基于多个 GPUs 的数据并行化处理,其基本思想是,每个 GPU 复制一个模型副本,分别对 batch 数据进行前向和后向计算. 后向计算的梯度发送到服务器,由服务器运行 reduce 操作,计算平均梯度. 然后,将平均梯度传输回 GPU,GPU 使用 SGD 更新模型参数. 采用数据并行和有效的网络通信库(如NCCL),可以实现训练时间的几乎线性减少.
Pytorch 关于数据并行有两种实现:nn.parallel.data_parallel 和 DistributedDataParallel.
1. 数据加载并行化
深度学习框架,如Pytorch 和 Tensorflow,网络训练从磁盘读取输入数据开始,一般包括四个步骤:
[1] - 从磁盘加载数据到 host;
[2] - 将数据从可分页的(pageable)数据传输到 host 的固定内存(pinned memory);
[3] - 将数据从固定内存传输到 GPU;
[4] - 在 GPU 上进行前向和后向计算.
这些步骤中的每一个都必须尽可能并行化,并且每当不存在数据依赖性时,下一个 batch 都应与当前 batch 进行管道化(pipelined).
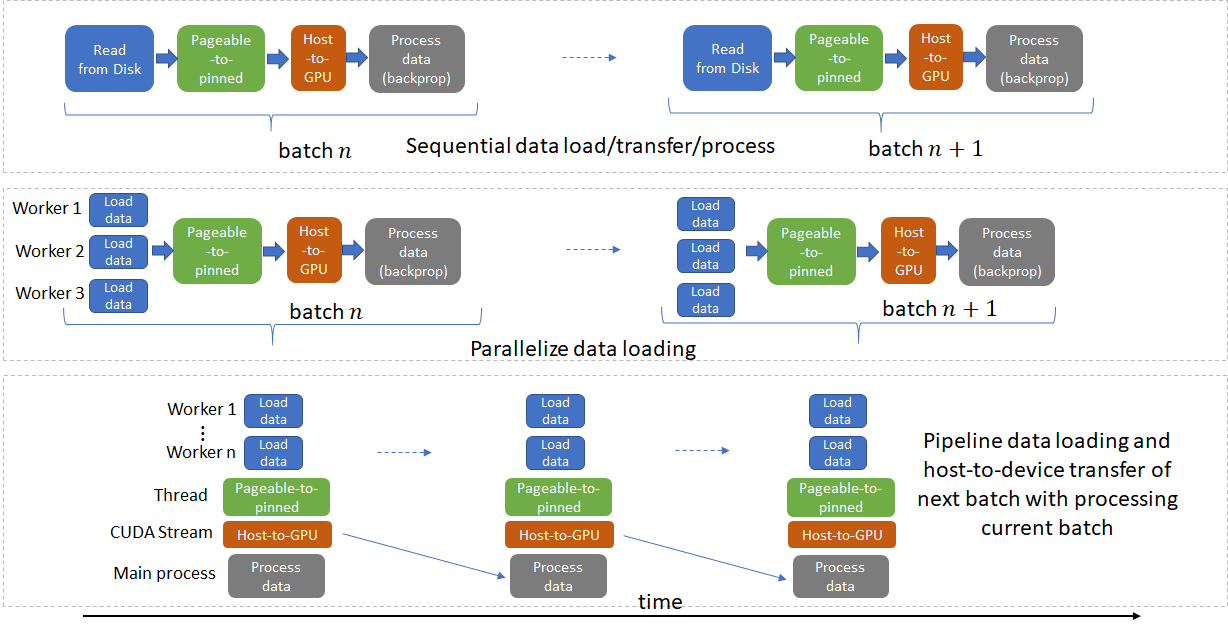
PyTorch 中的 Dataloader 提供了多进程(multi-process)从磁盘加载数据(设置num_works>0)以及多线程(multi-threaded) 将数据从可分页的(pageable)数据传输到 host 的固定内存(设置 pin_memory = True)的能力.

