转自 TensorFlow 中文社区
TensorFlow程序读取数据一共有3种方法:
- 供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据.
- 从文件读取数据: 在TensorFlow图的起始, 让一个输入管线从文件中读取数据.
- 预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况).
1. 供给数据(Feeding)
TensorFlow 的数据供给机制允许在 TensorFlow 运算图中将数据注入到任一张量中.
因此,python 运算可以把数据直接设置到TensorFlow图中.
通过给 run() 或者 eval() 函数输入feed_dict参数, 可以启动运算过程.
with tf.Session():
input = tf.placeholder(tf.float32)
classifier = ...
print classifier.eval(feed_dict={input: my_python_preprocessing_fn()})
虽然可以使用常量和变量来替换任何一个张量, 但是最好的做法应该是使用placeholder op 节点node.
设计 placeholder 节点的唯一的意图就是为了提供数据供给(feeding)的方法.
placeholder 节点被声明的时候是未初始化的,也不包含数据.
如果没有为它供给数据, 则 TensorFlow运算的时候会产生错误, 所以千万不要忘了为 placeholder 提供数据.
如 tensorflow/examples/tutorials/mnist/fully_connected_feed.py中关于 placeholder的使用:
def placeholder_inputs(batch_size):
"""
生成表示输入 tensors 的 placeholder 变量.
These placeholders are used as inputs by the rest of the model building
code and will be fed from the downloaded data in the .run() loop, below.
Args:
batch_size: The batch size will be baked into both placeholders.
Returns:
images_placeholder: Images placeholder.
labels_placeholder: Labels placeholder.
"""
# Note that the shapes of the placeholders match the shapes of the full
# image and label tensors, except the first dimension is now batch_size
# rather than the full size of the train or test data sets.
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size, mnist.IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))
return images_placeholder, labels_placeholder
训练时的调用:
def fill_feed_dict(data_set, images_pl, labels_pl):
"""
Fills the feed_dict for training the given step.
A feed_dict takes the form of:
feed_dict = {
<placeholder>: <tensor of values to be passed for placeholder>,
....
}
Args:
data_set: The set of images and labels, from input_data.read_data_sets()
images_pl: The images placeholder, from placeholder_inputs().
labels_pl: The labels placeholder, from placeholder_inputs().
Returns:
feed_dict: The feed dictionary mapping from placeholders to values.
"""
# Create the feed_dict for the placeholders filled with the next
# `batch size` examples.
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size, FLAGS.fake_data)
feed_dict = {images_pl: images_feed, labels_pl: labels_feed, }
return feed_dict
def run_training():
"""
Train MNIST for a number of steps.
"""
# MNIST 的 training, validation, test 数据集读取.
data_sets = input_data.read_data_sets(FLAGS.input_data_dir, FLAGS.fake_data)
# Tell TensorFlow that the model will be built into the default Graph.
with tf.Graph().as_default():
# 生成图片和标签的 placeholders.
images_placeholder, labels_placeholder = placeholder_inputs(FLAGS.batch_size)
# 构建 Graph,用于计算推断模型的预测结果.
logits = mnist.inference(images_placeholder,FLAGS.hidden1,FLAGS.hidden2)
# 添加 loss 计算 Ops 到 Graph
loss = mnist.loss(logits, labels_placeholder)
# 添加梯度计算 Ops 到 Graph.
train_op = mnist.training(loss, FLAGS.learning_rate)
# 添加计算 logits 和 labels 对比计算的 Op.
eval_correct = mnist.evaluation(logits, labels_placeholder)
# 基于Summaries的TF集合构建 summary Tensor.
summary = tf.summary.merge_all()
# 添加变量初始化 Op.
init = tf.global_variables_initializer()
# 创建训练断点保存的 saver.
saver = tf.train.Saver()
# 创建在Graph上运行 Ops 的会话 session.
sess = tf.Session()
# 初始化 SummaryWriter 以输出 summaries 和 Graph.
summary_writer = tf.summary.FileWriter(FLAGS.log_dir, sess.graph)
# 构建完成后:
# 运行 Op 以初始化变量.
sess.run(init)
# 开始训练 loop.
for step in xrange(FLAGS.max_steps):
start_time = time.time()
# 将当前训练的真实图片和标签数据填充到 feed dict.
feed_dict = fill_feed_dict(data_sets.train, images_placeholder, labels_placeholder)
