题目:Xception: Deep Learning with Depthwise Separable Convolutions - CVPR2017
作者:Franc¸ois Chollet
团队:Google Inc.
将卷积网络中 Inception 模块解释为正则卷积和深度可分离卷积操作间的中间步骤(深度卷积后接逐点卷积)
Present an interpretation of Inception modules in convolutional neural networks as being an intermediate step in-between regular convolution and the depthwise separable convolution operation (a depthwise convolution followed by a pointwise convolution)
深度可分离卷积(depthwise separable convolution)可以理解为具有最大数的 towers 的 Inception 模块.
将 Inception 模块替换为深度可分离卷积.
1. Inception 假设
卷积层尝试在 3D 空间中,根据 2 个空间维度(width 和 height) 和 1 个通道维度(channels),来学习 filters.
因此,单个卷积核是同时学习跨通道关联(cross-channels correations) 和空间关联(spatial correlations).
spatial correlations 学习的是某个特征在空间中的分布;
cross-channel correlations 学习的是这些不同特征的组合方式.
Inception 模块的思想是,采用显式的分解为一系列的操作,其分别在 cross-channel correlations 和 spatial correlations 上进行处理,以更加简单高效的进行卷积核学习.
以经典 Inception 模块为例. 如 Figure 1.

Inception 模块首先采用 1x1 conv 来学习 cross-channel correlations,将输入数据映射到 3 或 4 个比原始输入空间更小的独立空间;
然后,采用正则 3x3 或 5x5 convs 来学习较小的 3D 空间的 spatial correlations.
实际上,Inception 模块的基本假设是,cross-channel correlations 和 spatial correlations 被充分解耦,最好不要同时对二者进行l联合学习.
再比如,Inception 模块的简化版本,如 Figure 2.
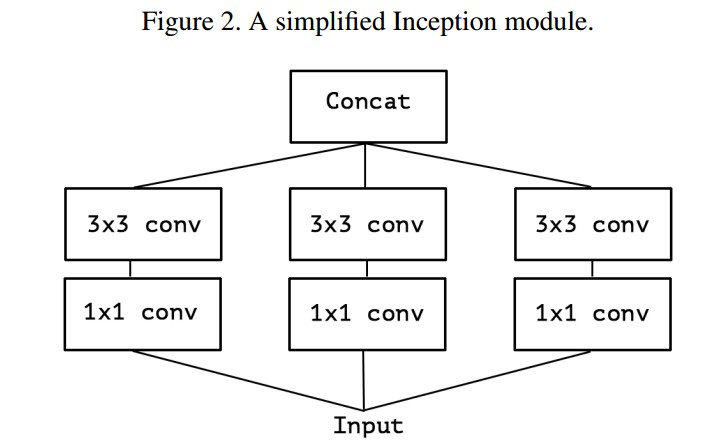
该 Inception 仅仅使用了 1 个尺寸的 conv(如,3x3),且不包括平均池化层.
其可以变换表示为 spatial convolutions 后接 1 个大的 1x1 conv. 该 spatial convolutions 会在输出通道的不同非重叠分割段(nonoverlapping segments)进行学习. 如 Figure 3.
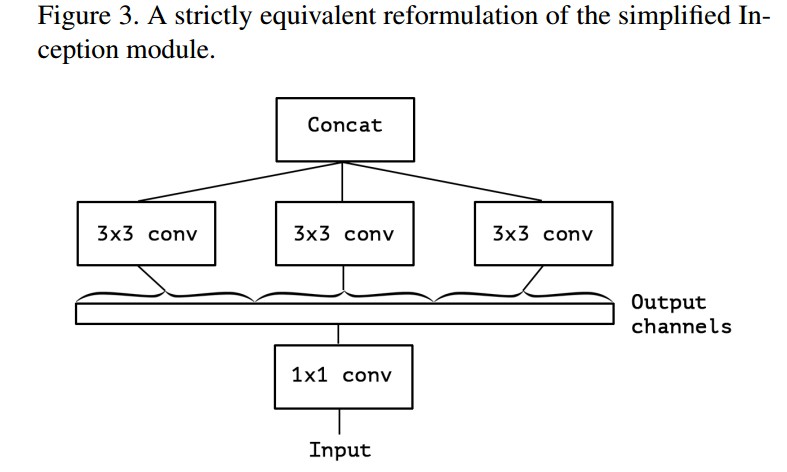
这种变换会引起这样的问题:
- 划分的 segments 的数量(和尺寸) 会有什么影响?
- 更强的假设,如假设 cross-channel correlations 和 spatial correlations 可以完全分开学习,是否比 Inception 假设更合理?
