原文:淘宝首页那些“辣眼睛”的图去哪了?- 2019.12.13
出处:天池大数据科研平台 - 微信公众号
作者:忘返
导读:在淘宝这个平台上,消费者每天都在浏览着琳琅满目的图片,图片是消费者与商品交互的第一媒介. 图片的质量会极大影响消费者的消费体验和转化效果,高质量的图片会让消费者怦然心动,流连忘返,而低质量的“辣眼睛”图片会让消费者望而却步. 在淘宝首页猜你喜欢(以下简称首猜)场景下,由于图片数量太多,让人工来审核所有图片是不现实的. 作为阿里技术人,我们的使命就是使用技术手段过滤掉低质量的图片,将高质量的图片和素材呈现给消费者.
一. 摘要
恶心图片,顾名思义,就是让人感到恶心,不适的图片. 其大致可以被分为跟动物有关的,跟人有关的,以及物体这三种类型.
要从数量巨大的商品池中精确地将恶心图片过滤出来,面临着以下几个技术难点:
[1] - 初始样本很少且难收集,面临模型冷启动的问题;
[2] - 线上真实数据场景下,正负样本比例差距过大,面临严重的类别不平衡问题;
[3] - 恶心样本多种多样,如昆虫,爬行动物,人的各个身体部位等等,样本的特征分布非常分散.
针对第一个问题,我们通过本团队的小样本平台从淘宝内容池中召回恶心图片扩充样本量,并通过半监督算法利用淘宝的无标签数据进行训练.
针对第二个问题,我们在训练中通过 online hard example mining +级联的方法,并且通过 active learning和噪声样本识别算法加快模型迭代.
针对第三个问题,我们在模型中引入了attention机制,让模型focus在恶心的局部区域.
本文的二、三、四节分别论述了这三个解决方案.
模型于19年10月初在首猜上线,在集团的各个业务场景下累计召回了几万张恶心图片. 最新版的模型的精确率为95%,召回率为94%.
二. 冷启动方案
由于初始样本量比较少,面临冷启动的问题. 我们从首猜负反馈数据里拿到了几百张恶心图片,并通过本团队的小样本召回平台,用图像检索的方法从淘宝内容池中召回了几百张恶心图片,组成了最开始的训练样本.
为了防止过拟合,我们采用了轻量级的网络 mobilenet v2.
另外,我们通过半监督算法利用淘宝的无标签数据进行训练,提高模型的泛化能力. 具体思想为:一个网络的输出可以被认为是 $Y=\mathbf{f}_{\mathbf{w}}(X)$,其中 W 是网络参数,X 是输入图片. 一个好的模型应该足够鲁棒,无论是 W 的扰动(本文称为参数扰动)还是X的扰动(本文称为 输入扰动),输出都应该保持不变. 训练流程如下所示:
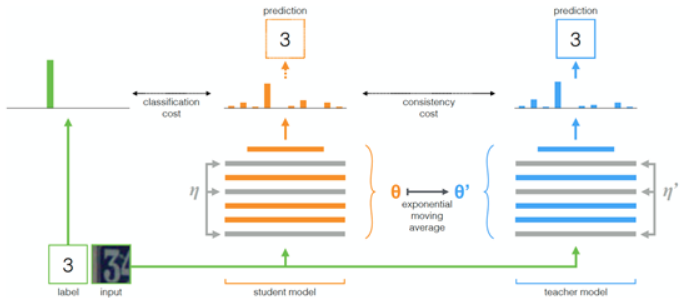
对于有标签数据,对 student 网络的输出构造交叉熵损失函数,对于所有数据(无标签+有标签),对student 网络和 teacher网络(两个网络结构一致)的输出构造 MSE 损失函数. 每次迭代的时候使用梯度下降法更新student网络参数并使得teacher网络的参数成为student网络参数的滑动指数平均. (具体可参考论文 Mean teachers are better rolemodels: Weight-averaged consistency targets improve semi-supervised deeplearning results - 2017)如下式所示:
$$ \theta^{\prime}_t = \alpha \theta^{\prime}_{t-1} + (1-\alpha) \theta_t $$
Github - CuriousAI/mean-teacher
在参数扰动上,我们使用的是上述公式中的滑动指数平均. 在输入扰动上,我们对student网络和teacher网络的输入做了不同的数据增强. 我们使用了随机翻转,random resized crop,random erasing等方法,在后来召回来的 bad case中,发现有一部分召回来的负样本是化了妆的嘴唇、眼部、脸部等,这些区域和某些恶心图正样本比较相似. 因此尝试了random_distort 的方法,经过处理之后,类似的 bad case 基本消除.
