Github 项目 - 百度语义分割库PaddleSeg - AIUAI
PaddleSeg 语义分割库的自定义图像数据集的语义分割实现.
1. 数据标注
需预先采集好用于训练、评估和测试的图片,并使用数据标注工具完成数据标注.
PaddleSeg支持2种标注工具:LabelMe、精灵数据标注工具.
标注教程如下:
最后用我们提供的数据转换脚本将上述标注工具产出的数据格式转换为模型训练时所需的数据格式.
数据标注推荐使用LabelMe工具.
2. 数据准备
PaddleSeg 采用通用的文件列表方式组织训练集、验证集和测试集. 像素标注类别需要从0开始递增.
注: 标注图像请使用PNG无损压缩格式的图片
以Cityscapes数据集为例, 需要整理出训练集、验证集、测试集对应的原图和标注文件列表用于PaddleSeg 训练即可.
其中DATASET.DATA_DIR为数据根目录,文件列表的路径以数据集根目录作为相对路径起始点.
./cityscapes/ # 数据集根目录
├── gtFine # 标注目录
│ ├── test
│ │ ├── berlin
│ │ └── ...
│ ├── train
│ │ ├── aachen
│ │ └── ...
│ └── val
│ ├── frankfurt
│ └── ...
└── leftImg8bit # 原图目录
├── test
│ ├── berlin
│ └── ...
├── train
│ ├── aachen
│ └── ...
└── val
├── frankfurt
└── ...文件列表组织形式如下:
原始图片路径 [SEP] 标注图片路径其中[SEP]是文件路径分割符,可以在DATASET.SEPARATOR配置项中修改, 默认为空格.
注意事项:
- 务必保证分隔符在文件列表中每行只存在一次, 如文件名中存在空格,请使用'|'等文件名不可用字符进行切分
- 文件列表请使用UTF-8格式保存, PaddleSeg默认使用UTF-8编码读取file_list文件
如下图所示,左边为原图的图片路径,右边为图片对应的标注路径.

3. PaddleSeg 训练配置
pdseg/utils/config.py
根据 config.py 文件分别说明.
from __future__ import print_function
from __future__ import unicode_literals
from utils.collect import SegConfig
import numpy as np
cfg = SegConfig()3.1. 基本配置
## 基本配置 ##
# 均值,图像预处理减去的均值(格式为 [R, G, B])
cfg.MEAN = [0.5, 0.5, 0.5]
# 标准差,图像预处理除以标准差(格式为 [R, G, B])
cfg.STD = [0.5, 0.5, 0.5]
# 批处理大小
cfg.BATCH_SIZE = 1
# 验证(评估)时图像裁剪尺寸(格式为 [宽,高])
cfg.EVAL_CROP_SIZE = tuple()
# 训练时图像裁剪尺寸(格式为 [宽,高])
cfg.TRAIN_CROP_SIZE = tuple()注:
[1] - EVAL_CROP_SIZE :裁剪的大小不能小于原图.
[2] - BATCH_SIZE:训练、评估及可视化时所用的BATCH大小.
- 当指定了多卡运行时,PaddleSeg 会将数据平分到每张卡上运行,因此每张卡单次运行的数量为 BATCH_SIZE // dev_count.
- 多卡运行时,请确保 BATCH_SIZE 可被 dev_count 整除.
- 增大 BATCH_SIZE 有利于模型训练时的收敛速度,但是会带来显存的开销.
- 目前 PaddleSeg 提供的很多预训练模型都有BN层,如果 BATCH SIZE 设置为 1,则训练可能不稳定导致 nan.
3.2. 数据集配置
## 数据集配置 ##
# 数据主目录目录
cfg.DATASET.DATA_DIR = './dataset/cityscapes/'
# 训练集列表
cfg.DATASET.TRAIN_FILE_LIST = './dataset/cityscapes/train.list'
# 训练集数量
cfg.DATASET.TRAIN_TOTAL_IMAGES = 2975
# 验证集列表
cfg.DATASET.VAL_FILE_LIST = './dataset/cityscapes/val.list'
# 验证数据数量
cfg.DATASET.VAL_TOTAL_IMAGES = 500
# 测试数据列表
cfg.DATASET.TEST_FILE_LIST = './dataset/cityscapes/test.list'
# 测试数据数量
cfg.DATASET.TEST_TOTAL_IMAGES = 500
# Tensorboard 可视化的数据集
cfg.DATASET.VIS_FILE_LIST = None
# 类别数(需包括背景类)
cfg.DATASET.NUM_CLASSES = 19
# 输入图像类型, 支持三通道'rgb',四通道'rgba',单通道灰度图'gray'
cfg.DATASET.IMAGE_TYPE = 'rgb'
# 输入图片的通道数
cfg.DATASET.DATA_DIM = 3
# 数据列表分割符, 默认为空格
cfg.DATASET.SEPARATOR = ' '
# 忽略的像素标签值, 默认为255,一般无需改动
cfg.DATASET.IGNORE_INDEX = 255
# 数据增强时图像的padding值
cfg.DATASET.PADDING_VALUE = [127.5,127.5,127.5]注:
[1] - DATA_DIR:与文件名拼接,以组成图片的绝对路径名.