2. Conv 和 Separable Conv 间的连续性
基于上面的更强的假设 - 假设 spatial correlations 的学习与 cross-channel correlations 的学习无关,Inception 模块的极端版本可以是:
首先采用 1x1 conv 学习 cross-channel correlations;
然后分别学习每个输出通道的 spatial correlations.
在每个 channel 上进行 separable convolution,假设 1x1 卷积输出 128 channels 的 feature maps,则 Inception 的极端版本即在每个 channel 上进行 3x3 conv,而不是学习一个 3x3x128 的 kernel,而是学习 128 个 3x3 的kernel.
如,Figure 4.
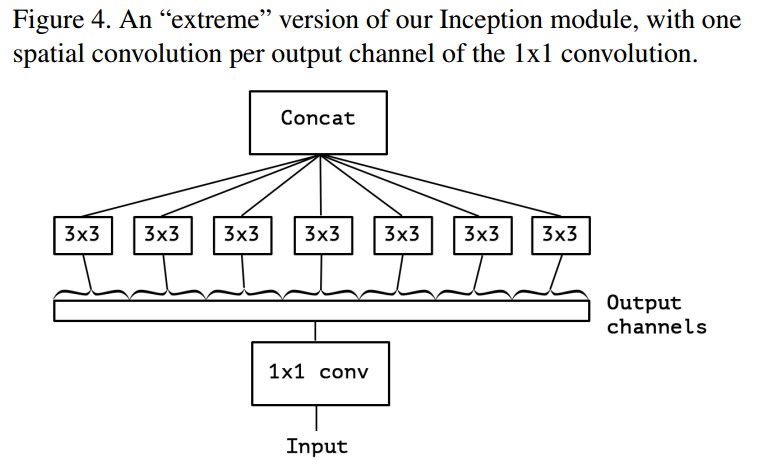
此 Inception 模块的极端形式几乎与深度可分离卷积(depthwise separable convolution) 一致.
深度可分离卷积,在深度框架中,如 TensorFlow 和 Keras,通常被称为可分离卷积(separable convolution),其构成主要为:depthwise conv,如,spatial conv 对输入的每个通道分别学习;然后接 pointwise conv,如 1x1 conv,根据 depthwise conv 将通道输出投影到新的通道空间.
该 depthwise separable conv 与图像处理社区中的 separable conv 是不能混淆的,后者是空间独立卷积.
Inception 模块的极端版本与 depthwise separable conv 的两个微小差别:
- [1] - 操作的顺序:depthwise separable convolutions 通常是先进行 channel-wise spatial conv,然后再是 1x1 conv(如 TensorFlow 中的实现);Inception 则是先进行 1x1 conv.
- [2] - 在第一个操作后是否存在非线性层:Inception 中,1x1 conv 和 channel-wise spatial conv 操作后均有 ReLU 非线性层;但,depthwise separable convolutions 通常不包括非线性层.
采用 depthwise separable convolutions 代替 Inception 模块,如堆积 depthwise separable convolutions 来构建网络模型.
3. Xception 结构
主要相关:
- Convolution Neural Networks
- Inception 结构
- Depthwise separable convolutions
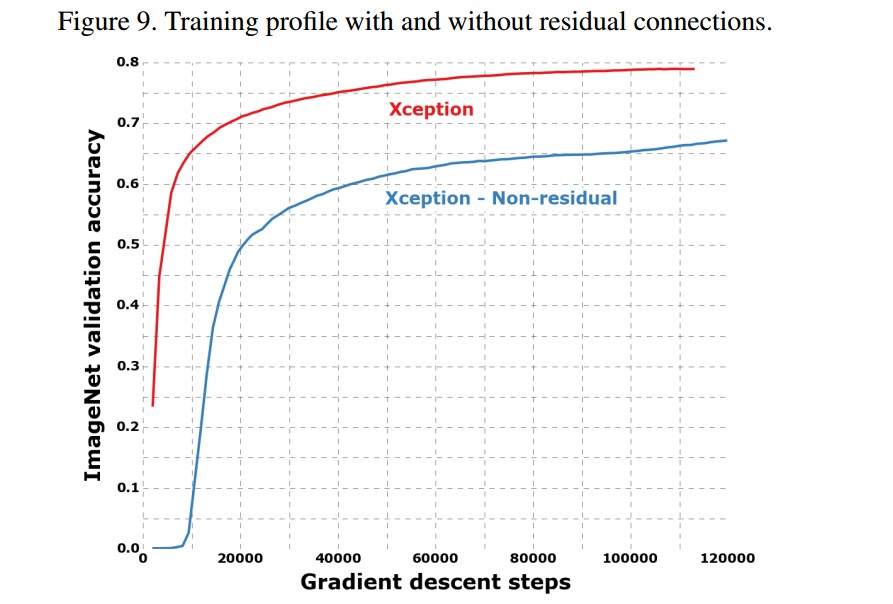
- Residual connections 残差链接
Xception,即 Extreme Inception,其完全基于 depthwise separable convolution layers 来构建,其主要基于假设:CNN 网络中特征图的 cross-channels correlations 和 spatial correlations 可以完全解耦(decoupled).
