原文: New State-of-the-art in Logo Detection Using YOLOv3 and Darknet - 2019.03.26
作者: Nikolas Laskaris
图片 Logo 检测具有很多应用场景,比如,市场分析和知识产品保护中的品牌识别(brands recognition).
Logo 检测主要面临两个主要挑战:[1]待分类的公司 logos 数量是不固定的;[2] 实际场景中的 logo 往往只占了输入图片的非常少的一部分特征.
Logo 检测精度比较高的方法是采用目标定位(object localization)方法.
基于 Logos32Plus 数据集[12] 和 YOLOv3-Darknet 目标检测方法[18],对比与 benchmark models,取得的结果为:recall(97.71%), F1(97.76%) 和 accuracy(98.12%).
1. Logo 检测的应用场景
检测图片和视频中的品牌 logos 对于市场分析(便于公司能够追踪在社交媒体内容中品牌图片出现的场合与频率)和版权保护等很多领域具有重要应用. 欧盟已经颁布了新的法律,规定技术公司对未经适当版权许可发布的材料负责[20]. 为了更便于公司能够遵守越来越严格的版权法律和版权保护需求,识别 logos 则变得越来越重要.

图1 - 带有品牌 logo 的图片例示. 左: Apple; 右: Corona.
在深度学习模型出现之前,logo 检测方法一般是基于 keypoin-based 检测器和描述子(descriptor)技术[1, 2],以及采用 homographic class graphs [3, 4] 的 logos 定位方法.
在过去几年,基于 ConvNets 的方法取得了更有的 logos 检测结果[5, 6]. 常用数据集是采用 Flickr32 数据集进行模型训练[7]. Flickr32 数据集共包含 32 个类别的 8240 张图片. 最近,Bianco 等提出了 Flickr32 扩展的 Logos32Plus 数据集. 其同样包括 32 个 logo 类别,但共 12312 张图片.

图: 32 个 Logos 类别.

图 2 - Logos32Plus 数据集概览
定位(localization)关注于输入图片的特定区域,其能够明显提升 logo 检测分类器的精度. 计算机视觉领域有很多目标检测算法,包括 Faster-RCNN, RFCN, Retinanet, SSD, Selective Search 以及 YOLO[14, 15, 16, 8, 18].

图3 - Bianco 等采用的 Selective Search 方法例示.
在对于 Logo 数据集进行模型训练时,由于 logo 目标只覆盖了输入图片中的很小的区域,关于感兴趣的目标物体的定位信息能够显著提升分类精度. 对于很多定位方法,模型训练需要目标定位的 groundtruth. 一般是采用边界框标注的形式,或者是包含了整个目标的边界框的坐标.

图4 - 包含 logo 目标边界框标注的训练图片例示
2. 基于无边界框标注数据的训练
为了便于对比有边界框标注和无边界框标注的训练效果,首先基于无边界框标注数据训练 baseline 模型.
| Parameter | Value |
|---|---|
| Architecture | ResNet34 |
| Transformations | Fast.ai default transforms |
| Initial Training | Train for four epochs |
| Learning Rate Finder | Unfreeze and lr_find() |
| Continued Training | Train for eight epochs with max_lr = slice(1e-6, 1e-4) |
表 5 - 模型结构和训练参数
得到的 benchmarks 结果如下表6,对比于后面表 10 的结果,大概会有 15-20% 的差距.
| Dataset | Training Samples | Validation Samples | Total Samples | Model Arch. | Accuracy | Annotations |
|---|---|---|---|---|---|---|
| Flick-27 | 864 | 216 | 1080 | ResNet34 | 74% | No |
| Flickr32 | 1941 | 485 | 2426 | ResNet34 | 83% | No |
| Logos32Plus | 6264 | 1566 | 7830 | ResNet34 | 77% | No |
表 6 - benchmark 数据集的模型效果
3. YOLOv3-Darknet 目标检测模型的训练
对于具有边界框标注信息的数据集,这里采用 YOLOv3 目标检测算法和 Darknet 架构[8].
RCNN 系列目标算法,需要将目标检测分为定位和分类两个步骤,必须分别进行模型训练,导致训练速度慢,且难以优化.
YOLO(You Only Look Once) 是一种快速目标检测算法,其只需在一个网络里进行.