# 运行一次模型训练
# 返回 `train_op` (which is discarded) 和 `loss` Op 的激活值.
_, loss_value = sess.run([train_op, loss], feed_dict=feed_dict)
duration = time.time() - start_time
# Write the summaries and print an overview fairly often.
if step % 100 == 0:
# Print status to stdout.
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration))
# Update the events file.
summary_str = sess.run(summary, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, step)
summary_writer.flush()
# 保存断点,测试模型
if (step + 1) % 1000 == 0 or (step + 1) == FLAGS.max_steps:
checkpoint_file = os.path.join(FLAGS.log_dir, 'model.ckpt')
saver.save(sess, checkpoint_file, global_step=step)
# Evaluate against the training set.
print('Training Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.train)
# Evaluate against the validation set.
print('Validation Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation)
# Evaluate against the test set.
print('Test Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.test)
MNIST训练的例子 - [MNIST tutorial 中也有 placeholder 的相关使用.2. 从文件读取数据
一种典型的文件读取管线会包含下面这些步骤:
- 文件名列表
- 可配置的 文件名乱序(shuffling)
- 可配置的 最大训练迭代数(epoch limit)
- 文件名队列
- 针对输入文件格式的阅读器
- 纪录解析器
- 可配置的预处理器
- 样本队列
2.1 文件名列表, 乱序(shuffling), 最大训练迭代数(epoch limits)
可以使用字符串张量(比如["file0", "file1"], [("file%d" % i) for i in range(2)], [("file%d" % i) for i in range(2)]) 或者tf.train.match_filenames_once 函数来产生文件名列表.
将文件名列表交给tf.train.string_input_producer 函数.string_input_producer来生成一个先入先出的队列, 文件阅读器会需要它来读取数据.
string_input_producer 的配置参数,可以设置文件名乱序和最大的训练迭代数.
QueueRunner 会为每次迭代(epoch)将所有的文件名加入文件名队列中, 如果 shuffle=True , 则对文件名进行乱序. 这一过程是比较均匀的,因此它可以产生均衡的文件名队列.
这个 QueueRunner 的工作线程是独立于文件阅读器Reader 的线程, 因此乱序和将文件名推入到文件名队列这些过程不会阻塞文件阅读器运行.
2.2 文件格式
根据文件格式, 选择对应的文件阅读器, 然后将文件名队列提供给阅读器的 read 方法。
阅读器的 read 方法会输出一个 key 来表征输入的文件和其中的纪录(对于调试非常有用),同时得到一个字符串标量, 这个字符串标量可以被一个或多个解析器,或者转换操作将其解码为张量并且构造成为样本.
2.2.1 CSV 文件
从CSV文件中读取数据, 需要使用TextLineReader和decode_csv 操作, 如下面的例子所示:
filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"])
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 默认值,以避免空列. 同时指定编码结果的类型.
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(value, record_defaults=record_defaults)
features = tf.concat(0, [col1, col2, col3, col4])
with tf.Session() as sess:
# Start populating the filename queue.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(1200):
# Retrieve a single instance:
example, label = sess.run([features, col5])
coord.request_stop()
coord.join(threads)
每次read 的执行都会从文件中读取一行内容, decode_csv 操作会解析这一行内容并将其转为张量列表.
如果输入的参数有缺失,record_default 参数可以根据张量的类型来设置默认值.
在调用run或者eval去执行read之前, 必须调用tf.train.start_queue_runners来将文件名填充到队列. 否则read操作会被阻塞到文件名队列中有值为止.
2.2.2 固定长度的记录
从二进制文件中读取固定长度纪录, 可以使用tf.FixedLengthRecordReader的tf.decode_raw操作.
decode_raw操作可以讲一个字符串转换为一个uint8的张量.
举例来说,the CIFAR-10 dataset的文件格式定义是:每条记录的长度都是固定的,一个字节的标签,后面是3072字节的图像数据.
uint8的张量的标准操作就可以从中获取图像片并且根据需要进行重组.
例子代码可以在tensorflow/models/image/cifar10/cifar10_input.py找到,具体讲述可参见教程.
def read_cifar10(filename_queue):
"""
从 CIFAR10 数据文件,读取并解析样本.