如 Figure 5.
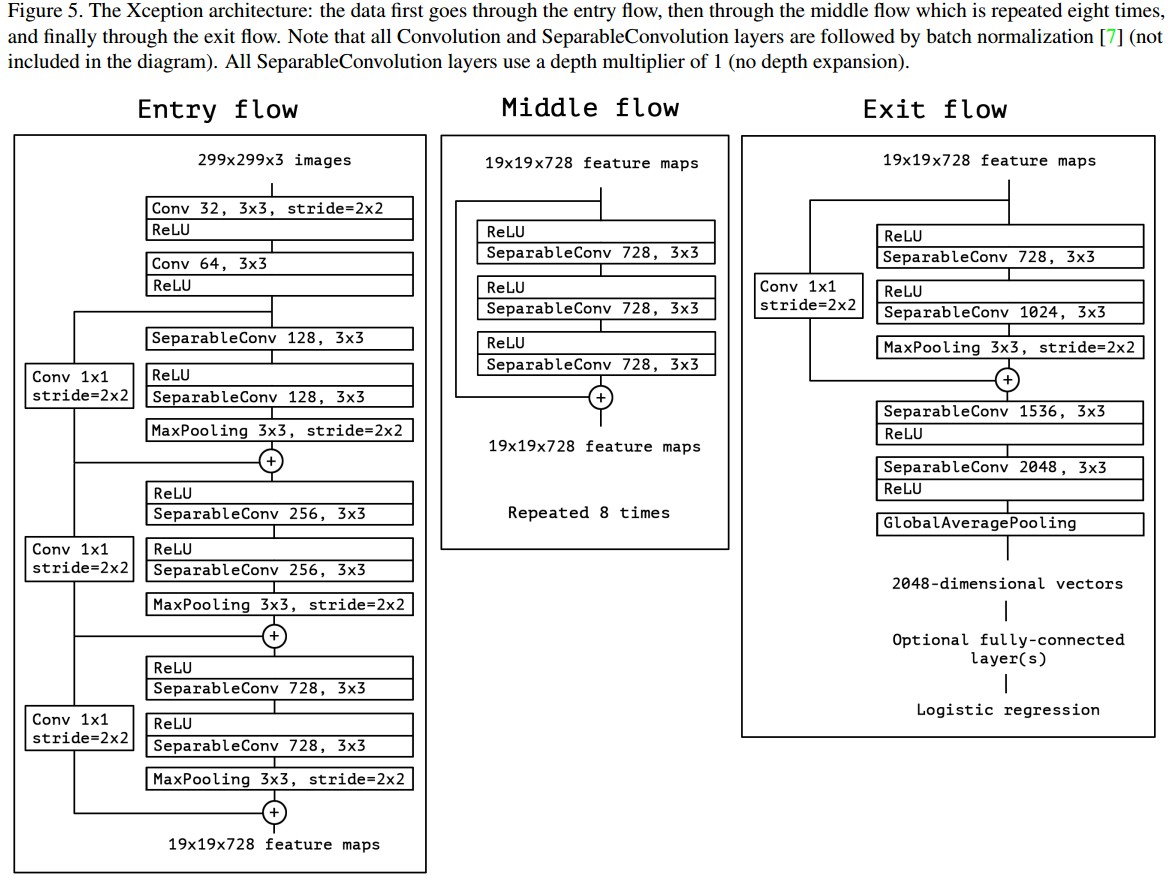
Xception 包括 36 个卷积层,用于特征提取;36 个卷积层被结构化为 14 个模块,每个结构化模块都有线性残差链接,除了第一个和最后一个模块.
简单来说,Xception 结构是包含残差链接的 depthwise separable convolution layers 的线性堆积. 非常易于定义和修改,在 Keras 和 TensorFlow-Slim 中只需要 30-40 行代码.
