基于深度神经网络的噪声标签学习-云社区-华为云 (huaweicloud.com)
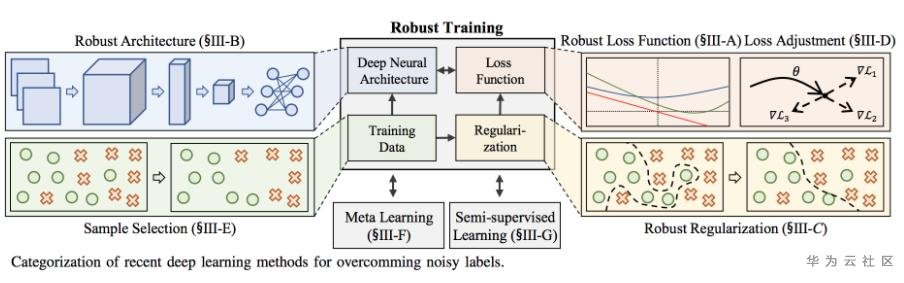
神经网络的成功建立在大量的干净数据和很深的网络模型基础上。但是在现实场景中数据和模型往往不会特别理想,比如数据层面有误标记的情况,像小狗被标注成狼,而且实际的业务场景讲究时效性,神经网络的层数不能特别深。我们尝试不断迭代数据和模型缺陷情况下神经网络的有效训练方法,通过noisy label learning技术,解决网络训练过程中noisy data的问题,该技术已经在团队实际业务场景中落地,通过从损失函数、网络结构、模型正则化、损失函数调整、样本选择、标签纠正等多个模块的优化,不局限于全监督、半监督和自监督学习方法,提升整个模型的鲁棒性
1. 损失函数
主要是从损失函数去修改,核心思路是当数据整体是干净的时候,传统的交叉熵损失函数学习到少量的负样本,可以提升模型的鲁棒性;当数据噪声比较大时,CE会被噪声数据带跑偏,我们要修改损失函数使其在训练中每个样本的权重都是一样重要的,因此不难想到采用GCE Loss,控制超参数,结合了CE Loss和MAE Loss
- A. Ghosh, H. Kumar, and P. Sastry,“Robust loss functions under label noise for deep neural networks,” in Proc. AAAI, 2017
- Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels, NeurlPS 2018
另外,还有从KL散度想法借鉴过来的,作者认为在计算熵的时候,原始q, p代表的真实数据分布和预测值在较为干净的数据上没有问题,但是在噪声比较大的数据上,可能q并不能代表真实数据分布,相反的是不是p可以表示真实数据分布,因此提出基于对称的交叉熵损失函数(Symmetric cross entropy )
- Y. Wang, X. Ma, Z. Chen, Y. Luo, J. Yi, and J. Bailey, “Symmetric cross entropy for robust learning with noisy labels,” in Proc. ICCV, 2019, pp. 322–330
2. 模型结构
主要通过借鉴巧妙的网络结构,在模型训练过程中,通过模型对数据进行挑选,选择一批较为干净的数据,逐步提升模型的鲁棒性。首先要介绍的就是coteaching framework,首先是基于两个模型相互挑选数据输入给对方计算loss,传递给对方网络的数据是每个min-batch里面loss最低的一些数据,随着epoch增加,数据量有所变化,另外每一轮epoch结束,会shuffle数据,保证数据不会被永久遗忘
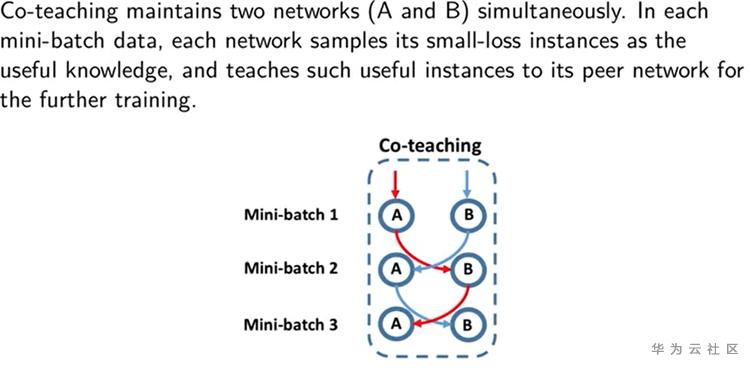
- How does Disagreement Help Generalization against Label Corruption? ICML 2019
- Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels, NeurlPS 2018
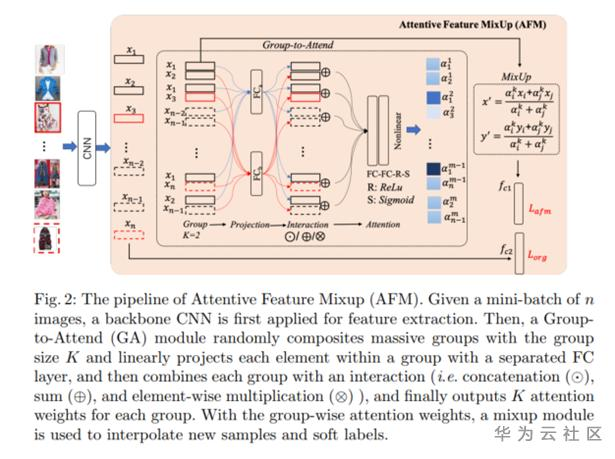
