1. 任务队列与消息队列
任务队列与消息队列都是由队列实现的异步协议. 其最大不同在于,消息队列传递的是“消息”,任务队列传递的是“任务”
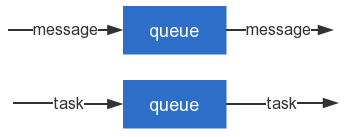
消息队列(Message Queue) 用来做异步通信,而任务队列(Task Queue) 更强调异步执行的任务.
示例如,
- 消息队列用来快速消费队列中的消息。比如日志处理场景,需要把不同服务器上的日志合并到一起,这时就需要用到消息队列。
- 任务队列是用来执行一个耗时任务。比如用户在购买的一件物品后,通常需要计算用户的积分以及等级,并把它们保存到数据库。这时就需要用到任务队列。
实际上发送消息也是一个任务,也就是说任务队列是在消息队列之上的管理工作,任务队列的很多典型应用是发送消息,如发送邮件,发送短信,发送消息推送等。可以简单认为任务队列就是消息队列在异步任务场景下的深度化定制开发。
- 消息队列更侧重于消息的吞吐、处理,具有有处理海量信息的能力。另外利用消息队列的生产者和消费者的概念,也可以实现任务队列的功能,但是还需要进行额外的开发。
- 任务队列则提供了执行任务所需的功能,比如任务的重试,结果的返回,任务状态记录等。虽然也有并发的处理能力,但一般不适用于高吞吐量快速消费的场景。
Refer: 消息队列(kafka/nsq等)与任务队列(celery/ytask等)到底有什么不同?
1.1. 任务队列和多线程
使用任务队列比使用多线程做异步任务的优势:
[1] - 有日志,入参出参都有记录
[2] - 能重试,简单配置即可自动重试
[3] - 有返回值,能够拿到异步任务的值
作为队列,也就具有一个先进先出模型,任务的生产者发送任务到队列中,消费者则接收任务并处理它,这样就实现了一个基本的应用解耦合和异步通信,任务或者消息是平台和语言无关的。
任务队列的主要应用场景在
[1] - 不用实时响应、性能占用较大,任务处理时间较长的任务,如占用网络性能的发送邮件,占用IO性能的视频处理。
[2] - 按时发布的定时任务,如定期对服务器的检查,对当天网站的监测分析。
一般的任务就是消息,消息中的有效载荷包含执行任务需要的全部数据。消息中间件或者称为消息代理,就是用来接收生产者发送过来的任务消息,存进队列再按序发送给任务
常见的消息队列有Rabbitmq、Zeromq、Redis等.
为什么使用Celery而不使用线程发送耗时任务:
- 因为并发量较大的时候,线程切换会有开销时间,也会降低并发的数量、共享数据维护麻烦
- Celery是通过消息队列进行异步任务处理,不用担心并发量高是负载过大,也可以处理复杂系统性能问题,相对灵活
2. Celery 分布式任务队列