Recommendation: if you want N-way read parallelism, call this function
N times. This will give you N independent Readers reading different
files & positions within those files, which will give better mixing of
examples.
Args:
filename_queue: A queue of strings with the filenames to read from.
Returns:
An object representing a single example, with the following fields:
height: number of rows in the result (32)
width: number of columns in the result (32)
depth: number of color channels in the result (3)
key: a scalar string Tensor describing the filename & record number
for this example.
label: an int32 Tensor with the label in the range 0..9.
uint8image: a [height, width, depth] uint8 Tensor with the image data
"""
class CIFAR10Record(object):
pass
result = CIFAR10Record()
# Dimensions of the images in the CIFAR-10 dataset.
# See http://www.cs.toronto.edu/~kriz/cifar.html for a description of the input format.
label_bytes = 1 # 2 for CIFAR-100
result.height = 32
result.width = 32
result.depth = 3
image_bytes = result.height * result.width * result.depth
# 每个记录由 label + image 组成,每个都是固定数目的字节.
record_bytes = label_bytes + image_bytes
# 读取一个记录,从 filename_queue 读取文件名.
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
result.key, value = reader.read(filename_queue)
# 从字符串转换为 uint8 向量,record_bytes long.
record_bytes = tf.decode_raw(value, tf.uint8)
# 第一个字节表示 label,由 uint8->int32.
result.label = tf.cast(tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32)
# 第一个字节后的剩余字节表示 image,
# reshape from [depth * height * width] to [depth, height, width].
depth_major = tf.reshape(
tf.strided_slice(record_bytes, [label_bytes],
[label_bytes + image_bytes]),
[result.depth, result.height, result.width])
# Convert from [depth, height, width] to [height, width, depth].
result.uint8image = tf.transpose(depth_major, [1, 2, 0])
return result
2.2.3 标准TensorFlow格式
TensorFlow 允许将任意数据转换为 TFRecords文件.
TFRecords 文件数据格式是 tf.train.Example protocol buffer,如:
message Example {
Features features = 1;
};
message SequenceExample {
Features context = 1;
FeatureLists feature_lists = 2;
};
生成 TFRecords 的过程是,获取数据,将数据写入 Example protocol buffer,序列化为字符串,再通过tf.python_io.TFRecordWriter class写入到TFRecords文件.
如:tensorflow/g3doc/how_tos/reading_data/convert_to_records.py
"""
将 MNIST 数据转换为Example protos 的 TFRecords 文件格式.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os
import sys
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets import mnist
FLAGS = None
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def convert_to(data_set, name):
"""
转化数据集为 tfrecords.
"""
images = data_set.images
labels = data_set.labels
num_examples = data_set.num_examples
if images.shape[0] != num_examples:
raise ValueError('Images size %d does not match label size %d.' %
(images.shape[0], num_examples))
rows = images.shape[1]
cols = images.shape[2]
depth = images.shape[3]
filename = os.path.join(FLAGS.directory, name + '.tfrecords')
print('Writing', filename)
with tf.python_io.TFRecordWriter(filename) as writer:
for index in range(num_examples):
image_raw = images[index].tostring()
example = tf.train.Example(
features=tf.train.Features(
feature={
'height': _int64_feature(rows),
'width': _int64_feature(cols),
'depth': _int64_feature(depth),
'label': _int64_feature(int(labels[index])),
'image_raw': _bytes_feature(image_raw)
}))
writer.write(example.SerializeToString())
def main(unused_argv):
# 读取数据.
data_sets = mnist.read_data_sets(FLAGS.directory,
dtype=tf.uint8,
reshape=False,
validation_size=FLAGS.validation_size)
# 转化为 Examples,并写入 TFRecords.
convert_to(data_sets.train, 'train')
convert_to(data_sets.validation, 'validation')
convert_to(data_sets.test, 'test')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--directory',
type=str,
default='/tmp/data',
help='Directory to download data files and write the converted result'
)
parser.add_argument(
'--validation_size',
type=int,
default=5000,
help="""\
Number of examples to separate from the training data for the validation
set.\
"""
)
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
从TFRecords文件中读取数据, 可以使用tf.TFRecordReader 的 tf.parse_single_example解析器.
parse_single_example 操作可以将 Example protocol buffer 解析为张量. 如tensorflow/g3doc/how_tos/reading_data/fully_connected_reader.py 中:
def decode(serialized_example):
"""
从给定的 serialized_example 解析图片和标签.