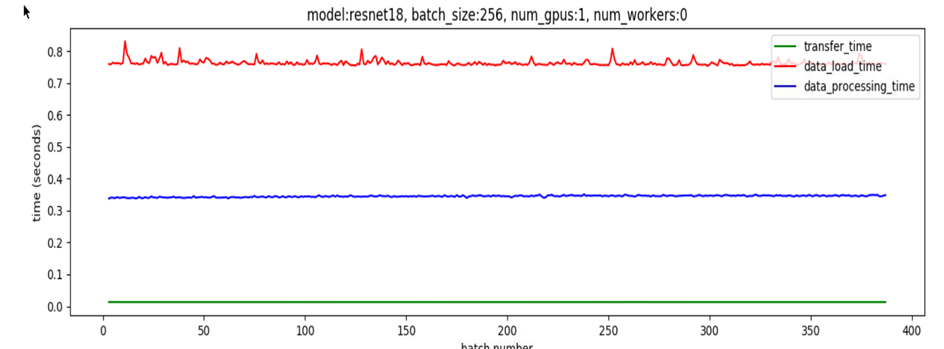
对于大批量的数据,若仅有一个线程用于加载数据,则数据加载时间占主导地位,这意味着无论如何加快数据处理速度,性能都会受到数据加载时间的限制. 如图:
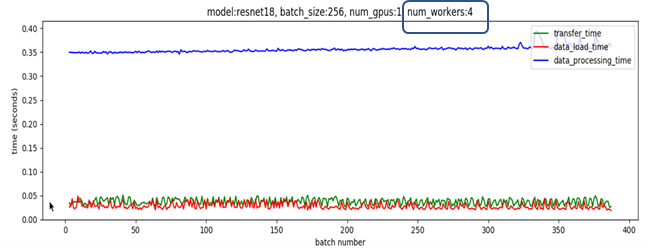
如,Pytorch 中设置num_workers = 4以及pin_memory = True. 即可使用多进程(multiple processes)从磁盘读取不重叠的数据,并启动生产者-消费者线程(producer-consumer thread) 以将这些进程读取的数据从可分页的内存转移到固定内存.
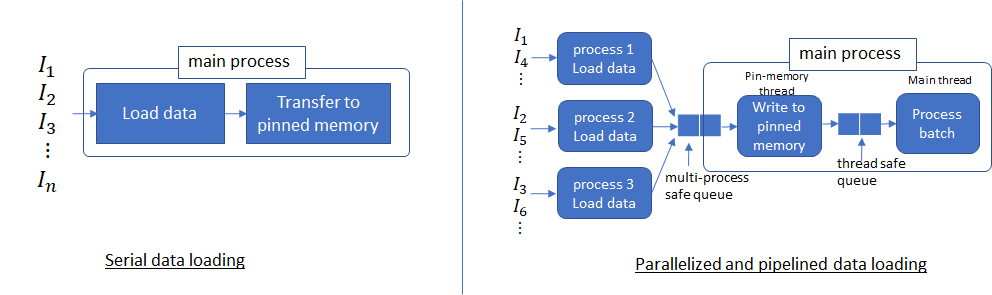
多进程可以更快的加载数据,且,当数据处理的时间足够长时,管道化数据加载几乎能够忽略数据加载延迟. 其原因是,处理当前 batch 数据的同时,下一 batch 的数据已经从磁盘读取并传输到固定内存里. 如果当前 batch 的处理时间足够长,下一 batch 的数据是立即可用的. 基于这种思想,有助于 num_workers 参数的选择,其应是,从磁盘读取 batch 数据的速度比 GPUs 处理当前 batch 数据的速度更快(但,也不能太高,因为多个进程也会浪费系统资源).