Celery - Distributed Task Queue
Celery 是一个异步的分布式任务队列,主要用于实时处理和任务调度。其消息中间件(Broker)是推荐使用 RabbitMQ ,Backend 使用Redis . 此外还支持其他的消息队列或者是数据库。
注,Celery Broker 的选择:
| Name | Status | Monitoring | Remote Control |
|---|---|---|---|
| RabbitMQ | Stable | Yes | Yes |
| Redis | Stable | Yes | Yes |
| Amazon SQS | Stable | No | No |
| Zookeeper | Experimental | No | No |
Celery 是一个异步任务调度工具,用户使用 Celery 产生任务,借用中间件Broker来传递任务,任务执行单元Worker 从 Broker 消费任务。任务执行单元可以单机部署,也可以分布式部署,因此 Celery 是一个高可用的生产者-消费者模型的异步任务队列。
Celery 高可用体现于,假如发出一个任务执行命令给 Celery,只要 Celery 的任务执行单元Worker 在运行,那么它一定会执行;如果执行单元Worker 出现故障,如断电、断网等,只要任务执行单元Worker 恢复运行,那么它会继续执行已经发出的命令。实用场景如,假如有交易系统接到了大量交易请求,主机却挂了,但前端用户仍可以继续发交易请求,发送交易请求后,用户无需等待。待主机恢复后,已发出的交易请求可以继续执行,只不过用户收到交易确认的时间延长而已,但并不影响用户体验。
Celery 产生任务的方式有两种
[1] - 发布者发布任务
[2] - 任务调度按时发布定时任务
可以将任务交给 Celery 处理,也可以让 Celery 自动按 crontab 那样去自动调度任务,然后去做其他事情,可以随时查看任务执行的状态,也可以让 Celery 执行完成后自动把执行结果告知。
2.1. Celery 应用场景
[1] - 高并发的请求任务。某些时间极高的并发任务请求,如公司中常见的购买理财、学生缴费,在理财产品投放市场后、开学前的一段时间,交易量猛增,确认交易时间较长,此时可以把交易请求任务交给 Celery 去异步执行,执行完再将结果返回给用户。用户提交后不需要等待,任务完成后会通知到用户(购买成功或缴费成功),提高了网站的整体吞吐量和响应时间,几乎不需要增加硬件成本即可满足高并发。