[2] - TRAIN_FILE_LIST、VAL_FILE_LIST 、TEST_FILE_LIST 和 VIS_FILE_LIST:由多行数据组成,每行的数据格式为:
<img_path><sep><label_path>[3] - NUM_CLASSES:类别数量,构建网络所需,包含背景类别. 数据集中的 label 标注必须为 0 ~ (NUM_CLASSES - 1),如果label设置错误,会导致计算IOU时出现异常.
[4] - SEPARATOR:文件列表中用于分隔输入图片和标签图片的分隔符,默认为空格符. 假设训练文件列表如下,则 SEPARATOR 应该填写 |.
mydata/train/image1.jpg|mydata/train/image1.label.jpg
mydata/train/image2.jpg|mydata/train/image2.label.jpg
mydata/train/image3.jpg|mydata/train/image3.label.jpg
mydata/train/image4.jpg|mydata/train/image4.label.jpg
...[5] - IGNORE_INDEX:默认为 255. 忽略的像素标签值,label 中所有标记为该值的像素不会参与到 loss 的计算以及IOU、Acc等指标的计算.
3.3. 数据加载配置
## 数据载入配置 ##
# 数据载入时的并发数, 建议值8
cfg.DATALOADER.NUM_WORKERS = 8
# 数据载入时缓存队列大小, 建议值256
cfg.DATALOADER.BUF_SIZE = 2563.4. 数据增强配置
## 数据增强配置 ##
# 图像镜像左右翻转
cfg.AUG.MIRROR = True
# 图像上下翻转开关,True/False
cfg.AUG.FLIP = False
# 图像启动上下翻转的概率,0-1
cfg.AUG.FLIP_RATIO = 0.5
# 图像resize的固定尺寸(宽,高),非负
cfg.AUG.FIX_RESIZE_SIZE = tuple()
# 图像resize的方式有三种:
# unpadding(固定尺寸),stepscaling(按比例resize),rangescaling(长边对齐)
cfg.AUG.AUG_METHOD = 'rangescaling'
# 图像resize方式为stepscaling,resize最小尺度,非负
cfg.AUG.MIN_SCALE_FACTOR = 0.5
# 图像resize方式为stepscaling,resize最大尺度,不小于MIN_SCALE_FACTOR
cfg.AUG.MAX_SCALE_FACTOR = 2.0
# 图像resize方式为stepscaling,resize尺度范围间隔,非负
cfg.AUG.SCALE_STEP_SIZE = 0.25
# 图像resize方式为rangescaling,训练时长边resize的范围最小值,非负
cfg.AUG.MIN_RESIZE_VALUE = 400
# 图像resize方式为rangescaling,训练时长边resize的范围最大值,
# 不小于MIN_RESIZE_VALUE
cfg.AUG.MAX_RESIZE_VALUE = 600
# 图像resize方式为rangescaling, 测试验证可视化模式下长边resize的长度,
# 在MIN_RESIZE_VALUE到MAX_RESIZE_VALUE范围内
cfg.AUG.INF_RESIZE_VALUE = 500
# RichCrop数据增广开关,用于提升模型鲁棒性
cfg.AUG.RICH_CROP.ENABLE = False
# 图像旋转最大角度,0-90
cfg.AUG.RICH_CROP.MAX_ROTATION = 15
# 裁取图像与原始图像面积比,0-1
cfg.AUG.RICH_CROP.MIN_AREA_RATIO = 0.5
# 裁取图像宽高比范围,非负
cfg.AUG.RICH_CROP.ASPECT_RATIO = 0.33
# 亮度调节范围,0-1
cfg.AUG.RICH_CROP.BRIGHTNESS_JITTER_RATIO = 0.5
# 饱和度调节范围,0-1
cfg.AUG.RICH_CROP.SATURATION_JITTER_RATIO = 0.5
# 对比度调节范围,0-1
cfg.AUG.RICH_CROP.CONTRAST_JITTER_RATIO = 0.5
# 图像模糊开关,True/False
cfg.AUG.RICH_CROP.BLUR = False
# 图像启动模糊百分比,0-1
cfg.AUG.RICH_CROP.BLUR_RATIO = 0.13.5. 模型配置
## 模型通用配置 ##
# 模型名称, 支持deeplab, unet, icnet三种
cfg.MODEL.MODEL_NAME = ''
# BatchNorm类型: bn、gn(group_norm)
cfg.MODEL.DEFAULT_NORM_TYPE = 'bn'
# 多路损失加权值
cfg.MODEL.MULTI_LOSS_WEIGHT = [1.0]
# DEFAULT_NORM_TYPE为gn时group数
cfg.MODEL.DEFAULT_GROUP_NUMBER = 32
# 极小值, 防止分母除0溢出,一般无需改动
cfg.MODEL.DEFAULT_EPSILON = 1e-5
# BatchNorm动量, 一般无需改动
cfg.MODEL.BN_MOMENTUM = 0.99
# 是否使用FP16训练
cfg.MODEL.FP16 = False
# FP16需对LOSS进行scale, 一般训练FP16设置为8.0
cfg.MODEL.SCALE_LOSS = 1.0注:
[1] - MULTI_LOSS_WEIGHT:多路损失的权重.
- 仅在模型存在多路损失的情况下生效
- 目前支持的模型中只有
icnet使用多路(3路)损失 - 当选择模型为
icnet且该值的长度不为 3 时,PaddleSeg 会强制设置该字段为[1.0, 0.4, 0.16].