如图,
2. DataParallel
nn.parallel.data_parallel
2.1. 工作过程
如图:
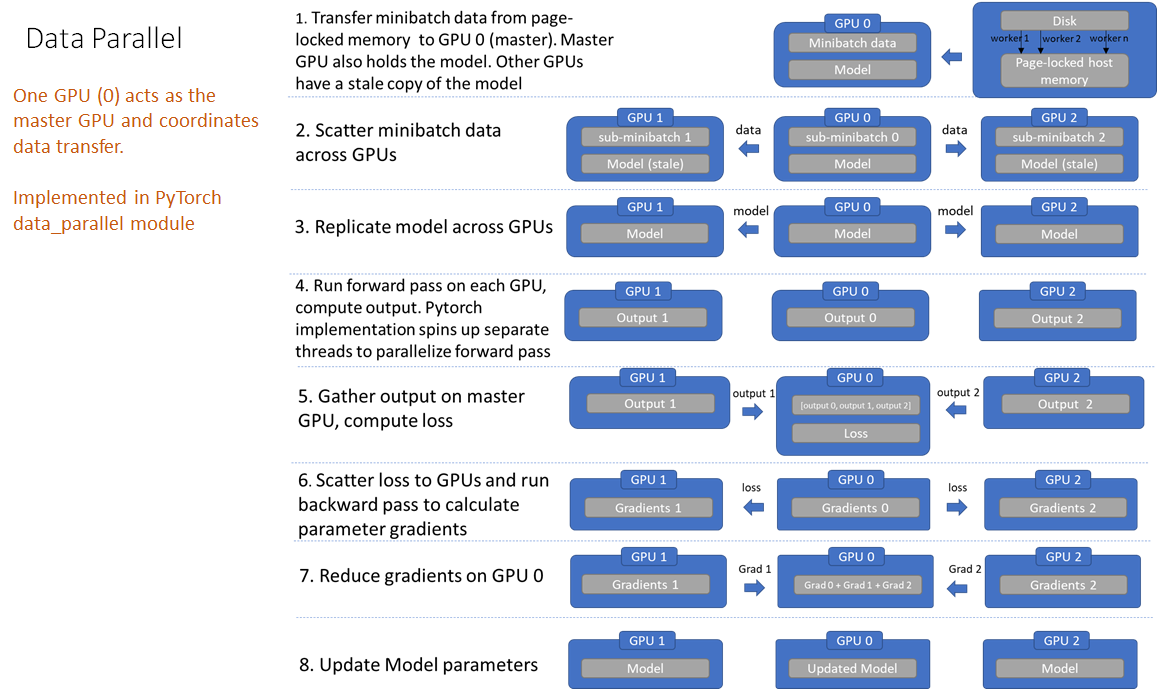
DataParallel 的工作过程如:
[1] - 将整个 mini-batch 数据加载到主线程(main thread);
[2] - 在各 GPU 上分发(scatter) sub mini-batchs 的数据;
[3] - 在各 GPU 上复制模型;
[4] - 每个 GPU 分别在各自的线程对其 sub mini-batch 的数据进行前向计算;
[5] - 在主 GPU 上收集(gather) 网络输出,并通过将网络输出与 batch 内每个元素的真实标签比较,计算损失函数;
[6] - 分发损失函数到各 GPU,每个 GPU 进行后向传播,以计算梯度;
[7] - 在主 GPU 上 reduce 梯度;
[8] - 更新主 GPU 上的模型参数.
以上即完成了一次迭代. 由于只在主 GPU 上更新了模型参数,因此,其他GPU上的模型现在并未同步,且必须在下一次迭代开始时,将模型参数广播到其他 GPU.
nn.parallel.data_parallel.py 中 forward 函数的实现,对应如:
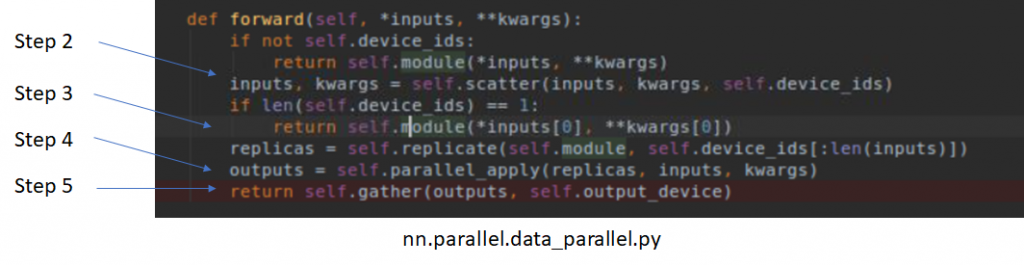
不过,backwords 的实现是 C 的,

2.2. 存在问题
[1] - 冗余数据副本
- 数据从主机(host) 复制到主GPU,然后将sub mini-batches 分发到其他GPU上
[2] - 在前向计算前跨GPUs 进行模型复制
- 由于模型参数是在主GPU上更新的,因此模型必须在每次前向计算开始时重新同步
[3] - 每个 batch 的线程创建/销毁开销
- 并行转发是在多个线程中实现的(这可能只是PyTorch问题)
[4] - 梯度减少管道机会未利用(Gradient reduction pipelining opportunity left unexploited)
- Pytorch数据并行实现中,梯度下降发生在后向传播的末尾处.