[2] - 定时任务。在云计算,大数据,集群等技术越来越普及,生产环境的机器也越来越多,定时任务是避免不了的,如果每台机器上运行着自己的 crontab 任务,管理起来相当麻烦,例如当进行灾备切换时,某些 crontab 任务可能需要单独手工调起,给运维人员造成极大的麻烦,而使用 Celery 可以集中管理所有机器的定时任务,而且灾备无论何时切换,定时任务总能正确的执行。
[3] - 异步任务。一些耗时较长的操作,比如 I/O 操作,网络请求,可以交给 Celery 去异步执行,用户提交后可以做其他事情,当任务完成后将结果返回用户即可,可提高用户体验。
2.2. Celery 架构
Celery 架构如图:
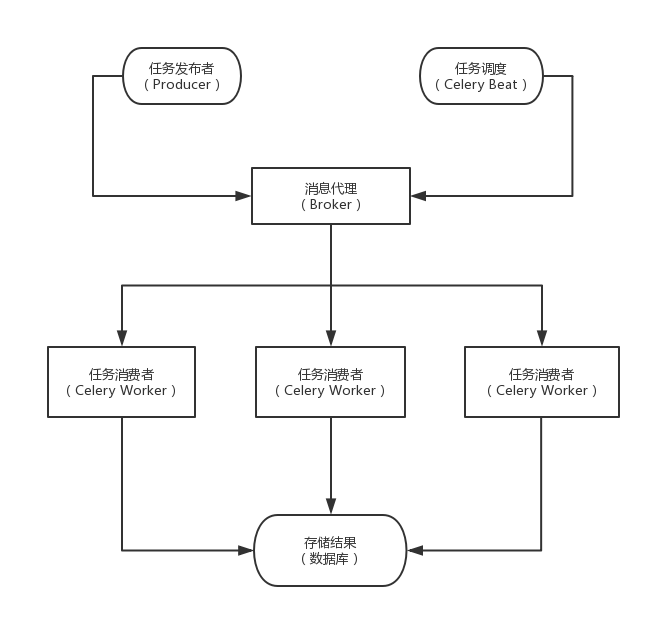
Celery 包含的组件:
[1] - 任务调度Celery Beat: 任务调度器,用来调度周期任务。Celery Beat进程会读取配置文件的内容,周期性的将配置中到期需要执行的任务发送给任务队列。
[2] - 任务生产者Producer: 任务生产者,调用 Celery 产生任务。
[3] - 中间人Broker: 消息中间件,任务消息存进队列,再按序发送给消费者。使用中间人(Broker)在客户端和 Worker 之前传递,这个过程从客户端向队列添加消息开始,之后中间人把消息派送给 Worker。
[4] - 任务执行单元Celery Worker: 执行任务的消费者,通常可以在多台服务器上运行多个消费者。Worker 持续地监控任务队列,当队列中有新的任务时,它便取出来执行。Worker 可以运行在不同的机器上,只要它指向同一个中间人即可;Worker还可以监控一个或多个任务队列。Celery 是分布式任务队列的重要原因就在于 worker 可以分布在多台主机中运行。修改配置文件后不需要重启 Worker,它会自动生效。
[5] - 任务结果存储Result Backend: 任务处理完成之后保存状态信息和结果,用来持久存储 Worker 执行任务的结果,一般是数据库,如AMQP,Redis,memcached,MongoDb,SQLAlchemy等。
Celery 工作流:
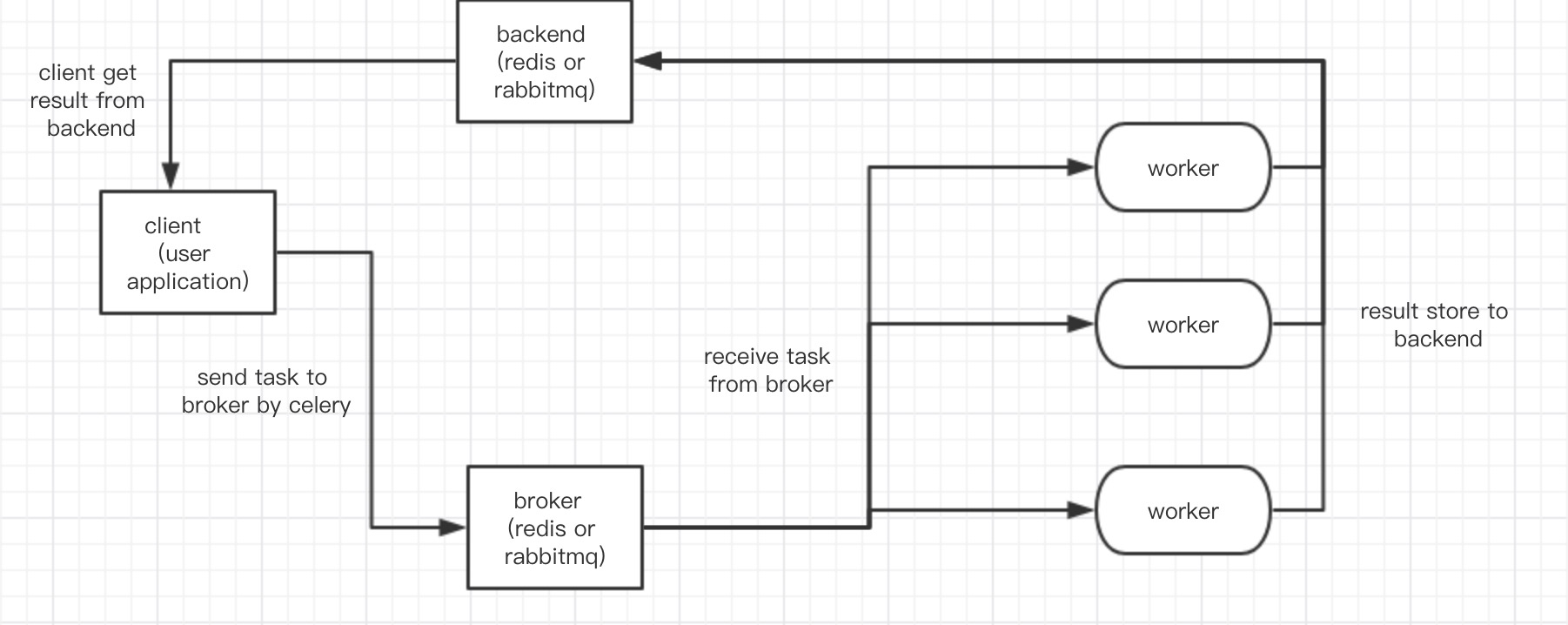
2.3. Celery 任务工作流
Celery Task的状态图:
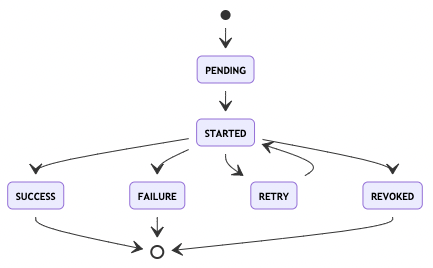
其中,除SUCCESS外,还有失败(FAILURE)、取消(REVOKED)两个结束状态。 而RETRY则是在设置了重试机制后,进入的临时等待状态。
此外,如果保存在Redis的结果信息被清理(默认仅保存1天),那么任务状态又会变成PENDING。 (这在设计上是个巨大的问题,使用时要做对应容错。)
Celery Task 工作流如图,
