原文:Stable Diffusion Clearly Explained! - 2023.01.02
在 Stable Diffusion 之前,可以先了解下 Diffusion Model.
Diffusion Model 存在比较明显的速度问题. 因为 diffusing(sampling) 过程是在全尺寸的像素空间进行迭代进行的,当 steps T 和图像尺寸比较大时,速度非常的慢.
Stable Diffusion 原来的名字是,Latent Diffusion Model (LDM). 正如其名字,Diffusion 是在 latent space 进行的. 其速度就比 Diffusion Model 快了很多.
Stable Diffusion
Departure to Latent Space
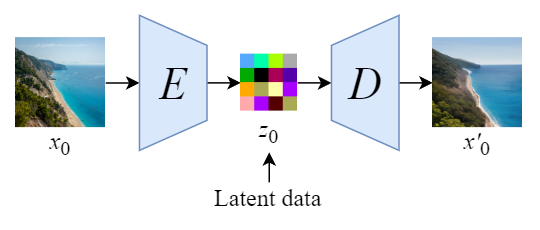
图:Autoencoder
首先,训练一个自编码器,将图像压缩为低维表示.
- 采用训练的编码器 $E$,可以将全尺寸图像编码为低维 latent 数据(压缩数据)
- 采用训练的解码器$D$,可以将 latent data 解码为图像
Latent Diffusion
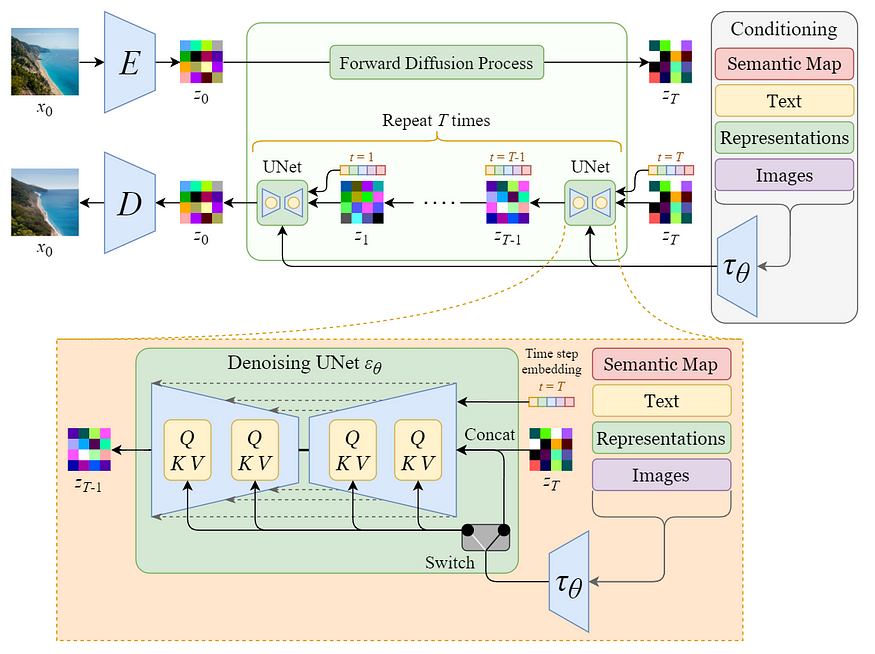
将图像编码为 latent data 后,forward 和 reverse diffusion 过程即在 latent space 进行.
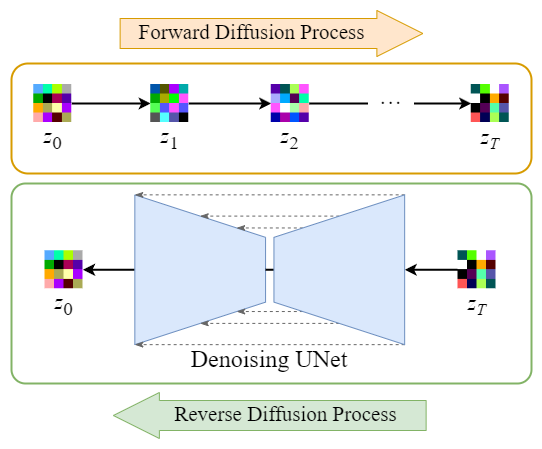
图:Overview of the Stable Diffusion model
[1] - Forward Diffusion Process -> 添加噪声到 latent data
[2] - Reverse Diffusion Process -> 移除 latent data 中的噪声
Conditioning
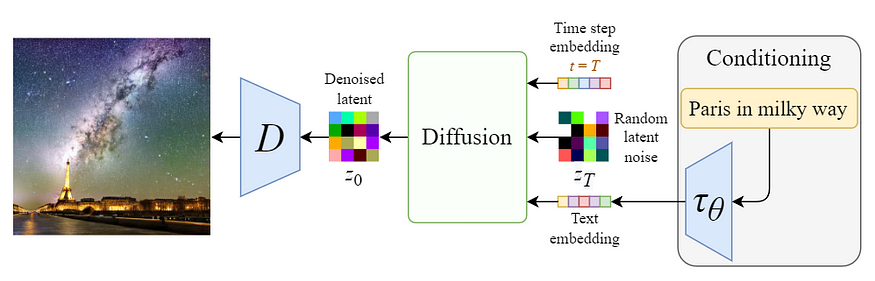
图:Overview of the conditioning mechanism
Stable Diffusion Model 的实力在于,其可以从 text prompts 生成图像. 其是通过修改内部的 diffusion model,使其可以接受条件输入,来实现的.