"""
features = tf.parse_single_example(
serialized_example,
# Defaults are not specified since both keys are required.
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64),
})
# image 从标量字符串张量(单个字符串长度为mnist.IMAGE_PIXELS)转化为 uint8 张量(shape [mnist.IMAGE_PIXELS].
image = tf.decode_raw(features['image_raw'], tf.uint8)
image.set_shape((mnist.IMAGE_PIXELS))
# label 从标量 uint8 张量转化为 int32 标量.
label = tf.cast(features['label'], tf.int32)
return image, label
2.3 图片预处理
如cifar10_input.py:
def distorted_inputs(data_dir, batch_size):
"""
Construct distorted input for CIFAR training using the Reader ops.
Args:
data_dir: Path to the CIFAR-10 data directory.
batch_size: Number of images per batch.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
filenames = [os.path.join(data_dir, 'data_batch_%d.bin' % i) for i in xrange(1, 6)]
for f in filenames:
if not tf.gfile.Exists(f):
raise ValueError('Failed to find file: ' + f)
# 创建队列,输出读取的 filenames.
filename_queue = tf.train.string_input_producer(filenames)
# 从 filename队列中的文件读取样本.
read_input = read_cifar10(filename_queue)
reshaped_image = tf.cast(read_input.uint8image, tf.float32)
height = IMAGE_SIZE
width = IMAGE_SIZE
# 图片增强
# random distortions applied to the image.
# 随机裁剪 [height, width].
distorted_image = tf.random_crop(reshaped_image, [height, width, 3])
# 随机水平翻转.
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 操作步骤是不可互换的,可以考虑随机打乱操作顺序.
distorted_image = tf.image.random_brightness(distorted_image, max_delta=63)
distorted_image = tf.image.random_contrast(
distorted_image, lower=0.2, upper=1.8)
# 去均值,除以像素方差.
float_image = tf.image.per_image_standardization(distorted_image)
# 设置张量 shapes.
float_image.set_shape([height, width, 3])
read_input.label.set_shape([1])
# 确保随机打乱具有更好的混合.
min_fraction_of_examples_in_queue = 0.4
min_queue_examples = int(NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN * min_fraction_of_examples_in_queue)
print('Filling queue with %d CIFAR images before starting to train. '
'This will take a few minutes.' % min_queue_examples)
# 通过构建样本队列,构建 images 和 labels 的batch 数据.
return _generate_image_and_label_batch(
float_image,
read_input.label,
min_queue_examples,
batch_size,
shuffle=True)
def _generate_image_and_label_batch(image, label, min_queue_examples,
batch_size, shuffle):
"""
构建 images 和 labels 的队列化batch.
Args:
image: 3-D Tensor of [height, width, 3] of type.float32.
label: 1-D Tensor of type.int32
min_queue_examples: int32, minimum number of samples to retain
in the queue that provides of batches of examples.
batch_size: Number of images per batch.
shuffle: boolean indicating whether to use a shuffling queue.
Returns:
images: Images. 4D tensor of [batch_size, height, width, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
# 创建队列,打乱样本顺序;
# 然后,从样本队列读取 'batch_size' 个 images + labels.
num_preprocess_threads = 16
if shuffle:
images, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size,
min_after_dequeue=min_queue_examples)
else:
images, label_batch = tf.train.batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size)
# 可视化训练图片.
tf.summary.image('images', images)
return images, tf.reshape(label_batch, [batch_size])
2.4 批处理 Batch
在数据输入管线的末端, 需要采用另一个队列来执行输入样本的训练,评价和推断.
采用 tf.train.shuffle_batch 函数对队列中的样本进行乱序处理.
如:
def read_my_file_format(filename_queue):
reader = tf.SomeReader() # 某种数据读取器
key, record_string = reader.read(filename_queue)
example, label = tf.some_decoder(record_string) # 字符串编码方式
processed_example = some_processing(example) # 数据处理
return processed_example, label
def input_pipeline(filenames, batch_size, num_epochs=None):
filename_queue = tf.train.string_input_producer(filenames, num_epochs=num_epochs, shuffle=True)
example, label = read_my_file_format(filename_queue)
# min_after_dequeue 定义了随机采样的缓存区buffer 的大小,该值越大,则打乱效果越好,但开始时比较慢,且需要内存更多.
# 容量capacity 必须大于 min_after_dequeue, 大于的量决定了预取prefetch 的最大值.
# 推荐值:min_after_dequeue + (num_threads + a small safety margin) * batch_size
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch(
[example, label], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
如果需要对不同文件中的样本进行更强的乱序和并行处理,可以采用 tf.train.shuffle_batch_join 函数.