例如:
假设模型存在三路损失,计算结果分别为loss1/loss2/loss3,并且MULTI_LOSS_WEIGHT的值为[1.0, 0.4, 0.16],则最终损失的计算结果为:
loss = 1.0 * loss1 + 0.4 * loss2 + 0.16 * loss3[2] - SCALE_LOSS:对损失进行缩放的系数,默认值为 1.0. 当 FP16=True 时,建议其值设为 8.
## DeepLab模型配置 ##
# DeepLab backbone 配置, 可选项xception_65, mobilenetv2
cfg.MODEL.DEEPLAB.BACKBONE = "xception_65"
# DeepLab output stride
cfg.MODEL.DEEPLAB.OUTPUT_STRIDE = 16
# MobileNet backbone scale 设置
cfg.MODEL.DEEPLAB.DEPTH_MULTIPLIER = 1.0
# MobileNet backbone scale 设置
cfg.MODEL.DEEPLAB.ENCODER_WITH_ASPP = True
# MobileNet backbone scale 设置
cfg.MODEL.DEEPLAB.ENABLE_DECODER = True
# ASPP是否使用可分离卷积
cfg.MODEL.DEEPLAB.ASPP_WITH_SEP_CONV = True
# 解码器是否使用可分离卷积
cfg.MODEL.DEEPLAB.DECODER_USE_SEP_CONV = True
## UNET模型配置 ##
# 上采样方式, 默认为双线性插值.不设置,则采用转置卷积进行上采样.
cfg.MODEL.UNET.UPSAMPLE_MODE = 'bilinear'
## ICNET模型配置 ##
# RESNET backbone scale 设置
cfg.MODEL.ICNET.DEPTH_MULTIPLIER = 0.5
# RESNET 层数 设置
cfg.MODEL.ICNET.LAYERS = 50
## PSPNET模型配置 ##
# RESNET backbone scale 设置
cfg.MODEL.PSPNET.DEPTH_MULTIPLIER = 1
# RESNET 层数 设置 50或101. 支持 18 34 50 101 152.
cfg.MODEL.PSPNET.LAYERS = 50注:
[1] - DEPTH_MULTIPER:MobileNet V2的depth mutiper值,仅当BACKBONE为mobilenetv2 生效.
[2] - ENCODER_WITH_ASPP:DeepLabv3+的模型Encoder中是否使用ASPP. 默认为 True. 若设置为 False,可以提升模型计算速度,但是会降低精度.
[3] - DECODER_WITH_ASPP:DeepLabv3+的模型是否使用Decoder. 默认为 True. 若设置为 False,可以提升模型计算速度,但是会降低精度.
3.6. 优化配置
## 模型优化相关配置 ##
# 初始学习率
cfg.SOLVER.LR = 0.1
# 学习率下降方法, 支持poly piecewise cosine 三种
cfg.SOLVER.LR_POLICY = "poly"
# 优化算法, 支持SGD和Adam两种算法
cfg.SOLVER.OPTIMIZER = "sgd"
# 动量参数
cfg.SOLVER.MOMENTUM = 0.9
# 二阶矩估计的指数衰减率
cfg.SOLVER.MOMENTUM2 = 0.999
# 学习率Poly下降指数,仅当策略为LR_POLICY为poly时有效
cfg.SOLVER.POWER = 0.9
# step下降指数,仅当策略为LR_POLICY为piecewise时有效
cfg.SOLVER.GAMMA = 0.1
# step下降间隔,仅当策略为LR_POLICY为piecewise时有效
cfg.SOLVER.DECAY_EPOCH = [10, 20]
# 学习率权重衰减,0-1,L2正则化系数
cfg.SOLVER.WEIGHT_DECAY = 0.00004
# 训练开始epoch数,默认为1
cfg.SOLVER.BEGIN_EPOCH = 1
# 训练epoch数,正整数
cfg.SOLVER.NUM_EPOCHS = 30注:
[1] - LR_POLICY:学习率的衰减策略,支持poly piecewise cosine三种策略.