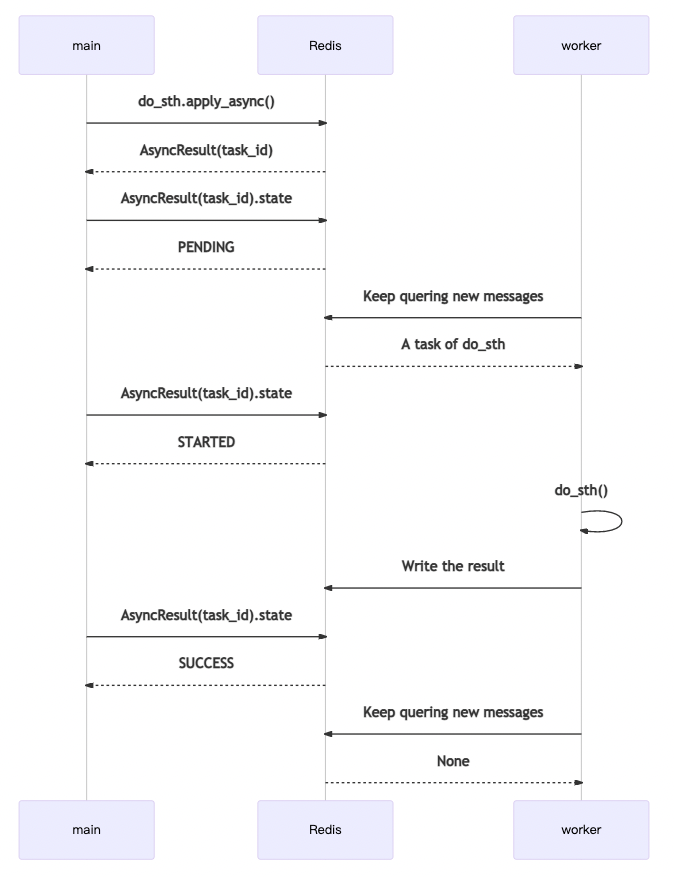
其中,main代表业务代码主进程。 worker就是指Celery的Worker。
main 发送消息后,会得到一个AsyncResult,其中包含task_id。 仅通过task_id,也可以自己构造一个AsyncResult,查询相关信息。 其中,代表运行过程的,主要是state。
worker会持续保持对Redis(或RabbitMQ等消息队列)的关注,查询新的消息。 如果获得新消息,将其消费后,开始运行do_sth。 运行完成会把返回值对应的结果,以及一些运行信息,回写到Redis(或其它Backend,如Django数据库等)上。 在系统的任何地方,通过对应的AsyncResult(task_id)就可以查询到结果。
2.4. Celery 基本概念
Celery 架构由三部分组成:
[1] - 消息中间件(message broker)
[2] - 任务执行单元(worker)
[3] - 任务执行结果存储(task result store)
Celery 架构图,如:
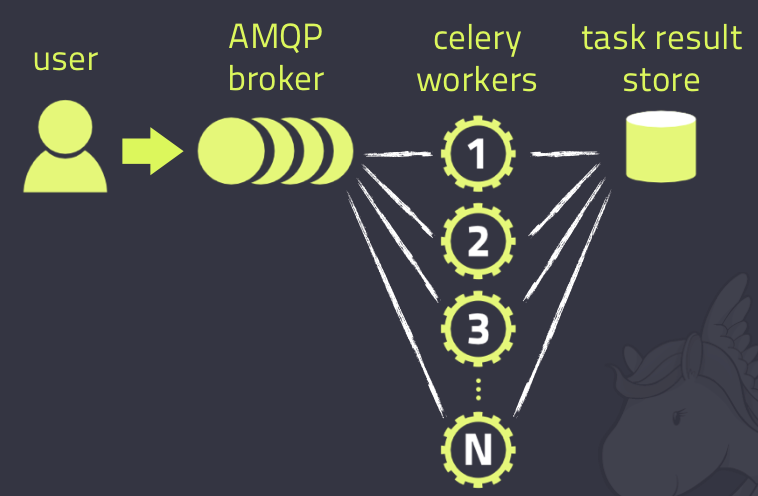
Celery 作为一个强大的分布式任务队列 的 异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行. 通常被用于实现异步任务(async task)和定时任务(crontab).
需要一个消息队列来分发任务,首先要有一个消息中间件,如rabbitmq(推荐)、redis等,架构组成如图:
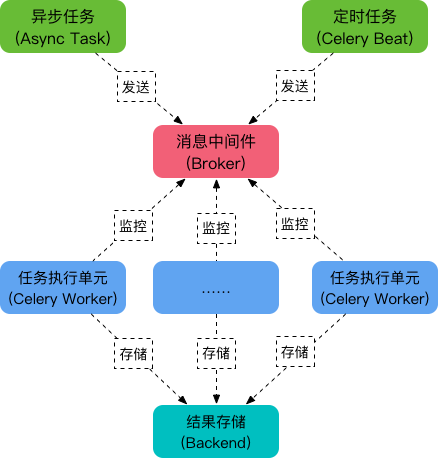
其除了三大部分,还可以划分为如下几个模块:
[1] - 任务模块 Task
包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列。
[2] - 消息中间件 Broker
Broker,即为任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis等。
[3] - 任务执行单元 Worker
Worker 是执行任务的处理单元,它实时监控消息队列,获取队列中调度的任务,并执行它。
[4] - 任务结果存储 Backend
Backend 用于存储任务的执行结果,以供查询。同消息中间件一样,存储也可使用 RabbitMQ, redis和 MongoDB等。
3. Celery Worker 参数
Celery 启动一个 Worker:
celery worker -A proj --loglevel=info