三. 算法迭代流程
在线上数据中,正负样本的比例非常不均衡(远低于千分之一),大部分都是各种各样的正常图片,只有少量的恶心图. 这意味着,即使模型在验证集上能达到99%的准确率,剩下的1%的错误也会在线上被无限放大,而且线上还有很多训练集里没出现过的负样本.
在模型版本快速的更替中,我们采取了 active learning,噪声样本识别,OHEM+级联的迭代流程,如下图所示.
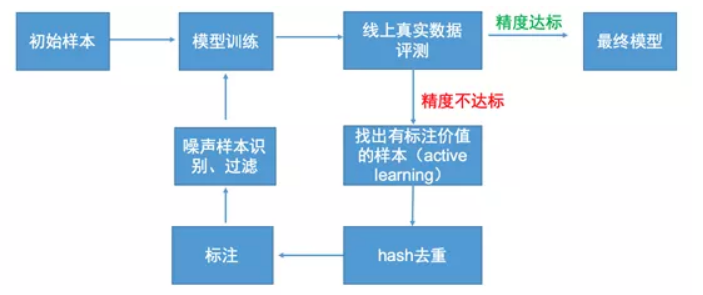
3.1. active learning
在每次的版本迭代过程中,模型都会召回一批数据. 在一开始数据量比较少的情况下,可以全部标注然后进行训练. 但是当数据变多了以后,一方面标注成本是非常巨大的,而另一方面根据curriculum learning的思想,应该让模型的学习由易到难,先学习简单的样本,然后逐渐学习更难的样本,提高难例样本在训练集的权重,这样能够加快模型的训练,找到更好的局部最优. 因此如果每次都将所有的召回样本全部标注投入训练,结果是吃力又不太讨好的. 在此我们借鉴active learning的思想,去找出有标注价值的难例样本. 样本选择策略有两方面:
[1] -在每次召回来的样本中,选择置信度在 $\mathbf{P}_h$ 以上的和在 $\mathbf{P}_l$ 以下的样本进行标注,挑选出前者中的负样本和后者中的正样本;
[2] - 在训练时引入损失预测模块,训练的时候预测各个样本的相对损失大小. 通过该模块对召回来的样本进行loss预测,并取出排名靠前的样本进行标注.
上面两个策略都是挑选出难例样本进行标注.
选择第一个策略是因为,一般情况下,我们希望模型对正样本预测的置信度越高越好,希望模型对负样本的置信度越低越好,而置信度在 $\mathbf{P}_h$ 以上的负样本和 $\mathbf{P}_l$ 以下的正样本对于模型来说都是难例样本. 实际中选择的阈值可以根据情况来进行调节.
选择第二个策略是因为,我们可以根据loss的大小来判断是否是难例样本,但是这些样本都没有现成的label,因此我们借鉴论文 Learning loss for active learning - CVPR2019 的方法,在训练的时候加入一个损失预测(loss prediction,以下简称LP)模块,来预测各个样本的loss.
Github - Mephisto405/Learning-Loss-for-Active-Learning
LP模块从 target prediction模块(简称TP)的一些中间层抽取特征(使其特征更加丰富),组合起来用于loss预测. 训练流程为:每次一个batch进来B个样本(B为偶数),将这B个样本拆分成B/2个样本对,分别送入 TP 模块和下面的 LP 模块. LP模块的loss如下所示:
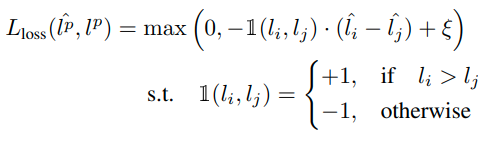
对于每个样本对,LP模块预测出来的loss的相对大小要与TP模块预测出来的相对大小保持一致,且绝对值要大于一定的阈值,才会使loss等于0. TP模块的 loss 在这里就是Ground Truth. 由于Ground Truth是随着训练不断变化的,直接对两个模块的输出计算MSE损失函数会导致效果非常差. 而且在做inference的时候,并不需要知道每个样本具体的loss大小,而只需要知道他们的loss的排名.