[5] - 在主GPU上不必要地收集模型输出output
[6] - GPU利用率不均
- 在主GPU上进行损失函数计算计算
- 在主GPU 上进行梯度下降、参数更新
2.3. DP 示例代码
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# Parameters and DataLoaders
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(
dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
#
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
#
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model) #并行
model.to(device)
#训练
for data in rand_loader:
input = data.to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())3. DistributedDataParallel
3.1. 工作过程
如图:
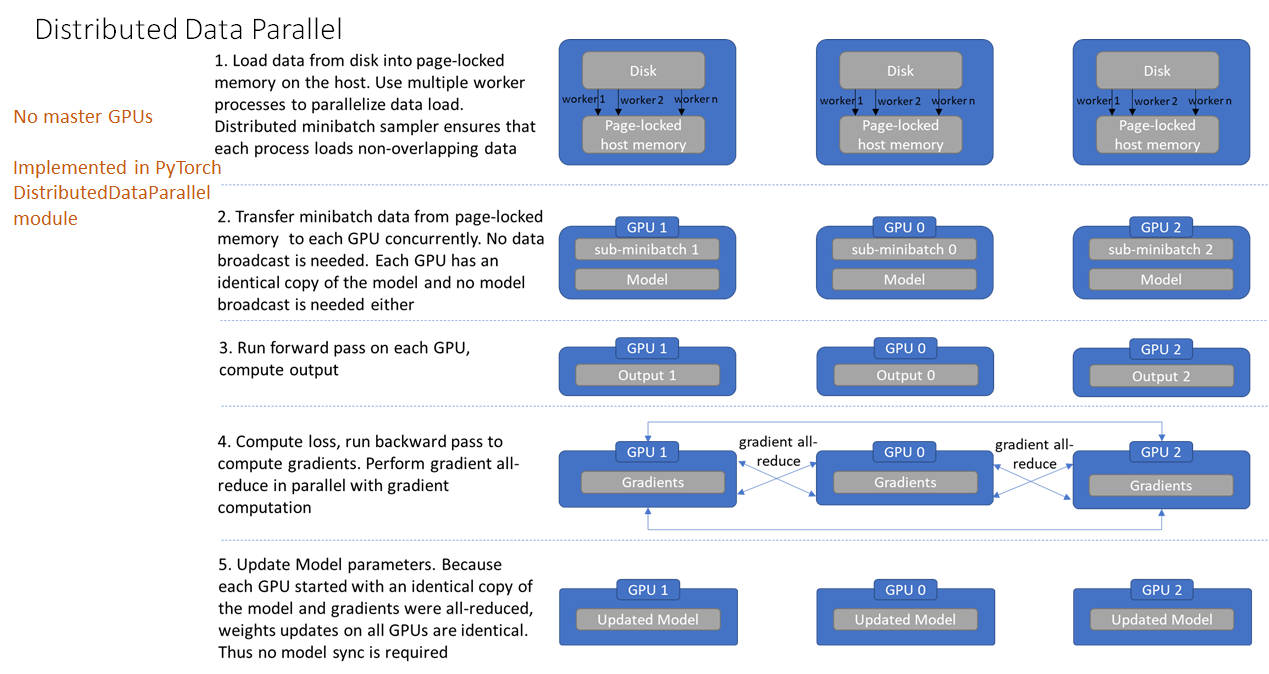
DistributedDataParallel 消除了 DataParallel 中上述不足. 其不再需要主 GPU,每个 GPU 分别进行各自任务. 每个 GPU 上的训练是其独立进程,而在 DataParallel 中是采用多线程(multi-thread) 的.
DistributedDataParallel 的工作过程如,
[1] - 从磁盘加载数据到 host 的page-locked内存. 采用多个 worker 进程并行地数据加载;其中,distributed data sampler 确保了加载的数据在跨进程间是不重叠的.
[2] - 将 mini-batch 数据由 page-locked 内存转移到 GPU. 不需要任何数据广播. 因为每个 GPU 分别有模型副本,因此也不需要模型广播.
[3] - 分别在各 GPU 独立进行前向计算和损失函数计算. 因此,也不需要收集各 GPUs 的输出.
[4] - 后向梯度计算,梯度是跨GPUs all-reduced的. 确保在后向传播结束时,每个 GPU 最终得到相同的平均梯度的副本.
[5] - 更新模型参数. 由于每个 GPU 是由相同的模型副本开始的,且梯度是 all-reduced 的,因此所有 GPUs 上的权重更新是相同的,无需再进行模型同步.
以上即完成了一次迭代. 这种设计确保了模型参数的更新是相同的,因此消除了每次开始时的模型同步.