[1.1.] - 当使用poly衰减时,假设初始学习率为0.1,训练总步数为10000,则在power分别为0.4 0.8 1 1.2 1.6时,衰减曲线如下图:
- power = 1 衰减曲线为直线
- power > 1 衰减曲线内凹
- power < 1 衰减曲线外凸
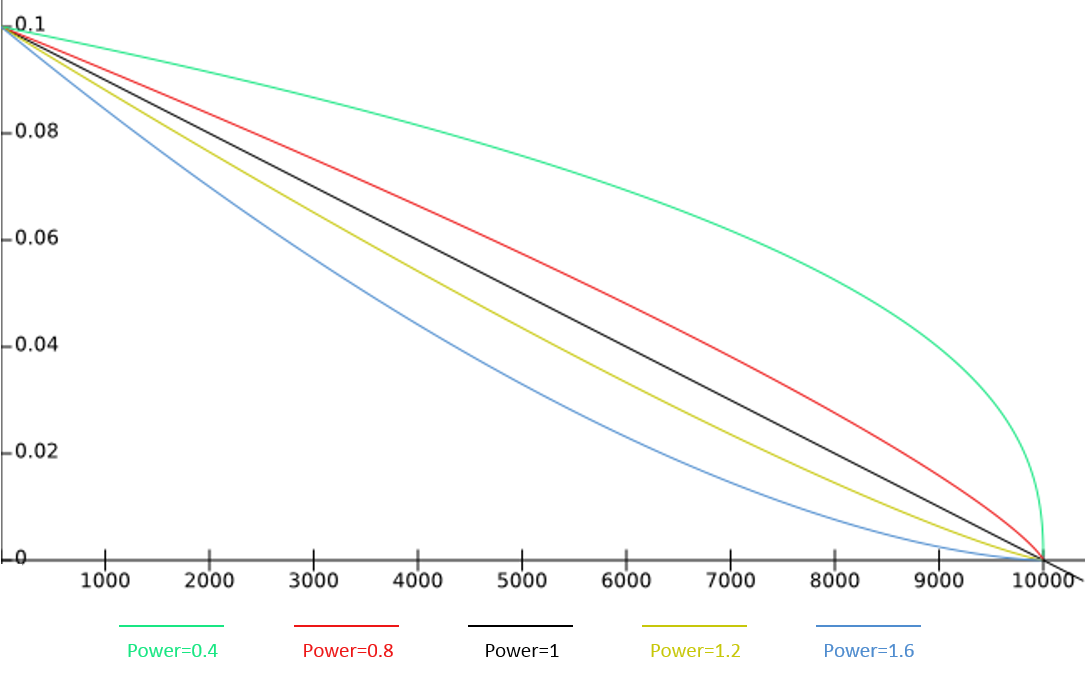
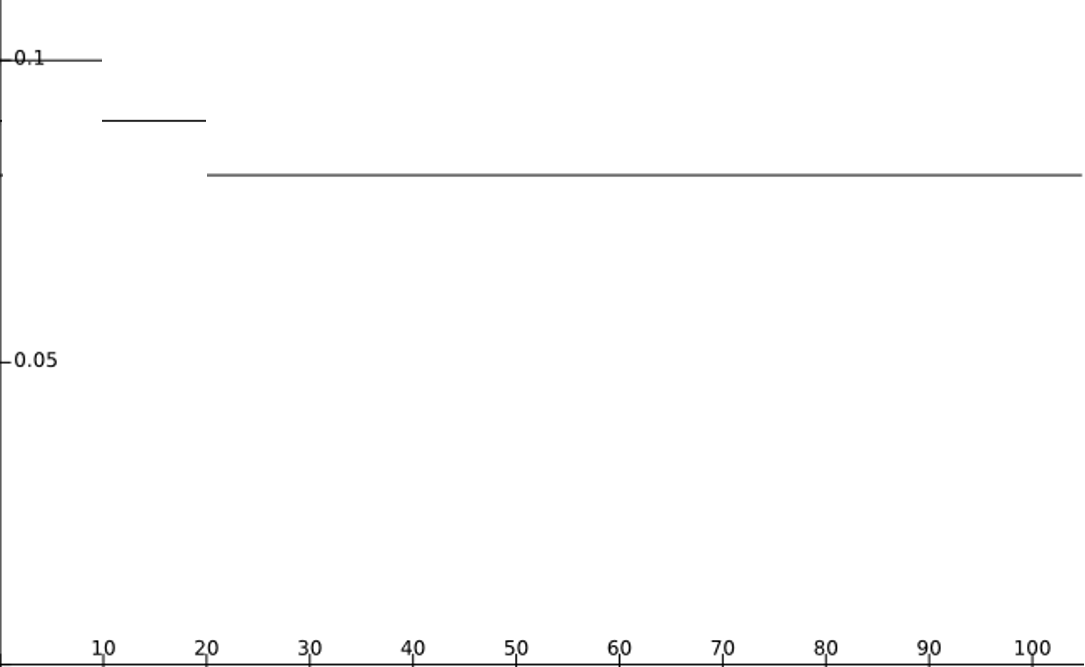
[1.2.] - 当使用piecewise衰减时,假设初始学习率为0.1,GAMMA为0.9,总EPOCH数量为100,DECAY_EPOCH为[10, 20],衰减曲线如下图:
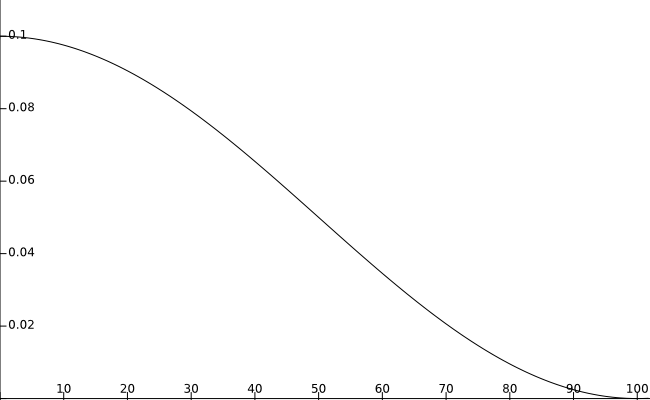
[1.3.] - 当使用cosine衰减时,假设初始学习率为0.1,总EPOCH数量为100,衰减曲线如下图:
3.7. 训练配置
## 训练配置 ##
# 模型保存路径
cfg.TRAIN.MODEL_SAVE_DIR = ''
# 预训练模型路径
cfg.TRAIN.PRETRAINED_MODEL_DIR = ''
# 是否resume,继续训练
cfg.TRAIN.RESUME_MODEL_DIR = ''
# 是否使用多卡间同步BatchNorm均值和方差
cfg.TRAIN.SYNC_BATCH_NORM = False
# 模型参数保存的epoch间隔数,可用来继续训练中断的模型
cfg.TRAIN.SNAPSHOT_EPOCH = 10注:
[1] - PRETRAINED_MODEL_DIR:预训练模型路径.