3.1. YOLO 输出向量
$$ Y = [p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_3,...,c_n] $$
其中,
$p_c$ - 图片中目标物体的概率
$b_x, b_y$ - 物体检测框的中心点 (x, y) 坐标
$b_h, b_w$ - 物体检测框的 height 和 width
$c_1$ - 预测的边界框内物体所属的最大置信度的类别
$c_2$ - 预测的边界框内物体所属的第二大置信度的类别
$c_3$ - 预测的边界框内物体所属的第三大置信度的类别
$c_n$ - 预测的边界框内物体所属的第 n 大置信度的类别
YOLOv3 的输入图片被划分为 $S \times S$ 个单元格(grid cell). 对于图片中出现的每个物体,每个单元格(单元格的中心落在物体的中心处) 被用于预测物体的位置.
每个单元格预测 $B$ 个边界框和 $C$ 个类别概率值. 每个边界框预测包含 5 个元素:(x, y, w, h, confidence). 其中,(x, y) 坐标表示边界框相对于单元格位置的的中心点位置. 坐标被归一化到 [0, 1] 之间. 根据原始图像尺寸,边界框的高度和宽度 (w, h) 也被归一化到 [0, 1].

图 7 - YOLO 中图像单元格和边界框例示.
置信度(confidence score) 定义为:$Pr(Object) * IOU(pred, truth)$. 其中,IOU( Intersection-Over-Union) 表示预测的边界框与 groundtruth 边界框之间的重叠程度(值越大,重叠度越高,预测的结果越好). 如果单元格内不存在物体,则置信度应该为 0. 否则,置信度值等于 IoU 值.
此外,还有必要每个单元格内预测的类别概率,其定义为 $\frac{Pr(Class[i])}{Pr(Object)}$.
置信度、边界框位置以及类别预测结果一起构成的输出向量,其是 $S \times S \times (B*5 +C)$ 维的 tensor. 其中,$S$ 为在每个轴的单元格数量(上张图片中 $S=3$). $B$ 是对每个单元格所预测的边界框数量. $C$ 是分类器中所预测的物体类别数.
3.2. YOLO 网络
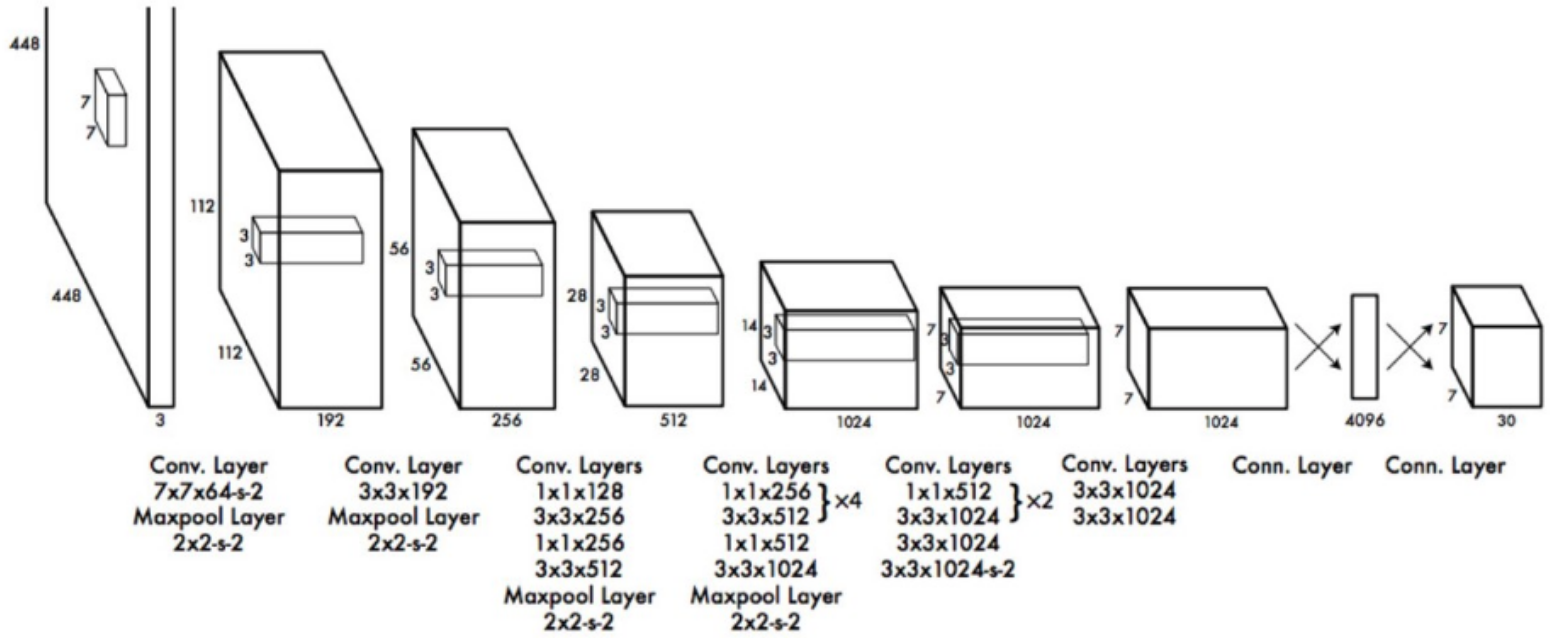
图 8 - Darknet YOLO 结构
YOLO 的网络结构是简单明了的,head 网络包含两个全连接层. 网络的最后输出层会反映输出向量的 tensor 维度.