celery worker --app=proj -l info
celery worker -A proj -l info -Q hipri,lopri
celery worker -A proj --concurrency=4
celery worker -A proj --concurrency=1000 -P eventlet
celery worker --autoscale=10,0其中,
- -A 是指对应的应用程序, 其参数是项目中 Celery实例的位置,也即 celery_app = Celery()的位置。
- worker 是指这里要启动其中的worker
Celery Worker 启动过程的内部分析:
当启动一个Worker时,这个Worker会与Broker建立链接(tcp长链接),然后如果有数据传输,则会创建相应的channel, 这个连接可以有多个channel。然后,Worker就会去borker的队列里面取相应的task来进行消费了,这也是典型的消费者生产者模式。
其中,这个worker主要是有四部分组成的,task_pool, consumer, scheduler, mediator。task_pool主要是用来存放的是一些worker, 当启动了一个worker, 并且提供并发参数的时候,会将一些worker放在这里面。celery 默认的并发方式是prefork,也就是多进程的方式,这里只是celery对multiprocessing.Pool进行了轻量的改造,然后给了一个新的名字叫做prefork,这个pool与多进程的进程池的区别就是这个task_pool只是存放一些运行的worker. consumer 也就是消费者, 主要是从broker那里接受一些message,然后将message转化为celery.worker.request.Request的一个实例。并且在适当的时候,会把这个请求包装进Task中,Task就是用装饰器app_celery.task()装饰的函数所生成的类,所以可以在自定义的任务函数中使用这个请求参数,获取一些关键的信息。此时,已经了解了task_pool和consumer。
3.1. Worker具体参数
celery worker --help 如:
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
全局参数:
-A APP, --app APP
-b BROKER, --broker BROKER
--loader LOADER
--config CONFIG
--workdir WORKDIR Optional directory to change to after detaching.