- 若未指定,则模型会随机初始化所有的参数,从头开始训练
- 若指定了,但是路径不存在,则参数加载失败,仍然会被随机初始化
- 若指定了,且路径存在,但是部分参数不存在或者shape无法对应,则该部分参数随机初始化
[2] - RESUME_MODEL_DIR:从指定路径中恢复参数并继续训练. 当 RESUME_MODEL_DIR 存在时,PaddleSeg会恢复到上一次训练的最近一个epoch,并且恢复训练过程中的临时变量(如已经衰减过的学习率,Optimizer的动量数据等),PRETRAINED_MODEL 路径的最后一个目录必须为int数值或者字符串final,PaddleSeg会将int数值作为当前起始EPOCH继续训练,若目录为final,则不会继续训练. 若目录不满足上述条件,PaddleSeg会抛出错误.
[3] - SYNC_BATCH_NORM:是否在多卡间同步BN的均值和方差.
- 值设为 True 时,带来一定的性能消耗(多卡间同步数据导致)
- 仅在GPU多卡训练时值设为 True 才有效(Windows不支持多卡训练,因此无需打开该开关)
- GPU多卡训练时,建议开启,可以提升模型的训练效果
3.8. 测试配置
## 测试配置 ##
# 测试模型路径
cfg.TEST.TEST_MODEL = ''3.9. 模型部署配置
## 预测部署模型配置 ##
# 预测保存的模型名称,仅用在使用 pdseg/export_model.py 导出模型时.
cfg.FREEZE.MODEL_FILENAME = '__model__'
# 预测保存的参数名称,仅用在使用 pdseg/export_model.py 导出模型时.
cfg.FREEZE.PARAMS_FILENAME = '__params__'
# 预测模型参数保存的路径,仅用在使用 pdseg/export_model.py 导出模型时.
cfg.FREEZE.SAVE_DIR = 'freeze_model'4. 数据校验
对自定义的数据集和 yaml 配置进行校验,以排查基本的数据和配置问题.
数据校验脚本如下,支持通过YAML_FILE_PATH来指定配置文件.
# YAML_FILE_PATH为yaml配置文件路径
python pdseg/check.py --cfg ${YAML_FILE_PATH}运行后,命令行将显示校验结果的概览信息,详细信息可到detail.log文件中查看.
4.1. 列表分割符校验
判断在 TRAIN_FILE_LIST,VAL_FILE_LIST和TEST_FILE_LIST 列表文件中的分隔符DATASET.SEPARATOR设置是否正确.
4.2. 数据集读取校验
通过是否能成功读取DATASET.TRAIN_FILE_LIST,DATASET.VAL_FILE_LIST,DATASET.TEST_FILE_LIST中所有图片,判断这3项设置是否正确.
若不正确返回错误信息. 错误可能有多种情况,如数据集路径设置错误、图片损坏等.
4.3. 标注格式校验
检查标注图像是否为PNG格式.
NOTE: 标注图像请使用PNG无损压缩格式的图片,若使用其他格式则可能影响精度.
4.4. 标注通道数校验
检查标注图的通道数. 正确的标注图应该为单通道图像.
4.5. 标注类别校验
检查实际标注类别是否和配置参数DATASET.NUM_CLASSES,DATASET.IGNORE_INDEX匹配.
NOTE:
[1] - 标注图像类别数值必须在[0~(DATASET.NUM_CLASSES-1)]范围内或者为DATASET.IGNORE_INDEX. 标注类别最好从0开始,否则可能影响精度.
[2] - PaddleSeg支持0~255共256类标签,其中255类别表示ignore,即在训练阶段不会使用该像素进行学习,默认以0开始标注类别.
4.6. 标注像素统计
统计每种类别像素数量,显示以供参考.
4.7. 图像格式校验
检查图片类型 DATASET.IMAGE_TYPE 是否设置正确.
NOTE: 当数据集包含三通道图片时DATASET.IMAGE_TYPE设置为rgb; 当数据集全部为四通道图片时DATASET.IMAGE_TYPE设置为rgba;
4.8. 图像与标注图尺寸一致性校验
验证图像尺寸和对应标注图尺寸是否一致.
4.9. 模型验证参数EVAL_CROP_SIZE校验
验证EVAL_CROP_SIZE是否设置正确,共有3种情形:
- 当
AUG.AUG_METHOD为unpadding时,EVAL_CROP_SIZE的宽高应不小于AUG.FIX_RESIZE_SIZE的宽高. - 当
AUG.AUG_METHOD为stepscaling时,EVAL_CROP_SIZE的宽高应不小于原图中最大的宽高. - 当
AUG.AUG_METHOD为rangscaling时,EVAL_CROP_SIZE的宽高应不小于缩放后图像中最大的宽高.
4.10. 数据增强参数AUG.INF_RESIZE_VALUE校验
验证 AUG.INF_RESIZE_VALUE 是否在 [AUG.MIN_RESIZE_VALUE~AUG.MAX_RESIZE_VALUE] 范围内. 若在范围内,则通过校验.
5. 模型训练
主要包含三部分的配置:
数据集
- 训练集主目录
- 训练集文件列表
- 测试集文件列表
- 评估集文件列表
预训练模型
- 预训练模型名称
- 预训练模型的backbone网络
- 预训练模型的Normalization类型
- 预训练模型路径
其他
- 学习率
- Batch大小
- ...