例如,以这里采用的 Logos32Plus 数据集为例,如果将每张图片划分为 5x5 单元格,每个单元格预测 5 个边界框,则网络的输出向量的维度为:$S \times S \times (B*5 +C) = 5 \times 5 \times (5 \times 5 + 32) = 5 \times 5 \times 57 = 1425$.
3.3. YOLO 损失函数
YOLO 的 loss 函数定义如下:
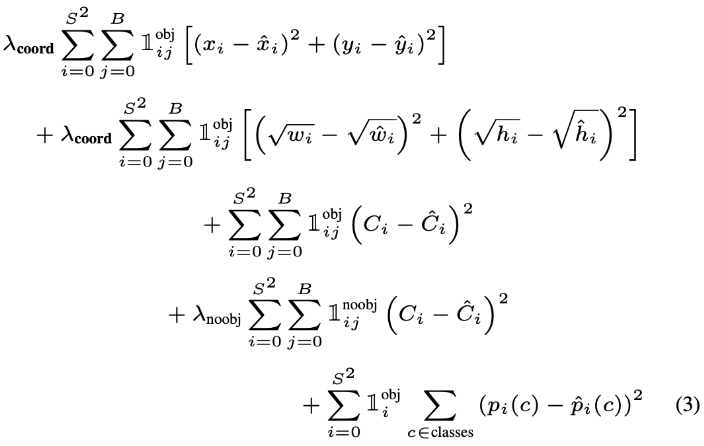
图 9 - YOLO 损失函数
下面分别对损失函数的每一部分分别简单说明.
[1] - 第一部分: X 和 Y

关于预测边界框中心点坐标(x, y) 的损失值.
计算的是每个单元格($i=0, ..., S^2$)的所有预测的边界框($j=0,...,B$)的相加和. 其中,$\mathbf{1}_{ij}^{obj}$ 表示如果单元格 $i$ 中出现物体,且该单元格的第 $j$ 个边界框预测器是关于该物体(responsible),则其值为 1, 否则值为 0.
(x, y) 是预测边界框的中心点坐标.
[2] - 第二部分:Width 和 Height
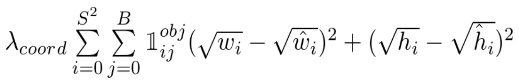
关于预测边界框的 height 和 width 的损失值.
由于较大的边界框的小偏差应该比较小的边界框的小偏差的作用小(small deviations in large boxes should matter less than in small boxes),因此采用了 height 和 width 的开平方,而不是直接采用 height 和width 进行计算.
[3] - 第三部分:Object Confidence
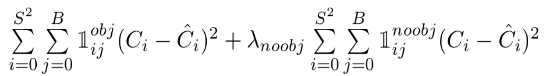
关于每个边界框预测器的置信度(confidence score)的损失值.
$C$ 为置信度值,$\hat{C}$ 是预测边界框和 groundtruth 边界框之间的 IOU 值.
如果在单元格内存在物体,则 $\mathbf{1}_j ^{obj}$ 等于 1,否则其值为 0. 而 $\mathbf{1}_j^{noobj}$ 的定义相反.
[4] - 第四部分:Classification Loss
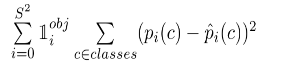
除了 $\mathbf{1}_i^{obj}$ 项,则是标准的平方差.
$\mathbf{1}_i^{obj}$ 项的作用是,如果单元格内不存在物体时,不对分类误差进行惩罚.[13]
$\lambda$ 是权重平衡参数,用于提升模型稳定性.