其中,关于梯度计算的梯度 all-reduce,如图:
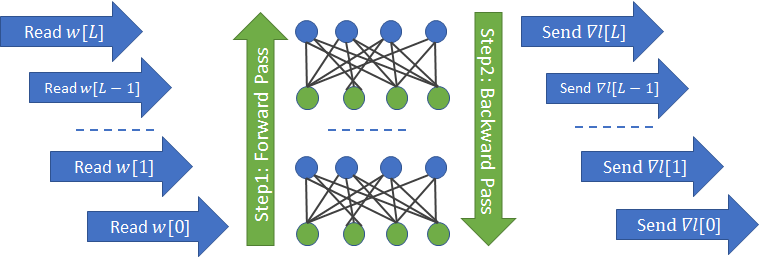
一个网络层的梯度参数的计算,不再依赖于上一网络层的梯度.
3.2. 多机多卡
DistributedDataParallel 一般用于多机训练(multi-host),每个 host 包含多 GPUs,各 host 之间通过网络进行通信. 默认是一个GPU上运行一个进程的操作.
可采用的配置如图:
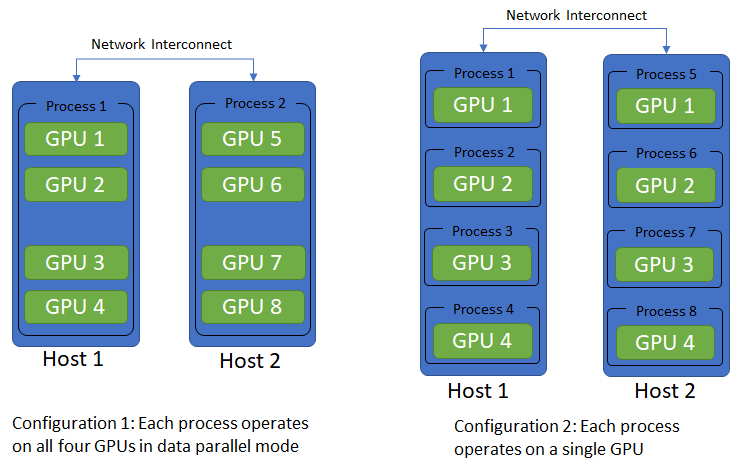
Pytoch 采用多机多卡的 DistributedDataParallel 涉及两个重要方面:
[1] - init_process_group - 确保共享文件系统、网络通信同步等.
torch.distributed.init_process_group(
backend,
init_method=None,
timeout=datetime.timedelta(0, 1800),
world_size=-1,
rank=-1,
store=None,
group_name='')其中,涉及的一些概念:
world_size: 全局进程数
rank: 进程序号,用于进程间的通讯,表示进程优先级. rank=0 的 host 为 master 节点.
local_rank: 进程内 GPU 编号,非显式参数,由torch.distributed.launch内部指定. 如,rank=3, local_rank=0 表示第3个进程内的第一块GPU.
[2] - DistributedSampler - 确保每个进程加载不重叠的数据
torch.utils.data.distributed.DistributedSampler(
dataset,
num_replicas=None,
rank=None,
shuffle=True,
seed=0,
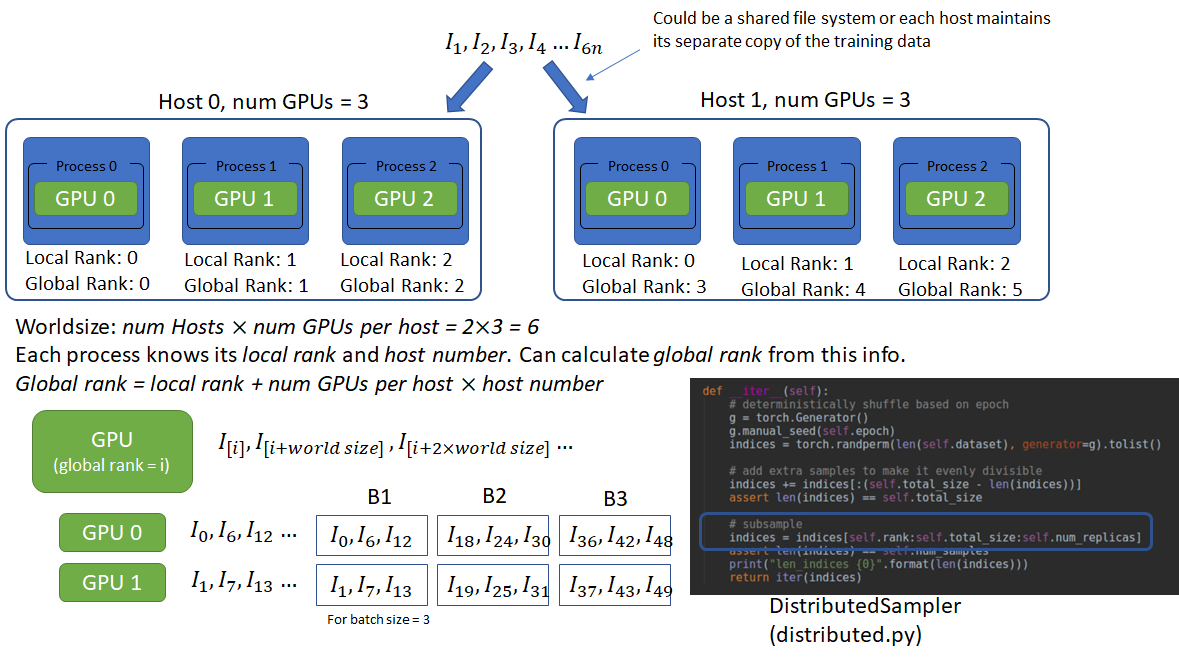
drop_last=False)示例,假设多机设置为一个进程控制一个 GPU,有 2 个 host,且每个 host 有 3 GPUs. 各进程通过共享文件系统或数据副本进行数据访问. 为了数据的不重叠读取,每个进程必须要知道在进程组(process group) 中的进程数和在组中的rank. 这样,每个进程根据其自己的 rank 作为偏移,进程数作为步长,读取不重叠数据段(chunks). 其是通过 world_size 和 rank 来提供的. 如:
#Host 1:
python imagenet_distributed_data_parallel.py <location of dataset> --batch-size 256 --workers 16 --arch resnet50 \