在三者中,预训练模型的配置尤为重要,如果模型或者 BACKBONE 配置错误,会导致预训练的参数没有加载,进而影响收敛速度.
数据集的配置和数据路径有关,这里假设数据存放在 dataset/mini_pet 中.
其他配置则根据数据集和机器环境的情况进行调节,最终会保存一个如下内容的yaml配置文件,存放路径为:configs/xxx.yaml.
5.1. U-Net
configs/unet_pet.yaml
# 数据集配置
DATASET:
DATA_DIR: "./dataset/mini_pet/"
NUM_CLASSES: 3 #主体类目数量
TEST_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
TRAIN_FILE_LIST: "./dataset/mini_pet/file_list/train_list.txt"
VAL_FILE_LIST: "./dataset/mini_pet/file_list/val_list.txt"
VIS_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
# 预训练模型配置
MODEL:
MODEL_NAME: "unet"
DEFAULT_NORM_TYPE: "bn"
# 其他配置
TRAIN_CROP_SIZE: (512, 512)
EVAL_CROP_SIZE: (512, 512)
AUG:
AUG_METHOD: "unpadding"
FIX_RESIZE_SIZE: (512, 512)
BATCH_SIZE: 4
TRAIN:
PRETRAINED_MODEL_DIR: "./pretrained_model/unet_bn_coco/"
MODEL_SAVE_DIR: "./saved_model/unet_pet/"
SNAPSHOT_EPOCH: 10
TEST:
TEST_MODEL: "./saved_model/unet_pet/final"
SOLVER:
NUM_EPOCHS: 100
LR: 0.005
LR_POLICY: "poly"
OPTIMIZER: "adam"| 预训练模型名称 | BackBone | Norm | 数据集 | 配置 |
|---|---|---|---|---|
| unet_bn_coco | - | bn | COCO | MODEL.MODEL_NAME: unet MODEL.DEFAULT_NORM_TYPE: bn |
5.2. DeepLabV3+
configs/deeplabv3p_xception65_pet.yaml
# 数据集配置
DATASET:
DATA_DIR: "./dataset/mini_pet/"
NUM_CLASSES: 3
TEST_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
TRAIN_FILE_LIST: "./dataset/mini_pet/file_list/train_list.txt"
VAL_FILE_LIST: "./dataset/mini_pet/file_list/val_list.txt"
VIS_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
# 预训练模型配置
MODEL:
MODEL_NAME: "deeplabv3p"
DEFAULT_NORM_TYPE: "bn"
DEEPLAB:
BACKBONE: "xception_65"
# 其他配置
TRAIN_CROP_SIZE: (512, 512)
EVAL_CROP_SIZE: (512, 512)
AUG:
AUG_METHOD: "unpadding"
FIX_RESIZE_SIZE: (512, 512)
BATCH_SIZE: 4
TRAIN:
PRETRAINED_MODEL_DIR: "./pretrained_model/deeplabv3p_xception65_bn_coco/"
MODEL_SAVE_DIR: "./saved_model/deeplabv3p_xception65_bn_pet/"
SNAPSHOT_EPOCH: 10
TEST:
TEST_MODEL: "./saved_model/deeplabv3p_xception65_bn_pet/final"
SOLVER:
NUM_EPOCHS: 100
LR: 0.005
LR_POLICY: "poly"
OPTIMIZER: "sgd"| 预训练模型名称 | BackBone | Norm Type | 数据集 | 配置 |
|---|---|---|---|---|
| mobilenetv2-2-0_bn_imagenet | - | bn | ImageNet | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: mobilenet MODEL.DEEPLAB.DEPTH_MULTIPLIER: 2.0 MODEL.DEFAULT_NORM_TYPE: bn |
| mobilenetv2-1-5_bn_imagenet | - | bn | ImageNet | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: mobilenet MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.5 MODEL.DEFAULT_NORM_TYPE: bn |
| mobilenetv2-1-0_bn_imagenet | - | bn | ImageNet | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: mobilenet MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0 MODEL.DEFAULT_NORM_TYPE: bn |