如:
def read_my_file_format(filename_queue):
# 同上
def input_pipeline(filenames, batch_size, read_threads, num_epochs=None):
filename_queue = tf.train.string_input_producer(filenames, num_epochs=num_epochs, shuffle=True)
example_list = [read_my_file_format(filename_queue) for _ in range(read_threads)]
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch_join(example_list, batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
这里虽然只采用了一个文件名队列 filename_queue,但 TensorFlow 仍然可以保证多个文件阅读器readers 从同一次迭代(epoch) 的不同文件中读取数据,直到所有文件都被读取为止.(一般来说,一个线程对文件名队列进行填充的效率是足够的.)
另一种替代方案是: 使用 tf.train.shuffle_batch 函数, 设置num_threads的值大于1.
这种方案可以保证同一时刻只在一个文件中进行读取操作(但是读取速度依然优于单线程),而不是之前的同时读取多个文件.
这种方案的优点是:
- 避免了两个不同的线程从同一个文件中读取同一个样本.
- 避免了过多的磁盘搜索操作.
一共需要多少个读取线程呢? 函数 tf.train.shuffle_batch* 为 TensorFlow 图提供了获取文件名队列中的元素个数之和的方法.
如果有足够多的读取线程, 文件名队列中的元素个数之和应该一直是一个略高于 0 的数. 具体可以参考TensorBoard:可视化学习.
2.5 创建线程并使用QueueRunner对象来预取
简单来说:如上面,tf.train 函数添加 QueueRunner 到数据流图中.
在运行任何训练步骤之前,需要调用 tf.train.start_queue_runners 函数,否则数据流图将一直挂起.
tf.train.start_queue_runners 函数将会启动输入管道的线程,填充样本到队列中,以便出队操作可以从队列中拿到样本.
这种情况下最好配合使用一个 tf.train.Coordinator,这样可以在发生错误的情况下正确地关闭这些线程.
如果对训练迭代数做了限制,那么需要使用一个训练迭代数计数器,并且需要被初始化.
推荐的代码模板如下:
# 创建图,等.
init_op = tf.initialize_all_variables()
# 创建会话session, 以在 Graph 中运行计算.
sess = tf.Session()
# 初始化变量 (like the epoch counter).
sess.run(init_op)
# 开始输入队列线程 input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
while not coord.should_stop():
# 运行训练
sess.run(train_op)
except tf.errors.OutOfRangeError:
print 'Done training -- epoch limit reached'
finally:
# 结束后,停止线程threads.
coord.request_stop()
#等待线程结束(threads to finish).
coord.join(threads)
sess.close()
2.6 数据读取原理
首先,首先创建数据流图:数据流图由一些流水线的阶段组成,阶段间用队列连接在一起.
第一阶段生成文件名,读取这些文件名并送入到文件名队列中.
第二阶段从文件中读取数据(使用Reader),产生样本,并把样本放入一个样本队列中.
根据设置,实际上也可以拷贝第二阶段的样本,使得它们相互独立,这样就可以从多个文件中并行读取.
第二阶段的最后是一个排队操作,即入队到队列中去,在下一阶段出队.
因为我们是要开始运行这些入队操作的线程,所以训练循环会使得样本队列中的样本不断地出队.