图:Conditioning mechanism details
内部的 diffusion model 被转换为条件图像生成器(conditional image generator),通过采用 cross-attention mechanism 增强 denoising U-Net.
上图中的 Switch 用于控制不同类型的条件输入:
- 对于 text 输入,首先采用语言模型 $\tau (\theta)$ (如,BERT, CLIP等) 将其转换为 embeddings(vectors) ,然后通过 multi-head Attention (Q, K, V) 层映射进 U-Net.
- 对于其他空间对齐的输入,如,分割图、图像、inpainting,等,可以采用 concatenation 进行条件控制.
Training
目标损失函数,如:
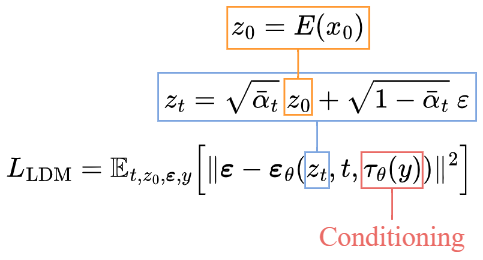
相比于 Diffusion Model 的损失函数,仅改动了:
- 输入是 latent data $z_t$,而不是图像 $x_t$
- 添加条件输入 $\tau _{\theta} (y)$ 到 U-Net
Sampling
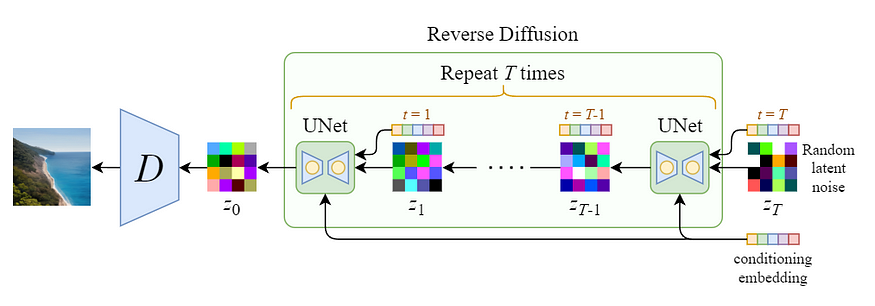
图:Stable Diffusion sampling process (denoising)
因为 latent data 比原图小了很多,因此其 denoising 过程快了很多.
Stable Diffusion vs Diffusion Model
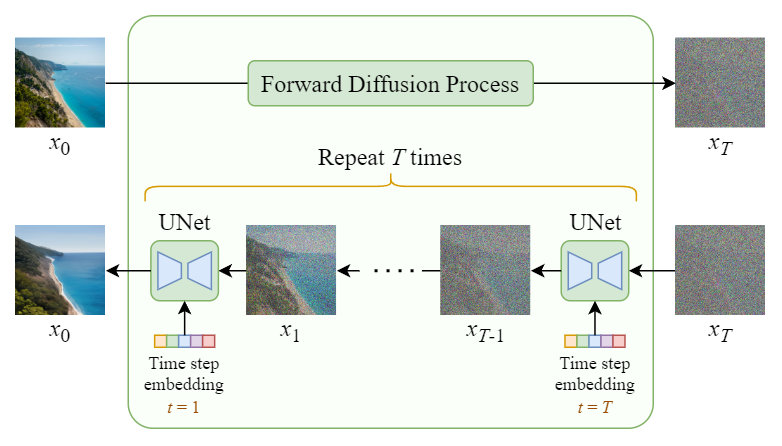
Pure Diffusion Model
Stable Diffusion (Latent Diffusion Model)
Summary
- Stable Diffusion (Latent Diffusion Model) 在 latent space 进行 diffusion 过程,因此比 diffusion model 具有更快的速度.
- Stable Diffusion (Latent Diffusion Model) 可以支持更多的条件输入,如文本、分割图等.
References
[1] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with Latent Diffusion Models,” arXiv.org, 13-Apr-2022. [Online]. Available: https://arxiv.org/abs/2112.10752.
[2] J. Alammar, “The Illustrated Stable Diffusion,” The Illustrated Stable Diffusion — Jay Alammar — Visualizing machine learning one concept at a time. [Online]. Available: https://jalammar.github.io/illustrated-stable-diffusion/.
[3] A. Gordić, “Stable diffusion: High-resolution image synthesis with latent diffusion models | ML coding series,” YouTube, 01-Sep-2022. [Online]. Available: https://www.youtube.com/watch?v=f6PtJKdey8E.