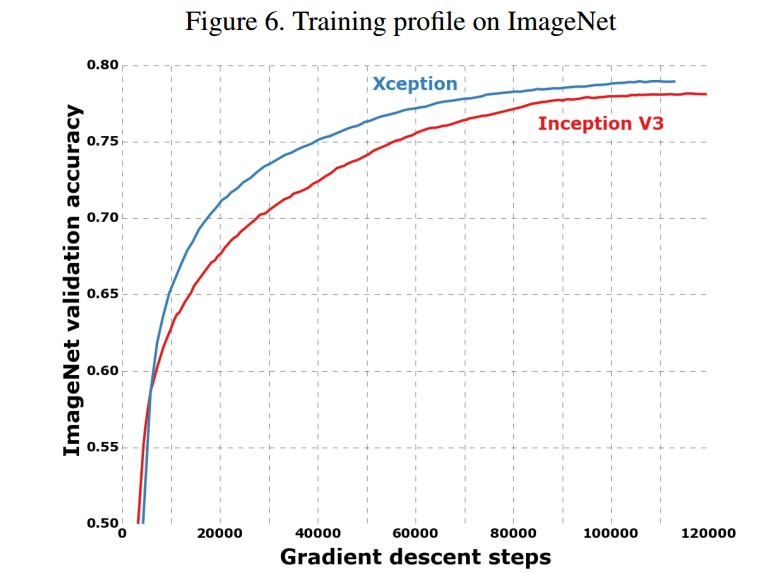
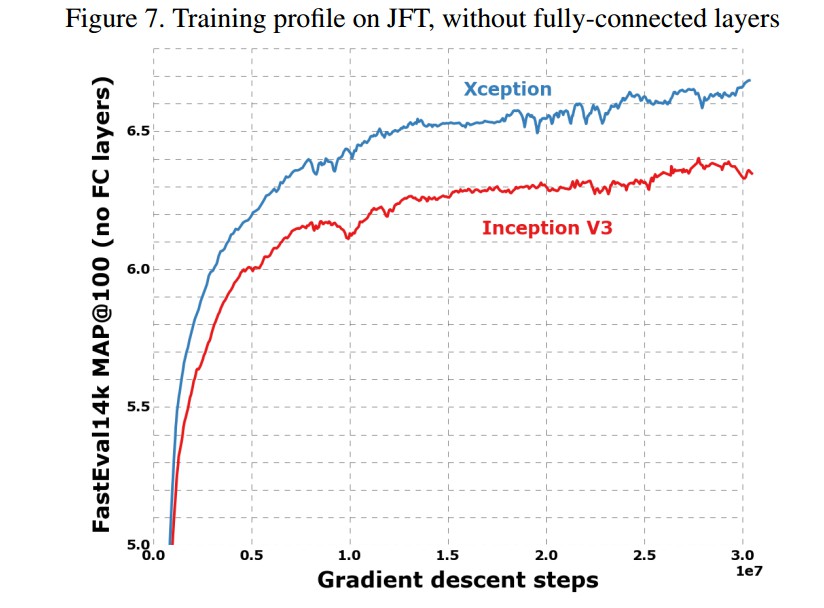
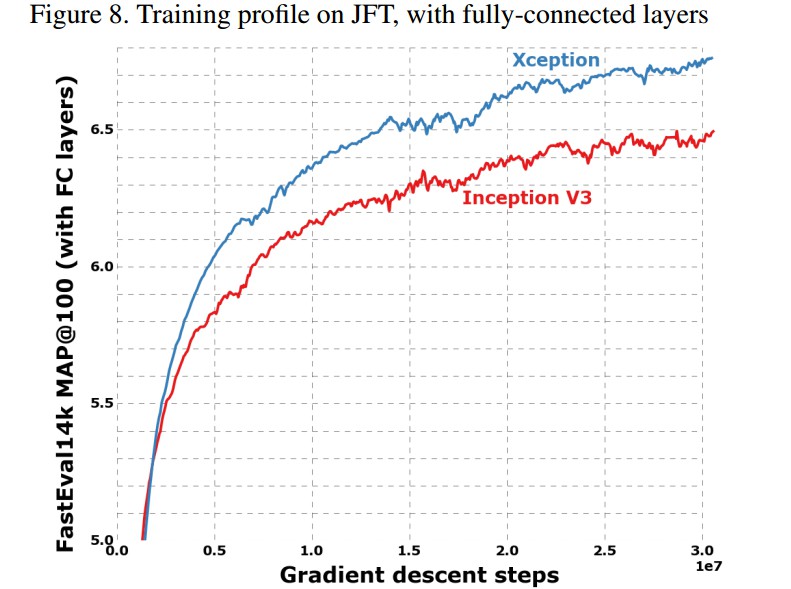
4. Experiments
- JFT dataset - 谷歌的大规模图片分类数据库,350 million 高分辨率图片,17000 个类别.
- ImageNet dataset


Related
[1] - 关于「Xception」和「DeepLab V3+」的那些事
[2] - CVPR 2017精彩论文解读:对Xception(一种深度可分离卷积)的介绍