum subsets (1.76 secs).
Clustering 9 of 10 categories into 3 curriculum subsets (0.54 secs).
Clustering 10 of 10 categories into 3 curriculum subsets (1.18 secs).
Test is successful.