3.4. YOLOv3 模型训练

图 10 - YOLO 在第 1000,1300 和 9000 次迭代的预测结果
模型训练 160 个 epochs 后(共 1024256 张图片),达到了 91.41% 的测试准确率. 其中,未进行任何数据增强、其它变换操作以及 fast.ai 最佳实践技巧(如 lr_find()).
据作者所知,这是 YOLO-Darknet 目标检测算法第一次用于 Logos32Plus 数据集进行模型训练.
作者最初假设领域特定(domain specific)的训练(不使用预训练的权重)能够改善模型性能,但还是采用 ImageNet 的权重作为 darknet 的训练初始化. 同样的,训练 160 个 epochs,最终得到的验证准确率为 98.12%.
4. Results
| Method | Train Data | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|---|
| BoW SIFT | FL32 | 0.991 | 0.784 | 0.875 | 0.941 |
| BoW SIFT + SP + SynQE | FL32 | 0.994 | 0.826 | 0.902 | N/A |
| Romberg et al. | FL32 | 0.981 | 0.610 | 0.752 | N/A |
| Revaud et al. | FL32 | >0.980 | 0.726 | 0.834 | N/A |
| Romberg et al. | FL32 | 0.999 | 0.832 | 0.908 | N/A |
| Bianco et al. 2015 | FL32 | 0.909 | 0.845 | 0.876 | 0.884 |
| Bianco et al. 2015 + Q.Exp | FL32 | 0.971 | 0.629 | 0.763 | 0.904 |
| Eggert et al. | FL32 | 0.996 | 0.786 | 0.879 | 0.846 |
| Oliveira et al | FL32 | 0.955 | 0.908 | 0.931 | N/A |
| DeepLogo | FL32 | N/A | N/A | N/A | 0.896 |
| Bianco et al. 2017 | FL32 | 0.976 | 0.676 | 0.799 | 0.910 |
| Bianco et al. 2017 | L32+ | 0.989 | 0.906 | 0.946 | 0.958 |
| Our Model | L32+ | 0.9782 | 0.9771 | 0.9776 | 0.9812 |
表 11 - Logo 检测的一些优秀算法结果. FL32: Flickr32; L32+: Logos32Plus datasets. 模型效果与 benchmarks 进行对比.[13, 14, 9, 5, 6, 10, 11, 12]
5. Platform.ai Projections投影
Platform.ai 提供了用于图像数据集类别分布可视化的工具. 这里上传 Logos32Plus 数据集的 10 个子类数据集进行可视化. 在没有边界框标注数据,并训练 ResNet 模型,模型能够清晰的学会根据与 ImageNet 相关的信息,如shapes(bottle, car) 和 color(red, yellow),对 logos 进行区分.
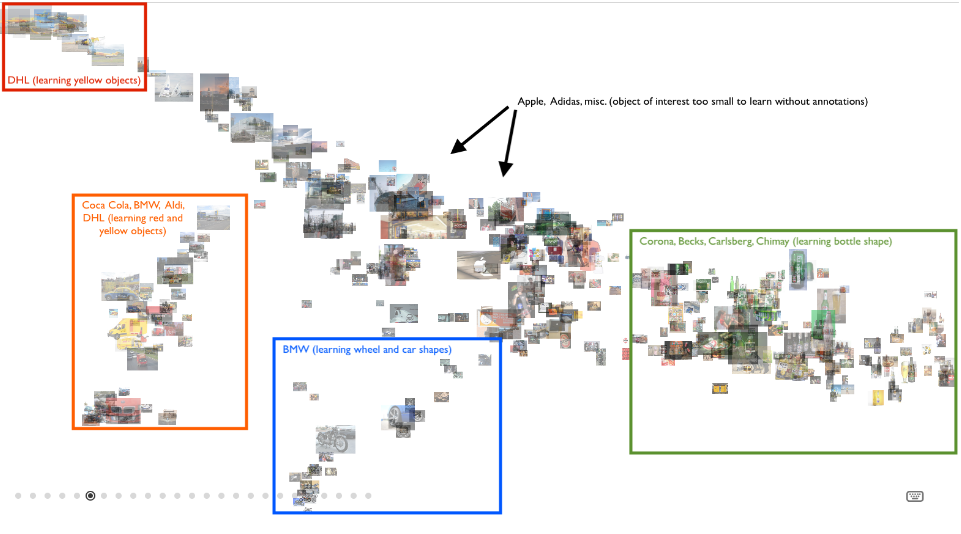
图 12 - platform.ai 的可视化聚类投影
6. 总结
通过对多个 benchmark 数据集(Flickr27, Flickr32 and Logos32Plus),采用 fast.ai 最佳时间技巧训练 ResNet 模型,对比本文采用 YOLO-Darknet 在 Logos32Plus 数据集上训练的模型,验证了前面所说的目标检测有助于提升模型效果,并取得了新的最优 Logos 检测结果.