--no-color, -C
--quiet, -q
Worker 参数:
-n HOSTNAME, --hostname HOSTNAME
Set custom hostname (e.g., 'w1@%h'). Expands: %h
(hostname), %n (name) and %d, (domain).
-D, --detach Start worker as a background process.
-S STATEDB, --statedb STATEDB
Path to the state database. The extension '.db' may be
appended to the filename. Default: None
-l LOGLEVEL, --loglevel LOGLEVEL
Logging level, choose between DEBUG, INFO, WARNING,
ERROR, CRITICAL, or FATAL.
-O OPTIMIZATION
--prefetch-multiplier PREFETCH_MULTIPLIER
Set custom prefetch multiplier value for this worker
instance.
Pool参数(多进程参数):
-c CONCURRENCY, --concurrency CONCURRENCY
Number of child processes processing the queue. The
default is the number of CPUs available on your
system.
-P POOL, --pool POOL Pool implementation: prefork (default), eventlet,
gevent or solo.
-E, --task-events, --events
Send task-related events that can be captured by
monitors like celery events, celerymon, and others.
--time-limit TIME_LIMIT
Enables a hard time limit (in seconds int/float) for
tasks.
--soft-time-limit SOFT_TIME_LIMIT
Enables a soft time limit (in seconds int/float) for
tasks.
--max-tasks-per-child MAX_TASKS_PER_CHILD, --maxtasksperchild MAX_TASKS_PER_CHILD
Maximum number of tasks a pool worker can execute
before it's terminated and replaced by a new worker.
--max-memory-per-child MAX_MEMORY_PER_CHILD, --maxmemperchild MAX_MEMORY_PER_CHILD
Maximum amount of resident memory, in KiB, that may be
consumed by a child process before it will be replaced
by a new one. If a single task causes a child process
to exceed this limit, the task will be completed and
the child process will be replaced afterwards.
Default: no limit.
Queue参数(队列参数):
--purge, --discard Purges all waiting tasks before the daemon is started.
**WARNING**: This is unrecoverable, and the tasks will
be deleted from the messaging server.
--queues QUEUES, -Q QUEUES
List of queues to enable for this worker, separated by
comma. By default all configured queues are enabled.
Example: -Q video,image
--exclude-queues EXCLUDE_QUEUES, -X EXCLUDE_QUEUES
List of queues to disable for this worker, separated
by comma. By default all configured queues are
enabled. Example: -X video,image.
--include INCLUDE, -I INCLUDE
Comma separated list of additional modules to import.
Example: -I foo.tasks,bar.tasks
Features:
--without-gossip Don't subscribe to other workers events.
--without-mingle Don't synchronize with other workers at start-up.
--without-heartbeat Don't send event heartbeats.
--heartbeat-interval HEARTBEAT_INTERVAL
Interval in seconds at which to send worker heartbeat
--autoscale AUTOSCALE
Enable autoscaling by providing max_concurrency,
min_concurrency. Example:: --autoscale=10,3 (always
keep 3 processes, but grow to 10 if necessary)
Daemonization Options:
-f LOGFILE, --logfile LOGFILE
Path to log file. If no logfile is specified, stderr
is used.