| mobilenetv2-0-5_bn_imagenet | - | bn | ImageNet | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: mobilenet MODEL.DEEPLAB.DEPTH_MULTIPLIER: 0.5 MODEL.DEFAULT_NORM_TYPE: bn |
| mobilenetv2-0-25_bn_imagenet | - | bn | ImageNet | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: mobilenet MODEL.DEEPLAB.DEPTH_MULTIPLIER: 0.25 MODEL.DEFAULT_NORM_TYPE: bn |
| xception41_imagenet | - | bn | ImageNet | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: xception_41 MODEL.DEFAULT_NORM_TYPE: bn |
| xception65_imagenet | - | bn | ImageNet | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: xception_65 MODEL.DEFAULT_NORM_TYPE: bn |
| deeplabv3p_mobilenetv2-1-0_bn_coco | MobileNet V2 | bn | COCO | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: mobilenet MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0 MODEL.DEEPLAB.ENCODER_WITH_ASPP: False MODEL.DEEPLAB.ENABLE_DECODER: False MODEL.DEFAULT_NORM_TYPE: bn |
| deeplabv3p_xception65_bn_coco | Xception | bn | COCO | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: xception_65 MODEL.DEFAULT_NORM_TYPE: bn |
| deeplabv3p_mobilenetv2-1-0_bn_cityscapes | MobileNet V2 | bn | Cityscapes | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: mobilenet MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0 MODEL.DEEPLAB.ENCODER_WITH_ASPP: False MODEL.DEEPLAB.ENABLE_DECODER: False MODEL.DEFAULT_NORM_TYPE: bn |
| deeplabv3p_xception65_gn_cityscapes | Xception | gn | Cityscapes | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: xception_65 MODEL.DEFAULT_NORM_TYPE: gn |
| deeplabv3p_xception65_bn_cityscapes | Xception | bn | Cityscapes | MODEL.MODEL_NAME: deeplabv3p MODEL.DEEPLAB.BACKBONE: xception_65 MODEL.DEFAULT_NORM_TYPE: bn |
5.3. ICNet
configs/icnet_pet.yaml
# 数据集配置
DATASET:
DATA_DIR: "./dataset/mini_pet/"
NUM_CLASSES: 3
TEST_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
TRAIN_FILE_LIST: "./dataset/mini_pet/file_list/train_list.txt"
VAL_FILE_LIST: "./dataset/mini_pet/file_list/val_list.txt"
VIS_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
# 预训练模型配置
MODEL:
MODEL_NAME: "icnet"
DEFAULT_NORM_TYPE: "bn"
MULTI_LOSS_WEIGHT: "[1.0, 0.4, 0.16]"
ICNET:
DEPTH_MULTIPLIER: 0.5
# 其他配置
TRAIN_CROP_SIZE: (512, 512)
EVAL_CROP_SIZE: (512, 512)
AUG:
AUG_METHOD: "unpadding"
FIX_RESIZE_SIZE: (512, 512)
BATCH_SIZE: 4
TRAIN:
PRETRAINED_MODEL_DIR: "./pretrained_model/icnet_bn_cityscapes/"
MODEL_SAVE_DIR: "./saved_model/icnet_pet/"
SNAPSHOT_EPOCH: 10
TEST:
TEST_MODEL: "./saved_model/icnet_pet/final"
SOLVER:
NUM_EPOCHS: 100
LR: 0.005
LR_POLICY: "poly"
OPTIMIZER: "sgd"| 预训练模型名称 | BackBone | Norm | 数据集 | 配置 |
|---|---|---|---|---|
| icnet_bn_cityscapes | - | bn | Cityscapes | MODEL.MODEL_NAME: icnet MODEL.DEFAULT_NORM_TYPE: bn MODEL.MULTI_LOSS_WEIGHT: [1.0, 0.4, 0.16] |