在实际场景运用中,我们同时运用了置信度选择和LP模块两个策略,并且在线上做了测试. 结果如下:
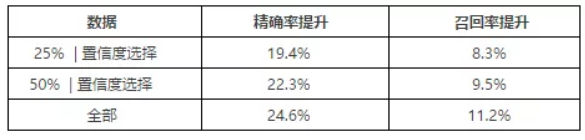
每一行表示的是,从上一版的模型召回的数据中,用相应的策略选择样本,进行标注后加入训练,然后相比于上一版的模型的精确率提升量和召回率提升量(注:本文所有的提升量都是指的绝对值). 最后一行是指标注全部数据,|代表取并集. 从中可以看出,相比于最后一行,只需要标注30%的数据(25%的数据和置信度选择的数据取并集),就获得大部分的精确率提升和召回数量提升. 也就是说,后续performance的提升主要来源于这些难例数据,而在这个过程中可以减少约70%的标注量.
3.2. 噪声样本识别
在解决业务问题时,我们总希望能获得高质量的训练样本,而从业务场景中拿到的数据都含有一定比例的噪声样本,可能是因为标注规则不清晰,培训不够完善,或者是有一些边界样本,或者是其他的一些原因,即使是外包同学标注的数据往往也存在误标的情况. 如下图所示,这些都被标注成了正样本,如果将这些数据送入模型训练,很容易造成误杀.

在实验中我们发现,如果不对噪声样本进行处理的话,无论怎么改进算法本身,在验证集的精度一直上不去,到达了一个瓶颈.
经过调研之后,我们发现,针对噪声样本问题,大致有以下四种解决方案:
[1] - 多人标注后进行投票,这种方法能在根源上消除噪声样本,但是成本巨大;
[2] - 训练时采取更大的batch size,这种方法能够在一定程度上降低噪声样本带来的影响,但是无法完全消除,而且容易受到计算资源的限制;
[3] - 设计一个noise-robust model,这种方法一般会设计特殊的网络结构或者loss函数,来提高模型的抗噪性能,但是其设计往往过于复杂;
[4] - 通过噪声样本识别方法来识别出噪声样本并进行校验,然后在干净的数据集重新训练.
最终,我们选择了上面第四种方案. 我们使用本团队发表在 ICCV2019 的论文 O2U-Net: A Simple Noisy Label Detection Approachfor Deep Neural Networks. 其基本思想为:在训练过程中循环调整学习率,使得模型在过拟合和欠拟合状态间反复切换. 突然增大学习率,使得网络跳出局部最优,进入欠拟合状态,此时噪声样本产生的loss较大,而干净样本的loss偏小,随着训练,学习率衰减,网络慢慢进入过拟合状态. 此时噪声样本和干净样本的loss都很小. 在此过程中噪声样本的loss的均值和方差都比干净样本大. 论文中学习率和样本loss的周期性变化如下图所示:
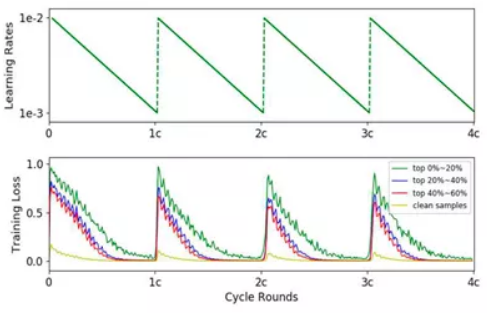
网络的训练分为三步:
[1] - pre-training阶段. 学习率设为正常值,训练直到在验证集的accuracy达到稳定.
[2] - 循环学习率阶段.
[3] - 对疑似噪声样本进行校验,在干净的数据集上重新训练.
我们对loss均值排名前5%的疑似噪声数据重新进行了标注. 发现其中有约71%的是错标的噪声样本(其他的是难例样本),将这些噪声样本重新标注后加入训练集训练,在验证集的精度提高了0.74%,在线上的精确率提高了约8%. 从此可以看出,验证集的一个小的进步可以在线上改进很多,反之一个小的错误在线上会被放大很多倍.