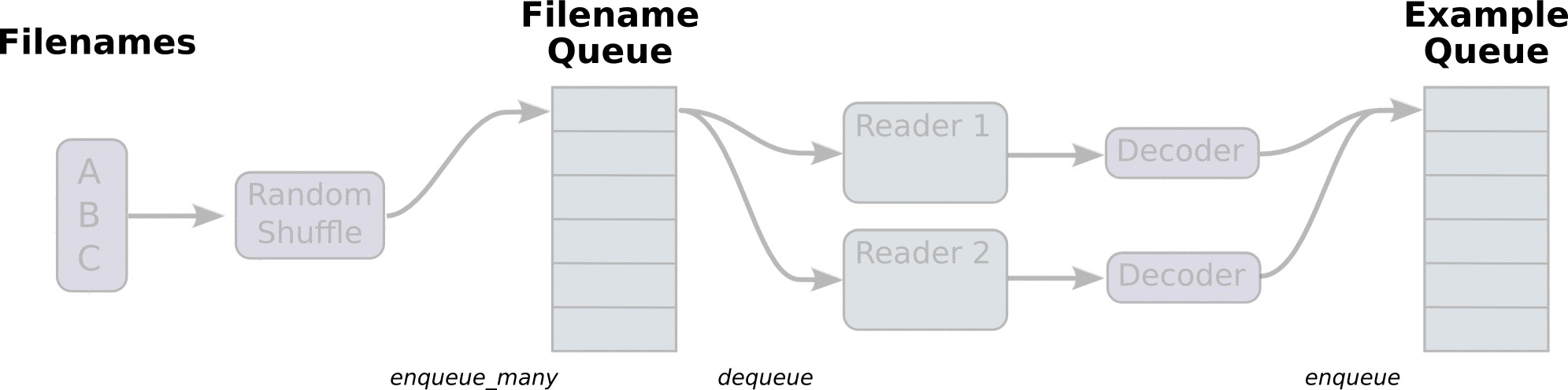
在 tf.train 中要创建这些队列和执行入队操作,需要添加 tf.train.QueueRunner 到一个使用 tf.train.add_queue_runner 函数的数据流图中.
每个 QueueRunner 负责一个阶段,处理那些需要在线程中运行的入队操作的列表.
一旦数据流图构造成功,tf.train.start_queue_runners 函数就会要求数据流图中每个 QueueRunner 去开始它的线程运行入队操作.
如果一切顺利的话,即可执行训练步骤,同时队列也会被后台线程来填充.
如果设置了最大训练迭代数,在某些时候,样本出队的操作可能会得到一个 tf.OutOfRangeError 的错误。 这其实是 TensorFlow 的“文件结束”(EOF) - 意味着已经达到了最大训练迭代数,已经没有更多可用的样本.
最后一个因素是 Coordinator. 负责在收到任何关闭信号时,让所有的线程都知道. 最常用的是,在发生异常时这种情况就会呈现出来,比如说其中一个线程在运行某些操作时出现错误(或一个普通的Python异常).
关于threading, queues, QueueRunners, and Coordinators的内容可以 threading_and_queues.
2.7 在达到最大训练迭代数时清理关闭线程?
如果有一个模型且设置了最大训练迭代数,则意味着,生成文件的那个线程将只会在产生 OutOfRange 错误之前运行许多次. 该 QueueRunner 会捕获该错误,并且关闭文件名的队列,最后退出线程.
关闭队列做了两件事情:
- 如果还试着对文件名队列执行入队操作时将发生错误.
任何线程不应该尝试去这样做,但是当队列因为其他错误而关闭时,这就会有用了. 任何当前或将来出队操作,有两种状态:成功(如果队列中还有足够的元素) 或立即失败(发生
OutOfRange错误). 它们不会防止等待更多的元素被添加到队列中,因为上面的一点已经保证了这种情况不会发生.
关键是,当在文件名队列被关闭时候,有可能还有许多文件名在该队列中,这样下一阶段的流水线(包括 reader 和其它预处理) 还可以继续运行一段时间.
一旦文件名队列空了之后,如果后面的流水线还要尝试从文件名队列中取出一个文件名(例如,从一个已经处理完文件的reader中),这将会触发 OutOfRange 错误.
此情况下,即使可能有一个 QueueRunner 关联着多个线程. 如果这不是在 QueueRunner 中的最后那个线程,OutOfRange 错误仅仅只会使得一个线程退出. 这使得其他正处理自己的最后一个文件的线程继续运行,直至他们完成为止. (但如果假设使用的是tf.train.Coordinator,其他类型的错误将导致所有线程停止).
一旦所有的reader线程触发 OutOfRange 错误,然后才是下一个队列,再是样本队列被关闭.