5.4. 训练过程
[1] - 下载预训练模型权重:
python pretrained_model/download_model.py unet_bn_coco
#python pretrained_model/download_model.py deeplabv3p_xception65_bn_coco
#python pretrained_model/download_model.py icnet_bn_cityscapes[2] - 数据校验
python pdseg/check.py --cfg ./configs/unet_pet.yaml
#python pdseg/check.py --cfg ./configs/icnet_pet.yaml
#python pdseg/check.py --cfg ./configs/deeplabv3p_xception65_pet.yaml[3] - 模型训练
python pdseg/train.py --use_gpu --cfg ./configs/unet_pet.yaml
#python pdseg/train.py --use_gpu --cfg ./configs/deeplabv3p_xception65_pet.yaml
#python pdseg/train.py --use_gpu --cfg ./configs/icnet_pet.yaml示例:
选择GPU 0号卡进行训练,通过环境变量CUDA_VISIBLE_DEVICES来指定.
export CUDA_VISIBLE_DEVICES=0
python pdseg/train.py --use_gpu \
--do_eval \
--use_tb \
--tb_log_dir train_log \
--cfg configs/unet_pet.yaml \
BATCH_SIZE 4 \
TRAIN.PRETRAINED_MODEL_DIR pretrained_model/unet_bn_coco \
SOLVER.LR 5e-5注: 如果开启了 do_eval 和 use_tb ,则可以通过 TensorBoard 查看边训练边评估的效果:
tensorboard --logdir train_log --host {$HOST_IP} --port {$PORT}
#$HOST_IP为机器IP地址,替换为实际IP,$PORT替换为可访问的端口输出如:
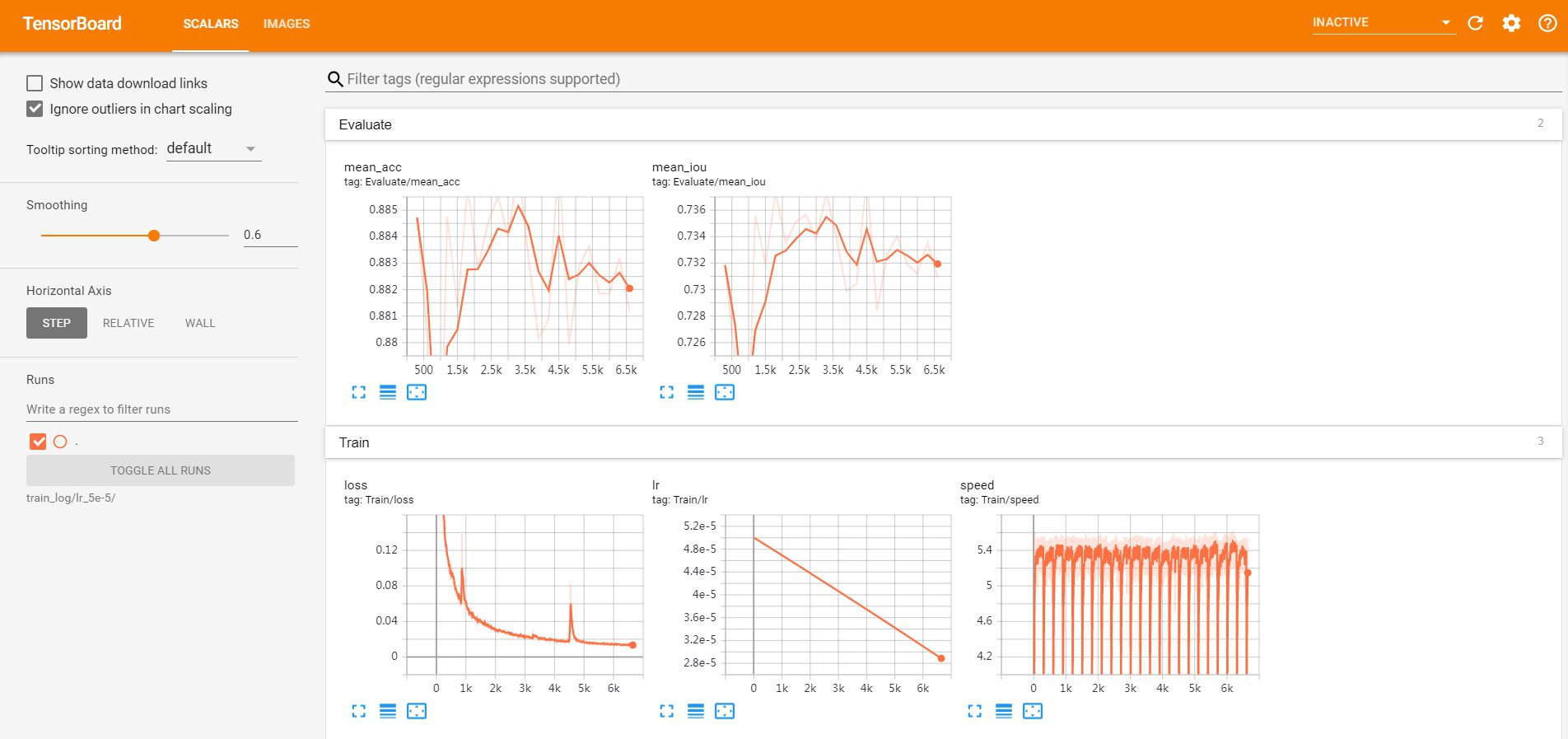

[4] - 模型评估
python pdseg/eval.py --use_gpu --cfg ./configs/unet_pet.yaml
#python pdseg/eval.py --use_gpu --cfg ./configs/deeplabv3p_xception65_pet.yaml
#python pdseg/eval.py --use_gpu --cfg ./configs/icnet_pet.yaml6. 模型可视化
PaddleSeg 提供的train.py、eval.py 和 vis.py 三个脚本,其使用方式类似:
# 训练
python pdseg/train.py ${FLAGS} ${OPTIONS}
# 评估
python pdseg/eval.py ${FLAGS} ${OPTIONS}
# 可视化
python pdseg/vis.py ${FLAGS} ${OPTIONS}注: FLAGS必须位于OPTIONS之前,否会将会遇到报错,例如如下的例子:
# FLAGS "--cfg configs/cityscapes.yaml" 必须在 OPTIONS "BATCH_SIZE 1" 之前
python pdseg/train.py BATCH_SIZE 1 --cfg configs/cityscapes.yaml6.1. 命令行FLAGS列表
| FLAG | 支持脚本 | 用途 | 默认值 | 备注 |
| --cfg | ALL | 配置文件路径 | None | |
| --use_gpu | ALL | 是否使用GPU进行训练 | False | |
| --use_mpio | train/eval | 是否使用多线程进行IO处理 | False | 会占用一定量的CPU内存,但是可以提高训练速度. NOTE: Windows平台下不支持该功能. Linux系统下训练使用--use_mpio使用多进程I/O,提升数据增强的处理速度进而大幅度提升GPU利用率. |
| --use_tb | train | 是否使用TensorBoard记录训练数据 | False | |
| --log_steps | train | 训练日志的打印周期(单位为step) | 10 | |
| --debug | train | 是否打印debug信息 | False | IOU等指标涉及到混淆矩阵的计算,会降低训练速度 |
| --tb_log_dir | train | TensorBoard的日志路径 | None | |
| --do_eval | train | 是否在保存模型时进行效果评估 | False | |
| --vis_dir | vis | 保存可视化图片的路径 | "visual" | |
| --also_save_raw_results | vis | 是否保存原始的预测图片 | False |
6.2. 模型可视化
通过 vis.py 来评估模型效果,比如,选择最后保存的模型进行效果的评估:
python pdseg/vis.py --use_gpu \
--cfg configs/unet_pet.yaml \
TEST.TEST_MODEL saved_models/unet_pet/final注:
[1] - 可视化的图片会默认保存在 visual/visual_results 目录,可以通过 --vis_dir 来指定输出目录.
[2] - 训练过程中会使用配置文件中的 DATASET.VIS_FILE_LIST 中的图片进行可视化显示,而 vis.py 则会使 DATASET.TEST_FILE_LIST.