还有一种思路,是基于attention注意力机制给干净样本和噪声数据进行打分,文章叫做Attention Feature Mixup,在计算最终loss的时候有两部分,一部分是同一个类的每张图和标签计算的交叉熵损失;另外一个损失是数据mixup得到的新的数据x'和标签y'计算的loss
3. 正则化
主要是通过一些添加正则ticks,防止模型过拟合到噪声数据上,常用的正则方法包含:label smooth、l1、l2、MixUp等
4. 样本选择
主要是从如何挑选出更好的数据为出发点,一种方法,叫做Area Under the Margin metric (AUM),是我们去年参加CVPR WebVision 2020(图像识别领域最高级别的比赛,接替ImageNet)取得冠军的方案。该方案是一种在训练过程中一边训练一边筛选数据的方式,具体思想是在一个min-batch利用模型计算每张图片的logits值和其它类中最大的logits求差值当做area,这样多轮epoch求平均,得到每张图的aum值。试验发现如果这个数据是较为干净的数据area的值会比较大,如果是存在mis-label的数据area值比较小,甚至是负值,作者就是通过这个思想将一个类的干净数据和噪声数据分离开的。当然论文在最后也指出,干净数据和噪声数据占比99%的阈值是最优的。
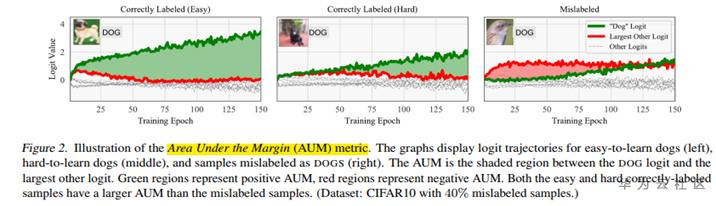
- Pleiss, Geoff, et al. "Identifying mislabeled data using the area under the margin ranking.“, NeurlPS 2020.
另外一篇,数据划分是通过密度聚类的思路,将一个类的数据分成easy dataset、smi-hard dataset和hard dataset,一般噪声数据是较为困难训练的数据,对于每张图分配一个权重,文中建议1.0、0.5和0.5;模型的训练借鉴了课程学习的思路
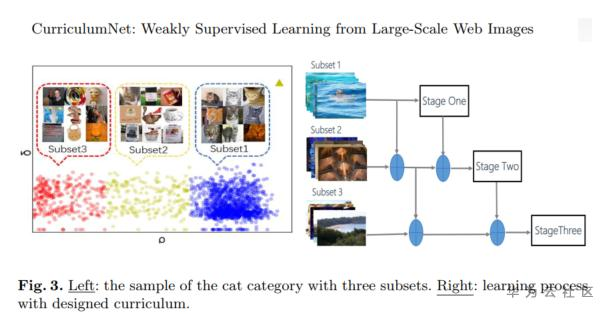
- Guo, Sheng, et al. "Curriculumnet: Weakly supervised learning from large-scale web images." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
5. 标签纠正
标签纠正(label correction)方法思路很简单就是相当于是一个重新打一个伪标签的概念,但是完全放弃原始的标签也过于暴力,ICCV2019的这篇文章在“label correction phase”通过一个pre-trained模型得到随机选择每个类中的几张图采用聚类的方法得到Prototype样本的每个类的聚类中心,对输入图片得到的特征向量和各类聚类中心计算距离,得到图片的伪标签,最后的loss是原始标签计算的交叉熵损失和伪标签计算的伪标签的求和
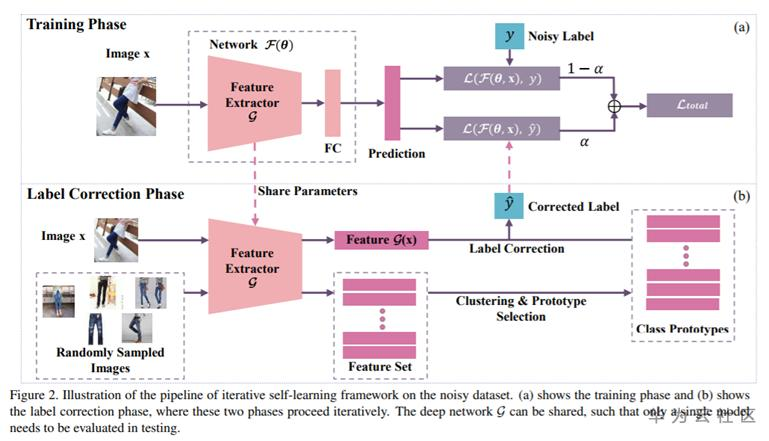
- Han, Jiangfan, Ping Luo, and Xiaogang Wang. "Deep self-learning from noisy labels.“, ICCV 2019