同样,样本队列中会有一些已经入队的元素,所以样本训练将一直持续直到样本队列中再没有样本为止. 如果样本队列是一个 RandomShuffleQueue,由于使用了shuffle_batch 或者 shuffle_batch_join,所以通常不会出现以往那种队列中的元素会比 min_after_dequeue 定义的更少的情况.
然而,一旦该队列被关闭,min_after_dequeue 设置的限定值将失效,最终队列将为空. 从这一点来说,当实际训练线程尝试从样本队列中取出数据时,将会触发 OutOfRange 错误,然后训练线程会退出. 一旦所有的线程完成,tf.train.Coordinator.join 会返回,就可以正常退出.
2.8 筛选记录或产生每个记录的多个样本
例如,有样本为
[x, y, z],可以生成一批形式为[batch, x, y, z]的样本。如果想滤除这个记录(或许不需要这样的设置),那么可以设置batch的大小为0;
但如果需要每个记录产生多个样本,那么batch的值可以大于1.
然后很简单,只需调用批处理函数(比如:
shuffle_batch or shuffle_batch_join)去设置 enqueue_many=True 就可以实现.2.9 稀疏输入数据
SparseTensors 数据类型使用队列来处理不是太好。
如果要使用 SparseTensors,必须在批处理之后使用
tf.parse_example 去解析字符串记录(而不是在批处理之前使用 tf.parse_single_example ).3. 预取数据
仅用于可以完全加载到内存等存储中的小数据集.
有两种方法:
存储在变量中,初始化后,永远不要改变它的值.
使用常数更简单一些,但是会使用更多的内存(因为常数会内联的存储在数据流图数据结构中,这个结构体可能会被复制几次).
training_data = ...
training_labels = ...
with tf.Session():
input_data = tf.constant(training_data)
input_labels = tf.constant(training_labels)
...
要改为使用变量的方式,需要在数据流图建立后初始化这个变量.
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,
shape=training_data.shape)
label_initializer = tf.placeholder(dtype=training_labels.dtype,
shape=training_labels.shape)
input_data = tf.Variable(data_initalizer, trainable=False, collections=[])
input_labels = tf.Variable(label_initalizer, trainable=False, collections=[])
...
sess.run(input_data.initializer,
feed_dict={data_initializer: training_data})
sess.run(input_labels.initializer,
feed_dict={label_initializer: training_lables})
设定 trainable=False 可以防止该变量被数据流图的 GraphKeys.TRAINABLE_VARIABLES 收集, 这样不会在训练的时候尝试更新它的值;
设定 collections=[] 可以防止 GraphKeys.VARIABLES 收集后作为保存和恢复的中断点.
无论哪种方式,tf.train.slice_input_producer function 函数可以被用来每次产生一个切片.
这样就会让样本在整个迭代中被打乱,所以在使用批处理的时候不需要再次打乱样本. 不必使用 shuffle_batch 函数,而是使用纯 tf.train.batch 函数.
如果要使用多个线程进行预处理,需要将num_threads参数设置为大于1.
在 tensorflow/g3doc/how_tos/reading_data/fully_connected_preloaded.py 中 MNIST例子,使用常数来预加载.
如:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.examples.tutorials.mnist import mnist
def run_training():
"""训练 MNIST."""
# 加载数据集
data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)
# 默认 Graph 构建模型.
with tf.Graph().as_default():
with tf.name_scope('input'):
# 输入数据,CPU上运行
with tf.device('/cpu:0'):
input_images = tf.constant(data_sets.train.images)
input_labels = tf.constant(data_sets.train.labels)
image, label = tf.train.slice_input_producer(
[input_images, input_labels], num_epochs=FLAGS.num_epochs)
label = tf.cast(label, tf.int32)
images, labels = tf.train.batch(
[image, label], batch_size=FLAGS.batch_size)
# 构建 Graph,从推断模型计算预测值.
logits = mnist.inference(images, FLAGS.hidden1, FLAGS.hidden2)
# 添加 loss Op 到 Graph,用于loss值.
loss = mnist.loss(logits, labels)
# 添加梯度计算 Ops 到 Graph.
train_op = mnist.training(loss, FLAGS.learning_rate)
# 添加 labels 的预测 logits Op.
eval_correct = mnist.evaluation(logits, labels)
# Build the summary operation based on the TF collection of Summaries.
summary_op = tf.summary.merge_all()
# 训练断点保存 saver.
saver = tf.train.Saver()
# 权重变量初始化 Op.
init_op = tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer())
# 创建在 Graph 上运行 Ops 的会话session.
sess = tf.Session()
# 运行初始化变量 Op.
sess.run(init_op)