--pidfile PIDFILE Optional file used to store the process pid. The
program won't start if this file already exists and
the pid is still alive.
--uid UID User id, or user name of the user to run as after
detaching.
--gid GID Group id, or group name of the main group to change to
after detaching.
--umask UMASK Effective umask(1) (in octal) of the process after
detaching. Inherits the umask(1) of the parent process
by default.
--executable EXECUTABLE
Executable to use for the detached process.
Embedded Beat Options:
-B, --beat Also run the celery beat periodic task scheduler.
Please note that there must only be one instance of
this service. .. note:: -B is meant to be used for
development purposes. For production environment, you
need to start celery beat separately.
-s SCHEDULE_FILENAME, --schedule-filename SCHEDULE_FILENAME, --schedule SCHEDULE_FILENAME
Path to the schedule database if running with the -B
option. Defaults to celerybeat-schedule. The extension
".db" may be appended to the filename. Apply
optimization profile. Supported: default, fair
--scheduler SCHEDULER
Scheduler class to use. Default is
celery.beat.PersistentScheduler3.2. Worker示例配置
Celery 默认配置 Configuration and defaults
配置文件,如:
'''
celery_config.py
'''
broker_url = "{}://{}:{}@{}:{}/{}".format(
broker_protocol,
broker_username,
broker_password,
broker_host,
broker_port,
broker_vhost)
worker_send_task_event = False
task_ignore_result = True
#设置单个任务的运行时间限制,否则会被杀死
# task will be killed after 60 seconds
task_time_limit = 60
# task will raise exception SoftTimeLimitExceeded after 50 seconds
task_soft_time_limit = 50
# task messages will be acknowledged after the task has been executed, not just before (the default behavior).
task_acks_late = True
# One worker taks 10 tasks from queue at a time and will increase the performance
worker_prefetch_multiplier = 10 Celery APP如:
'''
celery_app.py
'''
from celery import Celery
import celery_config
app = Celery(__name__)
app.config_from_object(celery_config)
@app.task()
def random_task():
pass运行命令行:
#CPU调度型任务,大量并行计算
celery -A <task> worker -l info -n <name of task> -c 4 -Ofair -Q <queue name> — without-gossip — without-mingle — without-heartbeat
# I/O型任务
celery -A <task> worker -l info -n <name of task> -Ofair -Q <queue name> -P eventlet -c 1000 — without-gossip — without-mingle — without-heartbeat4. Celery 示例问题
4.1. 如何解决Celery队列阻塞问题
队列阻塞的原因:
[1] - 队列中有耗时任务,且任务量大于celery并发数(Celery没有足够的worker去执行耗时任务)
[2] - 队列中有耗时任务,且Celery启动了
预取机制;任务会有指定的worker去执行,就算其worker是空闲状态,也不会执行其它任务
解决办法:
- 指定进程数
celery -A project worker --concurrency=4- 改变进程池方式为协程方式
pip install eventlet
celery -A project worker -P eventlet -c 1000- 增加并发数
celery -A project worker -n 进程名字 --concurrencu=并发数 -l info- 取消预取机制
#任务发送完成时是否需要确认,对性能会稍有影响
celery_app.conf.CELERY_LATE = True
#Celery worker每次去队列取任务的数量,默认值为4
celery_app.conf.CELERY_PREFETCH_MULTIPLIER = 1celery -A project worker -n 进程名字 -Ofair -l info- 错误重试机制
#重连时间间隔
@celery_app.task(bind=True, retry_backoff=3)
try:
...
except Exception as e:
#有异常自动重连三次
raise self.retry(exc=e, max_retries=3)文档
[1] - 常见问题 Frequently Asked Questions