7. 参考文献
[1] A. D. Bagdanov, L. Ballan, M. Bertini, A. Del Bimbo. “Trademark matching and retrieval in sports video databases.” Proceedings of the international workshop on Workshop on multimedia information retrieval, ACM, 2007. https://www.researchgate.net/publication/210113141_Trademark_matching_and_retrieval_in_sports_video_databases
[2] J. Kleban, X. Xie, W.-Y. Ma. “Spatial pyramid mining for logo detection in natural scenes.” IEEE International Conference, 2008. https://ieeexplore.ieee.org/document/4607625
[3] R. Boia, C. Florea, L. Florea, R. Dogaru. “Logo localization and recognition in natural images using homographic class graphs.” Machine Vision and Applications 27 (2), 2016. https://link.springer.com/article/10.1007/s00138-015-0741-7
[4] R. Boia, C. Florea, L. Florea. “Elliptical asift agglomeration in class prototype for logo detection.” BMVC, 2015. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=5C87F52DE38AB0C90F8340DFEBB841F7?doi=10.1.1.707.9371&rep=rep1&type=pdf
[5] S. Bianco, M. Buzzelli, D. Mazzini, R. Schettini. “Logo recognition using cnn features” Image Analysis and Processing ICIAP, 2015. https://link.springer.com/chapter/10.1007%2F978-3-319-23234-8_41
[6] C. Eggert, A. Winschel, R. Lienhart. “On the benefit of synthetic data for company logo detection.” ACM, 2015. http://www.multimedia-computing.de/mediawiki/images/c/cf/ACMMM2015.pdf
[7] S. Romberg, L. Garcia Pueyo, R. Lienhart, R. van Zwol. “Scalable Logo Recognition in Real-World Images.” ICMR11, 2011. http://www.multimedia-computing.de/flickrlogos/.
[8] Uijlings, Jasper RR, et al. "Selective search for object recognition." International journal of computer vision 104.2 (2013). http://www.huppelen.nl/publications/selectiveSearchDraft.pdf
[9] J. Revaud, M. Douze, C. Schmid. “Correlation-based burstiness for logo retrieval.” ACM, 2012. https://hal.inria.fr/hal-00728502/document
[10] G. Oliveira, X. Frazão, A. Pimentel, B. Ribeiro. “Automatic graphic logo detection via fast region-based convolutional networks.” IEEE, 2016. https://arxiv.org/abs/1604.06083
[11] F. N. Iandola, A. Shen, P. Gao, K. Keutzer. “Deeplogo: Hitting logo recognition with the deep neural network hammer.” 2015. https://arxiv.org/abs/1510.02131
[12] S. Bianco, M. Buzzelli, D. Mazzini, R. Schettini. “Deep Learning for Logo Recognition.” Neurocomputing 245, 2017. http://dx.doi.org/10.1016/j.neucom.2017.03.051
[13] M. Menegaz. “Understanding YOLO.” 2018. https://hackernoon.com/understanding-yolo-f5a74bbc7967
[14] S. Ren, K. He, R.B. Girshick, J. Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” IEEE Transactions on Pattern Analysis and Machine Intelligence, 39, 2015. https://arxiv.org/abs/1506.01497
[15] J. Dai, Y. Li, K. He, J. Sun. “R-FCN: Object Detection via Region-based Fully Convolutional Networks.” NIPS, 2016. https://arxiv.org/abs/1605.06409
[16] T. Lin, P. Goyal, R.B. Girshick, K. He, P. Dollár. “Focal Loss for Dense Object Detection.” IEEE, 2017. https://arxiv.org/abs/1708.02002
[17] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S.E. Reed, C. Fu, A.C. Berg. “SSD: Single Shot MultiBox Detector.” ECCV, 2016. https://arxiv.org/abs/1512.02325
[18] J. Redmon, S.K. Divvala, R.B. Girshick, A. & Farhadi. “You Only Look Once: Unified, Real-Time Object Detection.” IEEE, 2016. https://arxiv.org/abs/1506.02640
[19] J. Howard, et al. “Fast.ai.” 2019. https://github.com/fastai/fastai
[20] Z. Kleinman. “EU backs controversial copyright law.” BBC News, 2019. https://www.bbc.com/news/amp/technology-47708144