[淘宝噪声标签自动识别算法转] - AIUAI](https://www.aiuai.cn/aifarm1260.html)
3.3. OHEM +级联
在数据量达到一定的规模之后,此时mobilenet_v2的performance表现非常疲软,在线上的结果表明,densenet的精确率比mobilenet_v2高5个百分点,于是我们果断切到了densenet. 另一方面,面临样本不平衡问题,如何保证精确率达到90%以上,同时要保证召回率,就构成一个挑战. 我们调研了一些处理样本不平衡问题的方法. 其中,我们注意到目标检测领域的经典的 adaboost+cascade 的算法. 目标检测领域里会生成很多候选区域,所以会产生很多负样本. 用 adaboost 算法构建强分类器,然后将多个分类器级联就可以使大部分正样本通过的同时拒绝掉几乎所有的负样本. 在我们的业务场景下,我们采用了OHEM(online hard example mining)+级联的方法,如下图所示:
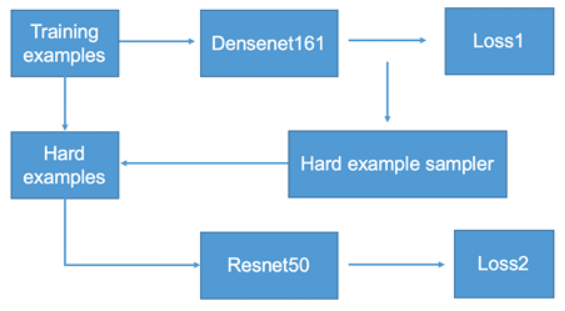
在训练的时候,第一个网络densenet161的batch size为A,然后将其 loss 最大的B个样本,送入到第二个网络 resnet50 进行训练. 这样每次第二个网络学习到的是第一个网络觉得比较难的样本. 在inference的时候,对两个模型的结果取与. 第二个网络选择resnet50是因为其表现优异,在验证集的精度只比densenet161 低 0.2%,之所以不选择同系列更大的网络是为了防止过拟合. 另一方面,OHEM算法本身就可以处理样本不平衡问题,因此不需要像某些two stage的目标检测算法,在第一个网络中设置1:3的超参数来进行欠采样.
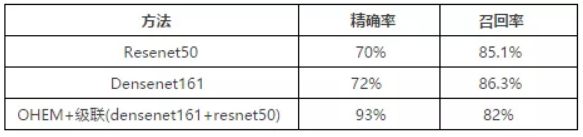
采用级联的方法后,在线上的精确率和召回率的变化见下表. 相比于单网络densenet161,精确率提高了21%,召回率降低了4.3%.
四. attention机制
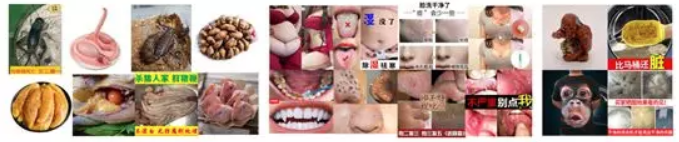
恶心图大致可以分为三类. 第一种类型是跟动物有关的,包括各种令人感到惊悚的爬行动物(从无腿的到无数条腿的都有),昆虫,以及一些颜色鲜红的死体活体,动物内脏等. 第二种类型,是跟人有关的,展示的是人体的各个丑陋、病态的部位. 如过度肥胖,脏牙齿,脸部、鼻子、身体、手脚等各种皮肤问题. 第三种是其他类型,即一些物体,包括惊悚的衣服、模型,脏乱的洗衣机、房间,马桶等. (下图高能,可直接跳过)
恶心样本多种多样,样本的特征分布非常分散. 我们分析样本后观察到,大部分图片都是某个或者某几个局部区域表现出令人恶心的特征,而不是全局都呈现出恶心的特征. 所以针对各种各样的恶心图,如何让模型focus到这些局部的恶心区域,对于提高模型的performance和泛化能力至关重要. 我们首先调研了论文 Learning Deep Features for Discriminative Localization - CVPR2016,作者将分类网络中最后的全连接层换成了GAP(Global average pooling)层,针对某一个类别,将最后一次卷积操作得到的feature map与其权重进行累加求和,于是就得到了这个类别的class activation map(CAM),如下图所示:
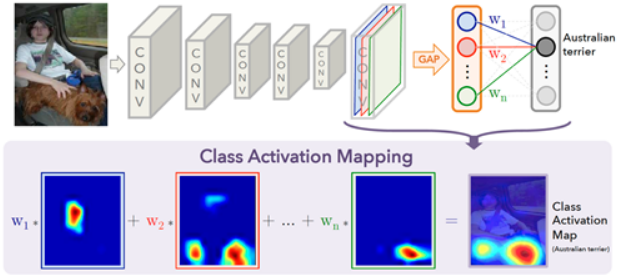
CAM反映了这个类别关注图片中的哪个区域. 那么反过来,如果我们能够调整各个feature map的权重,对每个通道进行加权,那么就能够调整网络所关心的区域. 另一方面,卷积操作本身涉及到通道和空间两个维度,我们不仅可以对每个通道的特征进行加权,也可以对每个空间位置的特征进行加权. 因此我们采用了下图的方案.