# 实例化 SummaryWriter,以输出 summaries 和 Graph.
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
# 启动输入队列线程input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 开始训练.
try:
step = 0
while not coord.should_stop():
start_time = time.time()
# 运行模型的一次迭代.
_, loss_value = sess.run([train_op, loss])
duration = time.time() - start_time
# 保存 summaries,打印信息.
if step % 100 == 0:
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value,
duration))
# Update the events file.
summary_str = sess.run(summary_op)
summary_writer.add_summary(summary_str, step)
step += 1
# 保存断点文件.
if (step + 1) % 1000 == 0:
print('Saving')
saver.save(sess, FLAGS.train_dir, global_step=step)
step += 1
except tf.errors.OutOfRangeError:
print('Saving')
saver.save(sess, FLAGS.train_dir, global_step=step)
print('Done training for %d epochs, %d steps.' % (FLAGS.num_epochs, step))
finally:
# 结束后,停止线程
coord.request_stop()
# 等待线程结束.
coord.join(threads)
sess.close()
在tensorflow/examples/how_tos/reading_data/fully_connected_preloaded_var.py,使用变量来预加载. 如:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.examples.tutorials.mnist import mnist
def run_training():
# 加载数据
data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)
with tf.Graph().as_default():
with tf.name_scope('input'):
# 输入数据
images_initializer = tf.placeholder(
dtype=data_sets.train.images.dtype,
shape=data_sets.train.images.shape)
labels_initializer = tf.placeholder(
dtype=data_sets.train.labels.dtype,
shape=data_sets.train.labels.shape)
input_images = tf.Variable(
images_initializer, trainable=False, collections=[])
input_labels = tf.Variable(
labels_initializer, trainable=False, collections=[])
image, label = tf.train.slice_input_producer(
[input_images, input_labels], num_epochs=FLAGS.num_epochs)
label = tf.cast(label, tf.int32)
images, labels = tf.train.batch(
[image, label], batch_size=FLAGS.batch_size)
# Build a Graph that computes predictions from the inference model.
logits = mnist.inference(images, FLAGS.hidden1, FLAGS.hidden2)
# Add to the Graph the Ops for loss calculation.
loss = mnist.loss(logits, labels)
# Add to the Graph the Ops that calculate and apply gradients.
train_op = mnist.training(loss, FLAGS.learning_rate)
# Add the Op to compare the logits to the labels during evaluation.
eval_correct = mnist.evaluation(logits, labels)
# Build the summary operation based on the TF collection of Summaries.
summary_op = tf.summary.merge_all()
# Create a saver for writing training checkpoints.
saver = tf.train.Saver()
# Create the op for initializing variables.
init_op = tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer())
# Create a session for running Ops on the Graph.
sess = tf.Session()
# Run the Op to initialize the variables.
sess.run(init_op)
sess.run(input_images.initializer,
feed_dict={images_initializer: data_sets.train.images})
sess.run(input_labels.initializer,
feed_dict={labels_initializer: data_sets.train.labels})
# Instantiate a SummaryWriter to output summaries and the Graph.
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
# Start input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# And then after everything is built, start the training loop.
try:
step = 0
while not coord.should_stop():
start_time = time.time()
# Run one step of the model.
_, loss_value = sess.run([train_op, loss])
duration = time.time() - start_time
# Write the summaries and print an overview fairly often.
if step % 100 == 0:
# Print status to stdout.
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value,
duration))
# Update the events file.
summary_str = sess.run(summary_op)
summary_writer.add_summary(summary_str, step)
step += 1
# Save a checkpoint periodically.
if (step + 1) % 1000 == 0:
print('Saving')
saver.save(sess, FLAGS.train_dir, global_step=step)
step += 1
except tf.errors.OutOfRangeError:
print('Saving')
saver.save(sess, FLAGS.train_dir, global_step=step)
print('Done training for %d epochs, %d steps.' % (FLAGS.num_epochs, step))
finally:
# When done, ask the threads to stop.
coord.request_stop()
# Wait for threads to finish.
coord.join(threads)
sess.close()