--multiprocessing-distributed --world-size 2 --rank 0 --dist-url tcp://192.145.3.1:12345
#Host 2:
python imagenet_distributed_data_parallel.py <location of dataset> --batch-size 256 --workers 16 --arch resnet50 \
--multiprocessing-distributed --world-size 2 --rank 1 --dist-url tcp://192.145.3.1:12345这里,world_size 是分布式系统中 hosts 数(2 个 hosts),rank 是每个 host 的rank. 因此,进程总数的计算为: world_size x 每个 host 的GPUs数=2x3=6.
然后,每个进程的global rank(进程组内唯一) 计算为:local rank(GPU id) + 每个host的GPUs数 x host rank.
如图:
3.3. DDP 示例代码
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()请注意,到目前为止,我们仅解决了从磁盘加载数据以及从可分页到固定内存的数据传输问题。从固定内存到GPU的数据传输(tensor.cuda())也可以使用CUDA流进行流水线处理。
现在将使用GPU网络检查数据并行处理。基本思想是,网络中的每个GPU使用模型的本地副本对一批数据进行正向和反向传播。反向传播期间计算出的梯度将发送到服务器,该服务器运行reduce归约操作以计算平均梯度。然后将平均梯度结果发送回GPU,GPU使用SGD更新模型参数。使用数据并行性和有效的网络通信软件库(例如NCCL),可以实现使训练时间几乎线性减少。
数据并行的操作要求我们将数据划分成多份,然后发送给多个 GPU 进行并行的计算。
注意:多卡训练要考虑通信开销的,是个trade off的过程,不见得四块卡一定比两块卡快多少,可能是训练到四块卡的时候通信开销已经占了大头
下面是一个简单的示例。要实现数据并行,第一个方法是采用 nn.parallel 中的几个函数,分别实现的功能如下所示:
- 复制(Replicate):将模型拷贝到多个 GPU 上;
- 分发(Scatter):将输入数据根据其第一个维度(通常就是 batch 大小)划分多份,并传送到多个 GPU 上;
- 收集(Gather):从多个 GPU 上传送回来的数据,再次连接回一起;
- 并行的应用(parallel_apply):将第三步得到的分布式的输入数据应用到第一步中拷贝的多个模型上。
参考
[1] - Pytorch - 单机多卡数据并行DataParallel - AIUAI
[2] - Distributed data parallel training using Pytorch on AWS - 2019.04.04