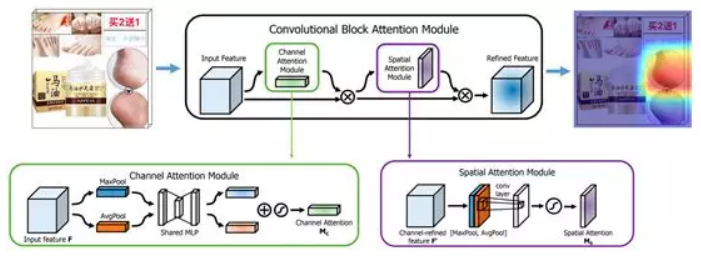
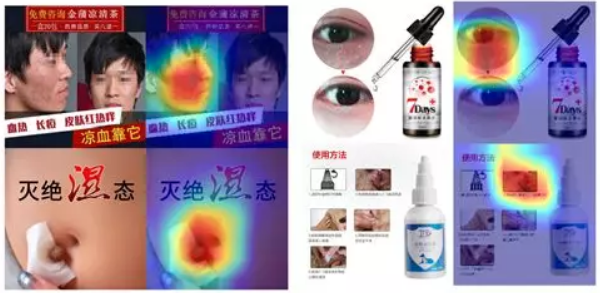
我们在网路的基础block中嵌入了上图中的attention block. 其中,每个attention block由一个channel attention module和一个spatial attention module组成. (具体实现细节可参考 CBAM:Convolutional Block Attention Module]()). 我们使用Grad-CAM的方法,利用梯度信息对网络关注的特征进行了可视化,如下图所示(高能,可直接跳过),反映出模型focus在恶心的区域上.
五. 业务结果
目前,我们的恶心图模型已经在首猜上线,持续扫描首猜的增量商品池. 主要取得的业务结果如下:
[1] - 在今年双十一的前两天,对首猜的全量商品池进行扫描,为双十一期间消费者购物体验的提升作出了贡献;
[2] - 对便宜好货和阿里妈妈的广告图片进行扫描,运营根据扫描结果进行手动商品下线;
[3] - 最新一版的模型在首猜达到了95%的精确率,召回率为94%.
目前,恶心图的精确率和召回率都达到了要求. 在图像质量维度上,淘宝对素材质量有以下诉求:
[1] - 电商图像信息表达准确度要高(卖家秀和买家秀差异吐槽,误导购买的平台风险)
[2] - 高质量图片的转化效率更高;
[3] - 不同场景运营标准和颗粒度差异.
因此,我们打造了一个水滴平台,对于各个业务方关注的图像质量问题,比如清晰度、牛皮癣、拼接图、白底图、多主体、插画图、纯色背景图、低俗、恶心图等等,利用各任务间的共享特征、以及海量的无标签数据,通过 multi-task learning 提高图像任务的识别精度同时加快模型迭代的效率、减少数据标注量. 目前已用于素材质量检测、基于视觉的自动化测试、基础处理(空窗、天坑、错误页)等方面.
参考资料
[1] - MobileNetV2: Inverted Residuals and Linear Bottlenecks
[2] - Mean teachers are better role models:Weight-averaged consistencytargets improve semi-supervised deep learning results
[3] - Learning Loss for Active Learning
[4] - O2U-Net: A Simple Noisy Label Detection Approach for Deep NeuralNetworks
[5] - Training Region-Based Object Detectors With Online Hard ExampleMining
[6] - Deep Residual Learning for Image Recognition
[7] - Densely Connected Convolutional Networks